Can Vision-Language Models Count? A Synthetic Benchmark and Analysis of Attention-Based Interventions
Pith reviewed 2026-05-17 20:01 UTC · model grok-4.3
The pith
Vision-language models count less accurately as visual and linguistic complexity rises, though targeted attention reweighting in the language decoder can strengthen grounding of quantity concepts to visual features.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Using controlled synthetic images and prompts, the authors establish that VLM counting accuracy degrades systematically with rising numbers of objects, variations in color and texture, and greater prompt specificity. Exploratory attention reweighting in the language model decoder yields modest but measurable improvements by influencing how models connect linguistic quantity concepts to visual representations.
What carries the argument
Synthetic benchmark with perturbations across object number, color, texture, background, and prompt specificity, combined with attention reweighting operations applied to visual tokens in the language decoder layers.
If this is right
- Accuracy falls as the number of objects or visual variations such as color and texture increase.
- More specific linguistic prompts produce corresponding drops in correct enumeration.
- Reweighting attention to visual tokens at selected decoder layers shifts counting outputs in measurable ways.
- Many errors trace to cross-modal binding rather than isolated visual processing deficits.
- The controlled perturbations expose failure modes that natural-image benchmarks do not isolate easily.
Where Pith is reading between the lines
- Similar layer-specific reweighting could be tested on other visual reasoning tasks such as spatial relations or attribute matching.
- The patterns suggest training-data biases contribute to quantity errors and may be addressable through decoder adjustments rather than full retraining.
- Extending the benchmark to overlapping objects or dynamic scenes would test whether the same degradation and intervention effects persist.
- The framework offers a way to compare model enumeration limits directly against human cognitive-load studies using matched stimuli.
Load-bearing premise
The synthetic perturbations and attention reweighting operations isolate the intended cross-modal binding failures without introducing new artifacts that would not appear in natural images.
What would settle it
Applying the same attention reweighting to the benchmark and finding no consistent change in counting accuracy as object numbers or prompt specificity increase would falsify the central claims about degradation and intervention effects.
Figures




read the original abstract
Recent research suggests that Vision Language Models (VLMs) often rely on inherent biases learned during training when responding to queries about visual properties of images. These biases are exacerbated when VLMs are asked highly specific questions that require selective visual attention, a demand that mirrors cognitive challenges observed in human enumeration tasks. We build upon this research by developing a synthetic benchmark dataset and evaluation framework to systematically characterize how counting performance varies as image and prompt properties change. Using open-source VLMs, we analyze how performance shifts across controlled perturbations (e.g. number of objects, object color, background color, object texture, background texture, and prompt specificity) and examine corresponding changes in visual attention allocation. We further conduct exploratory attention reweighting experiments in the language model decoder to modulate focus on visual tokens at different layers and assess their effects on counting behavior. Our results reveal that counting accuracy degrades systematically with increasing visual and linguistic complexity echoing human limits and cognitive load effects known from human perception, while targeted attention reweighting yields modest but measurable improvements. Rather than competing on benchmark accuracy, we introduce a controlled diagnostic framework for analyzing VLM enumeration behavior. Through systematic experiments, we expose failure modes rooted in cross-modal binding that natural image benchmarks may not easily isolate, and provide preliminary empirical evidence that targeted attention reweighting in the language decoder can influence how models ground linguistic quantity concepts in visual representations. Code and data available here: https://github.com/ssen7/vlm-count-analysis
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a synthetic benchmark and evaluation framework to characterize counting performance in open-source vision-language models under controlled perturbations of visual properties (object count, color, texture, background) and linguistic factors (prompt specificity). It examines corresponding shifts in visual attention allocation and conducts exploratory attention reweighting interventions in the language decoder layers to modulate focus on visual tokens. Key results indicate systematic accuracy degradation with rising visual and linguistic complexity, mirroring human cognitive load effects, alongside modest measurable gains from the reweighting approach. The work positions itself as a diagnostic tool for cross-modal binding failures rather than a new accuracy benchmark, with code and data released.
Significance. If the central empirical trends hold under stronger controls, the synthetic diagnostic framework would provide a useful complement to natural-image benchmarks by isolating factors that affect enumeration and cross-modal grounding in VLMs. The attention analysis and preliminary reweighting results offer mechanistic insights that could guide future inference-time interventions or architectural changes for quantity reasoning. Reproducibility is supported by the public code and data release.
major comments (1)
- [Attention reweighting experiments] Attention reweighting experiments (abstract and corresponding results section): the manuscript reports modest counting gains from targeted reweighting at different decoder layers but does not present control ablations such as uniform scaling of all visual tokens, reweighting of non-visual tokens, or random position/magnitude shifts matched to the intervention strength. Without these, the results do not yet isolate effects specific to quantity-concept grounding from generic changes in token salience or decoder dynamics, weakening support for the claim that the operation influences cross-modal binding for linguistic quantity concepts.
minor comments (2)
- [Abstract] Abstract: the summary of results mentions 'modest but measurable improvements' and 'systematic degradation' without numerical magnitudes, error bars, or reference to statistical tests; adding these details would improve clarity and allow readers to assess effect sizes directly.
- [Benchmark construction] The weakest assumption noted in the stress-test (synthetic perturbations isolating intended binding failures without new artifacts) is not explicitly tested or discussed in the manuscript; a brief validation against a small set of natural images or artifact checks would strengthen the framework's claims.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. We appreciate the positive assessment of the synthetic benchmark's diagnostic value and the attention analysis. We address the single major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: Attention reweighting experiments (abstract and corresponding results section): the manuscript reports modest counting gains from targeted reweighting at different decoder layers but does not present control ablations such as uniform scaling of all visual tokens, reweighting of non-visual tokens, or random position/magnitude shifts matched to the intervention strength. Without these, the results do not yet isolate effects specific to quantity-concept grounding from generic changes in token salience or decoder dynamics, weakening support for the claim that the operation influences cross-modal binding for linguistic quantity concepts.
Authors: We agree that the current set of experiments would benefit from additional controls to better isolate whether the observed gains stem specifically from enhanced cross-modal binding for quantity concepts rather than generic alterations in token salience or decoder behavior. Our reweighting experiments were presented as exploratory, with the goal of providing preliminary evidence that targeted interventions in the language decoder can measurably affect counting performance. To address the concern, we will add control ablations in the revised manuscript, including (1) uniform scaling applied to all visual tokens and (2) random position/magnitude perturbations matched in strength to the targeted interventions. These will be reported alongside the existing results to clarify the specificity of the effects. We believe this will strengthen support for the mechanistic interpretation without altering the core claims of the work. revision: yes
Circularity Check
No circularity: purely empirical measurements on synthetic data
full rationale
The paper conducts controlled experiments on a synthetic benchmark, directly measuring counting accuracy against ground-truth object counts under perturbations of visual and linguistic factors. Attention reweighting is applied as an exploratory intervention with reported effects on performance. No derivations, equations, fitted parameters renamed as predictions, or self-referential steps appear in the described framework. Results are evaluated externally against the synthetic ground truth, rendering the analysis self-contained without any reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We further conduct exploratory attention reweighting experiments in the language model decoder to modulate focus on visual tokens at different layers and assess their effects on counting behavior.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
CounterCount: A Diagnostic Framework for Counting Bias in Vision Language Models
CounterCount shows VLMs perform well on factual counting images but degrade on counterfactual edits, revealing reliance on object priors, and introduces an attention reweighting method that improves accuracy by up to 8%.
-
PushupBench: Your VLM is not good at counting pushups
VLMs reach only 42.1% exact accuracy on counting pushups in videos, with weaker models exploiting modal counts, and 1k-sample fine-tuning transfers gains to MVBench, PerceptionTest, and TVBench.
Reference graph
Works this paper leans on
-
[1]
[de— re] constructing vlms’ reasoning in counting.arXiv preprint arXiv:2510.19555, 2025
Simone Alghisi, Gabriel Roccabruna, Massimo Rizzoli, Seyed Mahed Mousavi, and Giuseppe Riccardi. [de— re] constructing vlms’ reasoning in counting.arXiv preprint arXiv:2510.19555, 2025. 1, 2
-
[2]
Niki Amini-Naieni, Tengda Han, and Andrew Zisserman. Countgd: Multi-modal open-world counting.Advances in Neural Information Processing Systems, 37:48810–48837,
-
[3]
Wenbin An, Feng Tian, Sicong Leng, Jiahao Nie, Haonan Lin, QianYing Wang, Ping Chen, Xiaoqin Zhang, and Shi- jian Lu. Mitigating object hallucinations in large vision- language models with assembly of global and local attention. InProceedings of the Computer Vision and Pattern Recogni- tion Conference, pages 29915–29926, 2025. 2
work page 2025
-
[4]
Generic attention- model explainability for interpreting bi-modal and encoder- decoder transformers
Hila Chefer, Shir Gur, and Lior Wolf. Generic attention- model explainability for interpreting bi-modal and encoder- decoder transformers. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision (ICCV), pages 397–406, 2021. 1
work page 2021
-
[5]
Internvl: Scaling up vision foundation mod- els and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation mod- els and aligning for generic visual-linguistic tasks. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24185–24198, 2024. 1
work page 2024
-
[6]
Lianghan Dong and Anamaria Crisan. Probing the visualiza- tion literacy of vision language models: the good, the bad, and the ugly.arXiv preprint arXiv:2504.05445, 2025. 2
-
[7]
Google deepmind: Gemini 2.5 pro, 2025.https: //deepmind.google/models/gemini/pro/
Google. Google deepmind: Gemini 2.5 pro, 2025.https: //deepmind.google/models/gemini/pro/. 2
work page 2025
-
[8]
Xuyang Guo, Zekai Huang, Zhenmei Shi, Zhao Song, and Ji- ahao Zhang. Your vision-language model can’t even count to 20: Exposing the failures of vlms in compositional counting. arXiv preprint arXiv:2510.04401, 2025. 1, 2
-
[9]
Kaiming He, Georgia Gkioxari, Piotr Doll ´ar, and Ross Gir- shick. Mask r-cnn. InProceedings of the IEEE international conference on computer vision, pages 2961–2969, 2017. 4
work page 2017
-
[10]
Do vision- language models really understand visual language? arXiv preprint arXiv:2410.00193,
Yifan Hou, Buse Giledereli, Yilei Tu, and Mrinmaya Sachan. Do vision-language models really understand visual lan- guage?arXiv preprint arXiv:2410.00193, 2024. 2
-
[11]
Point segment and count: A gener- alized framework for object counting
Zhizhong Huang, Mingliang Dai, Yi Zhang, Junping Zhang, and Hongming Shan. Point segment and count: A gener- alized framework for object counting. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17067–17076, 2024. 1
work page 2024
-
[12]
Seil Kang, Jinyeong Kim, Junhyeok Kim, and Seong Jae Hwang. See what you are told: Visual attention sink in large multimodal models.arXiv preprint arXiv:2503.03321, 2025. 2
-
[13]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C Berg, Wan-Yen Lo, et al. Segment any- thing. InProceedings of the IEEE/CVF international confer- ence on computer vision, pages 4015–4026, 2023. 4
work page 2023
-
[14]
Chunyuan Li, Cliff Wong, Sheng Zhang, Naoto Usuyama, Haotian Liu, Jianwei Yang, et al
Kang-il Lee, Minbeom Kim, Seunghyun Yoon, Minsung Kim, Dongryeol Lee, Hyukhun Koh, and Kyomin Jung. Vlind-bench: Measuring language priors in large vision- language models.arXiv preprint arXiv:2406.08702, 2024. 2
-
[15]
Tony Lee, Haoqin Tu, Chi H Wong, Wenhao Zheng, Yiyang Zhou, Yifan Mai, Josselin S Roberts, Michihiro Yasunaga, Huaxiu Yao, Cihang Xie, et al. Vhelm: A holistic evaluation of vision language models.Advances in Neural Information Processing Systems, 37:140632–140666, 2024. 2
work page 2024
-
[16]
Open ai: Introducing openai o3 and o4-mini, 2025
OpenAI. Open ai: Introducing openai o3 and o4-mini, 2025. https://openai.com/index/introducing-o3- and-o4-mini/. 2
work page 2025
-
[17]
Crowd- diff: Multi-hypothesis crowd density estimation using dif- fusion models
Yasiru Ranasinghe, Nithin Gopalakrishnan Nair, Wele Gedara Chaminda Bandara, and Vishal M Patel. Crowd- diff: Multi-hypothesis crowd density estimation using dif- fusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12809– 12819, 2024. 1
work page 2024
-
[18]
Ji Seung Ryu, Hyunyoung Kang, Yuseong Chu, and Sejung Yang. Vision-language foundation models for medical imag- ing: a review of current practices and innovations.Biomedi- cal Engineering Letters, pages 1–22, 2025. 1
work page 2025
-
[19]
Large VLM-based Vision-Language-Action Models for Robotic Manipulation: A Survey
Rui Shao, Wei Li, Lingsen Zhang, Renshan Zhang, Zhiyang Liu, Ran Chen, and Liqiang Nie. Large vlm-based vision- language-action models for robotic manipulation: A survey. arXiv preprint arXiv:2508.13073, 2025. 1
work page internal anchor Pith review arXiv 2025
-
[20]
Kimi Team, Angang Du, Bohong Yin, Bowei Xing, Bowen Qu, Bowen Wang, Cheng Chen, Chenlin Zhang, Chen- zhuang Du, Chu Wei, Congcong Wang, Dehao Zhang, Dikang Du, Dongliang Wang, Enming Yuan, Enzhe Lu, Fang Li, Flood Sung, Guangda Wei, Guokun Lai, Han Zhu, Hao Ding, Hao Hu, Hao Yang, Hao Zhang, Haoning Wu, Hao- tian Yao, Haoyu Lu, Heng Wang, Hongcheng Gao, H...
work page 2025
- [21]
-
[22]
Vi- sion language models are biased, 2025
An V o, Khai-Nguyen Nguyen, Mohammad Reza Taesiri, Vy Tuong Dang, Anh Totti Nguyen, and Daeyoung Kim. Vi- sion language models are biased, 2025. 2 9 Can Vision-Language Models Count? A Synthetic Benchmark and Analysis of Attention-Based Interventions Supplementary Material
work page 2025
-
[23]
Layer-wise Propagation of Visual attention Gradient-weighted attention.Inspired by Chefer et al
-
[24]
propose, we propose a lightweight gradient-weighted relevance propagation(LPV) for autoregressive VLMs that turns layer-wise attentions into token-level relevance maps by using gradient weighting and cross-layer diffusion. For each Transformer layerℓ, letA (ℓ) ∈R H×S×S be the multi- head attention (post-softmax) and let G(ℓ) = ∂L ∂A(ℓ) be its gradient obt...
-
[25]
Count the number of objects in this image. Answer the count within curly brackets, eg.{10}
Attention Reweighting in Qwen Models 8.1. Attention Reweighting in Grouped Query At- tention Architecture Qwen 2.5 and Qwen 3 models employ Grouped Query At- tention (GQA) , which differs from standard Multi-Head Attention by using fewer key-value heads than query heads to reduce computational cost. Specifically, withH= 32 attention heads andK= 8key-value...
-
[26]
Example images for theObjectcategory,Colorpattern, showing different object colors
Sample Images (a) black (b) white (c) red (d) yellow (e) blue (f) light gray (g) green (h) multicolor Figure 4. Example images for theObjectcategory,Colorpattern, showing different object colors. 4 (a) Checkerboard (b) Concentric Circles (c) Crosshatch (d) Diagonal Stripes (e) Dots (f) Horizontal Stripes (g) Linear Gradient (h) Radial Gradient (i) Vertica...
-
[27]
circles”(as default in color experiment), “squares
Prompts Table 9. Prompts used when image has different Object Color or Shape. ID Example Prompt Text Logical Role / Cognitive Cue P1Count the number of distinct objects in this image... Baseline:Generic unconstrained prompt. P2Count the number of{color}color objects in this image... Single (Simple) Attribute:Simple target Cue (Color) - Replace {color}with...
-
[28]
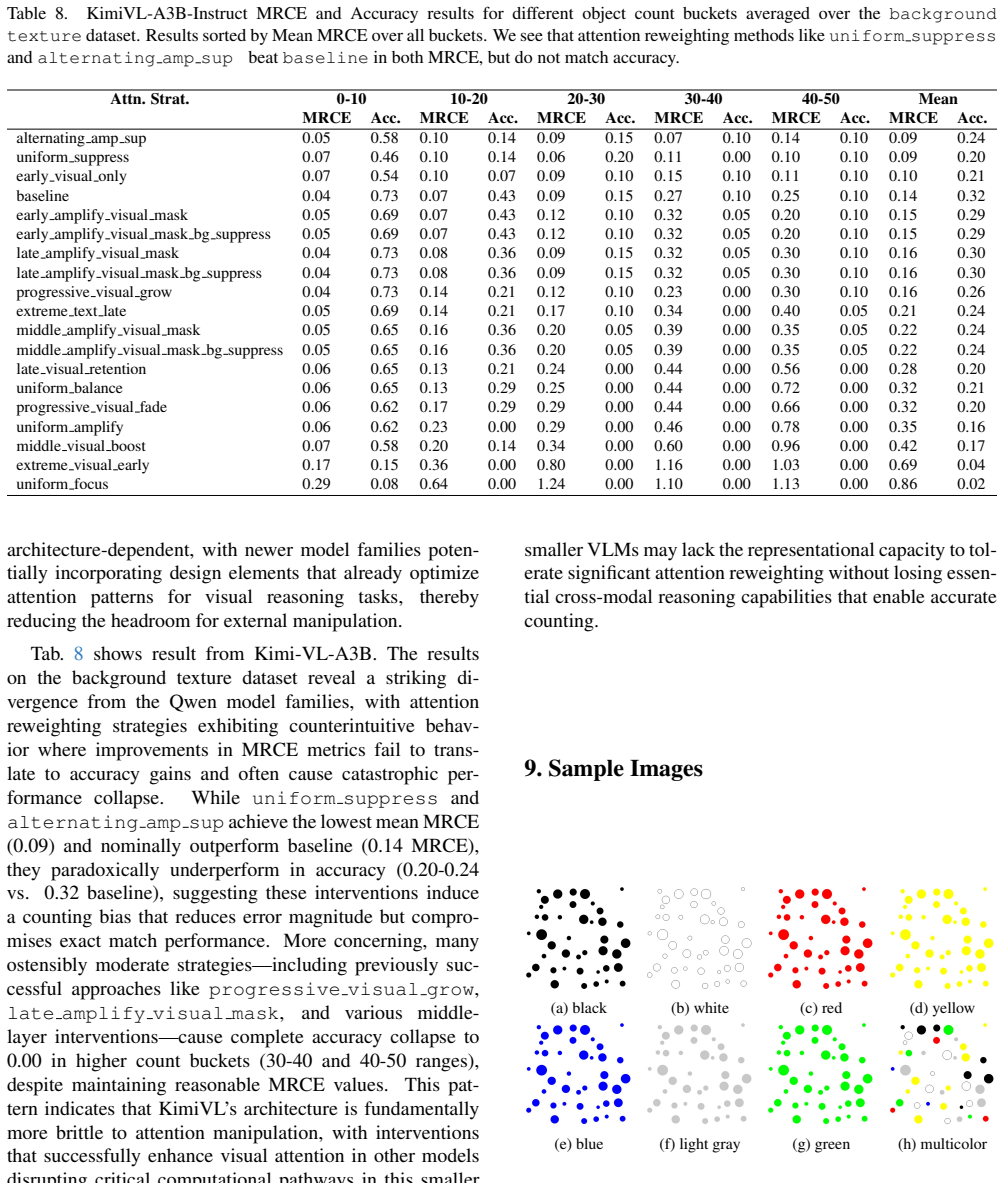
Effects of Visual Complexity Tables 12, Table 13, Table 14, and Table 15 present the Mean Relative Count Error (MRCE) for prompts 1, 3, 4, and 5, respectively
-
[29]
Attention on Visual Tokens Figures 9-10 shows the distribution of attention over vi- sion as well as counting error across prompts for the Qwen2.5-32B-Instruct and InternVL3-9B. Across models (i.e. Qwen2.5-32B-Instruct, InternVL3-9B, Qwen2.5-7B, and Kimi-VL-A3B), we observe a consistent divide in how architectural scale influences the effect of prompt spe...
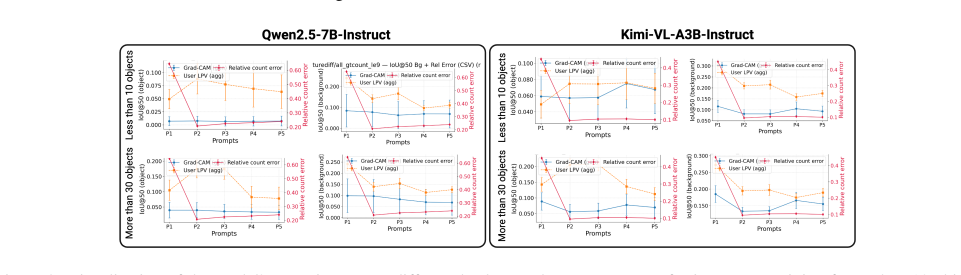
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.