GrOCE:Graph-Guided Online Concept Erasure for Text-to-Image Diffusion Models
Pith reviewed 2026-05-17 22:20 UTC · model grok-4.3
The pith
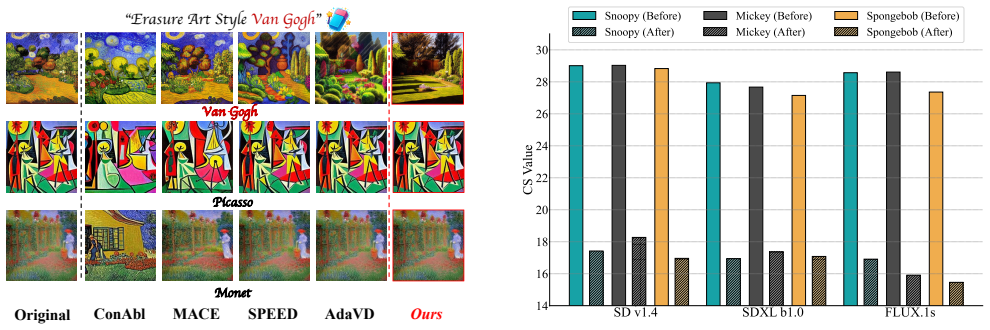
GrOCE removes target concepts from text-to-image diffusion models by building dynamic semantic graphs to isolate and suppress them in prompts without any retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GrOCE constructs a dynamic weighted graph over vocabulary concepts to capture semantic affinities, then uses multi-hop traversal and diffusion-based scoring to extract a target concept cluster, and finally severs the associated semantic components from the input prompt while preserving non-target elements and overall sentence structure.
What carries the argument
Dynamic semantic graph with incremental weighted edges, multi-hop traversal, and diffusion-based scoring to identify and isolate target concept clusters for selective severing.
If this is right
- Target concepts can be added or changed online without retraining the underlying diffusion model.
- Non-target semantics and global prompt structure remain intact during erasure.
- Performance improves on concept similarity and Fréchet Inception Distance metrics over prior erasure techniques.
- The process stays efficient and stable for evolving sets of unwanted concepts.
Where Pith is reading between the lines
- The same graph construction could be tested on text-to-video models by adding temporal links between frames.
- Prompts with ambiguous or overlapping concepts would show whether the scoring step cleanly separates clusters.
- Integration into user-facing tools might allow on-the-fly moderation for newly flagged content.
Load-bearing premise
That an incrementally built semantic graph plus multi-hop traversal and diffusion scoring can reliably find and suppress only the target concept clusters without harming unrelated meanings or the overall prompt structure.
What would settle it
Run the same mixed prompt containing both a target concept and unrelated concepts through the model before and after GrOCE; if generated images lose the target concept while retaining unrelated objects, style, and overall quality scores, the claim holds.
Figures




read the original abstract
Concept erasure aims to remove harmful, inappropriate, or copyrighted content from text-to-image diffusion models while preserving non-target semantics. However, existing methods either rely on costly fine-tuning or apply coarse semantic separation, often degrading unrelated concepts and lacking adaptability to evolving concept sets. In this paper, we propose Graph-Guided Online Concept Erasure (GrOCE), a training-free framework that performs precise and context-aware online removal of target concepts. GrOCE constructs dynamic semantic graphs to identify clusters of target concepts and selectively suppress their influence within text prompts. It consists of three synergistic components: (1) dynamic semantic graph construction (Construct) incrementally builds a weighted graph over vocabulary concepts to capture semantic affinities; (2) adaptive cluster identification (Identify) extracts a target concept cluster through multi-hop traversal and diffusion-based scoring to quantify semantic influence; and (3) selective severing (Sever) removes semantic components associated with the target cluster from the text prompt while retaining non-target semantics and the global sentence structure. Extensive experiments demonstrate that GrOCE achieves state-of-the-art performance on the Concept Similarity (CS) and Fr\'echet Inception Distance (FID) metrics, offering efficient, accurate, and stable concept erasure.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes GrOCE, a training-free framework for online concept erasure in text-to-image diffusion models. It constructs dynamic semantic graphs over vocabulary concepts to capture affinities (Construct), extracts target concept clusters via multi-hop traversal and diffusion-based scoring (Identify), and selectively removes associated semantic components from prompts while retaining non-target semantics and global structure (Sever). The authors claim that the three synergistic components enable state-of-the-art performance on Concept Similarity (CS) and Fréchet Inception Distance (FID) metrics.
Significance. If the central claims hold, GrOCE would offer a meaningful advance by providing an efficient, fully online and training-free alternative to fine-tuning-based erasure methods, with potential advantages in adaptability to evolving concept sets and reduced degradation of unrelated semantics.
major comments (2)
- The soundness of the central claim rests on the Identify component's multi-hop traversal plus diffusion-based scoring reliably isolating only the target concept cluster without side effects on adjacent concepts. The manuscript provides no concrete definition or pseudocode for the diffusion-based scoring function, nor any ablation isolating its contribution, leaving the training-free isolation assumption unverified.
- Abstract and experimental claims: the assertion of SOTA results on CS and FID is presented without reference to specific baselines, dataset splits, number of concepts tested, or statistical significance, making it impossible to evaluate whether the reported gains are attributable to the graph-guided approach or to unstated implementation choices.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below, providing clarifications and committing to revisions that strengthen the presentation of the Identify component and the experimental claims.
read point-by-point responses
-
Referee: The soundness of the central claim rests on the Identify component's multi-hop traversal plus diffusion-based scoring reliably isolating only the target concept cluster without side effects on adjacent concepts. The manuscript provides no concrete definition or pseudocode for the diffusion-based scoring function, nor any ablation isolating its contribution, leaving the training-free isolation assumption unverified.
Authors: We agree that additional detail on the diffusion-based scoring function is warranted to fully verify the isolation assumption. Section 3.2 describes the multi-hop traversal and scoring process at a high level, but we will add an explicit mathematical definition of the diffusion-based scoring function along with pseudocode in the revised manuscript. We will also include a new ablation study that isolates the contribution of this scoring mechanism, demonstrating its effect on cluster purity and absence of side effects on adjacent concepts. revision: yes
-
Referee: Abstract and experimental claims: the assertion of SOTA results on CS and FID is presented without reference to specific baselines, dataset splits, number of concepts tested, or statistical significance, making it impossible to evaluate whether the reported gains are attributable to the graph-guided approach or to unstated implementation choices.
Authors: We acknowledge that the abstract would benefit from greater specificity to allow direct evaluation of the SOTA claims. While Section 4 already details the experimental setup, baselines, and metrics, we will revise the abstract to explicitly reference the compared baselines, the number of target concepts evaluated, dataset splits used, and any statistical significance testing performed on the CS and FID improvements. This will clarify that gains are attributable to the graph-guided components rather than implementation details. revision: yes
Circularity Check
No circularity: algorithmic framework is self-contained
full rationale
The paper presents GrOCE as a training-free algorithmic pipeline with three explicit components—dynamic semantic graph construction from vocabulary affinities, multi-hop traversal plus diffusion-based scoring for cluster identification, and selective severing of target semantics—without any equations, fitted parameters, or predictions that reduce to their own inputs by construction. Performance is evaluated via external metrics (CS, FID) on experiments rather than derived from a closed loop. No self-citation load-bearing uniqueness theorems, ansatzes smuggled via prior work, or renaming of known results appear in the described derivation chain. The method is presented as a novel composition of standard graph and diffusion operations, making the central claims independent of the inputs.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Adaptive Cluster Identification performs multi-hop traversal with similarity decay to identify semantically entangled concepts... h=exp(−tL)v_c∗
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Dynamic Topological Graph Construction... τ_ij = τ_0 + λ·variance
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Disentangled Anatomy-Disease Diffusion (DADD) for Controllable Ulcerative Colitis Progression Synthesis
DADD disentangles anatomy and disease in a latent diffusion model using a Feature Purifier, ordinal disease embeddings, and Delta Steering to synthesize controllable ulcerative colitis progression images.
Reference graph
Works this paper leans on
-
[1]
Nora Belrose, David Schneider-Joseph, Shauli Ravfogel, Ryan Cotterell, Edward Raff, and Stella Biderman. Leace: Perfect linear concept erasure in closed form.Advances in Neural Information Processing Systems, 36:66044–66063,
-
[2]
Ace: Attentional concept erasure in diffusion models.arXiv preprint arXiv:2504.11850, 2025
Finn Carter. Ace: Attentional concept erasure in diffusion models.arXiv preprint arXiv:2504.11850, 2025. 3
-
[3]
Ruidong Chen, Honglin Guo, Lanjun Wang, Chenyu Zhang, Weizhi Nie, and An-An Liu. Trce: Towards reliable ma- licious concept erasure in text-to-image diffusion models. arXiv preprint arXiv:2503.07389, 2025. 3
-
[4]
Nvidia a100 tensor core gpu: Performance and innovation.IEEE Micro, 41(2):29–35,
Jack Choquette, Wishwesh Gandhi, Olivier Giroux, Nick Stam, and Ronny Krashinsky. Nvidia a100 tensor core gpu: Performance and innovation.IEEE Micro, 41(2):29–35,
-
[5]
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis.Advances in neural informa- tion processing systems, 34:8780–8794, 2021. 1
work page 2021
-
[6]
Chongyu Fan, Jiancheng Liu, Yihua Zhang, Eric Wong, Den- nis Wei, and Sijia Liu. Salun: Empowering machine unlearn- ing via gradient-based weight saliency in both image classi- fication and generation.arXiv preprint arXiv:2310.12508,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Erasing concepts from diffusion models
Rohit Gandikota, Joanna Materzynska, Jaden Fiotto- Kaufman, and David Bau. Erasing concepts from diffusion models. InProceedings of the IEEE/CVF international con- ference on computer vision, pages 2426–2436, 2023. 1, 3
work page 2023
-
[8]
Unified concept editing in diffusion models
Rohit Gandikota, Hadas Orgad, Yonatan Belinkov, Joanna Materzy´nska, and David Bau. Unified concept editing in diffusion models. InProceedings of the IEEE/CVF Win- ter Conference on Applications of Computer Vision, pages 5111–5120, 2024. 1, 3
work page 2024
-
[9]
Eraseanything: Enabling concept erasure in rectified flow transformers
Daiheng Gao, Shilin Lu, Wenbo Zhou, Jiaming Chu, Jie Zhang, Mengxi Jia, Bang Zhang, Zhaoxin Fan, and Weiming Zhang. Eraseanything: Enabling concept erasure in rectified flow transformers. InForty-second International Conference on Machine Learning, 2025. 3
work page 2025
-
[10]
Reliable and efficient concept erasure of text-to- image diffusion models
Chao Gong, Kai Chen, Zhipeng Wei, Jingjing Chen, and Yu- Gang Jiang. Reliable and efficient concept erasure of text-to- image diffusion models. InEuropean Conference on Com- puter Vision, pages 73–88, 2024. 3
work page 2024
-
[11]
Dumo: Dual encoder modula- tion network for precise concept erasure
Feng Han, Kai Chen, Chao Gong, Zhipeng Wei, Jingjing Chen, and Yu-Gang Jiang. Dumo: Dual encoder modula- tion network for precise concept erasure. InProceedings of the AAAI Conference on Artificial Intelligence, pages 3320– 3328, 2025. 2
work page 2025
-
[12]
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilib- rium.Advances in Neural Information Processing Systems, 30, 2017. 6
work page 2017
-
[13]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020. 1
work page 2020
-
[14]
Ablating con- cepts in text-to-image diffusion models
Nupur Kumari, Bingliang Zhang, Sheng-Yu Wang, Eli Shechtman, Richard Zhang, and Jun-Yan Zhu. Ablating con- cepts in text-to-image diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 22691–22702, 2023. 1, 2, 5
work page 2023
-
[15]
Flux.https://github.com/ black-forest-labs/flux, 2024
Black Forest Labs. Flux.https://github.com/ black-forest-labs/flux, 2024. 8
work page 2024
-
[16]
Flux.1 kontext: Flow matching for in-context image generation and editing in latent space,
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dock- horn, Jack English, Zion English, Patrick Esser, Sumith Ku- lal, Kyle Lacey, Yam Levi, Cheng Li, Dominik Lorenz, Jonas M¨uller, Dustin Podell, Robin Rombach, Harry Saini, Axel Sauer, and Luke Smith. Flux.1 kontext: Flow matching for in-context i...
-
[17]
Byung Hyun Lee, Sungjin Lim, Seunggyu Lee, Dong Un Kang, and Se Young Chun. Concept pinpoint eraser for text- to-image diffusion models via residual attention gate.arXiv preprint arXiv:2506.22806, 2025. 1
-
[18]
Auditing image-based nsfw classifiers for content filtering
Warren Leu, Yuta Nakashima, and Noa Garcia. Auditing image-based nsfw classifiers for content filtering. InPro- ceedings of the ACM Conference on Fairness, Accountabil- ity, and Transparency, pages 1163–1173, 2024. 1
work page 2024
-
[19]
Ouxiang Li, Yuan Wang, Xinting Hu, Houcheng Jiang, Tao Liang, Yanbin Hao, Guojun Ma, and Fuli Feng. Speed: Scal- able, precise, and efficient concept erasure for diffusion mod- els.arXiv preprint arXiv:2503.07392, 2025. 3, 5
-
[20]
Get what you want, not what you don’t: Image content suppression for text-to-image diffusion models
Senmao Li, Joost van de Weijer, Taihang Hu, Fahad Shahbaz Khan, Qibin Hou, Yaxing Wang, and Jian Yang. Get what you want, not what you don’t: Image content suppression for text-to-image diffusion models. InThe Twelfth International Conference on Learning Representations, 2024. 3
work page 2024
-
[21]
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. Dpm-solver: A fast ode solver for diffu- sion probabilistic model sampling in around 10 steps.Ad- vances in neural information processing systems, 35:5775– 5787, 2022. 5
work page 2022
-
[22]
Mace: Mass concept erasure in diffu- sion models
Shilin Lu, Zilan Wang, Leyang Li, Yanzhu Liu, and Adams Wai-Kin Kong. Mace: Mass concept erasure in diffu- sion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6430– 6440, 2024. 1, 5
work page 2024
-
[23]
One-dimensional adapter to rule them all: Concepts diffusion models and erasing applications
Mengyao Lyu, Yuhong Yang, Haiwen Hong, Hui Chen, Xuan Jin, Yuan He, Hui Xue, Jungong Han, and Guiguang Ding. One-dimensional adapter to rule them all: Concepts diffusion models and erasing applications. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7559–7568, 2024. 1, 3
work page 2024
-
[24]
Glide: Towards photorealistic image genera- tion and editing with text-guided diffusion models
Alex Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob McGrew, Ilya Sutskever, and Mark Chen. Glide: Towards photorealistic image genera- tion and editing with text-guided diffusion models. InIn- ternational Conference on Machine Learning, pages 28759– 28768, 2022. 1
work page 2022
-
[25]
How to blend concepts in diffusion models
Lorenzo Olearo, Giorgio Longari, Simone Melzi, Alessan- dro Raganato, and Rafael Pe ˜naloza. How to blend concepts in diffusion models. InProceedings of The Eighth Image Schema Day co-located with The 23rd International Con- ference of the Italian Association for Artificial Intelligence, pages 1–13, 2024. 3
work page 2024
-
[26]
Editing implicit assumptions in text-to-image diffusion models
Hadas Orgad, Bahjat Kawar, and Yonatan Belinkov. Editing implicit assumptions in text-to-image diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 7053–7061, 2023. 2
work page 2023
-
[27]
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An im- perative style, high-performance deep learning library.Ad- vances in neural information processing systems, 32, 2019. 5
work page 2019
-
[28]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763, 2021. 5
work page 2021
-
[29]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10684–10695, 2022. 8
work page 2022
-
[30]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 1, 3, 5
work page 2022
-
[31]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution im- age synthesis with latent diffusion models.arXiv preprint arXiv:2307.01952, 2023. 8
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Safe latent diffusion: Mitigating inappro- priate degeneration in diffusion models
Patrick Schramowski, Manuel Brack, Bj ¨orn Deiseroth, and Kristian Kersting. Safe latent diffusion: Mitigating inappro- priate degeneration in diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22522–22531, 2023. 2
work page 2023
-
[33]
Deep unsupervised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. InInternational confer- ence on machine learning, pages 2256–2265. pmlr, 2015. 1
work page 2015
-
[34]
Diffusion models encode the in- trinsic dimension of data manifolds
Jan Pawel Stanczuk, Georgios Batzolis, Teo Deveney, and Carola-Bibiane Sch¨onlieb. Diffusion models encode the in- trinsic dimension of data manifolds. InForty-first Interna- tional Conference on Machine Learning, 2024. 3
work page 2024
-
[35]
Precise, fast, and low- cost concept erasure in value space: Orthogonal complement matters
Yuan Wang, Ouxiang Li, Tingting Mu, Yanbin Hao, Kuien Liu, Xiang Wang, and Xiangnan He. Precise, fast, and low- cost concept erasure in value space: Orthogonal complement matters. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 28759–28768, 2025. 2, 3, 5, 6
work page 2025
-
[36]
Focal modulation networks.Advances in Neural Information Processing Systems, 35:4203–4217, 2022
Jianwei Yang, Chunyuan Li, Xiyang Dai, and Jianfeng Gao. Focal modulation networks.Advances in Neural Information Processing Systems, 35:4203–4217, 2022. 3
work page 2022
-
[37]
Sneakyprompt: Jailbreaking text-to-image generative models
Yuchen Yang, Bo Hui, Haolin Yuan, Neil Gong, and Yinzhi Cao. Sneakyprompt: Jailbreaking text-to-image generative models. InIEEE Symposium on Security and Privacy, pages 897–912, 2024. 1
work page 2024
-
[38]
Yaopei Zeng, Yuanpu Cao, Bochuan Cao, Yurui Chang, Jinghui Chen, and Lu Lin. Advi2i: Adversarial image at- tack on image-to-image diffusion models.arXiv preprint arXiv:2410.21471, 2024. 1
-
[39]
Guangzi Zhang, Yulin Qian, Juntao Deng, and Xingquan Cai. Inv-reversion: Enhanced relation inversion based on text-to-image diffusion models.Applied Sciences, 14(8): 3338, 2024. 3
work page 2024
-
[40]
Forget-me-not: Learning to for- get in text-to-image diffusion models
Gong Zhang, Kai Wang, Xingqian Xu, Zhangyang Wang, and Humphrey Shi. Forget-me-not: Learning to for- get in text-to-image diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1755–1764, 2024. 3
work page 2024
-
[41]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF international conference on computer vision, pages 3836–3847, 2023. 1
work page 2023
-
[42]
Yimeng Zhang, Xin Chen, Jinghan Jia, Yihua Zhang, Chongyu Fan, Jiancheng Liu, Mingyi Hong, Ke Ding, and Sijia Liu. Defensive unlearning with adversarial training for robust concept erasure in diffusion models.Advances in neu- ral information processing systems, 37:36748–36776, 2024. 3
work page 2024
-
[43]
Xin Zhao, Xiaojun Chen, Yuexin Xuan, Zhendong Zhao, Xi- aojun Jia, Xinfeng Li, and Xiaofeng Wang. Buster: Implant- ing semantic backdoor into text encoder to mitigate nsfw content generation.arXiv preprint arXiv:2412.07249, 2024. 1
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.