SatSAM2: Motion-Constrained Video Object Tracking in Satellite Imagery using Promptable SAM2 and Kalman Priors
Pith reviewed 2026-05-17 06:06 UTC · model grok-4.3
The pith
SatSAM2 adds Kalman motion constraints to SAM2 to track objects in satellite videos without any training or fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
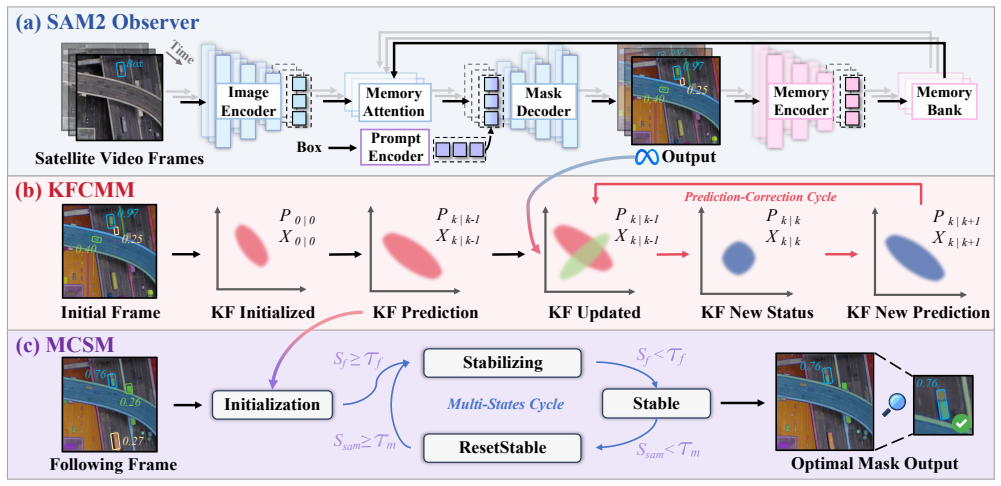
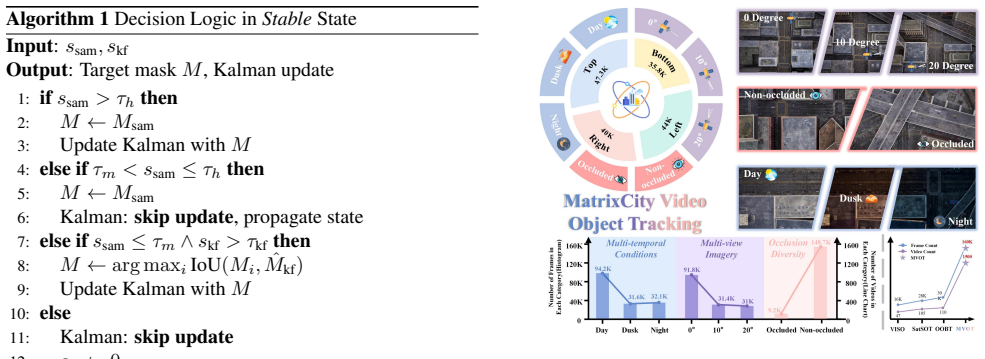
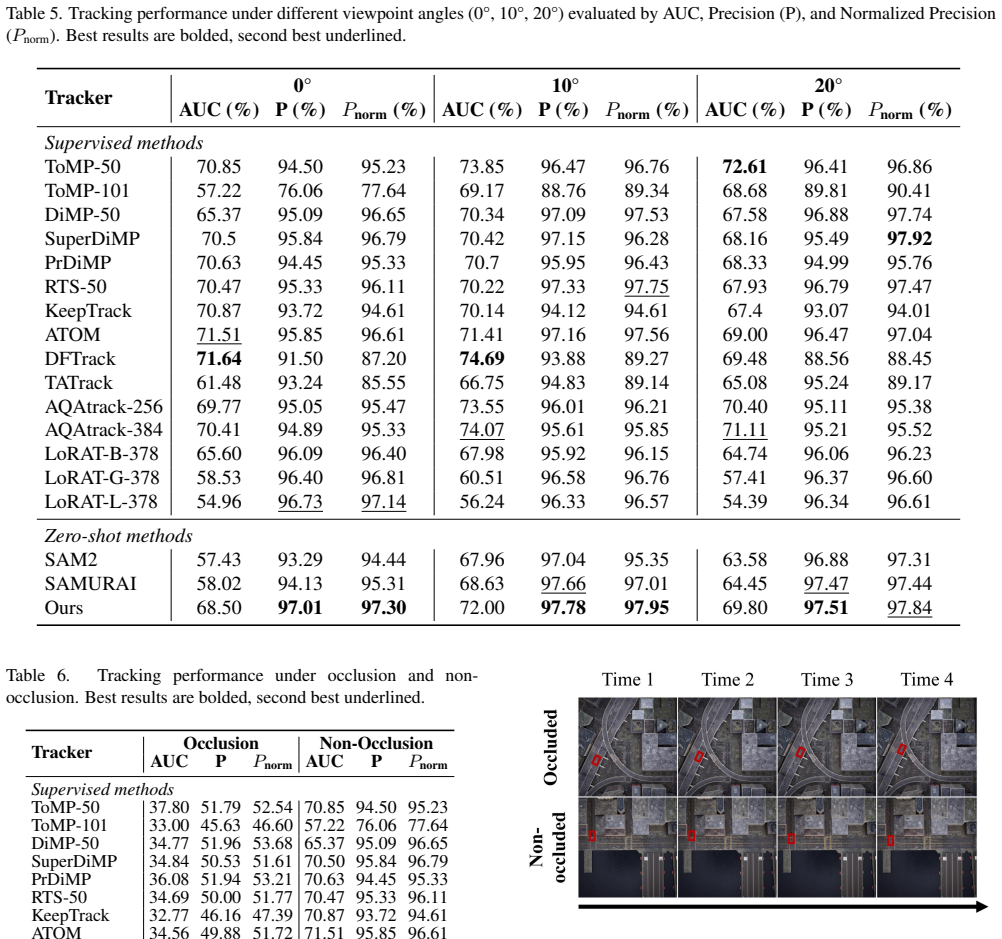
SatSAM2 adapts the SAM2 foundation model to satellite video object tracking by inserting two motion-aware modules: a Kalman Filter-based Constrained Motion Module that supplies temporal priors to limit drift, and a Motion-Constrained State Machine that adjusts the tracker state according to motion dynamics and detection reliability. These additions allow the system to maintain tracks through occlusions and viewpoint changes without scenario-specific training. On standard satellite tracking benchmarks and the new MVOT dataset of 1500-plus sequences, the resulting tracker exceeds both traditional methods and other SAM2-based approaches, including a 5.84 percent AUC improvement on the OOTB set.
What carries the argument
The Kalman Filter-based Constrained Motion Module paired with the Motion-Constrained State Machine, which together supply and enforce motion priors inside the SAM2 tracking loop to suppress drift and manage occlusion states.
If this is right
- Satellite video trackers can now be deployed across new scenes or sensors without collecting labeled training data for each case.
- Track loss during temporary occlusions or illumination shifts decreases because the state machine explicitly pauses or reinitializes based on motion consistency.
- Large-scale synthetic benchmarks like MVOT become viable proxies for comparing methods before real-data validation.
- The same motion-constraint pattern could be inserted into other promptable video segmentation models for remote-sensing tasks.
Where Pith is reading between the lines
- If the motion modules prove robust on real data, they could serve as a lightweight adapter layer for other foundation models in overhead imagery.
- The approach suggests a general recipe for injecting domain-specific physics priors into large vision models without full retraining.
- Wider release of the MVOT dataset may accelerate development of trackers that generalize across orbital altitudes and sensor types.
Load-bearing premise
The motion modules will suppress drift and recover from occlusions in varied real satellite footage without creating new failure modes or requiring case-by-case adjustments.
What would settle it
Performance measurements on a held-out collection of real satellite videos containing sudden maneuvers or extended occlusions that show no improvement or a drop in success rate compared with plain SAM2.
Figures







read the original abstract
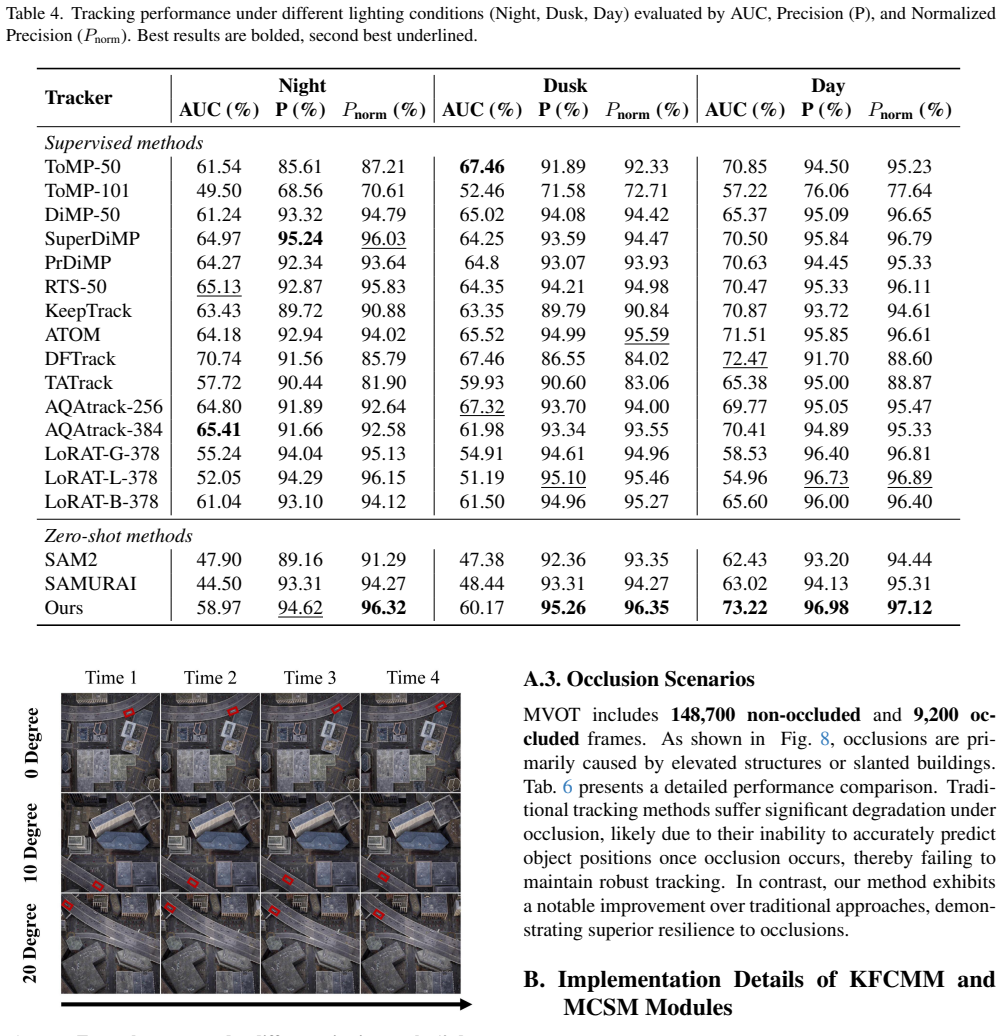
Existing satellite video tracking methods often struggle with generalization, requiring scenario-specific training to achieve satisfactory performance, and are prone to track loss in the presence of occlusion. To address these challenges, we propose SatSAM2, a zero-shot satellite video tracker built on SAM2, designed to adapt foundation models to the remote sensing domain. SatSAM2 introduces two core modules: a Kalman Filter-based Constrained Motion Module (KFCMM) to exploit temporal motion cues and suppress drift, and a Motion-Constrained State Machine (MCSM) to regulate tracking states based on motion dynamics and reliability. To support large-scale evaluation, we propose MatrixCity Video Object Tracking (MVOT), a synthetic benchmark containing 1,500+ sequences and 157K annotated frames with diverse viewpoints, illumination, and occlusion conditions. Extensive experiments on two satellite tracking benchmarks and MVOT show that SatSAM2 outperforms both traditional and foundation model-based trackers, including SAM2 and its variants. Notably, on the OOTB dataset, SatSAM2 achieves a 5.84% AUC improvement over state-of-the-art methods. Our code and dataset will be publicly released to encourage further research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SatSAM2, a zero-shot satellite video object tracker that adapts the promptable SAM2 foundation model using two new modules: a Kalman Filter-based Constrained Motion Module (KFCMM) to exploit temporal motion cues and suppress drift, and a Motion-Constrained State Machine (MCSM) to regulate tracking states. It introduces the MatrixCity Video Object Tracking (MVOT) synthetic benchmark with 1,500+ sequences and 157K frames, and reports that SatSAM2 outperforms traditional and foundation-model trackers on two satellite benchmarks and MVOT, with a 5.84% AUC gain on the OOTB dataset.
Significance. If the reported gains are substantiated by detailed ablations and robustness tests, the work would be significant for demonstrating practical zero-shot adaptation of large vision foundation models to the remote-sensing domain without scenario-specific training. The public release of code and the MVOT benchmark (with diverse viewpoints, illumination, and occlusions) would be a concrete contribution that enables reproducible research and could accelerate progress on satellite video tracking.
major comments (2)
- [§3.2] §3.2 (KFCMM description): The module relies on a standard Kalman filter with constant-velocity assumptions to constrain SAM2 prompts. Satellite imagery frequently exhibits perspective-induced acceleration, parallax, and irregular frame rates; the manuscript provides no quantitative validation (e.g., covariance sensitivity or cross-orbit tests) showing that prediction errors do not lock prompts onto background or trigger erroneous MCSM state switches.
- [§4] §4 (Experiments): The central claim of a 5.84% AUC improvement on OOTB and consistent outperformance on MVOT is presented without ablation studies isolating KFCMM and MCSM contributions, without error bars or statistical significance tests, and without failure-case analysis. This absence makes it impossible to verify that the gains are load-bearing on the proposed modules rather than on SAM2 base performance or benchmark specifics.
minor comments (2)
- [§3.3] Notation for the state-machine thresholds and Kalman process noise should be defined explicitly in a table or appendix so that readers can reproduce the exact configuration used in the reported results.
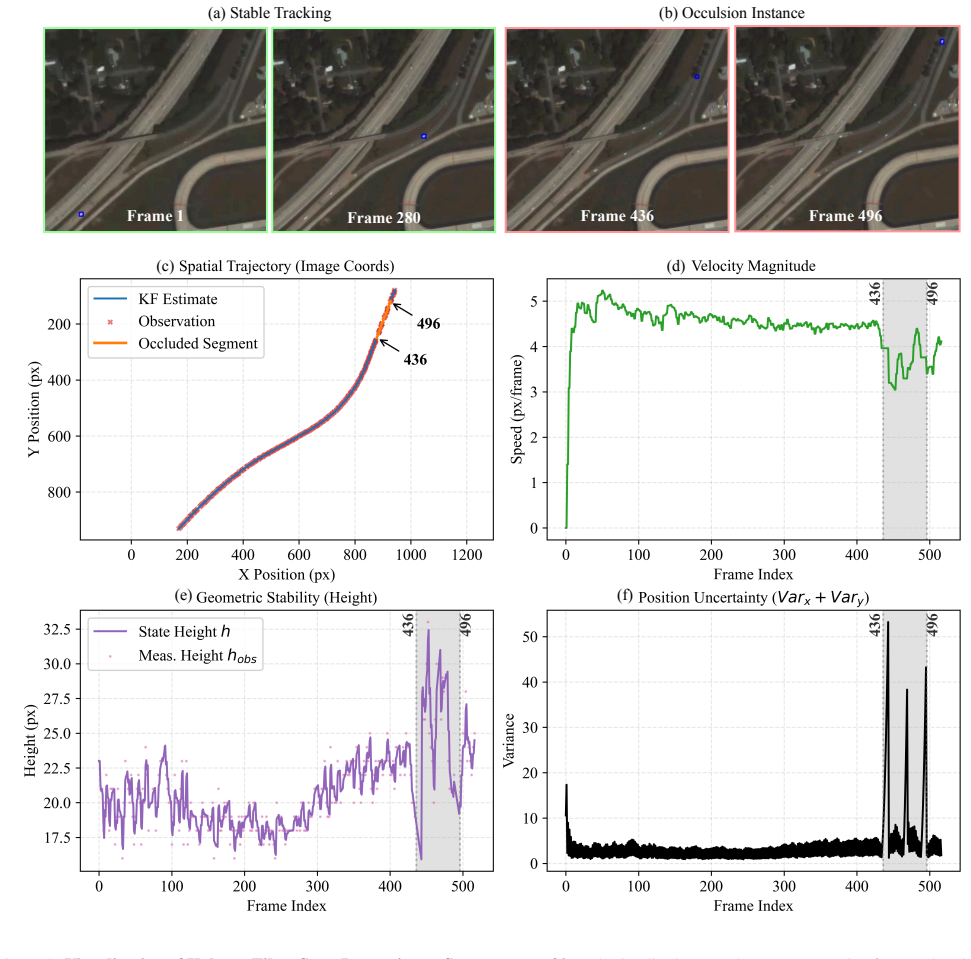
- Figure captions for qualitative results should include the specific sequence identifiers and frame numbers shown, and should note whether the displayed frames contain the occlusion or viewpoint-change cases highlighted in the text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the KFCMM assumptions and experimental rigor. We address each major comment below and will revise the manuscript to incorporate additional validation and analysis.
read point-by-point responses
-
Referee: [§3.2] §3.2 (KFCMM description): The module relies on a standard Kalman filter with constant-velocity assumptions to constrain SAM2 prompts. Satellite imagery frequently exhibits perspective-induced acceleration, parallax, and irregular frame rates; the manuscript provides no quantitative validation (e.g., covariance sensitivity or cross-orbit tests) showing that prediction errors do not lock prompts onto background or trigger erroneous MCSM state switches.
Authors: We acknowledge that the constant-velocity model in KFCMM is a simplification that may not capture all satellite-specific effects such as parallax or irregular frame rates. The module was introduced to supply a lightweight temporal constraint for SAM2 prompt generation in a zero-shot setting. In the revised manuscript we will add covariance sensitivity analysis, evaluation on sequences with varying frame rates, and cross-orbit tests to quantify prediction error impact on prompt stability and MCSM transitions. revision: yes
-
Referee: [§4] §4 (Experiments): The central claim of a 5.84% AUC improvement on OOTB and consistent outperformance on MVOT is presented without ablation studies isolating KFCMM and MCSM contributions, without error bars or statistical significance tests, and without failure-case analysis. This absence makes it impossible to verify that the gains are load-bearing on the proposed modules rather than on SAM2 base performance or benchmark specifics.
Authors: We agree that the experimental section would be strengthened by explicit ablations and statistical reporting. While the manuscript already compares against SAM2 and other baselines, we will add component-wise ablation studies (with and without KFCMM/MCSM), report error bars and significance tests where appropriate, and include a failure-case analysis to demonstrate when the motion constraints are most effective. revision: yes
Circularity Check
No circularity: empirical evaluation on independent benchmarks with standard components
full rationale
The paper presents SatSAM2 as a zero-shot tracker combining publicly available SAM2 with two new modules (KFCMM using Kalman filtering for motion cues and MCSM for state regulation). Performance claims such as the 5.84% AUC gain on OOTB and outperformance on MVOT are reported as outcomes of experiments on external satellite tracking benchmarks plus the authors' synthetic MVOT dataset. No equations, fitted parameters, or self-citations appear in the provided text that would make any prediction or uniqueness claim reduce to the input by construction. The derivation is a standard modular engineering extension evaluated externally and remains self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Object motion in satellite videos can be adequately modeled as linear with Gaussian noise for Kalman filtering purposes
invented entities (2)
-
Kalman Filter-based Constrained Motion Module (KFCMM)
no independent evidence
-
Motion-Constrained State Machine (MCSM)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
KFCMM Prediction-Correction Cycle... state transition matrix F = [[I4, Δt·I4, 0], ...] ... s_j^kf = IoU(ˆx_{t+1|t}, Mj) if area ratio in D
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Motion-Constrained State Machine... five states: Uninitialized, Initialized, Stabilizing, Stable, ResetStable... thresholds τ_h, τ_m, τ_kf
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Learning discriminative model prediction for track- ing
Goutam Bhat, Martin Danelljan, Luc Van Gool, and Radu Timofte. Learning discriminative model prediction for track- ing. InProceedings of the IEEE/CVF International Confer- ence on Computer Vision (ICCV), 2019. 2, 1
work page 2019
-
[2]
Learning discriminative model prediction for track- ing
Goutam Bhat, Martin Danelljan, Luc Van Gool, and Radu Timofte. Learning discriminative model prediction for track- ing. In2019 IEEE/CVF International Conference on Com- puter Vision (ICCV), pages 6181–6190, 2019. 8
work page 2019
-
[3]
Know your surroundings: Exploiting scene infor- mation for object tracking
Goutam Bhat, Martin Danelljan, Luc Van Gool, and Radu Timofte. Know your surroundings: Exploiting scene infor- mation for object tracking. InComputer Vision – ECCV 2020, pages 205–221, Cham, 2020. Springer International Publishing. 8, 1
work page 2020
-
[4]
Yuzeng Chen, Yuqi Tang, Zhiyong Yin, Te Han, Bin Zou, and Huihui Feng. Single object tracking in satellite videos: A correlation filter-based dual-flow tracker.IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 15:6687–6698, 2022. 2, 8, 6
work page 2022
-
[5]
Yuzeng Chen, Yuqi Tang, Yi Xiao, Qiangqiang Yuan, Yuwei Zhang, Fengqing Liu, Jiang He, and Liangpei Zhang. Satel- lite video single object tracking: A systematic review and an oriented object tracking benchmark.ISPRS Journal of Pho- togrammetry and Remote Sensing, 210:212–240, 2024. 3, 4, 6
work page 2024
-
[6]
Prob- abilistic regression for visual tracking
Martin Danelljan, Luc Van Gool, and Radu Timofte. Prob- abilistic regression for visual tracking. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020. 2, 8, 1
work page 2020
-
[7]
arXiv preprint arXiv:2003.09003
Patrick Dendorfer, Hamid Rezatofighi, Anton Milan, et al. Mot20: A benchmark for multi object tracking in crowded scenes.arXiv preprint arXiv:2003.09003, 2020. 2
-
[8]
Grewal.Kalman Filtering, pages 1285–1289
Mohinder S. Grewal.Kalman Filtering, pages 1285–1289. Springer Berlin Heidelberg, Berlin, Heidelberg, 2025. 2
work page 2025
-
[9]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Doll´ar, and Ross Girshick. Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 16000–16009, 2022. 4
work page 2022
-
[10]
R. E. Kalman. A new approach to linear filtering and predic- tion problems.Journal of Basic Engineering, 82(1):35–45,
-
[11]
Masoud Khodarahmi and Vafa Maihami. A review on kalman filter models.Archives of Computational Methods in Engineering, 30(1):727–747, 2023
work page 2023
-
[12]
Introduction to kalman filter and its applications
Youngjoo Kim and Hyochoong Bang. Introduction to kalman filter and its applications. InIntroduction and im- plementations of the Kalman filter. IntechOpen, 2018. 2
work page 2018
-
[13]
Berg, Wan-Yen Lo, Piotr Dollar, and Ross Girshick
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C. Berg, Wan-Yen Lo, Piotr Dollar, and Ross Girshick. Segment anything. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 4015–4026, 2023. 2
work page 2023
-
[14]
Pujian Lai, Meili Zhang, Gong Cheng, Shengyang Li, Xi- ankai Huang, and Junwei Han. Target-aware transformer for satellite video object tracking.IEEE Transactions on Geo- science and Remote Sensing, 62:1–10, 2024. 2, 8, 6
work page 2024
-
[15]
Jinpeng Li, Jun He, Weijia Li, Jiabin Chen, and Jinhua Yu. Roadcorrector: A structure-aware road extraction method for road connectivity and topology correction.IEEE Transac- tions on Geoscience and Remote Sensing, 62:1–18, 2024. 1
work page 2024
-
[16]
Shengyang Li, Zhuang Zhou, Manqi Zhao, Jian Yang, Wei- long Guo, Yixuan Lv, Longxuan Kou, Han Wang, and Yan- feng Gu. A multitask benchmark dataset for satellite video: Object detection, tracking, and segmentation.IEEE Trans- actions on Geoscience and Remote Sensing, 61:1–21, 2023. 3
work page 2023
-
[17]
Omnicity: Omnipotent city understanding with multi-level and multi- view images
Weijia Li, Yawen Lai, Linning Xu, Yuanbo Xiangli, Jinhua Yu, Conghui He, Gui-Song Xia, and Dahua Lin. Omnicity: Omnipotent city understanding with multi-level and multi- view images. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 17397–17407, 2023. 1
work page 2023
-
[18]
Weijia Li, Wenqian Zhao, Jinhua Yu, Juepeng Zheng, Con- ghui He, Haohuan Fu, and Dahua Lin. Joint seman- tic–geometric learning for polygonal building segmentation from high-resolution remote sensing images.ISPRS Journal of Photogrammetry and Remote Sensing, 201:26–37, 2023. 1
work page 2023
-
[19]
3d building reconstruction from monocular remote sensing images with multi-level supervi- sions
Weijia Li, Haote Yang, Zhenghao Hu, Juepeng Zheng, Gui- Song Xia, and Conghui He. 3d building reconstruction from monocular remote sensing images with multi-level supervi- sions. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 27728– 27737, 2024. 1
work page 2024
-
[20]
Yangfan Li, Chunjiang Bian, and Hongzhen Chen. Object tracking in satellite videos: Correlation particle filter track- ing method with motion estimation by kalman filter.IEEE Transactions on Geoscience and Remote Sensing, 60:1–12,
-
[21]
Matrixcity: A large-scale city dataset for city-scale neural rendering and beyond
Yixuan Li, Lihan Jiang, Linning Xu, Yuanbo Xiangli, Zhen- zhi Wang, Dahua Lin, and Bo Dai. Matrixcity: A large-scale city dataset for city-scale neural rendering and beyond. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3205–3215, 2023. 5, 1
work page 2023
-
[22]
Tracking meets lora: Faster training, larger model, stronger performance
Liting Lin, Heng Fan, Zhipeng Zhang, Yaowei Wang, Yong Xu, and Haibin Ling. Tracking meets lora: Faster training, larger model, stronger performance. InECCV, 2024. 2, 8, 1, 6
work page 2024
-
[23]
Learning target candidate association to keep track of what not to track
Christoph Mayer, Martin Danelljan, Danda Pani Paudel, and Luc Van Gool. Learning target candidate association to keep track of what not to track. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 13444–13454, 2021. 8 9
work page 2021
-
[24]
Transforming model prediction for tracking
Christoph Mayer, Martin Danelljan, Goutam Bhat, Matthieu Paul, Danda Pani Paudel, Fisher Yu, and Luc Van Gool. Transforming model prediction for tracking. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), pages 8731–8740, 2022. 2, 8, 1
work page 2022
-
[25]
Joint tracking and segmentation of multiple targets
Anton Milan, Laura Leal-Taix ´e, Konrad Schindler, and Ian Reid. Joint tracking and segmentation of multiple targets. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5397–5406, 2015. 2
work page 2015
-
[26]
Anton Milan, Laura Leal-Taix ´e, Ian Reid, Stefan Roth, and Konrad Schindler. Motchallenge: A benchmark for single- camera multiple target tracking.International Journal of Computer Vision, 2021. 2
work page 2021
-
[27]
Robust visual tracking by segmentation
Matthieu Paul, Martin Danelljan, Christoph Mayer, and Luc Van Gool. Robust visual tracking by segmentation. InCom- puter Vision – ECCV 2022, pages 571–588, Cham, 2022. Springer Nature Switzerland. 8, 1
work page 2022
-
[28]
SAM 2: Segment anything in images and videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R¨adle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junt- ing Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao- Yuan Wu, Ross Girshick, Piotr Doll´ar, and Christoph Feicht- enhofer. SAM 2: Segment anything in images and videos. In The Thirteenth Int...
work page 2025
-
[29]
Hiera: A hi- erarchical vision transformer without the bells-and-whistles
Chaitanya Ryali, Yuan-Ting Hu, Daniel Bolya, Chen Wei, Haoqi Fan, Po-Yao Huang, Vaibhav Aggarwal, Arkabandhu Chowdhury, Omid Poursaeed, Judy Hoffman, Jitendra Ma- lik, Yanghao Li, and Christoph Feichtenhofer. Hiera: A hi- erarchical vision transformer without the bells-and-whistles. ICML, 2023. 4
work page 2023
-
[30]
Ros-sam: High-quality interactive segmenta- tion for remote sensing moving object
Zhe Shan, Yang Liu, Lei Zhou, Cheng Yan, Heng Wang, and Xia Xie. Ros-sam: High-quality interactive segmenta- tion for remote sensing moving object. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3625–3635, 2025. 2
work page 2025
-
[31]
Jia Shao, Bo Du, Chen Wu, Mingming Gong, and Tongliang Liu. Hrsiam: High-resolution siamese network, towards space-borne satellite video tracking.IEEE Transactions on Image Processing, 30:3056–3068, 2021. 2
work page 2021
-
[32]
Jiahao Wang, Fang Liu, Licheng Jiao, Yingjia Gao, Hao Wang, Lingling Li, Puhua Chen, Xu Liu, and Shuo Li. Satel- lite video object tracking based on location prompts.IEEE Transactions on Circuits and Systems for Video Technology, 34(7):6253–6264, 2024. 1
work page 2024
-
[33]
An introduction to the kalman filter
Greg Welch and Gary Bishop. An introduction to the kalman filter. Technical Report TR 95-041, University of North Car- olina at Chapel Hill, Department of Computer Science, 1995. 2
work page 1995
-
[34]
Autore- gressive queries for adaptive tracking with spatio-temporal transformers
Jinxia Xie, Bineng Zhong, Zhiyi Mo, Shengping Zhang, Liangtao Shi, Shuxiang Song, and Rongrong Ji. Autore- gressive queries for adaptive tracking with spatio-temporal transformers. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19300– 19309, 2024. 2, 8, 6
work page 2024
-
[35]
Cheng-Yen Yang, Hsiang-Wei Huang, Wenhao Chai, Zhongyu Jiang, and Jenq-Neng Hwang. Samurai: Adapting segment anything model for zero-shot visual tracking with motion-aware memory, 2024. 2, 8, 4
work page 2024
-
[36]
arXiv preprint arXiv:2304.11968 (2023)
Jinyu Yang, Mingqi Gao, Zhe Li, Shanghua Gao, Fang Wang, and Fengcai Zheng. Track anything: Segment any- thing meets videos.arXiv preprint arXiv:2304.11968, 2023. 2
-
[37]
Sg-bev: Satellite-guided bev fusion for cross-view semantic segmentation
Junyan Ye, Qiyan Luo, Jinhua Yu, Huaping Zhong, Zhimeng Zheng, Conghui He, and Weijia Li. Sg-bev: Satellite-guided bev fusion for cross-view semantic segmentation. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 27748–27757, 2024. 1
work page 2024
-
[38]
Qian Yin, Qingyong Hu, Hao Liu, Feng Zhang, Yingqian Wang, Zaiping Lin, Wei An, and Yulan Guo. Detecting and tracking small and dense moving objects in satellite videos: A benchmark.IEEE Transactions on Geoscience and Re- mote Sensing, 60:1–18, 2021. 1, 2
work page 2021
-
[39]
Qian Yin, Qingyong Hu, Hao Liu, Feng Zhang, Yingqian Wang, Zaiping Lin, Wei An, and Yulan Guo. Detecting and tracking small and dense moving objects in satellite videos: A benchmark.IEEE Transactions on Geoscience and Re- mote Sensing, 60:1–18, 2022. 3
work page 2022
-
[40]
Manqi Zhao, Shengyang Li, Shiyu Xuan, Longxuan Kou, Shuai Gong, and Zhuang Zhou. Satsot: A benchmark dataset for satellite video single object tracking.IEEE Transactions on Geoscience and Remote Sensing, 60:1–11, 2022. 3, 4, 6
work page 2022
-
[41]
Joey Tianyi Zhou, Jiawei Du, Hongyuan Zhu, Xi Peng, Yong Liu, and Rick Siow Mong Goh. Anomalynet: An anomaly detection network for video surveillance.IEEE Transactions on Information Forensics and Security, 14(10):2537–2550,
-
[42]
1 10 SatSAM2: Motion-Constrained Video Object Tracking in Satellite Imagery using Promptable SAM2 and Kalman Priors Supplementary Material Supplementary Material This document serves as a comprehensive supplement to the main manuscript, providing detailed implementation spec- ifications, extended experimental analysis, and qualitative visualizations that ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.