P3-LLM: An Integrated NPU-PIM Accelerator for Edge LLM Inference Using Hybrid Numerical Formats
Pith reviewed 2026-05-18 00:12 UTC · model grok-4.3
The pith
Hybrid numerical formats let low-precision PIM units accelerate edge LLM inference while preserving accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
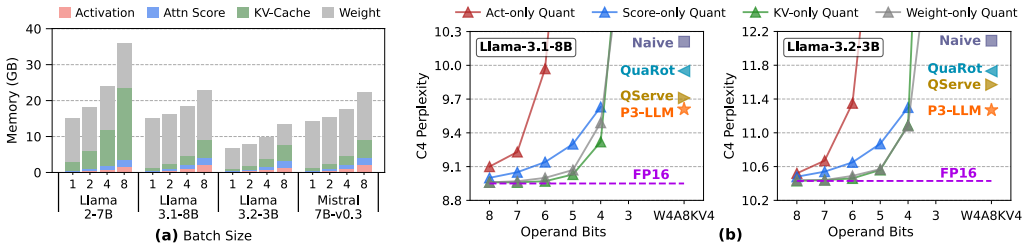
P3-LLM introduces a flexible mixed-precision quantization scheme that applies hybrid numerical formats to different LLM operands for high compression and minimal accuracy loss. An efficient PIM accelerator is then built with enhanced compute units that support these formats, allowing low-precision PIM operation under iso-area constraints and thereby raising computation throughput. Low-precision dataflow is further optimized by operator fusion to cut dequantization overhead, producing higher accuracy than prior KV-cache and weight-activation quantization methods together with average speedups of 4.9× over HBM-PIM, 2.0× over Ecco, and 3.4× over Pimba across diverse LLMs and tasks.
What carries the argument
Hybrid numerical formats applied to different LLM operands, which enable co-design of low-precision PIM compute units that raise throughput under iso-area constraints in DRAM technology.
If this is right
- The accelerator achieves higher accuracy than state-of-the-art KV-cache quantization and weight-activation quantization algorithms.
- Average speedups reach 4.9× over HBM-PIM, 2.0× over Ecco, and 3.4× over Pimba.
- Operator fusion minimizes runtime dequantization overhead for low-precision dataflow across LLM modules.
- The design supports diverse LLMs and tasks on edge hardware under iso-area constraints.
Where Pith is reading between the lines
- The same operand-specific format selection might reduce energy in other memory-bound accelerators such as those for vision or speech models.
- Hardware prototypes could expose additional fusion opportunities when the NPU and PIM share a common low-precision data path.
- Extending the approach to dynamic format selection at runtime could further adapt to varying sequence lengths without retraining.
Load-bearing premise
The hybrid numerical formats chosen for different operands will maintain acceptable accuracy while allowing the PIM compute units to be built at low precision under realistic iso-area constraints in actual DRAM technology.
What would settle it
A cycle-accurate or post-layout simulation of the low-precision PIM units in real DRAM process parameters that shows either throughput gains below the claimed multiples or accuracy loss exceeding the reported levels on the same models and tasks.
Figures










read the original abstract
The substantial memory bandwidth and computational demands of large language models (LLMs) present critical challenges for efficient inference. To tackle this, the literature has explored heterogeneous systems that combine neural processing units (NPUs) with DRAM-based processing-in-memory (PIM) for LLM acceleration. However, the high-precision PIM compute units incur significant area and power overhead in DRAM technology, limiting the effective computation throughput. In this paper, we introduce P3-LLM, a novel NPU-PIM integrated accelerator for edge LLM inference. Our approach is threefold: First, we propose a flexible mixed-precision quantization scheme, which leverages hybrid numerical formats to quantize different LLM operands with high compression efficiency and minimal accuracy loss. Second, we architect an efficient PIM accelerator for P3-LLM, featuring enhanced compute units to support hybrid numerical formats. Our careful choice of numerical formats allows to co-design low-precision PIM compute units that significantly boost the computation throughput under iso-area constraints. Third, we optimize the low-precision dataflow of different LLM modules by applying operator fusion to minimize the overhead of runtime dequantization. Evaluations on diverse LLMs and tasks demonstrate that P3-LLM achieves higher accuracy than state-of-the-art KV-cache quantization and weight-activation quantization algorithms. Combining the proposed quantization scheme with low-precision PIM architecture co-design, P3-LLM yields an average of $4.9\times$, $2.0\times$, and $3.4\times$ speedups over state-of-the-art LLM accelerators HBM-PIM, Ecco, and Pimba, respectively. Code is available at https://github.com/yc2367/P3-LLM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes P3-LLM, an integrated NPU-PIM accelerator for edge LLM inference. It introduces a flexible mixed-precision quantization scheme using hybrid numerical formats to quantize different LLM operands, an efficient PIM architecture with enhanced low-precision compute units co-designed for these formats to increase throughput under iso-area constraints in DRAM, and operator fusion to reduce runtime dequantization overhead in the low-precision dataflow. Evaluations claim higher accuracy than state-of-the-art KV-cache and weight-activation quantization methods, along with average speedups of 4.9× over HBM-PIM, 2.0× over Ecco, and 3.4× over Pimba.
Significance. If the hybrid-format co-design successfully enables low-precision PIM units while respecting realistic DRAM area budgets and maintaining accuracy, the work could meaningfully advance efficient edge LLM deployment by improving computation throughput in heterogeneous NPU-PIM systems. The open availability of code at the cited GitHub repository is a positive contribution to reproducibility.
major comments (2)
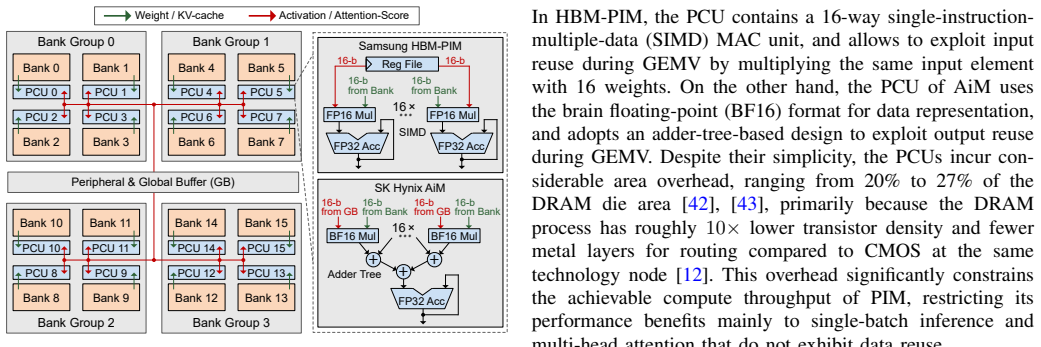
- [Section 4] Section 4 and associated architecture diagrams: the description of enhanced PIM compute units for hybrid numerical formats treats format conversion, dequantization logic, and multi-precision datapath support as area-neutral or negligible under iso-area constraints. In actual DRAM processes, even modest additional logic for operand routing or sense-amp sharing can increase effective area per compute unit and erode the density gain that underpins the reported throughput numbers; a quantitative area breakdown including these overheads is needed to substantiate the central speedup claims.
- [Evaluation] Evaluation section: the reported average speedups (4.9×, 2.0×, 3.4×) are presented without visible error bars, detailed descriptions of baseline implementations, or full experimental setup parameters, which prevents full verification of the performance advantages over HBM-PIM, Ecco, and Pimba.
minor comments (2)
- [Abstract] The abstract states that P3-LLM 'achieves higher accuracy' than SOTA methods but does not specify the exact accuracy metrics, models, or tasks where the gains are observed; adding this detail would improve clarity.
- Figure captions and table labels for the hybrid numerical formats and PIM datapath should explicitly indicate bit-widths and conversion points to aid reader understanding.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below and have revised the paper to strengthen the substantiation of our claims.
read point-by-point responses
-
Referee: [Section 4] Section 4 and associated architecture diagrams: the description of enhanced PIM compute units for hybrid numerical formats treats format conversion, dequantization logic, and multi-precision datapath support as area-neutral or negligible under iso-area constraints. In actual DRAM processes, even modest additional logic for operand routing or sense-amp sharing can increase effective area per compute unit and erode the density gain that underpins the reported throughput numbers; a quantitative area breakdown including these overheads is needed to substantiate the central speedup claims.
Authors: We appreciate this point. Our hybrid format selection was deliberately chosen to maximize resource sharing across precisions and thereby limit extra logic. Nevertheless, we agree that an explicit breakdown is required for credibility. In the revised Section 4 we now include a quantitative area breakdown (Table IV and accompanying text) derived from synthesized layouts in the target DRAM process. The breakdown shows that format conversion, dequantization, and multi-precision routing together add less than 8 % to the per-unit area; the reported iso-area throughput gains remain intact after this overhead is accounted for. revision: yes
-
Referee: [Evaluation] Evaluation section: the reported average speedups (4.9×, 2.0×, 3.4×) are presented without visible error bars, detailed descriptions of baseline implementations, or full experimental setup parameters, which prevents full verification of the performance advantages over HBM-PIM, Ecco, and Pimba.
Authors: We concur that greater transparency aids verification. The revised Evaluation section now reports error bars (standard deviation over five independent runs), provides expanded descriptions of how each baseline (HBM-PIM, Ecco, Pimba) was implemented and configured, and includes a new table (Table VII) listing all key experimental parameters: hardware configurations, DRAM process assumptions, workload batch sizes, and simulation settings. revision: yes
Circularity Check
No significant circularity; claims rest on external evaluations
full rationale
The paper proposes a hybrid-format quantization scheme and co-designed low-precision PIM units, then reports empirical speedups (4.9×/2.0×/3.4×) measured against external baselines HBM-PIM, Ecco, and Pimba on diverse LLMs. No derivation step reduces a claimed prediction or throughput result to a fitted parameter or self-citation by construction. Iso-area assumptions are design choices whose validity is tested via reported evaluations rather than defined into the result. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption High-precision PIM compute units incur significant area and power overhead in DRAM technology.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our approach is threefold: ... hybrid numerical formats to quantize different LLM operands ... low-precision PIM compute units that significantly boost the computation throughput under iso-area constraints.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
AMD, “AMD INSTINCT™ MI350X GPU.” [Online]. Avail- able: https://www.amd.com/content/dam/amd/en/documents/instinct- tech-docs/product-briefs/amd-instinct-mi350x-gpu-brochure.pdf
-
[2]
QuaRot: Outlier-Free 4-Bit Inference in Rotated LLMs,
S. Ashkboos, A. Mohtashami, M. L. Croci, B. Li, M. Jaggi, D. Alistarh, T. Hoefler, and J. Hensman, “QuaRot: Outlier-Free 4-Bit Inference in Rotated LLMs,”Advances in neural information processing systems (NeurIPS), 2024
work page 2024
-
[3]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
J. Bai, S. Bai, S. Yang, S. Wang, S. Tan, P. Wang, J. Lin, C. Zhou, and J. Zhou, “Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond,”arXiv preprint arXiv:2308.12966, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding,
Y . Bai, X. Lv, J. Zhang, H. Lyu, J. Tang, Z. Huang, Z. Du, X. Liu, A. Zeng, L. Hou, Y . Dong, J. Tang, and J. Li, “LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding,”Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), 2024
work page 2024
-
[5]
CACTI 7: New tools for interconnect exploration in innovative off-chip memories,
R. Balasubramonian, A. B. Kahng, N. Muralimanohar, A. Shafiee, and V . Srinivas, “CACTI 7: New tools for interconnect exploration in innovative off-chip memories,”ACM Transactions on Architecture and Code Optimization (TACO), vol. 14, no. 2, June 2017
work page 2017
-
[6]
Language Models are Few-Shot Learners,
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert- V oss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Amode...
work page 2020
-
[7]
BitMoD: Bit-serial Mixture-of- Datatype LLM Acceleration,
Y . Chen, A. F. AbouElhamayed, X. Dai, Y . Wang, M. Andronic, G. A. Constantinides, and M. S. Abdelfattah, “BitMoD: Bit-serial Mixture-of- Datatype LLM Acceleration,”IEEE International Symposium on High- Performance Computer Architecture (HPCA), 2025
work page 2025
-
[8]
Ecco: Improving Memory Band- width and Capacity for LLMs via Entropy-Aware Cache Compression,
F. Cheng, C. Guo, C. Wei, J. Zhang, C. Zhou, E. Hanson, J. Zhang, X. Liu, H. H. Li, and Y . Chen, “Ecco: Improving Memory Band- width and Capacity for LLMs via Entropy-Aware Cache Compression,” ACM/IEEE 52nd Annual International Symposium on Computer Archi- tecture (ISCA), 2025
work page 2025
-
[9]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
P. Clark, I. Cowhey, O. Etzioni, T. Khot, A. Sabharwal, C. Schoenick, and O. Tafjord, “Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge,”arXiv preprint arXiv:1803.05457, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[10]
DeepSeek AI, “DeepSeek R1.” [Online]. Available: https://github.com/ deepseek-ai/DeepSeek-R1
-
[11]
LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
T. Dettmers, M. Lewis, Y . Belkada, and L. Zettlemoyer, “LLM.int8(): 8-bit matrix multiplication for transformers at scale,”arXiv preprint arXiv:2208.07339, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[12]
The true Processing In Memory accelerator,
F. Devaux, “The true Processing In Memory accelerator,”IEEE Hot Chips 31 Symposium (HCS), 2019
work page 2019
-
[13]
Documenting large webtext corpora: A case study on the colossal clean crawled corpus,
J. Dodge, A. Marasovic, G. Ilharco, D. Groeneveld, M. Mitchell, and M. Gardner, “Documenting large webtext corpora: A case study on the colossal clean crawled corpus,” inConference on Empirical Methods in Natural Language Processing (EMNLP), 2021
work page 2021
-
[14]
Learning from Students: Applying t-Distributions to Explore Accurate and Efficient Formats for LLMs,
J. Dotzel, Y . Chen, B. Kotb, S. Prasad, G. Wu, S. Li, M. S. Abdelfat- tah, and Z. Zhang, “Learning from Students: Applying t-Distributions to Explore Accurate and Efficient Formats for LLMs,”International Conference on Machine Learning (ICML), 2024
work page 2024
-
[15]
Anda: Unlocking Efficient LLM Inference with a Variable-Length Grouped Activation Data Format,
C. Fang, M. Shi, R. Geens, A. Symons, Z. Wang, and M. Verhelst, “Anda: Unlocking Efficient LLM Inference with a Variable-Length Grouped Activation Data Format,”IEEE International Symposium on High-Performance Computer Architecture (HPCA), 2025
work page 2025
-
[16]
GPTQ: Accurate Post-training Compression for Generative Pretrained Transformers,
E. Frantar, S. Ashkboos, T. Hoefler, and D. Alistarh, “GPTQ: Accurate Post-training Compression for Generative Pretrained Transformers,” International Conference on Learning Representations (ICLR), 2023
work page 2023
-
[17]
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
L. Gao, S. Biderman, S. Black, L. Golding, T. Hoppe, C. Foster, J. Phang, H. He, A. Thite, N. Nabeshima, S. Presser, and C. Leahy, “The Pile: An 800GB Dataset of Diverse Text for Language Modeling,” arXiv preprint arXiv:2101.00027, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[18]
Zorik Gekhman, Gal Yona, Roee Aharoni, Matan Eyal, Amir Feder, Roi Reichart, and Jonathan Herzig
L. Gao, J. Tow, B. Abbasi, S. Biderman, S. Black, A. DiPofi, C. Foster, L. Golding, J. Hsu, A. Le Noac’h, H. Li, K. McDonell, N. Muennighoff, C. Ociepa, J. Phang, L. Reynolds, H. Schoelkopf, A. Skowron, L. Sutawika, E. Tang, A. Thite, B. Wang, K. Wang, and A. Zou, “The Language Model Evaluation Harness,” 2024. [Online]. Available: https://zenodo.org/recor...
-
[19]
Energy Cost Modelling for Optimizing Large Language Model Inference on Hardware Accelerators,
R. Geens, M. Shi, A. Symons, C. Fang, and M. Verhelst, “Energy Cost Modelling for Optimizing Large Language Model Inference on Hardware Accelerators,” inIEEE 37th International System-on-Chip Conference (SOCC), 2024
work page 2024
-
[20]
OliVe: Accelerating Large Language Models via Hardware-friendly Outlier-Victim Pair Quantization,
C. Guo, J. Tang, W. Hu, J. Leng, C. Zhang, F. Yang, Y .-B. Liu, M. Guo, and Y . Zhu, “OliVe: Accelerating Large Language Models via Hardware-friendly Outlier-Victim Pair Quantization,”ACM/IEEE 50th Annual International Symposium on Computer Architecture (ISCA), 2023
work page 2023
-
[21]
ANT: Exploiting Adaptive Numerical Data Type for Low-bit Deep Neural Network Quantization,
C. Guo, C. Zhang, J. Leng, Z. Liu, F. Yang, Y .-B. Liu, M. Guo, and Y . Zhu, “ANT: Exploiting Adaptive Numerical Data Type for Low-bit Deep Neural Network Quantization,”IEEE/ACM 55th Annual International Symposium on Microarchitecture (MICRO), 2022
work page 2022
-
[22]
Newton: A DRAM-maker’s Accelerator-in- Memory (AiM) Architecture for Machine Learning,
M. He, C. Song, I. Kim, C. Jeong, S. Kim, I. Park, M. Thottethodi, and T. N. Vijaykumar, “Newton: A DRAM-maker’s Accelerator-in- Memory (AiM) Architecture for Machine Learning,”IEEE/ACM 53rd International Symposium on Microarchitecture (MICRO), 2020
work page 2020
-
[23]
S. He, Z. Zhu, Y . He, and T. Jia, “LP-Spec: Leveraging LPDDR PIM for Efficient LLM Mobile Speculative Inference with Architecture- Dataflow Co-Optimization,” inIEEE/ACM International Conference on Computer-Aided Design (ICCAD), 2025
work page 2025
-
[24]
Measuring Massive Multitask Language Understanding,
D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song, and J. Steinhardt, “Measuring Massive Multitask Language Understanding,” inInternational Conference on Learning Representations (ICLR), 2021
work page 2021
-
[25]
NeuPIMs: NPU-PIM Heterogeneous Acceleration for Batched LLM Inferencing,
G. Heo, S. Lee, J. Cho, H. Choi, S. Lee, H. Ham, G. T. Kim, D. Mahajan, and J. Park, “NeuPIMs: NPU-PIM Heterogeneous Acceleration for Batched LLM Inferencing,”Proceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), 2024
work page 2024
-
[26]
KVQuant: Towards 10 Million Context Length LLM Inference with KV Cache Quantization,
C. Hooper, S. Kim, H. Mohammadzadeh, M. W. Mahoney, Y . S. Shao, K. Keutzer, and A. Gholami, “KVQuant: Towards 10 Million Context Length LLM Inference with KV Cache Quantization,”Advances in neural information processing systems (NeurIPS), 2024
work page 2024
-
[27]
M-ANT: Efficient Low-bit Group Quantization 13 for LLMs via Mathematically Adaptive Numerical Type,
W. Hu, H. Zhang, C. Guo, Y . Feng, R. Guan, Z. Hua, Z. Liu, Y . Guan, M. Guo, and J. Leng, “M-ANT: Efficient Low-bit Group Quantization 13 for LLMs via Mathematically Adaptive Numerical Type,”IEEE Interna- tional Symposium on High-Performance Computer Architecture (HPCA), 2025
work page 2025
-
[28]
Y . Hu, F. Liu, Z. Wang, Y . Zhao, T. Yang, L. Jiang, and H. Guan, “PLAIN: Leveraging High Internal Bandwidth in PIM for Accelerating Large Language Model Inference via Mixed-Precision Quantization,” inIEEE/ACM International Conference on Computer-Aided Design (ICCAD), 2025
work page 2025
-
[29]
FIGNA: Integer unit-based accelerator design for fp-int gemm preserving numerical accuracy,
J. Jang, Y . Kim, J. Lee, and J.-J. Kim, “FIGNA: Integer unit-based accelerator design for fp-int gemm preserving numerical accuracy,”IEEE International Symposium on High-Performance Computer Architecture (HPCA), 2024
work page 2024
-
[30]
BlockDialect: Block-wise Fine-grained Mixed Format Quantization for Energy-Efficient LLM Inference,
W. Jang and T. Tambe, “BlockDialect: Block-wise Fine-grained Mixed Format Quantization for Energy-Efficient LLM Inference,”International Conference on Machine Learning (ICML), 2025
work page 2025
-
[31]
JEDEC, “High Bandwidth Memory DRAM,” 2021. [Online]. Available: https://www.jedec.org/standards-documents/docs/jesd235a
work page 2021
-
[32]
High Bandwidth Memory (HBM3) DRAM,
JEDEC, “High Bandwidth Memory (HBM3) DRAM,” 2025. [Online]. Available: https://www.jedec.org/standards-documents/docs/jesd238b01
work page 2025
-
[33]
High Bandwidth Memory (HBM4) DRAM,
JEDEC, “High Bandwidth Memory (HBM4) DRAM,” 2025. [Online]. Available: https://www.jedec.org/standards-documents/docs/jesd270-4
work page 2025
-
[34]
A. Q. Jiang, A. Sablayrolles, A. Mensch, C. Bamford, D. S. Chaplot, D. de Las Casas, F. Bressand, G. Lengyel, G. Lample, L. Saulnier, L. R. Lavaud, M.-A. Lachaux, P. Stock, T. L. Scao, T. Lavril, T. Wang, T. Lacroix, and W. E. Sayed, “Mistral 7B,”arXiv preprint arXiv:2310.06825, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[35]
Ten Lessons From Three Generations Shaped Google’s TPUv4i: Industrial Product,
N. P. Jouppi, D. H. Yoon, M. Ashcraft, M. Gottscho, T. B. Jablin, G. Kurian, J. Laudon, S. Li, P. C. Ma, X. Ma, T. Norrie, N. Patil, S. Prasad, C. Young, Z. Zhou, and D. A. Patterson, “Ten Lessons From Three Generations Shaped Google’s TPUv4i: Industrial Product,” ACM/IEEE 48th Annual International Symposium on Computer Archi- tecture (ISCA), 2021
work page 2021
-
[36]
G. Kim, J. Kim, N. Y . Kim, W. Shin, J.-H. Won, H. Joo, H. Choi, B. An, G. Shin, D. Yun, J. Kim, C. Kim, I.-H. Kim, J. Park, Y . Song, B. Yang, H. Lee, S. Park, W. Lee, S. Kim, Y . Park, Y . Jung, G.-H. Park, and E. Lim, “SK Hynix AI-Specific Computing Memory Solution: From AiM Device to Heterogeneous AiMX-xPU System for Comprehensive LLM Inference,”IEEE ...
work page 2024
-
[37]
Samsung PIM/PNM for Transfmer Based AI : Energy Efficiency on PIM/PNM Cluster,
J. H. Kim, Y . Ro, J. So, S. Lee, S. Kang, Y . Cho, H. Kim, B. Kim, K. Kim, S.-S. Park, J.-S. Kim, S. Cha, W.-J. Lee, J. Jung, J. Lee, J. Lee, J. Song, S. Lee, J. Cho, J. Yu, and K. Sohn, “Samsung PIM/PNM for Transfmer Based AI : Energy Efficiency on PIM/PNM Cluster,”IEEE Hot Chips 35 Symposium (HCS), 2023
work page 2023
-
[38]
Oaken: Fast and Efficient LLM Serving with Online-Offline Hybrid KV Cache Quantization,
M. Kim, S. Hong, R. Ko, S. Choi, H. Lee, J. Kim, J.-Y . Kim, and J. Park, “Oaken: Fast and Efficient LLM Serving with Online-Offline Hybrid KV Cache Quantization,”ACM/IEEE 52nd Annual International Symposium on Computer Architecture (ISCA), 2025
work page 2025
-
[39]
Pimba: A Processing- in-Memory Acceleration for Post-Transformer Large Language Model Serving,
W. Kim, Y . Lee, Y . Kim, J. Hwang, S. Oh, J. Jung, A. Huseynov, W. G. Park, C. H. Park, D. Mahajan, and J. Park, “Pimba: A Processing- in-Memory Acceleration for Post-Transformer Large Language Model Serving,”IEEE/ACM 58th International Symposium on Microarchitec- ture (MICRO), 2025
work page 2025
-
[40]
Tender: Accelerating Large Language Mod- els via Tensor Decomposition and Runtime Requantization,
J. Lee, W. Lee, and J. Sim, “Tender: Accelerating Large Language Mod- els via Tensor Decomposition and Runtime Requantization,”ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA), 2024
work page 2024
-
[41]
MX+: Pushing the Limits of Microscaling Formats for Efficient Large Language Model Serving,
J. Lee, J. Park, S. Cha, J. Cho, and J. Sim, “MX+: Pushing the Limits of Microscaling Formats for Efficient Large Language Model Serving,” IEEE/ACM 58th Annual International Symposium on Microarchitecture (MICRO), 2025
work page 2025
-
[42]
S. J. Lee, K. Kim, S. Oh, J. Park, G. Hong, D. Y . Ka, K.-D. Hwang, J.-J. Park, K. Kang, J. Kim, J. Jeon, N. Y . Kim, Y . Kwon, K. Vladimir, W. Shin, J.-H. Won, M. Lee, H. Joo, H. Choi, J. Lee, D.-Y . Ko, Y . Jun, K. yeong Cho, I. Kim, C. Song, C. Jeong, D.-H. Kwon, J. Jang, I. Park, J. H. Chun, and J. Cho, “A 1ynm 1.25V 8Gb 16Gb/s/Pin GDDR6- Based Accele...
work page 2023
-
[43]
S. Lee, S. Kang, J. Lee, H. Kim, E. Lee, S. young Seo, H. Yoon, S. Lee, K. Lim, H. Shin, J. Kim, S. O, A. Iyer, D. Wang, K. Sohn, and N. S. Kim, “Hardware Architecture and Software Stack for PIM Based on Commercial DRAM Technology: Industrial Product,”ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA), 2021
work page 2021
-
[44]
C. Li, Y . Yin, X. Wu, J. Zhu, Z. Gao, D. Niu, Q. Wu, X. Si, Y . Xie, C. Zhang, and G. Sun, “H2-LLM: Hardware-Dataflow Co-Exploration for Heterogeneous Hybrid-Bonding-based Low-Batch LLM Inference,” ACM/IEEE 52nd Annual International Symposium on Computer Archi- tecture (ISCA), 2025
work page 2025
-
[45]
S. Li, Y . Chen, C. Li, Y . Fu, Z. Wang, Z. Yu, H. You, Z. Ye, W. Zhou, Y . Zhang, and Y . C. Lin, “ORCHES: Orchestrated Test-Time- Compute-based LLM Reasoning on Collaborative GPU-PIM HEteroge- neous System,”IEEE/ACM 58th Annual International Symposium on Microarchitecture (MICRO), 2025
work page 2025
-
[46]
AWQ: Activation-aware Weight Quan- tization for LLM Compression and Acceleration,
J. Lin, J. Tang, H. Tang, S. Yang, W.-M. Chen, W.-C. Wang, G. Xiao, X. Dang, C. Gan, and S. Han, “AWQ: Activation-aware Weight Quan- tization for LLM Compression and Acceleration,” inProceedings of Machine Learning and Systems (MLSys), 2024
work page 2024
-
[47]
QServe: W4A8KV4 Quantization and System Co-design for Efficient LLM Serving,
Y . Lin, H. Tang, S. Yang, Z. Zhang, G. Xiao, C. Gan, and S. Han, “QServe: W4A8KV4 Quantization and System Co-design for Efficient LLM Serving,” inProceedings of Machine Learning and Systems (MLSys), 2025
work page 2025
-
[48]
SPARK: Scalable and Precision-Aware Acceleration of Neural Networks via Ef- ficient Encoding,
F. Liu, N. Yang, H. Li, Z. Wang, Z. Song, S. Pei, and L. Jiang, “SPARK: Scalable and Precision-Aware Acceleration of Neural Networks via Ef- ficient Encoding,”IEEE International Symposium on High-Performance Computer Architecture (HPCA), 2024
work page 2024
-
[49]
KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache,
Z. Liu, J. Yuan, H. Jin, S. Zhong, Z. Xu, V . Braverman, B. Chen, and X. Hu, “KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache,”International Conference on Machine Learning (ICML), 2024
work page 2024
-
[50]
Ramulator 2.0: A Modern, Modular, and Extensible DRAM Simulator,
H. Luo, Y . C. Tugrul, F. N. Bostanci, A. Olgun, A. G. Yaglikc ¸i, and O. Mutlu, “Ramulator 2.0: A Modern, Modular, and Extensible DRAM Simulator,”IEEE Computer Architecture Letters (CAL), vol. 23, pp. 112– 116, 2023
work page 2023
-
[51]
Pointer sentinel mixture models,
S. Merity, C. Xiong, J. Bradbury, and R. Socher, “Pointer sentinel mixture models,”International Conference on Learning Representations (ICLR), 2017
work page 2017
-
[52]
Introducing Llama 3.1: Our most capable models to date
Meta, “Introducing Llama 3.1: Our most capable models to date.” [Online]. Available: https://ai.meta.com/blog/meta-llama-3-1/
-
[53]
Meta, “Llama-3.2-90B-Vision-Instruct.” [Online]. Available: https: //huggingface.co/meta-llama/Llama-3.2-90B-Vision-Instruct
-
[54]
Llama 3.2: Revolutionizing edge AI and vision with open, customizable models
Meta, “Llama 3.2: Revolutionizing edge AI and vision with open, customizable models.” [Online]. Available: https://ai.meta.com/blog/ llama-3-2-connect-2024-vision-edge-mobile-devices/
work page 2024
-
[55]
Meta, “Meta Llama 2.” [Online]. Available: https://github.com/meta- llama/llama
-
[56]
The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation
Meta, “The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation.” [Online]. Available: https: //ai.meta.com/blog/llama-4-multimodal-intelligence/
-
[57]
P. Micikevicius, D. Stosic, N. Burgess, M. Cornea, P. K. Dubey, R. Grisenthwaite, S. Ha, A. Heinecke, P. Judd, J. Kamalu, N. Mellem- pudi, S. F. Oberman, M. Shoeybi, M. Siu, and H. Wu, “FP8 Formats for Deep Learning,”arXiv preprint arXiv:2209.05433, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[58]
Introducing NVFP4 for Efficient and Accurate Low-Precision Inference
NVIDIA, “Introducing NVFP4 for Efficient and Accurate Low-Precision Inference.” [Online]. Available: https://developer.nvidia.com/blog/ introducing-nvfp4-for-efficient-and-accurate-low-precision-inference/
-
[59]
NVIDIA Blackwell GPU Architecture
NVIDIA, “NVIDIA Blackwell GPU Architecture.” [Online]. Available: https://resources.nvidia.com/en-us-blackwell-architecture/datasheet
-
[60]
Open AI, “Openai o3-mini.” [Online]. Available: https://openai.com/ index/openai-o3-mini/
-
[61]
OpenAI, “Gsm8k dataset.” [Online]. Available: https://huggingface.co/ datasets/openai/gsm8k
-
[62]
FIGLUT: An Energy-Efficient Accelerator Design for FP-INT GEMM Using Look-Up Tables,
G. Park, H. Kwon, J. Kim, J. Bae, B. Park, D. Lee, and Y . Lee, “FIGLUT: An Energy-Efficient Accelerator Design for FP-INT GEMM Using Look-Up Tables,”IEEE International Symposium on High- Performance Computer Architecture (HPCA), 2025
work page 2025
-
[63]
AttAcc! Unleashing the Power of PIM for Batched Transformer- based Generative Model Inference,
J. Park, J. Choi, K. Kyung, M. J. Kim, Y . Kwon, N. S. Kim, and J. H. Ahn, “AttAcc! Unleashing the Power of PIM for Batched Transformer- based Generative Model Inference,”Proceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), 2024
work page 2024
-
[64]
MicroScopiQ: Ac- celerating Foundational Models through Outlier-Aware Microscaling Quantization,
A. Ramachandran, S. Kundu, and T. Krishna, “MicroScopiQ: Ac- celerating Foundational Models through Outlier-Aware Microscaling Quantization,”ACM/IEEE 52nd Annual International Symposium on Computer Architecture (ISCA), 2025
work page 2025
-
[65]
With Shared Microexponents, A Little Shifting Goes a Long Way,
B. D. Rouhani, R. Zhao, V . Elango, R. Shafipour, M. Hall, M. Mes- makhosroshahi, A. More, L. Melnick, M. Golub, G. Varatkar, L. Shao, G. Kolhe, D. Melts, J. Klar, R. L’Heureux, M. Perry, D. Burger, E. S. Chung, Z. Deng, S. Naghshineh, J. Park, and M. Naumov, “With Shared Microexponents, A Little Shifting Goes a Long Way,”ACM/IEEE 50th 14 Annual Internati...
work page 2023
-
[66]
IANUS: Integrated Accelerator based on NPU-PIM Unified Memory System,
M. Seo, X. T. Nguyen, S. J. Hwang, Y . Kwon, G. Kim, C. Y . Park, I.-H. Kim, J. Park, J. Kim, W. Shin, J.-H. Won, H. Choi, K. Kim, D. Kwon, C. Jeong, S. Lee, Y . Choi, W. Byun, S. Baek, H.-J. Lee, and J. Kim, “IANUS: Integrated Accelerator based on NPU-PIM Unified Memory System,”Proceedings of the 29th ACM International Conference on Ar- chitectural Suppo...
work page 2024
-
[67]
OmniQuant: Omnidirectionally Calibrated Quantization for Large Language Models,
W. Shao, M. Chen, Z. Zhang, P. Xu, L. Zhao, Z. Li, K. Zhang, P. Gao, Y . J. Qiao, and P. Luo, “OmniQuant: Omnidirectionally Calibrated Quantization for Large Language Models,”International Conference on Learning Representations (ICLR), 2024
work page 2024
-
[68]
RoFormer: Enhanced Transformer with Rotary Position Embedding,
J. Su, Y . Lu, S. Pan, B. Wen, and Y . Liu, “RoFormer: Enhanced Transformer with Rotary Position Embedding,”Neurocomputing, 2024
work page 2024
-
[69]
LLaMA: Open and Efficient Foundation Language Models
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozi `ere, N. Goyal, E. Hambro, F. Azhar, A. Rodriguez, A. Joulin, E. Grave, and G. Lample, “LLaMA: Open and Efficient Foundation Language Models,”arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[70]
FP8 versus INT8 for efficient deep learning inference,
M. van Baalen, A. Kuzmin, S. S. Nair, Y . Ren, E. Mahurin, C. Patel, S. Subramanian, S. Lee, M. Nagel, J. B. Soriaga, and T. Blankevoort, “FP8 versus INT8 for efficient deep learning inference,”arXiv preprint arXiv:2303.17951, 2023
-
[71]
ZeroQuant-FP: A Leap Forward in LLMs Post-Training W4A8 Quantization Using Floating-Point Formats,
X. Wu, Z. Yao, and Y . He, “ZeroQuant-FP: A Leap Forward in LLMs Post-Training W4A8 Quantization Using Floating-Point Formats,”arXiv preprint arXiv:2307.09782, 2023
-
[72]
SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models,
G. Xiao, J. Lin, M. Seznec, J. Demouth, and S. Han, “SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models,”International Conference on Machine Learning (ICML), 2023
work page 2023
-
[73]
X. Xie, L. Wang, L. Xiao, M. Han, L. Liu, X. Xu, J. Wang, Z. Song, and X. Liao, “Amove: Accelerating LLMs through Mitigating Outliers and Salient Points via Fine-Grained Grouped Vectorized Data Type,” IEEE/ACM 58th International Symposium on Microarchitecture (MI- CRO), 2025
work page 2025
-
[74]
A. Yang, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Li, D. Liu, F. Huang, H. Wei, H. Lin, J. Yang, J. Tu, J. Zhang, J. Yang, J. Yang, J. Zhou, J. Lin, K. Dang, K. Lu, K. Bao, K. Yang, L. Yu, M. Li, M. Xue, P. Zhang, Q. Zhu, R. Men, R. Lin, T. Li, T. Tang, T. Xia, X. Ren, X. Ren, Y . Fan, Y . Su, Y . Zhang, Y . Wan, Y . Liu, Z. Cui, Z. Zhang, and Z. Qi...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[75]
FlashInfer: Efficient and Customizable Attention Engine for LLM Inference Serving,
Z. Ye, L. Chen, R. Lai, W. Lin, Y . Zhang, S. Wang, T. Chen, B. Kasikci, V . Grover, A. Krishnamurthy, and L. Ceze, “FlashInfer: Efficient and Customizable Attention Engine for LLM Inference Serving,”Proceed- ings of Machine Learning and Systems (MLSys), 2025
work page 2025
-
[76]
S. Yun, K. Kyung, J. Cho, J. Choi, J. Kim, B. Kim, S. Lee, K. Sohn, and J. H. Ahn, “Duplex: A Device for Large Language Models with Mixture of Experts, Grouped Query Attention, and Continuous Batch- ing,”IEEE/ACM 57th International Symposium on Microarchitecture (MICRO), 2024
work page 2024
-
[77]
SageAttention: Accurate 8-Bit Attention for Plug-and-play Inference Acceleration,
J. Zhang, J. Wei, P. Zhang, J. Zhu, and J. Chen, “SageAttention: Accurate 8-Bit Attention for Plug-and-play Inference Acceleration,”International Conference on Learning Representations (ICLR), 2025
work page 2025
-
[78]
DistServe: Disaggregating Prefill and Decoding for Goodput- optimized Large Language Model Serving,
Y . Zhong, S. Liu, J. Chen, J. Hu, Y . Zhu, X. Liu, X. Jin, and H. Zhang, “DistServe: Disaggregating Prefill and Decoding for Goodput- optimized Large Language Model Serving,” in18th USENIX Symposium on Operating Systems Design and Implementation (OSDI), 2024
work page 2024
-
[79]
A Survey on Efficient Inference for Large Language Models
Z. Zhou, X. Ning, K. Hong, T. Fu, J. Xu, S. Li, Y . Lou, L. Wang, Z. Yuan, X. Li, S. Yan, G. Dai, X. Zhang, Y . Dong, and Y . Wang, “A Survey on Efficient Inference for Large Language Models,”arXiv preprint arXiv:2404.14294, 2024. 15
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.