Reward Auditor: Inference on Reward Modeling Suitability in Real-World Perturbed Scenarios
Pith reviewed 2026-05-21 18:22 UTC · model grok-4.3
The pith
Reward Auditor infers systematic vulnerabilities in reward models by auditing degradation in preference confidence distributions under real-world perturbations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Reward Auditor is a hypothesis-testing framework designed for RM suitability inference. Under real-world perturbed scenarios, it quantifies statistical significance and effect size by auditing distribution degradation of RM preference perception confidence. This enables inference of both the certainty and severity of RM vulnerabilities across diverse real-world scenarios, rather than merely reporting accuracies in specific scenarios.
What carries the argument
Reward Auditor, a hypothesis-testing framework that audits the degradation of the distribution of reward model preference perception confidence under perturbations to infer suitability.
If this is right
- Reward models can now be evaluated for conditional reliability rather than just scenario-specific accuracy.
- Both the certainty (statistical significance) and severity (effect size) of vulnerabilities can be inferred for different perturbations.
- This approach supports the creation of verifiably safe, robust, and trustworthy LLM alignment systems.
- The framework allows identification of systematic vulnerabilities in specific real-world scenarios.
Where Pith is reading between the lines
- Developers could apply the auditor to select or train reward models that show less degradation on perturbations relevant to their deployment.
- Future work might compare the vulnerabilities revealed by this method to actual downstream performance drops in deployed systems.
- This statistical auditing lens could be adapted to test other components of LLM pipelines, such as safety classifiers, under similar perturbations.
- Integrating it with existing preference datasets might reveal which types of perturbations most reliably expose weaknesses.
Load-bearing premise
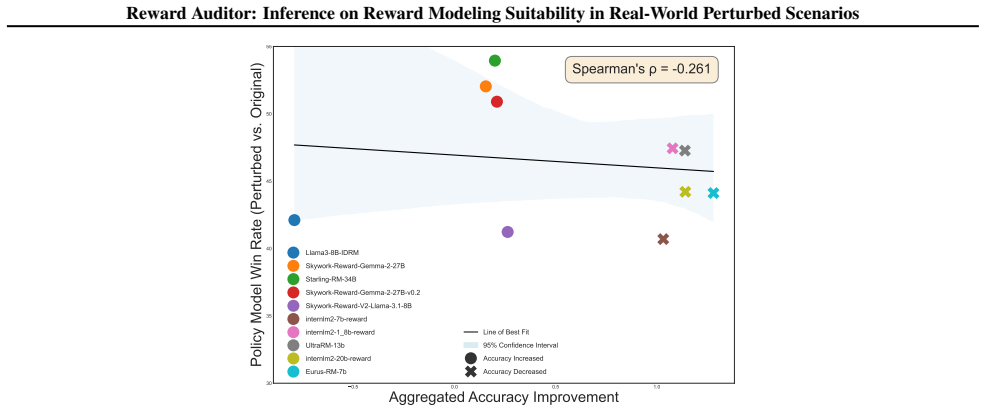
Degradation in the distribution of preference perception confidence under the chosen perturbations indicates systematic vulnerabilities in the reward model's suitability for real-world use, as opposed to other influences like prompt sensitivity or noise.
What would settle it
Observing no significant degradation in confidence distributions for a reward model that is known to fail in real-world perturbed scenarios, or finding degradation without corresponding real-world failures, would falsify the inference method.
Figures









read the original abstract
Reliable reward models (RMs) are critical for ensuring the safe alignment of large language models (LLMs). However, current RM evaluation methods focus solely on preference perception accuracies in given specific scenarios, obscuring the critical vulnerabilities of RMs in real-world scenarios. We identify the true challenge lies in assessing a novel dimension: Suitability, defined as conditional reliability under specific real-world perturbations. To this end, we introduce Reward Auditor, a hypothesis-testing framework specifically designed for RM suitability inference. Rather than answering "How accurate is the RM's preference perception for given samples?", it employs scientific auditing to answer: "Can we infer RMs exhibit systematic vulnerabilities in specific real-world scenarios?". Under real-world perturbed scenarios, Reward Auditor quantifies statistical significance and effect size by auditing distribution degradation of RM preference perception confidence. This enables inference of both the certainty and severity of RM vulnerabilities across diverse real-world scenarios. This lays a solid foundation for building next-generation LLM alignment systems that are verifiably safe, more robust, and trustworthy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Reward Auditor, a hypothesis-testing framework for assessing the suitability of reward models (RMs) in real-world perturbed scenarios. Suitability is defined as the conditional reliability of RMs under specific perturbations. The framework uses auditing of distribution degradation in RM preference perception confidence to quantify statistical significance and effect size, enabling inferences about the certainty and severity of RM vulnerabilities across diverse scenarios.
Significance. If empirically validated with appropriate controls, this framework could significantly improve the evaluation of RMs by focusing on their robustness to real-world perturbations rather than just accuracy in fixed scenarios, potentially leading to more reliable LLM alignment systems. The emphasis on statistical auditing provides a quantifiable way to assess vulnerabilities.
major comments (2)
- The abstract describes the intended statistical approach but supplies no concrete data, test details, validation results, or error analysis, leaving it unclear whether the claimed inferences are supported.
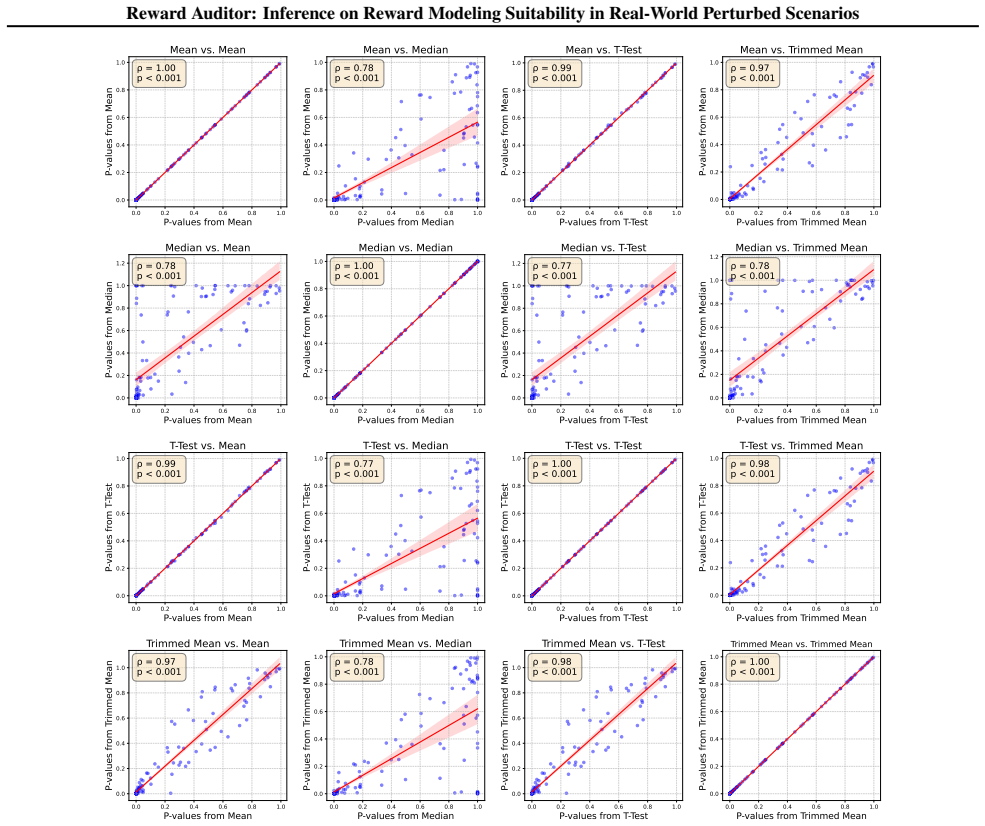
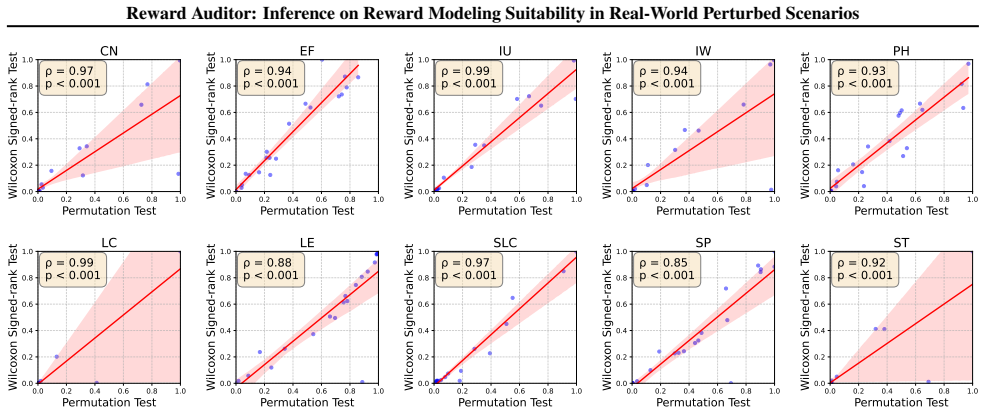
- The central inference that distribution degradation under perturbations indicates RM suitability vulnerabilities lacks supporting controls or baselines to isolate RM-specific effects from generic perturbation impacts like prompt sensitivity or noise. This assumption is load-bearing for the claims about inferring systematic vulnerabilities.
Simulated Author's Rebuttal
We thank the referee for their constructive and insightful comments. We address each major comment below, providing clarifications from the manuscript and indicating planned revisions where appropriate to improve clarity and rigor.
read point-by-point responses
-
Referee: The abstract describes the intended statistical approach but supplies no concrete data, test details, validation results, or error analysis, leaving it unclear whether the claimed inferences are supported.
Authors: We acknowledge that the abstract is high-level by design. The full manuscript details the hypothesis-testing procedure (including specific tests for distribution degradation such as Kolmogorov-Smirnov statistics), concrete perturbation scenarios, datasets, and validation results with reported p-values and effect sizes in Sections 3 and 4, along with error analysis in the appendix. To improve accessibility, we will revise the abstract to briefly reference key empirical outcomes supporting the inferences. revision: yes
-
Referee: The central inference that distribution degradation under perturbations indicates RM suitability vulnerabilities lacks supporting controls or baselines to isolate RM-specific effects from generic perturbation impacts like prompt sensitivity or noise. This assumption is load-bearing for the claims about inferring systematic vulnerabilities.
Authors: This concern is well-taken. The manuscript employs paired-sample comparisons between original and perturbed inputs for the same RM to control for generic prompt sensitivity, and includes a random-preference baseline model audited under identical perturbations to isolate RM-specific degradation effects. We will add an expanded subsection explicitly discussing these controls and their role in supporting the inference of systematic vulnerabilities. revision: partial
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper introduces Reward Auditor as a hypothesis-testing framework that applies standard statistical auditing to quantify significance and effect size from distribution degradation of preference perception confidence under perturbations, with suitability defined as conditional reliability. No equations, derivations, or self-referential reductions appear that would make any prediction equivalent to its inputs by construction, nor are there load-bearing self-citations or fitted parameters renamed as outputs. The central claim rests on applying established hypothesis testing to observed distributions rather than any internal loop or ansatz smuggled via prior work, rendering the framework self-contained against external statistical benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Statistical significance and effect size computed from confidence distribution degradation reliably indicate systematic RM vulnerabilities under real-world conditions.
invented entities (1)
-
Suitability
no independent evidence
Forward citations
Cited by 5 Pith papers
-
BoostAPR: Boosting Automated Program Repair via Execution-Grounded Reinforcement Learning with Dual Reward Models
BoostAPR improves automated program repair by using execution-grounded RL with a sequence-level assessor and line-level credit allocator, reaching 40.7% on SWE-bench Verified and strong cross-language results.
-
PlanViz: Evaluating Planning-Oriented Image Generation and Editing for Computer-Use Tasks
PlanViz is a new benchmark with three sub-tasks and PlanScore metric to evaluate planning-oriented image generation and editing by unified multimodal models for computer-use tasks.
-
BoostAPR: Boosting Automated Program Repair via Execution-Grounded Reinforcement Learning with Dual Reward Models
BoostAPR uses supervised fine-tuning on verified fixes, dual sequence- and line-level reward models from execution feedback, and PPO to reach 40.7% on SWE-bench Verified with strong cross-language results.
-
BoostAPR: Boosting Automated Program Repair via Execution-Grounded Reinforcement Learning with Dual Reward Models
BoostAPR boosts automated program repair by training a sequence-level assessor and line-level credit allocator from execution outcomes, then applying them in PPO to reach 40.7% on SWE-bench Verified.
-
The Efficiency Frontier: A Unified Framework for Cost-Performance Optimization in LLM Context Management
Introduces Efficiency Frontier framework for deployment-aware cost-performance optimization of LLM context strategies, reporting ~25% token reduction at F1≈0.78 on 5,000 HotpotQA instances.
Reference graph
Works this paper leans on
-
[1]
is a standard statistical procedure that assesses normality by quantifying deviations in sample skewness and kurtosis from that of a normal distribution. A statistically significant result (i.e., a small p-value) implies that we can reject the null hypothesis that the data follows a normal distribution. The normality test results presented in Table 2 reve...
work page 2007
-
[2]
and Reward Bench (Lambert et al., 2024). Figure 7 visually illustrates the distinct characteristics and capabilities of these two datasets when used as testing benchmarks, leading to the following key conclusions: ♂lightbulbReward Bench proves more challenging and comprehensive in exposing vulnerabilities in RMs.In terms of the breadth of problem exposure...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.