CaptionQA: Is Your Caption as Useful as the Image Itself?
Pith reviewed 2026-05-17 05:38 UTC · model grok-4.3
The pith
Captions from state-of-the-art multimodal models lose up to 32 percent of image utility on downstream tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
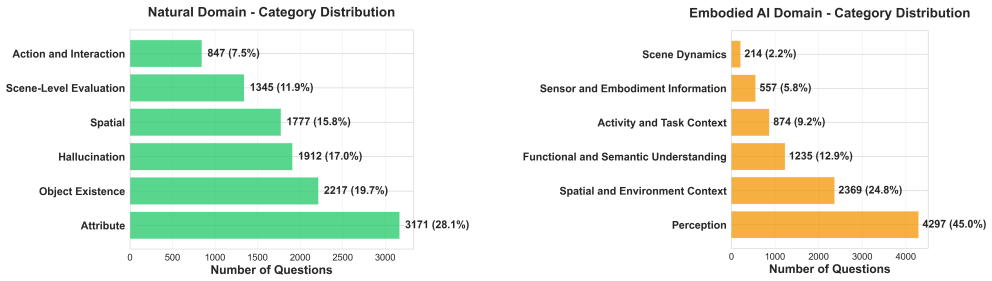
CaptionQA evaluates caption quality by measuring how well a downstream LLM can answer multiple-choice questions that require visual information when given only the caption. Across natural, document, e-commerce, and embodied-AI domains, state-of-the-art multimodal models produce captions whose utility falls short of the source images by as much as 32 percent on these questions, even when the same models perform comparably on conventional image-QA benchmarks.
What carries the argument
CaptionQA benchmark that builds densely annotated, domain-specific multiple-choice questions requiring visual details and measures utility by LLM accuracy when answering from captions alone.
If this is right
- Systems that rely on captions for retrieval, recommendation, or multi-step reasoning may underperform because critical visual details are missing.
- Caption generation should be optimized for preserving task-relevant information rather than generic fluency.
- Evaluation of multimodal models needs to include utility-based tests in addition to traditional caption metrics.
- Domain-specific taxonomies can guide caption improvement for particular applications such as document understanding or embodied planning.
Where Pith is reading between the lines
- The same question-construction method could be applied to test caption utility in additional tasks like visual search or planning.
- Training loops for captioning models could incorporate direct feedback from downstream LLM performance on utility questions.
- The benchmark suggests that caption quality should be measured relative to specific downstream needs rather than in isolation.
Load-bearing premise
The constructed questions truly demand visual details that typical captions cannot supply and that LLM performance on captions serves as a reliable proxy for downstream task utility.
What would settle it
A result showing that LLMs reach the same accuracy on the questions when given only captions as when given the images themselves.
Figures






















read the original abstract
Image captions serve as efficient surrogates for visual content in multimodal systems such as retrieval, recommendation, and multi-step agentic inference pipelines. Yet current evaluation practices miss a fundamental question: Can captions stand-in for images in real downstream tasks? We propose a utility-based benchmark, CaptionQA, to evaluate model-generated captions, where caption quality is measured by how well it supports downstream tasks. CaptionQA is an extensible domain-dependent benchmark covering 4 domains--Natural, Document, E-commerce, and Embodied AI--each with fine-grained taxonomies (25 top-level and 69 subcategories) that identify useful information for domain-specific tasks. CaptionQA builds 33,027 densely annotated multiple-choice questions (50.3 per image on average) that explicitly require visual information to answer, providing a comprehensive probe of caption utility. In our evaluation protocol, an LLM answers these questions using captions alone, directly measuring whether captions preserve image-level utility and are utilizable by a downstream LLM. Evaluating state-of-the-art MLLMs reveals substantial gaps between the image and its caption utility. Notably, models nearly identical on traditional image-QA benchmarks lower by up to 32% in caption utility. We release CaptionQA along with an open-source pipeline for extension to new domains. The code is available at https://github.com/bronyayang/CaptionQA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CaptionQA, a utility-based benchmark with 33,027 densely annotated multiple-choice questions (50.3 per image) across four domains (Natural, Document, E-commerce, Embodied AI) and fine-grained taxonomies. It evaluates whether model-generated captions preserve image utility for downstream tasks by measuring how well an LLM can answer the questions from captions alone versus from the original images, reporting performance drops of up to 32% for state-of-the-art MLLMs that perform similarly on traditional image-QA benchmarks. The benchmark and extension pipeline are released.
Significance. If the questions are confirmed to require non-caption-recoverable visual information, the results would provide a more actionable, task-oriented evaluation of captions than existing metrics, with direct implications for captioning in retrieval, recommendation, and agentic pipelines. The domain-specific taxonomies and open pipeline are constructive contributions.
major comments (2)
- [Benchmark Construction] The headline claim of up to 32% utility drop rests on the assertion (abstract and benchmark construction) that the 33,027 MCQs 'explicitly require visual information to answer' and cannot be solved from captions. No verification step is described that tests whether high-quality, information-dense captions (e.g., those covering the salient elements from the taxonomies) would still leave the questions unanswerable. Without this control, the measured gap risks conflating question design with caption quality and weakens the proxy validity of 'LLM answering from caption' for downstream utility.
- [Evaluation Results] §4 (Evaluation Results): The reported performance gaps for MLLMs need explicit statistical testing, confidence intervals, and controls for inter-question difficulty or domain-specific variance to support the cross-model comparison that models 'nearly identical on traditional image-QA benchmarks' show large caption-utility drops.
minor comments (2)
- [Abstract] Abstract: Specify the exact traditional image-QA benchmarks and the numerical performance values on which the MLLMs are described as 'nearly identical' to provide context for the 32% caption-utility gap.
- [Benchmark Statistics] The average of 50.3 questions per image is stated but the distribution across domains and subcategories should be reported in a table for transparency.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We have carefully reviewed the major comments and provide point-by-point responses below, outlining how we will strengthen the paper in revision.
read point-by-point responses
-
Referee: [Benchmark Construction] The headline claim of up to 32% utility drop rests on the assertion (abstract and benchmark construction) that the 33,027 MCQs 'explicitly require visual information to answer' and cannot be solved from captions. No verification step is described that tests whether high-quality, information-dense captions (e.g., those covering the salient elements from the taxonomies) would still leave the questions unanswerable. Without this control, the measured gap risks conflating question design with caption quality and weakens the proxy validity of 'LLM answering from caption' for downstream utility.
Authors: We acknowledge that the manuscript does not include an explicit control experiment testing high-quality, information-dense captions against the questions. Questions were constructed using domain-specific taxonomies targeting visual elements (e.g., precise spatial relations, fine-grained attributes, and task-critical details) that standard captioning models typically omit or underspecify. To directly address the concern, we will add a new subsection to the benchmark construction section in the revised manuscript. This will describe a control study in which we generate dense captions covering all taxonomy elements and measure the residual unanswerability rate for the MCQs, providing quantitative evidence that the questions probe non-recoverable visual information. revision: yes
-
Referee: [Evaluation Results] §4 (Evaluation Results): The reported performance gaps for MLLMs need explicit statistical testing, confidence intervals, and controls for inter-question difficulty or domain-specific variance to support the cross-model comparison that models 'nearly identical on traditional image-QA benchmarks' show large caption-utility drops.
Authors: We agree that the current presentation of results would benefit from greater statistical rigor. In the revised manuscript, we will augment §4 with bootstrap-derived 95% confidence intervals on all reported accuracy gaps, paired statistical significance tests (e.g., McNemar’s test on per-question outcomes) between image and caption conditions, and additional tables breaking down performance by domain and by question difficulty strata derived from the taxonomy. These controls will better substantiate the cross-model comparisons while preserving the original findings. revision: yes
Circularity Check
No circularity: empirical benchmark construction
full rationale
The paper presents an empirical benchmark (CaptionQA) built from domain taxonomies, dense human annotations, and multiple-choice questions. It measures caption utility via direct LLM performance comparisons on image vs. caption inputs. No equations, fitted parameters, predictions derived from inputs, or self-citation chains appear in the derivation. The central result (performance gaps) follows from the constructed test set and evaluation protocol without reducing to its own inputs by construction. This is a standard benchmark paper whose claims rest on external data collection rather than internal self-reference.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
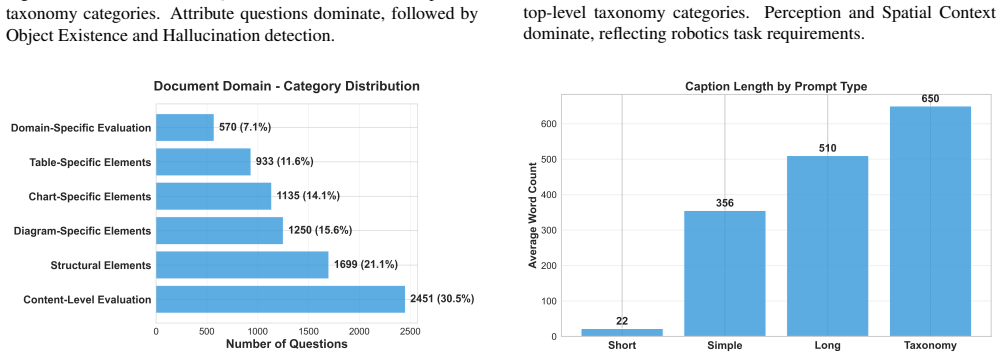
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
CaptionQA builds 33,027 densely annotated multiple-choice questions... that explicitly require visual information to answer... an LLM answers these questions using captions alone
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
fine-grained taxonomies (25 top-level and 69 subcategories) that identify useful information for domain-specific tasks
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
ClaimDiff-RL: Fine-Grained Caption Reinforcement Learning through Visual Claim Comparison
ClaimDiff-RL replaces holistic scalar rewards with reference-conditioned atomic claim differences verified by a multimodal judge to improve the hallucination-missing-fact tradeoff in long-form image captioning.
-
BalCapRL: A Balanced Framework for RL-Based MLLM Image Captioning
BalCapRL applies balanced multi-objective RL with GDPO-style normalization and length-conditional masking to improve MLLM image captioning, reporting gains of up to +13.6 DCScore, +9.0 CaptionQA, and +29.0 CapArena on...
Reference graph
Works this paper leans on
-
[1]
How enterprises are using multimodal mod- els in production with fireworks.https://fireworks
Fireworks AI. How enterprises are using multimodal mod- els in production with fireworks.https://fireworks. ai/blog/multimodal- enterprise, 2024. Fire- works AI Blog, published September 25, 2024. [Accessed: November 11, 2025]. 1
work page 2024
-
[2]
Spice: Semantic propositional image cap- tion evaluation
Peter Anderson, Basura Fernando, Mark Johnson, and Stephen Gould. Spice: Semantic propositional image cap- tion evaluation. InEuropean conference on computer vision, pages 382–398. Springer, 2016. 3
work page 2016
-
[3]
Vqa: Visual question answering
Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C Lawrence Zitnick, and Devi Parikh. Vqa: Visual question answering. InProceedings of the IEEE international conference on computer vision, pages 2425– 2433, 2015. 3
work page 2015
-
[4]
Qwen2.5-vl technical report, 2025
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhao- hai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report, 2025. 7
work page 2025
-
[5]
Snowflake Engineering Blog. Evaluating multimodal vs. text-based retrieval for rag with snowflake cortex.https: / / www . snowflake . com / en / engineering - blog/arctic- agentic- rag- multimodal- pdf- retrieval/, 2025. Snowflake Engineering Blog, pub- lished April 21, 2025. [Accessed: November 11, 2025]. 1
work page 2025
-
[6]
Gonzalez, Trevor Darrell, and John Canny
David Chan, Suzanne Petryk, Joseph E. Gonzalez, Trevor Darrell, and John Canny. Clair: Evaluating image captions with large language models, 2023. 3
work page 2023
-
[7]
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Jiaqi Wang, Yu Qiao, Dahua Lin, et al. Are we on the right way for evaluating large vision-language models?Advances in Neural Informa- tion Processing Systems, 37:27056–27087, 2024. 3
work page 2024
-
[8]
Kanzhi Cheng, Wenpo Song, Jiaxin Fan, Zheng Ma, Qiushi Sun, Fangzhi Xu, Chenyang Yan, Nuo Chen, Jianbing Zhang, and Jiajun Chen. Caparena: Benchmarking and analyzing detailed image captioning in the llm era.arXiv preprint arXiv:2503.12329, 2025. 3
-
[9]
Learning to evaluate image captioning,
Yin Cui, Guandao Yang, Andreas Veit, Xun Huang, and Serge Belongie. Learning to evaluate image captioning,
-
[10]
NVLM: Open Frontier-Class Multimodal LLMs
Wenliang Dai, Nayeon Lee, Boxin Wang, Zhuolin Yang, Zihan Liu, Jon Barker, Tuomas Rintamaki, Moham- mad Shoeybi, Bryan Catanzaro, and Wei Ping. Nvlm: Open frontier-class multimodal llms.arXiv preprint arXiv:2409.11402, 2024. 7
-
[11]
Yashar Deldjoo, Tommaso Di Noia, Daniele Malitesta, and Felice Antonio Merra. A study on the relative importance of convolutional neural networks in visually-aware recom- mender systems. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, pages 3961–3967, 2021. 1
work page 2021
-
[12]
Benchmarking and improving detail image caption.ArXiv, abs/2405.19092, 2024
Hongyuan Dong, Jiawen Li, Bohong Wu, Jiacong Wang, Yuan Zhang, and Haoyuan Guo. Benchmarking and improv- ing detail image caption.arXiv preprint arXiv:2405.19092,
-
[13]
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models
Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, et al. Mme: A comprehensive evaluation bench- mark for multimodal large language models.arXiv preprint arXiv:2306.13394, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Wenyi Hong, Wenmeng Yu, Xiaotao Gu, Guo Wang, Guob- ing Gan, Haomiao Tang, Jiale Cheng, Ji Qi, Junhui Ji, Li- hang Pan, et al. Glm-4.1 v-thinking: Towards versatile multi- modal reasoning with scalable reinforcement learning.arXiv e-prints, pages arXiv–2507, 2025. 7
work page 2025
-
[15]
Yichen Huang and Lin F Yang. Gemini 2.5 pro capable of winning gold at imo 2025.arXiv preprint arXiv:2507.15855, 7, 2025. 7
-
[16]
Collm: A large language model for composed image retrieval
Chuong Huynh, Jinyu Yang, Ashish Tawari, Mubarak Shah, Son Tran, Raffay Hamid, Trishul Chilimbi, and Abhinav Shrivastava. Collm: A large language model for composed image retrieval. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 3994–4004, 2025. 1
work page 2025
-
[17]
Adam Tauman Kalai, Ofir Nachum, Santosh S. Vempala, and Edwin Zhang. Why language models hallucinate, 2025. 4
work page 2025
-
[18]
Re-evaluating Automatic Metrics for Image Captioning
Mert Kilickaya, Aykut Erdem, Nazli Ikizler-Cinbis, and Erkut Erdem. Re-evaluating automatic metrics for image captioning.arXiv preprint arXiv:1612.07600, 2016. 3
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[19]
good4cir: Generating detailed synthetic captions for composed image retrieval
Pranavi Kolouju, Eric Xing, Robert Pless, Nathan Jacobs, and Abby Stylianou. good4cir: Generating detailed synthetic captions for composed image retrieval. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 3148–3157, 2025. 1
work page 2025
-
[20]
Seed-bench: Bench- marking multimodal large language models
Bohao Li, Yuying Ge, Yixiao Ge, Guangzhi Wang, Rui Wang, Ruimao Zhang, and Ying Shan. Seed-bench: Bench- marking multimodal large language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 13299–13308, 2024. 3
work page 2024
-
[21]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Zi- wei Liu, et al. Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326, 2024. 7
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Describe anything: Detailed localized image and video captioning.ArXiv, abs/2504.16072, 2025
Long Lian, Yifan Ding, Yunhao Ge, Sifei Liu, Hanzi Mao, Boyi Li, Marco Pavone, Ming-Yu Liu, Trevor Darrell, Adam Yala, and Yin Cui. Describe anything: Detailed localized im- age and video captioning.arXiv preprint arXiv:2504.16072,
-
[23]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In European conference on computer vision, pages 740–755. Springer, 2014. 3
work page 2014
-
[24]
Evaluating text-to-visual generation with image-to-text gen- eration
Zhiqiu Lin, Deepak Pathak, Baiqi Li, Jiayao Li, Xide Xia, Graham Neubig, Pengchuan Zhang, and Deva Ramanan. Evaluating text-to-visual generation with image-to-text gen- eration. InEuropean Conference on Computer Vision, pages 366–384. Springer, 2024. 3
work page 2024
-
[25]
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. Mmbench: Is your multi-modal model an all-around player? InEuropean conference on computer vi- sion, pages 216–233. Springer, 2024. 3
work page 2024
-
[26]
Zhihang Liu, Chen-Wei Xie, Bin Wen, Feiwu Yu, Jixuan Chen, Boqiang Zhang, Nianzu Yang, Pandeng Li, Yinglu Li, Zuan Gao, Yun Zheng, and Hongtao Xie. What is a good cap- tion? a comprehensive visual caption benchmark for eval- uating both correctness and thoroughness.arXiv preprint arXiv:2502.14914, 2025. 1, 3
-
[27]
Fan Lu, Wei Wu, Kecheng Zheng, Shuailei Ma, Biao Gong, Jiawei Liu, Wei Zhai, Yang Cao, Yujun Shen, and Zheng- Jun Zha. Benchmarking large vision-language models via directed scene graph for comprehensive image captioning. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 19618–19627, 2025. 3
work page 2025
-
[28]
Chartqa: A benchmark for question answer- ing about charts with visual and logical reasoning
Ahmed Masry, Xuan Long Do, Jia Qing Tan, Shafiq Joty, and Enamul Hoque. Chartqa: A benchmark for question answer- ing about charts with visual and logical reasoning. InFind- ings of the association for computational linguistics: ACL 2022, pages 2263–2279, 2022. 3
work page 2022
-
[29]
Docvqa: A dataset for vqa on document images
Minesh Mathew, Dimosthenis Karatzas, and CV Jawahar. Docvqa: A dataset for vqa on document images. InProceed- ings of the IEEE/CVF winter conference on applications of computer vision, pages 2200–2209, 2021. 3
work page 2021
-
[30]
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation.Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics (ACL), pages 311–318, 2002. 1, 3
work page 2002
-
[31]
Object hallucination in image cap- tioning, 2019
Anna Rohrbach, Lisa Anne Hendricks, Kaylee Burns, Trevor Darrell, and Kate Saenko. Object hallucination in image cap- tioning, 2019. 3
work page 2019
-
[32]
Tanik Saikh, Tirthankar Ghosal, Amish Mittal, Asif Ekbal, and Pushpak Bhattacharyya. Scienceqa: A novel resource for question answering on scholarly articles.International Journal on Digital Libraries, 23(3):289–301, 2022. 3
work page 2022
-
[33]
Martyna Slawinska. Transforming unstructured data into structured using AI.https://mindsdb.com/blog/ transforming - unstructured - data - into - structured- using- ai, 2024. MindsDB Blog, pub- lished November 22, 2024. [Accessed: November 11, 2025]. 1
work page 2024
-
[34]
Mistral ocr.https://mistral.ai/ news/mistral-ocr, 2025
Mistral AI Team. Mistral ocr.https://mistral.ai/ news/mistral-ocr, 2025. Mistral AI News, published March 6, 2025. [Accessed: November 11, 2025]. 1
work page 2025
-
[35]
Cider: Consensus-based image description evalua- tion
Ramakrishna Vedantam, C Lawrence Zitnick, and Devi Parikh. Cider: Consensus-based image description evalua- tion. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 4566–4575, 2015. 1, 3
work page 2015
-
[36]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265, 2025. 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Zhaoliang Wang, Baisong Liu, Weiming Huang, Tingting Hao, Huiqian Zhou, and Yuxin Guo. Leveraging multimodal large language model for multimodal sequential recommen- dation.Scientific Reports, 15(1):28960, 2025. 1
work page 2025
-
[38]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Magma: A foundation model for multi- modal ai agents
Jianwei Yang, Reuben Tan, Qianhui Wu, Ruijie Zheng, Baolin Peng, Yongyuan Liang, Yu Gu, Mu Cai, Seonghyeon Ye, Joel Jang, et al. Magma: A foundation model for multi- modal ai agents. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 14203–14214, 2025. 1
work page 2025
-
[40]
A survey on agentic multimodal large language models.arXiv preprint arXiv:2510.10991, 2025
Huanjin Yao, Ruifei Zhang, Jiaxing Huang, Jingyi Zhang, Yibo Wang, Bo Fang, Ruolin Zhu, Yongcheng Jing, Shunyu Liu, Guanbin Li, et al. A survey on agentic multimodal large language models.arXiv preprint arXiv:2510.10991, 2025. 1
-
[41]
Qinghao Ye, Xianhan Zeng, Fu Li, Chunyuan Li, and Haoqi Fan. Painting with words: Elevating detailed image caption- ing with benchmark and alignment learning.arXiv preprint arXiv:2503.07906, 2025. 1, 3
-
[42]
Peter Young, Alice Lai, Micah Hodosh, and Julia Hocken- maier. From image descriptions to visual denotations: New similarity metrics for semantic inference over event descrip- tions.Transactions of the association for computational lin- guistics, 2:67–78, 2014. 3
work page 2014
-
[43]
Qaeval: Mixture of evaluators for question-answering task evaluation
Tan Yue, Rui Mao, Xuzhao Shi, Shuo Zhan, Zuhao Yang, and Dongyan Zhao. Qaeval: Mixture of evaluators for question-answering task evaluation. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 14717–14730,
-
[44]
Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for ex- pert agi
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, et al. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for ex- pert agi. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9556– 9567, 2024. 3
work page 2024
-
[45]
Bohan Zhai, Shijia Yang, Chenfeng Xu, Sheng Shen, Kurt Keutzer, Chunyuan Li, and Manling Li. Halle-control: con- trolling object hallucination in large multimodal models. arXiv preprint arXiv:2310.01779, 2023. 1, 3
-
[46]
Yi-Fan Zhang, Huanyu Zhang, Haochen Tian, Chaoyou Fu, Shuangqing Zhang, Junfei Wu, Feng Li, Kun Wang, Qing- song Wen, Zhang Zhang, et al. Mme-realworld: Could your multimodal llm challenge high-resolution real-world 10 scenarios that are difficult for humans?arXiv preprint arXiv:2408.13257, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shen- glong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025. 7 11 CaptionQA: Is Your Caption as Useful as the Image Itself? Supplementary Material
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Motivation and Overview Figure 6 provides a conceptual overview of CaptionQA’s evaluation approach. Unlike traditional text-similarity metrics that are fact-blind, multimodal benchmarks that test a different task with sparse supervision, or complex non-deterministic caption evaluation pipelines, CaptionQA measures how “useful” a caption is by testing whet...
-
[49]
Question Characteristics Our pipeline generates predominantly 4-choice multiple- choice questions, which are more challenging than binary yes/no questions. As shown in Figure 7, 87–92% of ques- tions across domains are 4-choice, with the remaining split between 2-choice and 3-choice questions. The Natural do- main has a higher proportion of binary questio...
-
[50]
Write a very long and detailed caption describing the given image as comprehensively as possible
Caption Prompts Caption quality is highly sensitive to the instruction given to the MLLM. To study how prompting affects the utility of generated captions, we evaluate each model under four captioning prompts, shared across all domains: •Long.“Write a very long and detailed caption describing the given image as comprehensively as possible.” •Short.“Write ...
-
[51]
Taxonomy Structure Figure 14 presents the complete hierarchical taxonomy structure across all four CaptionQA domains. The taxon- omy guides question generation and ensures comprehensive coverage of domain-specific aspects that captions should capture. Each domain is organized into top-level categories (6–7 per domain) and their corresponding subcategories...
-
[52]
Perception and Spatial Context dominate, reflecting robotics task requirements
Image Amount Justification Instead of collecting tens of thousands of loosely annotated images as in most multimodal benchmarks, CaptionQA Figure 12.Embodied AI Domain:Question distribution across top-level taxonomy categories. Perception and Spatial Context dominate, reflecting robotics task requirements. Short Simple Long Taxonomy 0 100 200 300 400 500 ...
-
[53]
Cost of Extending CaptionQA to New Do- mains One of our design goals is that CaptionQA should be easy to extend beyond the four domains used in the main paper (Natural, Document, E-commerce, Embodied AI). In this section we clarify what needs to be done to add a new do- main and how the computational cost scales in our reference implementation. 4 Figure 1...
-
[54]
Rationale and Reliability of LLM as QA Reader Modern industrial systems increasingly rely on large lan- guage models not only as standalone chatbots, but ascom- ponentsinside downstream pipelines: LLM-based embed- ding models for retrieval and recommendation, LLM-driven re-ranking in search and feeds, and LLM agentic pipelines that orchestrate tools and m...
-
[55]
Prompt Transition Analysis: Where Does Length Help? We analyze accuracy changes across four prompt transitions to identify which categories benefit from longer or more structured prompts. 14.1. Short to Simple: Identifying High-ROI vs. Low-ROI Categories Figure 17 shows all 25 categories sorted by improvement. Document domain-specific evaluation (+47-51%)...
-
[56]
Category-Level Statistical Summary Table 9 shows statistics for all 25 top-level categories under the Simple prompt, aggregated across all models. For each category: mean score, standard deviation (across models), minimum and maximum scores (model variance), Cannot- Answer rate, and question count. Several insights emerge from Table 9: (1)Hallucina- tion ...
-
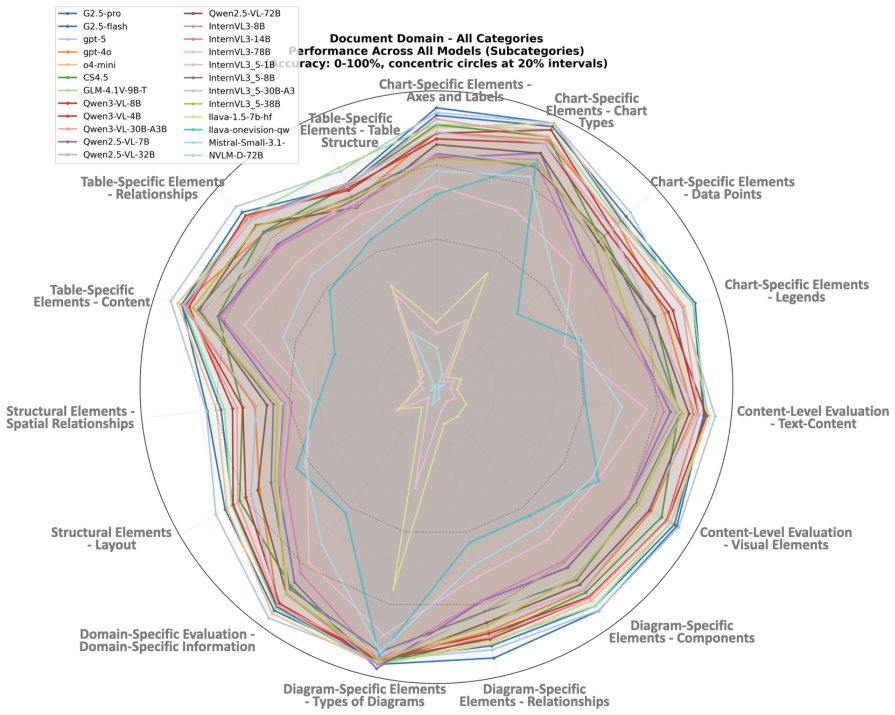
[57]
Detailed Model Performance Analysis Figure 28 presents a unified view of all 24 evaluated models across all 69 subcategories and 4 domains. Each axis rep- resents one subcategory, with axes colored by domain (Nat- ural=green, Document=blue, E-commerce=red, Embodied AI=orange) and separated by black radial lines marking do- main boundaries. Three findings ...
-
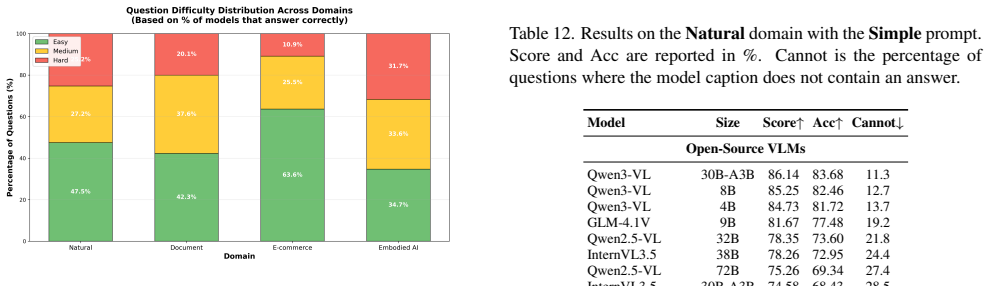
[58]
Question Difficulty Distribution To assess whether CaptionQA provides adequate discrimi- nation across different capability levels, we analyze ques- tion difficulty based on the percentage of models that an- swer each question correctly. 17.1. Difficulty Categorization We categorize questions into three difficulty levels based on the proportion of models ...
-
[59]
Write a very long and detailed caption describing the given image as comprehensively as possible
Full Results We report the full CaptionQA results as shown in Table 11– Table 26 for all evaluated models, prompts, and domains in this section. These tables complement the main-paper summary (Table 3) by providing per-domain, per-prompt breakdowns, and by including all three metrics: Score, Acc, and Cannot.Models in the tables are ranked by score. Models...
work page 1913
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.