Recognition: 2 theorem links
· Lean TheoremAVI-Edit: Audio-sync Video Instance Editing with Granularity-Aware Mask Refiner
Pith reviewed 2026-05-16 23:23 UTC · model grok-4.3
The pith
AVI-Edit refines user masks into precise instance regions and uses audio feedback to control edit timing in videos.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
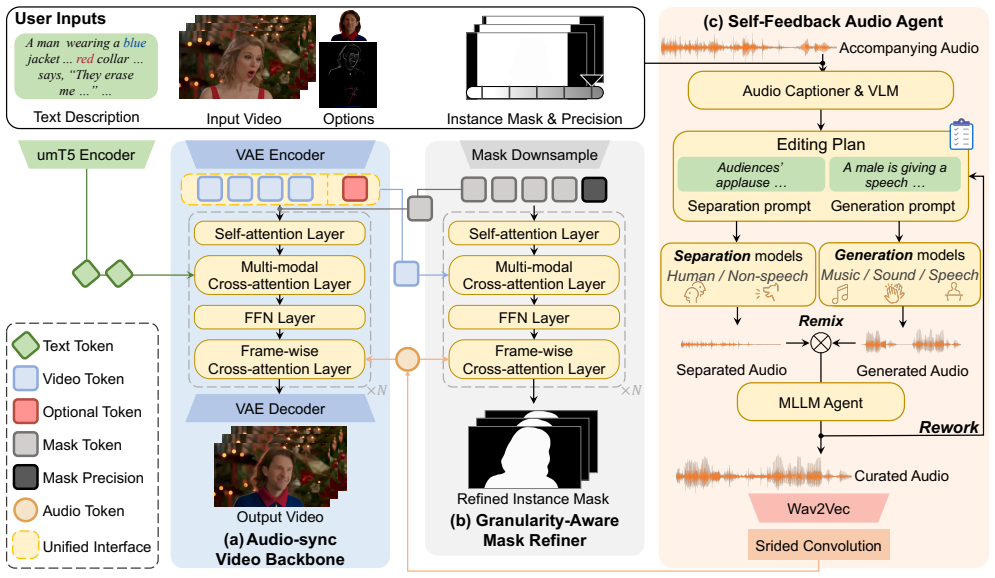
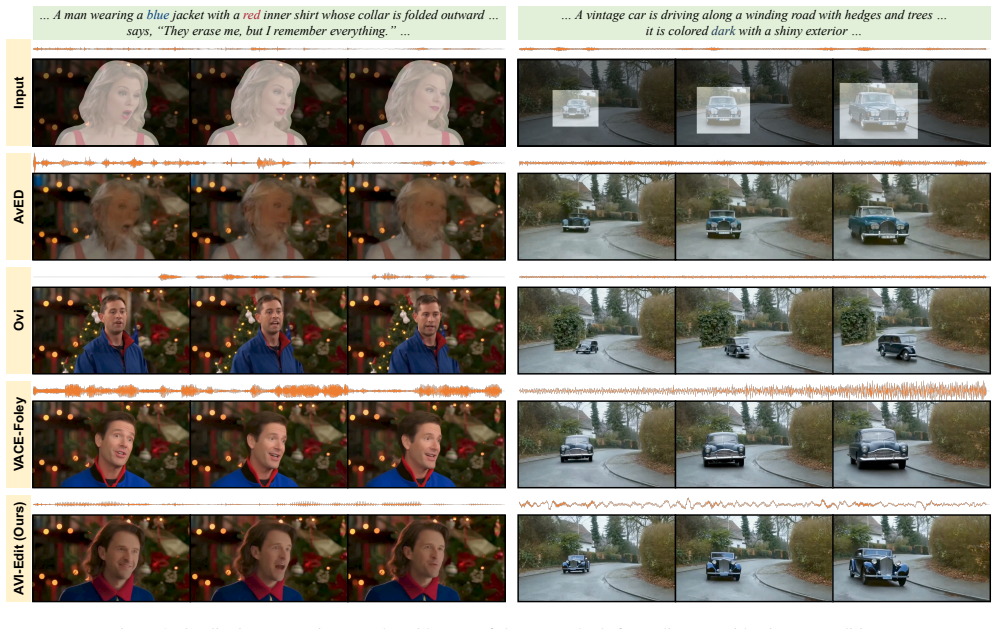
AVI-Edit achieves audio-synchronized video instance editing by iteratively refining coarse user masks into accurate instance-level regions with a granularity-aware mask refiner and by using a self-feedback audio agent to curate fine-grained temporal guidance from the audio, all supported by a newly constructed large-scale dataset with instance-centric correspondence annotations.
What carries the argument
The granularity-aware mask refiner that iteratively converts coarse user-provided masks into precise instance-level regions, together with the self-feedback audio agent that supplies detailed temporal control signals derived from the audio track.
If this is right
- Users gain independent control over individual objects in a scene while the rest of the video remains unchanged.
- Audio itself supplies the timing cues that decide when an edit begins, ends, or changes intensity.
- The released dataset supplies paired instance masks and audio tracks that can serve as training material for related audio-conditioned editing tasks.
- The same pipeline can be applied to different source videos without retraining the core components from scratch.
Where Pith is reading between the lines
- The mask refiner could be swapped with newer segmentation models to handle more challenging initial inputs such as occluded or fast-moving objects.
- Extending the audio agent to accept spoken natural-language instructions might allow users to describe edits in words rather than masks.
- The dataset annotations could be reused to benchmark other audio-video alignment techniques outside the editing setting.
Load-bearing premise
The mask refiner can turn rough user inputs into exact object boundaries without leaking into background or missing parts of the instance, and the audio agent can reliably produce usable timing guidance in every case.
What would settle it
A test video in which the refined mask either includes unrelated background pixels or excludes portions of the target object, or in which the final edited output shows actions or movements that visibly drift out of sync with the original audio.
Figures






read the original abstract
Recent advancements in video generation highlight that realistic audio-visual synchronization is crucial for engaging content creation. However, existing video editing methods largely overlook audio-visual synchronization and lack the fine-grained spatial and temporal controllability required for precise instance-level edits. In this paper, we propose AVI-Edit, a framework for audio-sync video instance editing. We propose a granularity-aware mask refiner that iteratively refines coarse user-provided masks into precise instance-level regions. We further design a self-feedback audio agent to curate high-quality audio guidance, providing fine-grained temporal control. To facilitate this task, we additionally construct a large-scale dataset with instance-centric correspondence and comprehensive annotations. Extensive experiments demonstrate that AVI-Edit outperforms state-of-the-art methods in visual quality, condition following, and audio-visual synchronization. Project page: https://hjzheng.net/projects/AVI-Edit/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AVI-Edit, a framework for audio-synchronized video instance editing. It proposes a granularity-aware mask refiner that iteratively converts coarse user-provided masks into precise instance-level regions, along with a self-feedback audio agent that curates high-quality temporal audio guidance. A new large-scale dataset with instance-centric correspondence and annotations is constructed to support training and evaluation. Experiments claim that AVI-Edit outperforms prior methods in visual quality, condition following, and audio-visual synchronization.
Significance. If the reported gains hold under rigorous evaluation, the work addresses an important gap in video editing by jointly handling fine-grained spatial instance control and audio-visual temporal alignment. The granularity-aware refiner and self-feedback agent provide concrete architectural mechanisms for these capabilities, and the new dataset with instance-level annotations could serve as a useful benchmark resource for the community.
minor comments (3)
- [§3.2] §3.2: The integration of the self-feedback audio agent into the overall editing pipeline is described at a high level; adding a diagram or pseudocode for the iterative curation loop would improve reproducibility.
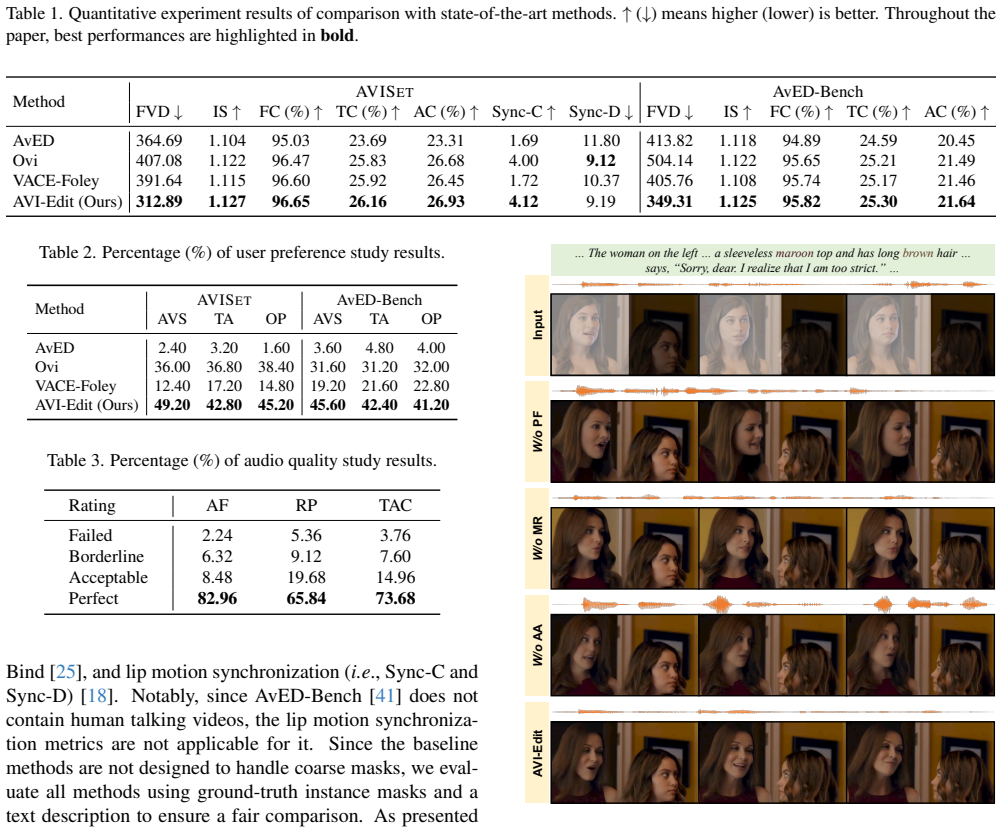
- [Table 2] Table 2: The quantitative comparison table reports improvements in audio-visual synchronization but does not list the exact synchronization metric (e.g., AVSync score or lip-sync error); clarify the primary metric used for the headline claim.
- [§4.1] §4.1: Dataset statistics (number of videos, average instance count per video, annotation protocol) are summarized briefly; expanding this subsection with a table of key statistics would strengthen the contribution description.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of our manuscript and the recommendation for minor revision. We are pleased that the significance of jointly addressing fine-grained spatial instance control and audio-visual temporal alignment is recognized, along with the potential utility of the proposed granularity-aware mask refiner, self-feedback audio agent, and the new instance-centric dataset.
Circularity Check
No significant circularity detected
full rationale
The paper introduces a new editing framework consisting of a granularity-aware mask refiner and a self-feedback audio agent, along with a newly constructed dataset for training and evaluation. No equations, fitted parameters, or derivation chains are present in the provided text. Claims of outperformance rest on experimental comparisons rather than any self-referential definitions, predictions that reduce to inputs by construction, or load-bearing self-citations. The method descriptions specify architectural details and objectives independently of the target results.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
granularity-aware mask refiner that iteratively refines coarse user-provided masks into precise instance-level regions... self-feedback audio agent to curate high-quality audio guidance
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
flow matching objective... Wan2.2-5B diffusion transformer
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Free AI V oice Generator & V oice Agents Platform.https: //elevenlabs.io. 5
-
[2]
Veo 3 | Google AI Studio.https : / / aistudio . google.com/models/veo-3. 2
-
[3]
ElevenLabs — Meet Scribe the world’s most accurate ASR model, 2025.https : / / elevenlabs . io / blog / meet-scribe. 3
work page 2025
-
[4]
Sora 2 is here, 2025.https://openai.com/index/ sora-2/. 2
work page 2025
-
[5]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv:2502.13923,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Condensed movies: Story based retrieval with con- textual embeddings
Max Bain, Arsha Nagrani, Andrew Brown, and Andrew Zis- serman. Condensed movies: Story based retrieval with con- textual embeddings. InACCV, 2020. 3
work page 2020
-
[7]
Ar- tificial intelligence for advertising and media: machine learn- ing and neural networks
Bibars Al Haj Bara, Nadezhda N Pokrovskaia, Marianna Yu Ababkova, Irina A Brusakova, and Anastasia A Korban. Ar- tificial intelligence for advertising and media: machine learn- ing and neural networks. InElConRus, 2022. 2
work page 2022
-
[8]
Stanislav Beliaev and Boris Ginsburg. TalkNet 2: Non- autoregressive depth-wise separable convolutional model for speech synthesis with explicit pitch and duration prediction. arXiv:2104.08189, 2021. 3
-
[9]
VideoPainter: Any- length video inpainting and editing with plug-and-play con- text control
Yuxuan Bian, Zhaoyang Zhang, Xuan Ju, Mingdeng Cao, Liangbin Xie, Ying Shan, and Qiang Xu. VideoPainter: Any- length video inpainting and editing with plug-and-play con- text control. InSIGGRAPH, 2025. 2
work page 2025
-
[10]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv:2311.15127, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Ge- nie: Generative interactive environments
Jake Bruce, Michael D Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, et al. Ge- nie: Generative interactive environments. InForty-first Inter- national Conference on Machine Learning, 2024. 2
work page 2024
-
[12]
PySceneDetect, 2025.https:// github.com/Breakthrough/PySceneDetect
Brandon Castellano. PySceneDetect, 2025.https:// github.com/Breakthrough/PySceneDetect. 3
work page 2025
-
[13]
VGGSound: A large-scale audio-visual dataset
Honglie Chen, Weidi Xie, Andrea Vedaldi, and Andrew Zis- serman. VGGSound: A large-scale audio-visual dataset. In ICASSP, 2020. 3
work page 2020
-
[14]
Ming Chen, Liyuan Cui, Wenyuan Zhang, Haoxian Zhang, Yan Zhou, Xiaohan Li, Songlin Tang, Jiwen Liu, Borui Liao, Hejia Chen, et al. MIDAS: Multimodal interactive digital- human synthesis via real-time autoregressive video genera- tion.arXiv:2508.19320, 2025. 3
-
[15]
Yiyang Chen, Xuanhua He, Xiujun Ma, and Yue Ma. Con- textFlow: Training-free video object editing via adaptive context enrichment.arXiv:2509.17818, 2025. 2
-
[16]
O-DisCo-Edit: Object distortion control for unified realistic video editing
Yuqing Chen, Junjie Wang, Lin Liu, Ruihang Chu, Xi- aopeng Zhang, Qi Tian, and Yujiu Yang. O-DisCo-Edit: Object distortion control for unified realistic video editing. arXiv:2509.01596, 2025. 2
-
[17]
OmniSep: Unified omni-modality sound separation with query-mixup.arXiv:2410.21269, 2024
Xize Cheng, Siqi Zheng, Zehan Wang, Minghui Fang, Ziang Zhang, Rongjie Huang, Ziyang Ma, Shengpeng Ji, Jialong Zuo, Tao Jin, et al. OmniSep: Unified omni-modality sound separation with query-mixup.arXiv:2410.21269, 2024. 5
-
[18]
Out of time: au- tomated lip sync in the wild
Joon Son Chung and Andrew Zisserman. Out of time: au- tomated lip sync in the wild. InACCV Workshops, 2017. 7, 11
work page 2017
-
[19]
Taming transformers for high-resolution image synthesis
Patrick Esser, Robin Rombach, and Björn Ommer. Taming transformers for high-resolution image synthesis. InCVPR,
-
[20]
The pascal visual object classes (voc) challenge.IJCV, 2010
Mark Everingham, Luc Van Gool, Christopher KI Williams, John Winn, and Andrew Zisserman. The pascal visual object classes (voc) challenge.IJCV, 2010. 10
work page 2010
-
[21]
Object-A VEdit: An object-level audio-visual editing model.arXiv:2510.00050, 2025
Youquan Fu, Ruiyang Si, Hongfa Wang, Dongzhan Zhou, Jiacheng Sun, Ping Luo, Di Hu, Hongyuan Zhang, and Xue- long Li. Object-A VEdit: An object-level audio-visual editing model.arXiv:2510.00050, 2025. 2, 3
-
[22]
Long video generation with time-agnostic vqgan and time- sensitive transformer
Songwei Ge, Thomas Hayes, Harry Yang, Xi Yin, Guan Pang, David Jacobs, Jia-Bin Huang, and Devi Parikh. Long video generation with time-agnostic vqgan and time- sensitive transformer. InECCV, 2022. 3
work page 2022
-
[23]
AudioSet: An ontology and human- labeled dataset for audio events
Jort F Gemmeke, Daniel PW Ellis, Dylan Freedman, Aren Jansen, Wade Lawrence, R Channing Moore, Manoj Plakal, and Marvin Ritter. AudioSet: An ontology and human- labeled dataset for audio events. InICASSP, 2017. 3
work page 2017
-
[24]
Short film dataset (SFD): A benchmark for story- level video understanding.arXiv:2406.10221, 2024
Ridouane Ghermi, Xi Wang, Vicky Kalogeiton, and Ivan Laptev. Short film dataset (SFD): A benchmark for story- level video understanding.arXiv:2406.10221, 2024. 3
-
[25]
ImageBind: One embedding space to bind them all
Rohit Girdhar, Alaaeldin El-Nouby, Zhuang Liu, Mannat Singh, Kalyan Vasudev Alwala, Armand Joulin, and Ishan Misra. ImageBind: One embedding space to bind them all. InCVPR, 2023. 7, 11
work page 2023
-
[26]
AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
Yuwei Guo, Ceyuan Yang, Anyi Rao, Zhengyang Liang, Yaohui Wang, Yu Qiao, Maneesh Agrawala, Dahua Lin, and Bo Dai. AnimateDiff: Animate your personal- ized text-to-image diffusion models without specific tuning. arXiv:2307.04725, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
Romain Hennequin, Anis Khlif, Felix V oituret, and Manuel Moussallam. Spleeter: a fast and efficient music source sep- aration tool with pre-trained models.Journal of Open Source Software, 2020. 5
work page 2020
-
[28]
Träumerai: Dreaming music with stylegan
Dasaem Jeong, Seungheon Doh, and Taegyun Kwon. Träumerai: Dreaming music with stylegan. arXiv:2102.04680, 2021. 3
-
[29]
VACE: All-in-One Video Creation and Editing
Zeyinzi Jiang, Zhen Han, Chaojie Mao, Jingfeng Zhang, Yulin Pan, and Yu Liu. V ACE: All-in-one video creation and editing.arXiv:2503.07598, 2025. 2, 6, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
RA VE: Randomized noise shuf- fling for fast and consistent video editing with diffusion mod- els
Ozgur Kara, Bariscan Kurtkaya, Hidir Yesiltepe, James M Rehg, and Pinar Yanardag. RA VE: Randomized noise shuf- fling for fast and consistent video editing with diffusion mod- els. InCVPR, 2024. 2
work page 2024
-
[31]
A style-based generator architecture for generative adversarial networks
Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. In CVPR, 2019. 3
work page 2019
-
[32]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv:1412.6980, 2014. 6 13
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[33]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. HunyuanVideo: A systematic framework for large video generative models.arXiv:2412.03603, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dock- horn, Jack English, Zion English, Patrick Esser, et al. FLUX. 1 Kontext: Flow matching for in-context image generation and editing in latent space.arXiv:2506.15742, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Crossing you in style: Cross-modal style transfer from music to visual arts
Cheng-Che Lee, Wan-Yi Lin, Yen-Ting Shih, Pei-Yi Kuo, and Li Su. Crossing you in style: Cross-modal style transfer from music to visual arts. InACM MM, 2020. 2
work page 2020
-
[36]
Sound-guided semantic video generation
Seung Hyun Lee, Gyeongrok Oh, Wonmin Byeon, Chany- oung Kim, Won Jeong Ryoo, Sang Ho Yoon, Hyunjun Cho, Jihyun Bae, Jinkyu Kim, and Sangpil Kim. Sound-guided semantic video generation. InECCV, 2022. 3
work page 2022
-
[37]
Soundini: Sound-guided diffusion for natural video editing.arXiv:2304.06818, 2023
Seung Hyun Lee, Sieun Kim, Innfarn Yoo, Feng Yang, Donghyeon Cho, Youngseo Kim, Huiwen Chang, Jinkyu Kim, and Sangpil Kim. Soundini: Sound-guided diffusion for natural video editing.arXiv:2304.06818, 2023. 3
-
[38]
Generating realistic images from in-the-wild sounds
Taegyeong Lee, Jeonghun Kang, Hyeonyu Kim, and Tae- hwan Kim. Generating realistic images from in-the-wild sounds. InICCV, 2023. 2
work page 2023
-
[39]
VidToMe: Video token merging for zero-shot video editing
Xirui Li, Chao Ma, Xiaokang Yang, and Ming-Hsuan Yang. VidToMe: Video token merging for zero-shot video editing. InCVPR, 2024. 2
work page 2024
-
[40]
Focal loss for dense object detection
Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár. Focal loss for dense object detection. InICCV,
-
[41]
Zero-shot audio-visual editing via cross- modal delta denoising.arXiv:2503.20782, 2025
Yan-Bo Lin, Kevin Lin, Zhengyuan Yang, Linjie Li, Jianfeng Wang, Chung-Ching Lin, Xiaofei Wang, Gedas Bertasius, and Lijuan Wang. Zero-shot audio-visual editing via cross- modal delta denoising.arXiv:2503.20782, 2025. 2, 3, 6, 7
-
[42]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximil- ian Nickel, and Matt Le. Flow matching for generative mod- eling.arXiv:2210.02747, 2022. 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[43]
Ovi: Twin Backbone Cross-Modal Fusion for Audio-Video Generation
Chetwin Low, Weimin Wang, and Calder Katyal. Ovi: Twin backbone cross-modal fusion for audio-video genera- tion.arXiv:2510.01284, 2025. 3, 6, 7
work page internal anchor Pith review arXiv 2025
-
[44]
Zero-shot unsupervised and text-based audio editing using ddpm inversion
Hila Manor and Tomer Michaeli. Zero-shot unsupervised and text-based audio editing using ddpm inversion. InICML,
-
[45]
Speech2Face: Learning the face behind a voice
Tae-Hyun Oh, Tali Dekel, Changil Kim, Inbar Mosseri, William T Freeman, Michael Rubinstein, and Wojciech Ma- tusik. Speech2Face: Learning the face behind a voice. In CVPR, 2019. 2
work page 2019
-
[46]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InICCV, 2023. 9
work page 2023
-
[47]
FateZero: Fus- ing attentions for zero-shot text-based video editing
Chenyang Qi, Xiaodong Cun, Yong Zhang, Chenyang Lei, Xintao Wang, Ying Shan, and Qifeng Chen. FateZero: Fus- ing attentions for zero-shot text-based video editing. In ICCV, 2023. 2
work page 2023
-
[48]
Learn- ing transferable visual models from natural language super- vision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learn- ing transferable visual models from natural language super- vision. InICML, 2021. 6, 11
work page 2021
-
[49]
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
Tianhe Ren, Shilong Liu, Ailing Zeng, Jing Lin, Kunchang Li, He Cao, Jiayu Chen, Xinyu Huang, Yukang Chen, Feng Yan, et al. Grounded SAM: Assembling open-world models for diverse visual tasks.arXiv:2401.14159, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[50]
Pydub, 2025.https://github.com/ jiaaro/pydub
James Robert. Pydub, 2025.https://github.com/ jiaaro/pydub. 5
work page 2025
-
[51]
High-resolution image syn- thesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image syn- thesis with latent diffusion models. InCVPR, 2022. 2
work page 2022
-
[52]
Improved techniques for training gans
Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved techniques for training gans. InNIPS, 2016. 6, 11
work page 2016
-
[53]
Improved aesthetic predictor, 2025
Christoph Schuhmann. Improved aesthetic predictor, 2025. https : / / github . com / christophschuhmann / improved-aesthetic-predictor. 3
work page 2025
-
[54]
Sizhe Shan, Qiulin Li, Yutao Cui, Miles Yang, Yuehai Wang, Qun Yang, Jin Zhou, and Zhao Zhong. HunyuanVideo- Foley: Multimodal diffusion with representation alignment for high-fidelity foley audio generation.arXiv:2508.16930,
-
[55]
AudioScenic: Audio-driven video scene editing
Kaixin Shen, Ruijie Quan, Linchao Zhu, Jun Xiao, and Yi Yang. AudioScenic: Audio-driven video scene editing. arXiv:2404.16581, 2024. 3
-
[56]
Roman Solovyev. MVSEP-CDX23-Cinematic-Sound- Demixing, 2025.https://github.com/ZFTurbo/ MVSEP-CDX23-Cinematic-Sound-Demixing. 5
work page 2025
-
[57]
Raft: Recurrent all-pairs field transforms for optical flow
Zachary Teed and Jia Deng. Raft: Recurrent all-pairs field transforms for optical flow. InECCV, 2020. 3
work page 2020
-
[58]
Meta Audiobox Aesthetics: Unified Automatic Quality Assessment for Speech, Music, and Sound
Andros Tjandra, Yi-Chiao Wu, Baishan Guo, John Hoffman, Brian Ellis, Apoorv Vyas, Bowen Shi, Sanyuan Chen, Matt Le, Nick Zacharov, et al. Meta audiobox aesthetics: Unified automatic quality assessment for speech, music, and sound. arXiv:2502.05139, 2025. 3
work page internal anchor Pith review arXiv 2025
-
[59]
Towards Accurate Generative Models of Video: A New Metric & Challenges
Thomas Unterthiner, Sjoerd Van Steenkiste, Karol Kurach, Raphael Marinier, Marcin Michalski, and Sylvain Gelly. To- wards accurate generative models of video: A new metric & challenges.arXiv:1812.01717, 2018. 6, 11
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[60]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianx- iao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv:2503.20314, 2025. 2, 4, 6, 8
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[61]
Universe-1: Unified audio-video generation via stitching of experts
Duomin Wang, Wei Zuo, Aojie Li, Ling-Hao Chen, Xinyao Liao, Deyu Zhou, Zixin Yin, Xili Dai, Daxin Jiang, and Gang Yu. UniVerse-1: Unified audio-video generation via stitch- ing of experts.arXiv:2509.06155, 2025. 3
-
[62]
VideoCLIP-XL: Advancing long descrip- tion understanding for video clip models.arXiv:2410.00741,
Jiapeng Wang, Chengyu Wang, Kunzhe Huang, Jun Huang, and Lianwen Jin. VideoCLIP-XL: Advancing long descrip- tion understanding for video clip models.arXiv:2410.00741,
-
[63]
Zhenzhi Wang, Jiaqi Yang, Jianwen Jiang, Chao Liang, Gao- jie Lin, Zerong Zheng, Ceyuan Yang, and Dahua Lin. In- terActHuman: Multi-concept human animation with layout- aligned audio conditions.arXiv:2506.09984, 2025. 3
-
[64]
Audio-sync video generation with multi-stream temporal control
Shuchen Weng, Haojie Zheng, Zheng Chang, Si Li, Boxin Shi, and Xinlong Wang. Audio-sync video generation with multi-stream temporal control. InNIPS, 2025. 2 14
work page 2025
-
[65]
VIRES: Video in- stance repainting via sketch and text guided generation
Shuchen Weng, Haojie Zheng, Peixuan Zhang, Yuchen Hong, Han Jiang, Si Li, and Boxin Shi. VIRES: Video in- stance repainting via sketch and text guided generation. In CVPR, 2025. 2
work page 2025
-
[66]
Tune-A-Video: One-shot tuning of image diffusion models for text-to-video generation
Jay Zhangjie Wu, Yixiao Ge, Xintao Wang, Stan Weixian Lei, Yuchao Gu, Yufei Shi, Wynne Hsu, Ying Shan, Xiaohu Qie, and Mike Zheng Shou. Tune-A-Video: One-shot tuning of image diffusion models for text-to-video generation. In ICCV, 2023. 2
work page 2023
-
[67]
MovieBench: A hierarchical movie level dataset for long video generation.arXiv:2411.15262, 2024
Weijia Wu, Mingyu Liu, Zeyu Zhu, Xi Xia, Haoen Feng, Wen Wang, Kevin Qinghong Lin, Chunhua Shen, and Mike Zheng Shou. MovieBench: A hierarchical movie level dataset for long video generation.arXiv:2411.15262, 2024. 3
-
[68]
Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, Ting He, Xinfa Zhu, et al. Qwen3-omni technical report.arXiv:2509.17765,
work page internal anchor Pith review Pith/arXiv arXiv
-
[69]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chen- gen Huang, Chenxu Lv, et al. Qwen3 technical report. arXiv:2505.09388, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[70]
GenCompositor: generative video compositing with diffusion transformer
Shuzhou Yang, Xiaoyu Li, Xiaodong Cun, Guangzhi Wang, Lingen Li, Ying Shan, and Jian Zhang. GenCompositor: generative video compositing with diffusion transformer. arXiv:2509.02460, 2025. 2
-
[71]
CogVideox: Text-to-video diffusion models with an expert transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiao- han Zhang, Guanyu Feng, et al. CogVideox: Text-to-video diffusion models with an expert transformer. InICLR, 2025. 2
work page 2025
-
[72]
Guy Yariv, Itai Gat, Lior Wolf, Yossi Adi, and Idan Schwartz. AudioToken: Adaptation of text-conditioned diffusion mod- els for audio-to-image generation.arXiv:2305.13050, 2023. 2
-
[73]
Generative ai for film creation: A survey of recent advances
Ruihan Zhang, Borou Yu, Jiajian Min, Yetong Xin, Zheng Wei, Juncheng Nemo Shi, Mingzhen Huang, Xianghao Kong, Nix Liu Xin, Shanshan Jiang, et al. Generative ai for film creation: A survey of recent advances. InCVPR, 2025. 2 15
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.