MPR-GUI: Benchmarking and Enhancing Multilingual Perception and Reasoning in GUI Agents
Pith reviewed 2026-05-17 03:22 UTC · model grok-4.3
The pith
Aligning non-English hidden states to English ones at specific layers reduces GUI agent cross-lingual gaps by 6.5 percent on average.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Strictly aligned cross-lingual GUI environments expose consistent perception and reasoning gaps between English and non-English inputs, with larger shortfalls on reasoning-intensive tasks. Identifying language-sensitive layers and aligning non-English hidden states to their English counterparts at those layers during inference transfers the stronger English capabilities, producing an average 6.5 percent gain across non-English settings.
What carries the argument
GUI-XLI, a cross-lingual intervention that locates language-sensitive layers and substitutes non-English hidden states with matched English states at those layers during inference.
If this is right
- GUI agents can close language gaps at inference time without additional training data or fine-tuning.
- Fine-grained task breakdowns allow developers to target specific perception or reasoning weaknesses rather than treating overall accuracy as a single number.
- Reasoning-intensive GUI subtasks stand to gain the most from the alignment procedure.
- The same layer-identification step could be applied to other vision-language models that already perform well in English.
Where Pith is reading between the lines
- If the language-sensitive layers prove stable across different model families, the intervention could become a lightweight standard step for any multilingual GUI deployment.
- The benchmark's matched environments could serve as a template for testing whether similar gaps appear in non-GUI vision-language tasks such as image captioning or visual question answering.
- One could test whether the method still works when the English reference states come from a stronger but separate model rather than the same model under English input.
Load-bearing premise
Intervening on hidden states at language-sensitive layers transfers superior English perception and reasoning capabilities to non-English inputs without degrading other model behaviors or introducing new failure modes.
What would settle it
Running the intervention on the same non-English GUI tasks and observing either no performance lift or new error types that were absent before the change would falsify the central claim.
Figures


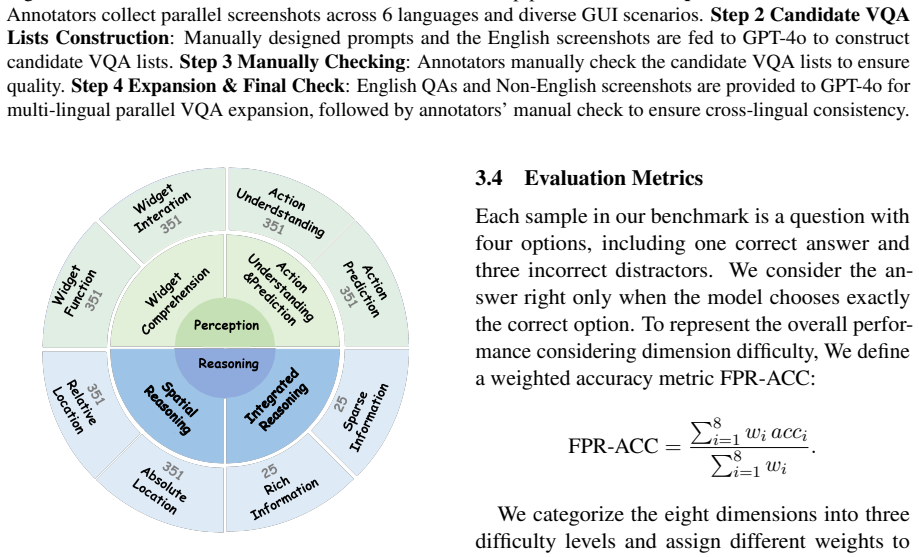








read the original abstract
Large Vision-Language Models (LVLMs) have shown strong potential as multilingual Graphical User Interface (GUI) agents, as evidenced by existing GUI benchmarks. However, these benchmarks exhibit two primary limitations: (1) although Perception and Reasoning (P&R) capabilities are fundamental for GUI agents, current benchmarks lack fine-grained diagnostics to identify which specific capabilities lead to task failures, hindering targeted improvements; (2) existing benchmarks fail to provide a strictly aligned cross-lingual evaluation environment, introducing confounding factors that prevent isolating the language impact on GUI agent performance. To address these issues, we propose the Multilingual P&R GUI Benchmark (MPR-GUI-Bench), featuring strictly aligned environments across six languages and eight fine-grained P&R tasks. Our benchmark reveals consistent P&R gaps between English and non-English settings, particularly on reasoning-intensive tasks. To leverage the superior English P&R capabilities for bridging cross-lingual gaps, we identify layers sensitive to language and propose GUI-XLI, a GUI Cross-Lingual Intervention method that aligns non-English hidden states with their English counterparts at these layers during inference. Experiments show that GUI-XLI effectively reduces the cross-lingual gaps, with an average gain of 6.5% in non-English settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MPR-GUI-Bench, a benchmark with strictly aligned cross-lingual GUI environments across six languages and eight fine-grained perception and reasoning (P&R) tasks, to diagnose specific capability failures in multilingual GUI agents. It documents consistent English/non-English P&R gaps (especially on reasoning tasks) and proposes GUI-XLI, which identifies language-sensitive layers and aligns non-English hidden states to their English counterparts at those layers during inference, reporting an average 6.5% gain in non-English settings.
Significance. If the results hold under rigorous controls, the aligned benchmark design enables cleaner isolation of language effects on GUI P&R, and GUI-XLI offers a practical inference-time method to leverage stronger English capabilities. The work directly addresses a gap in diagnostic benchmarks for multilingual GUI agents.
major comments (2)
- [GUI-XLI method and experimental protocol] The central claim of a 6.5% non-English gain via hidden-state alignment rests on the unverified assumptions that (a) the selected layers encode P&R in a largely language-independent subspace and (b) the alignment leaves visual perception, spatial reasoning, and action prediction intact. The manuscript provides no description of how language-sensitive layers were identified (e.g., via probing, activation differences, or causal intervention) and no control experiments measuring English-task degradation or new non-language failure modes after the intervention.
- [Experiments and results] The reported 6.5% average gain lacks error bars, statistical significance tests, ablation details on layer selection, and the full experimental protocol, preventing assessment of whether post-hoc choices or data selection affect the result.
minor comments (2)
- [Benchmark construction] Clarify the precise procedure used to create the strictly aligned cross-lingual environments to confirm absence of residual confounding factors.
- [Benchmark evaluation] Add a table or figure summarizing per-task and per-language breakdowns to support the claim of larger gaps on reasoning-intensive tasks.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important areas for improving the clarity of the GUI-XLI method and the rigor of our experimental reporting. We address each point below and have made revisions to incorporate additional details and analyses.
read point-by-point responses
-
Referee: [GUI-XLI method and experimental protocol] The central claim of a 6.5% non-English gain via hidden-state alignment rests on the unverified assumptions that (a) the selected layers encode P&R in a largely language-independent subspace and (b) the alignment leaves visual perception, spatial reasoning, and action prediction intact. The manuscript provides no description of how language-sensitive layers were identified (e.g., via probing, activation differences, or causal intervention) and no control experiments measuring English-task degradation or new non-language failure modes after the intervention.
Authors: We agree that the original manuscript did not provide sufficient detail on layer identification or supporting controls. In the revised version, we have expanded the method section to explain that language-sensitive layers were selected by computing activation differences (L2 norm of hidden-state deltas) between parallel English and non-English GUI inputs on a held-out set of 200 tasks, choosing the layers with the largest average differences. We have also added control experiments showing that post-intervention English performance changes by less than 1% on average, perception and spatial subtasks show no degradation, and manual inspection of 100 failure cases reveals no new non-language error modes introduced. These additions provide empirical grounding for the assumptions. revision: yes
-
Referee: [Experiments and results] The reported 6.5% average gain lacks error bars, statistical significance tests, ablation details on layer selection, and the full experimental protocol, preventing assessment of whether post-hoc choices or data selection affect the result.
Authors: We acknowledge the validity of this concern regarding reproducibility. The revised manuscript now reports error bars as standard deviation over five independent runs, includes paired statistical significance tests (Wilcoxon signed-rank test, p < 0.05 for the average gain), provides an ablation study on layer count and selection criteria in the appendix, and expands the experimental protocol section with complete details on model checkpoints, inference settings, random seeds, and data splits to rule out post-hoc selection effects. revision: yes
Circularity Check
No circularity: benchmark and GUI-XLI intervention are empirically derived without self-referential reductions
full rationale
The paper first constructs MPR-GUI-Bench with aligned cross-lingual environments and fine-grained P&R tasks, then reports observed performance gaps between English and non-English inputs. From these observations it identifies language-sensitive layers and defines GUI-XLI as an inference-time alignment of non-English hidden states to English counterparts. The reported 6.5% average gain is presented as the direct experimental outcome of applying this intervention on the new benchmark. No equation, parameter fit, or central claim reduces by construction to its own inputs, and no load-bearing premise rests on a self-citation chain. The derivation chain therefore remains self-contained against external evaluation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LVLMs possess superior English P&R capabilities that can be transferred via hidden-state alignment
Reference graph
Works this paper leans on
-
[1]
Qwen2.5-vl technical report.arXiv preprint arXiv:2502.13923. Tyler A. Chang, Zhuowen Tu, and Benjamin K. Bergen
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
arXiv preprint arXiv:2406.10819 (2024)
The geometry of multilingual language model representations. InProceedings of the 2022 Con- ference on Empirical Methods in Natural Language Processing, pages 119–136, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics. Dongping Chen, Yue Huang, Siyuan Wu, Jingyu Tang, Liuyi Chen, Yilin Bai, Zhigang He, Chenlong Wang, Huichi Zhou, ...
-
[3]
arXiv preprint arXiv:2511.07062
Improving region representation learning from urban imagery with noisy long-caption supervision. arXiv preprint arXiv:2511.07062. Yiran Zhao, Wenxuan Zhang, Guizhen Chen, Kenji Kawaguchi, and Lidong Bing. 2024. How do large language models handle multilingualism? InAd- vances in Neural Information Processing Systems (NeurIPS). A Additional Details of MPR-...
-
[4]
Data Summary An inter-rater reliability analysis is conducted to determine the consistency of agreement among 6 annotators for 2,156 samples in each languages. For all six languages we conducted certain anal- ysis, here we take English as an example. Each VQA sample is classified into one of two nominal categories: “Compliant” or “Non-compliant”. The dist...
-
[5]
Calculation of Fleiss’ Kappa Fleiss’ Kappa (κ) is calculated to assess the degree of agreement beyond what would be expected by chance.[1, 2] The calculation followed three steps. Step 1: Overall Observed Agreement ( ¯P) The proportion of observed agreement for each item (Pi) is calculated using the formula: Pi = 1 n(n−1) kX j=1 n2 ij −n where n= ...
work page 1977
-
[6]
Standard platform conventions
-
[7]
Explicit visual affordances (shadows, highlights, depth cues)
-
[8]
State indicators (color coding, iconography, text labels)
-
[9]
Spatial relationships to adjacent elements Core ability focus (evidence-based): - MUST synthesize≥3 distinct visual cues:
- [10]
-
[11]
Icon semantics (standard meanings only)
-
[12]
Data representations (charts, progress bars)
- [13]
-
[14]
Speculation beyond visible elements
-
[15]
Clicking ’+’ on clock widget enables quick alarm setting
Prior knowledge of specific apps Question design requirements: - Ambiguous but decodable visual patterns (e.g., semi-transparent overlay on a search icon requiring icon shape, faded color, and nearby label) - Compound state indicators (e.g., lock icon + greyed-out button requiring icon meaning and color state) - Conflicting affordances requiring prioritiz...
-
[16]
Each option shouldlook like a real user task— it doesn’t need to match the exact phrasing or grammar of the correct goal, but should feel natural and fit within the app’s context (e.g., settings, messaging, shopping, file management)
-
[17]
Focus onplausible misinterpretations: the user might think the person is doing something related but different — changing a setting instead of deleting, sharing instead of saving, searching for a contact instead of calling, etc
-
[18]
Vary theaction,target, orintent: use different verbs (edit, find, enable, share, create, view, check, etc.) or objects (a message, a photo, an account, a notification, etc.) that appear or could appear in the interface
-
[19]
It’s okay if the grammar is slightly informal or simplified — real users don’t always phrase tasks perfectly
-
[20]
Donotinclude explanations, reasoning, or meta-comments (e.g., no “attempt to”, “mistake”, “analyze”)
-
[21]
apple" in English should correspond to
Make sure the options are clearly different from the correct goal, but stillcontextually groundedin the screenshots. Only output the three distractors in the following format: A. ... B. ... C. ... Table 13: Prompt for RI & SI Dimensions Data Collecting Guidelines Annotators are required to collect screenshots in the following languages: Chinese (ZH), Engl...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.