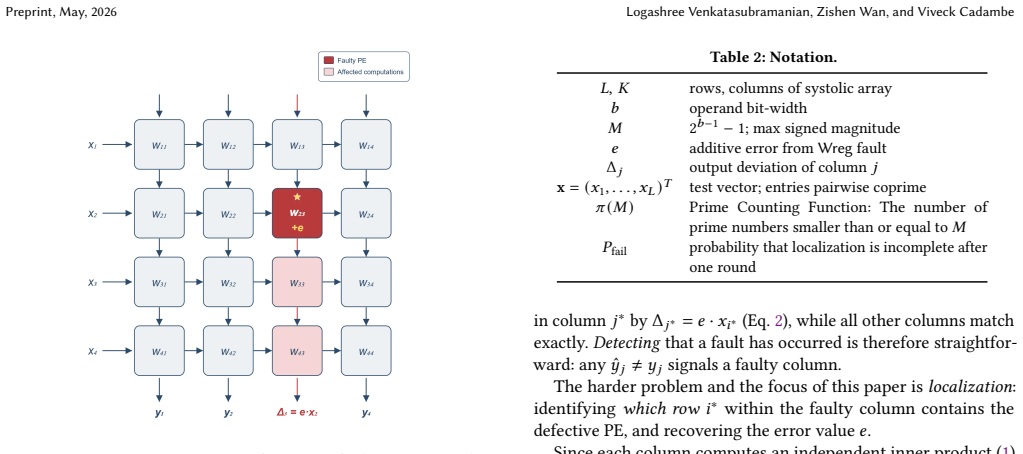
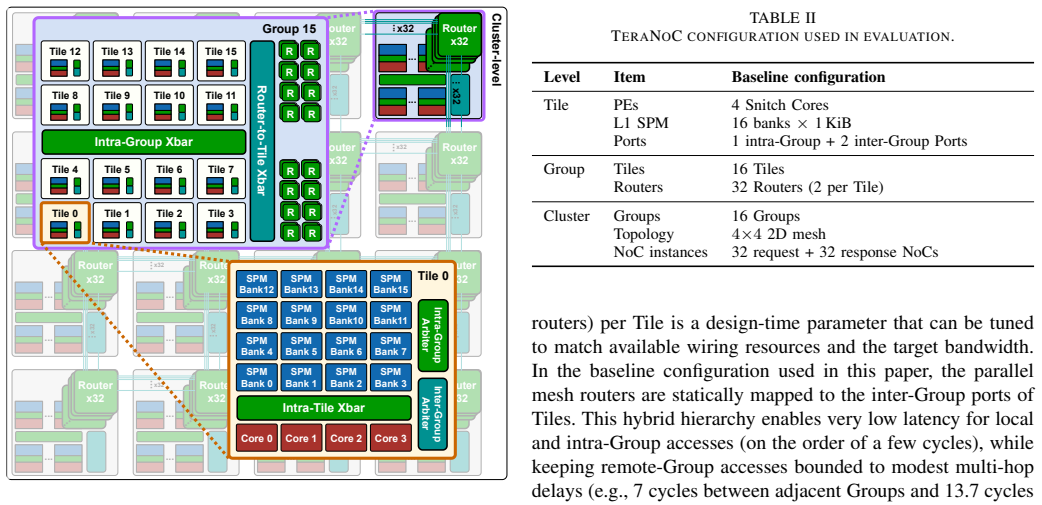
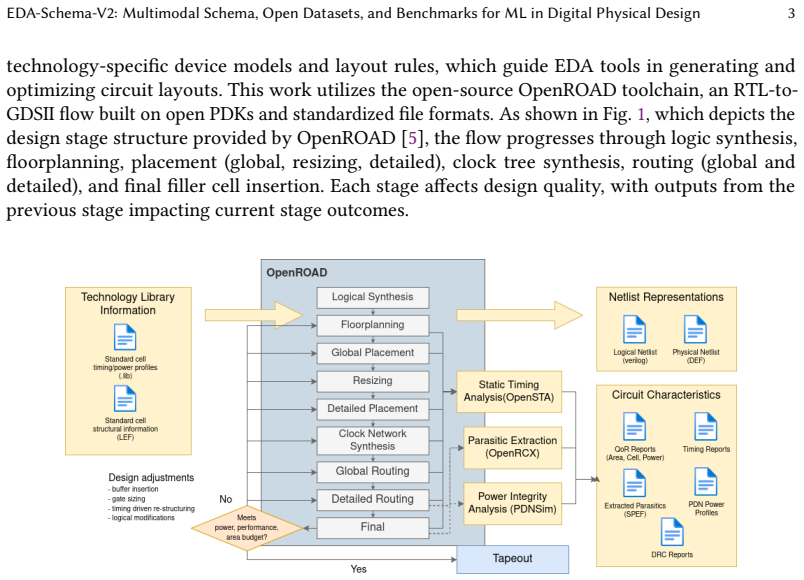
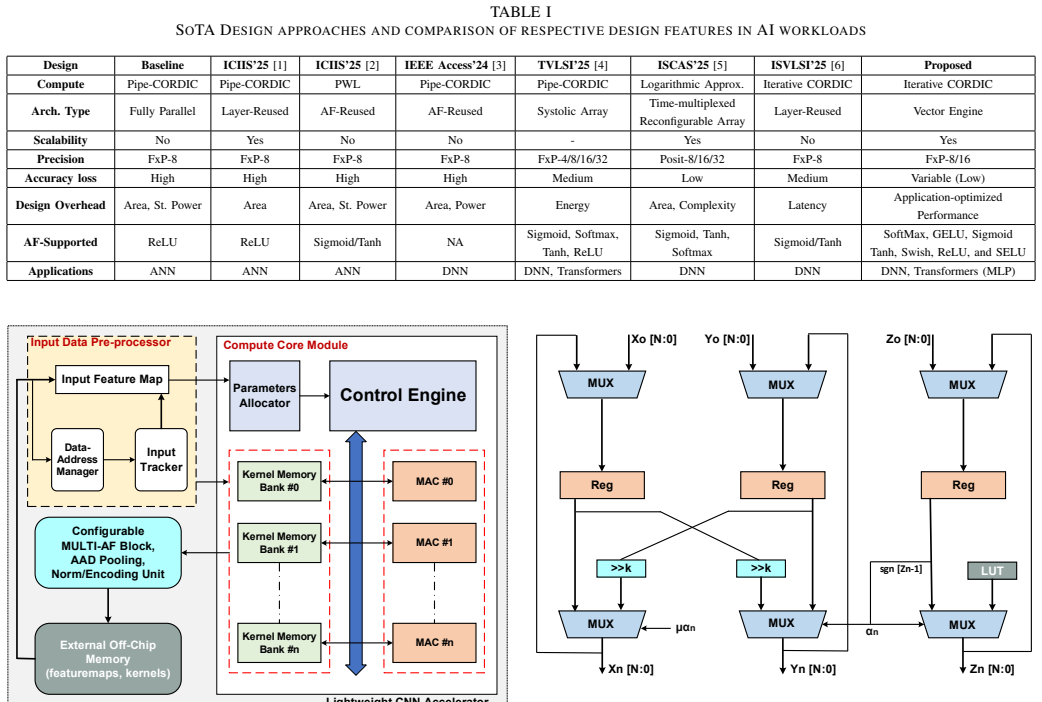
0
PoisonCap gives CHERI strict use-after-free at zero overhead
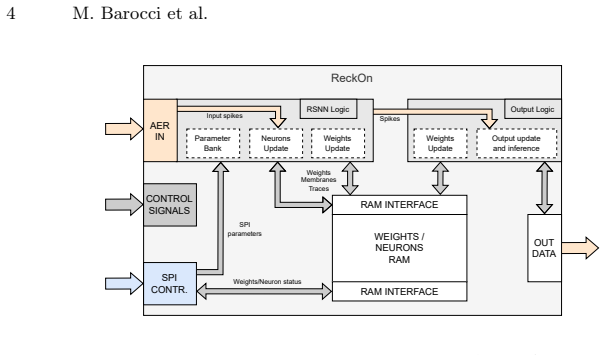
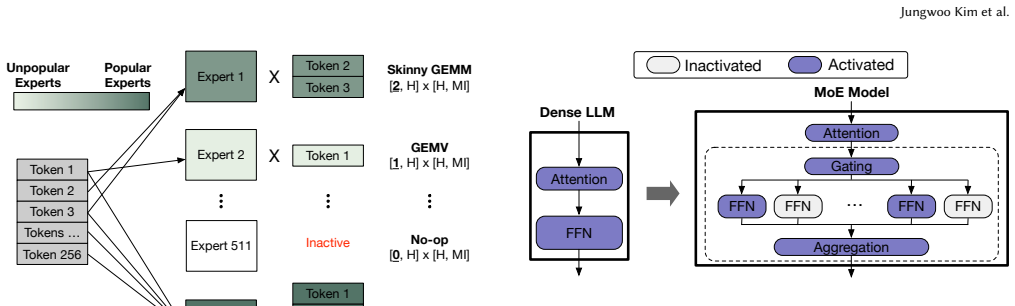
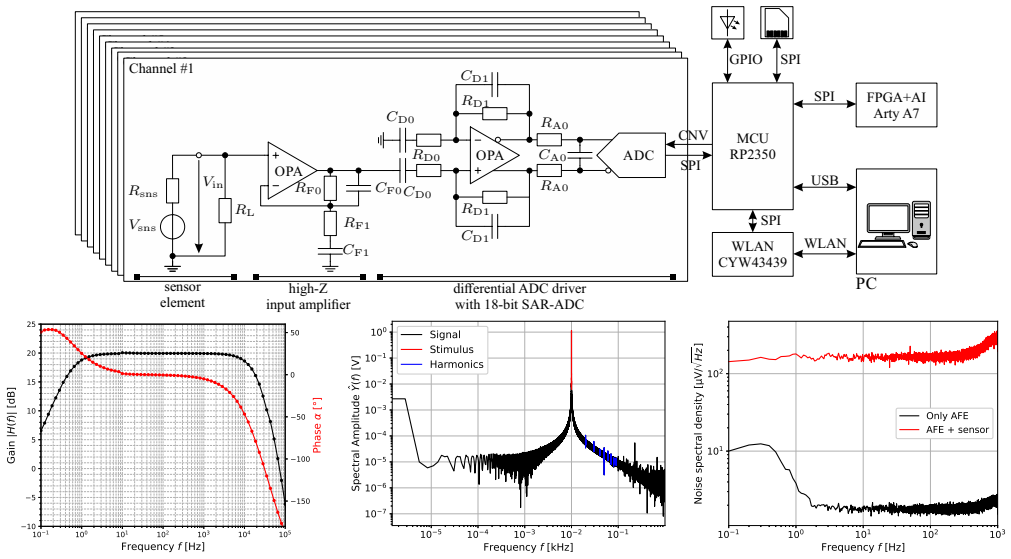
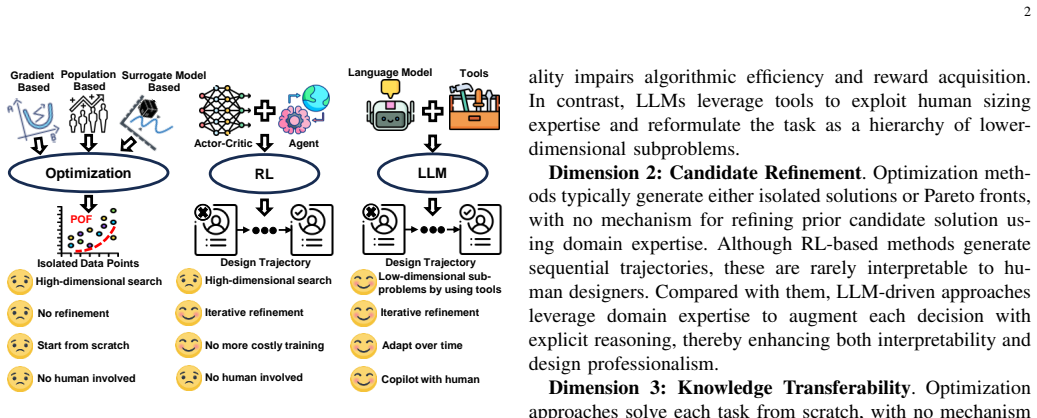
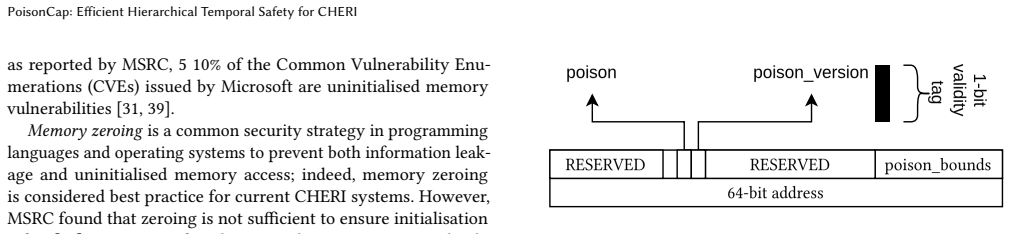
PoisonCap: Efficient Hierarchical Temporal Safety for CHERI
Poison capability format replaces shadow bitmaps, auto-zeros on reuse, and supports hierarchical delegation.
 full image
full image
abstract click to expand
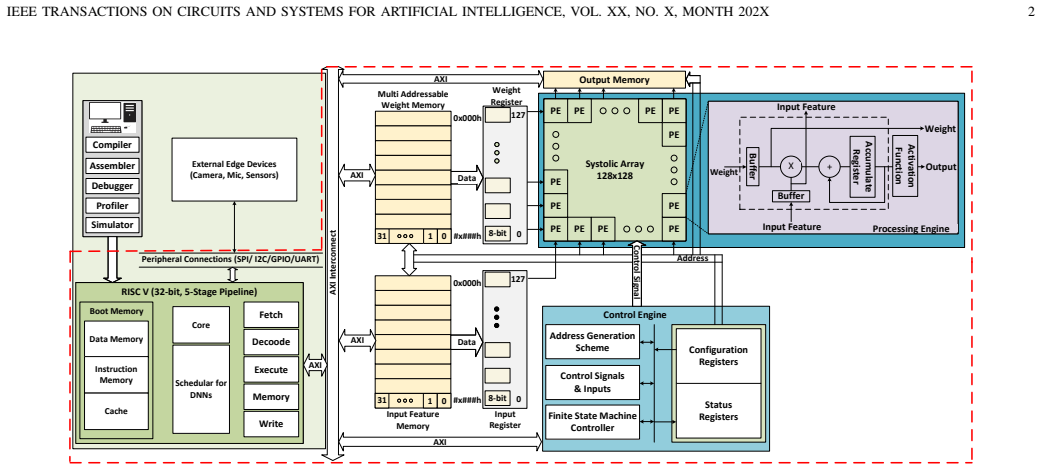
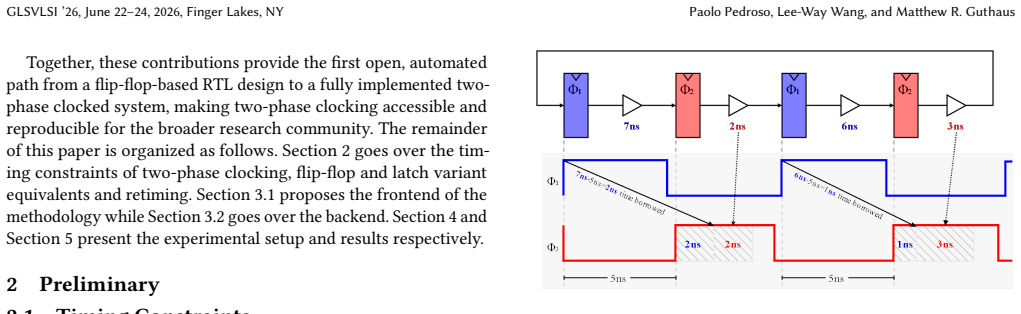
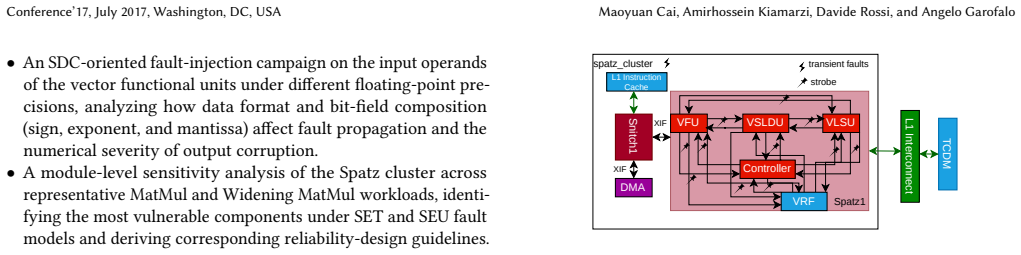
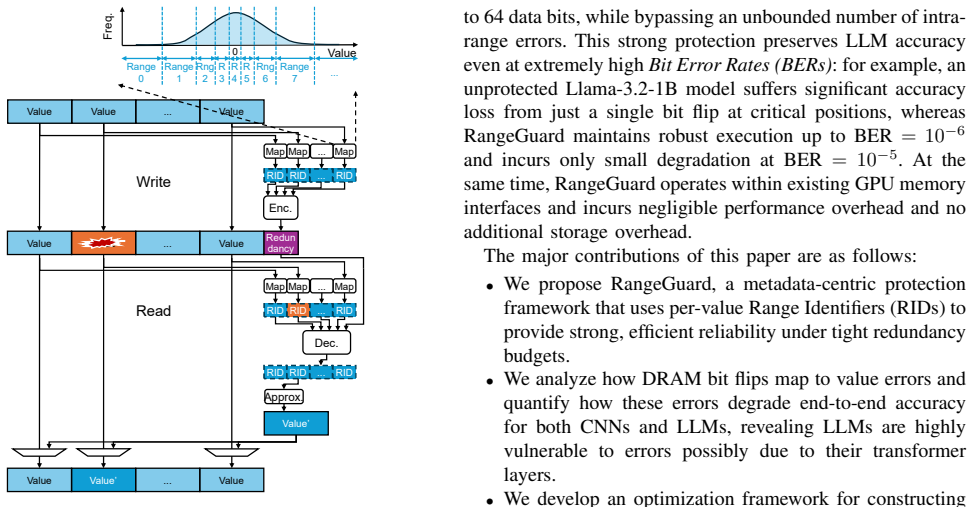
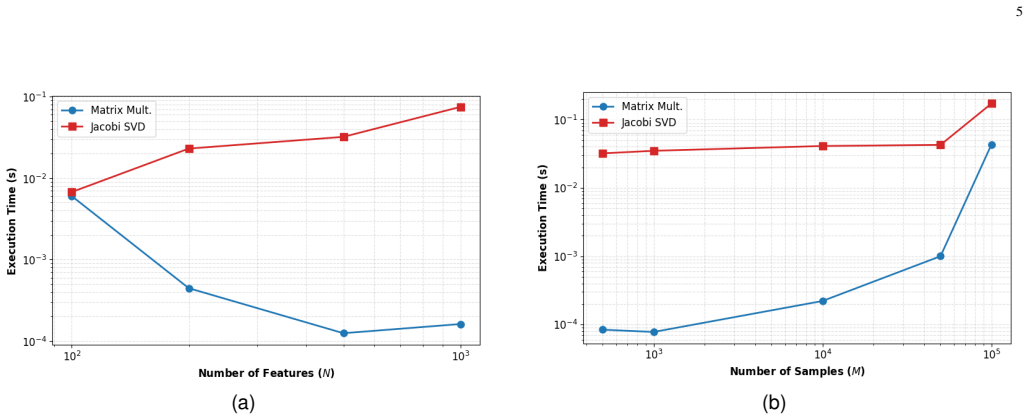
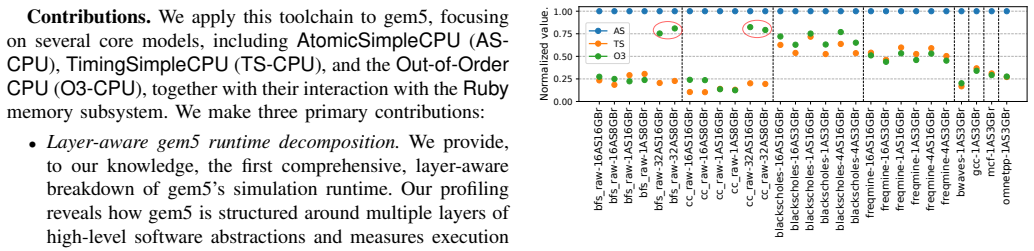
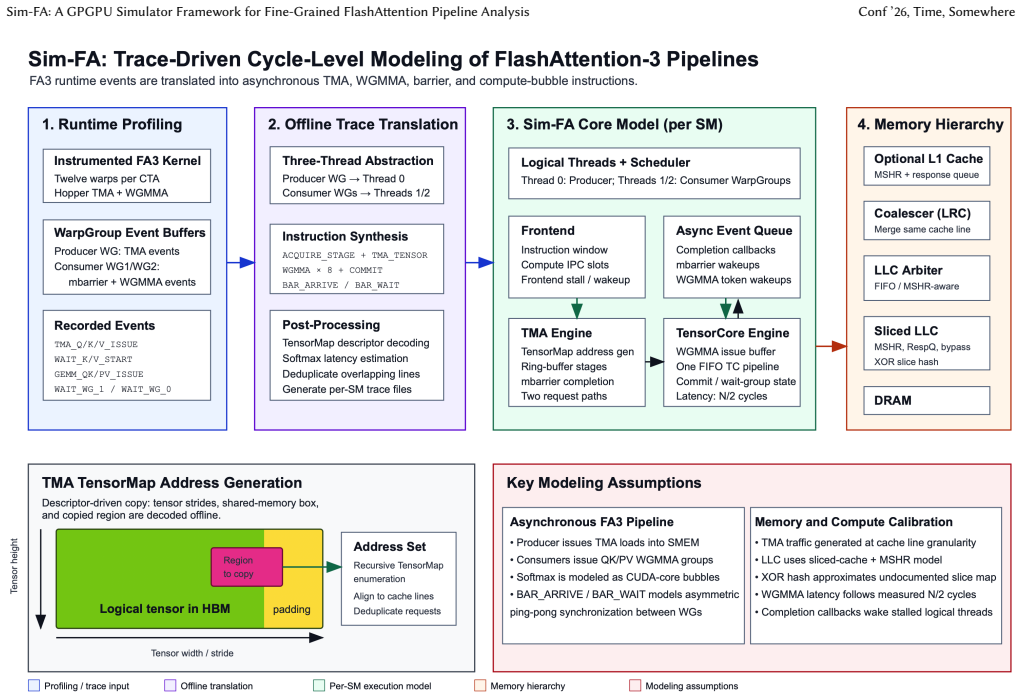
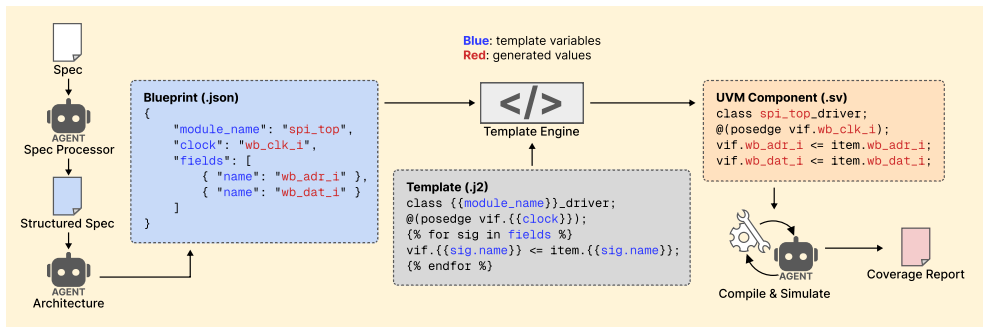
In this paper, we present PoisonCap: scalable temporal safety with strict use-after-free protection and initialisation safety for CHERI systems. Efficient memory safety is an increasing priority for programming languages, operating systems, and hardware designs, and CHERI is a leading hardware/software system that provides native spatial safety and a foundation for temporal memory safety. Cornucopia Reloaded, the current state-of-the-art CHERI temporal safety solution, provides use-after-reallocation safety instead of stronger use-after-free safety, and is not able to enforce initialisation safety. We show that a new 'poison' capability format can be used to enforce strict use-after-free and initialisation safety, and also to communicate memory state to the microarchitecture for efficient cache management of quarantined memory. We enable elegant delegation of memory poisoning privilege using capability bounds to allow nested allocators to enforce safety on their consumers without disturbing upstream allocators. PoisonCap can replace the Cornucopia shadow bitmap, and also automatically zeros memory on reallocation, or optionally traps on read-before-write to enforce initialisation safety. As a result, it incurs no fundamental overhead relative to a Cornucopia baseline that zeros before reallocation, strengthening CHERI temporal safety without performance overhead.