LangDriveCTRL: Natural Language Controllable Driving Scene Editing with Multi-modal Agents
Pith reviewed 2026-05-16 20:53 UTC · model grok-4.3
The pith
LangDriveCTRL edits real driving videos from natural language by modeling them as 3D scene graphs and routing instructions through specialized agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
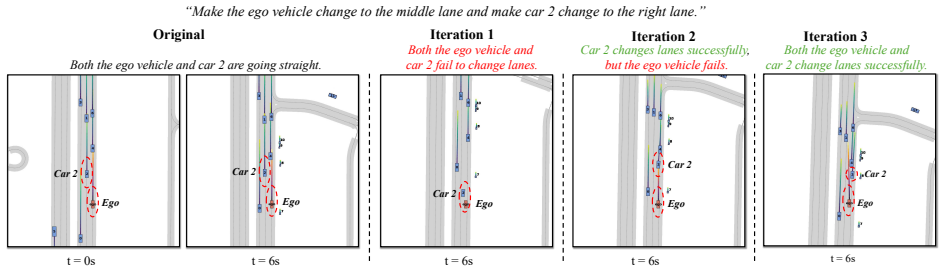
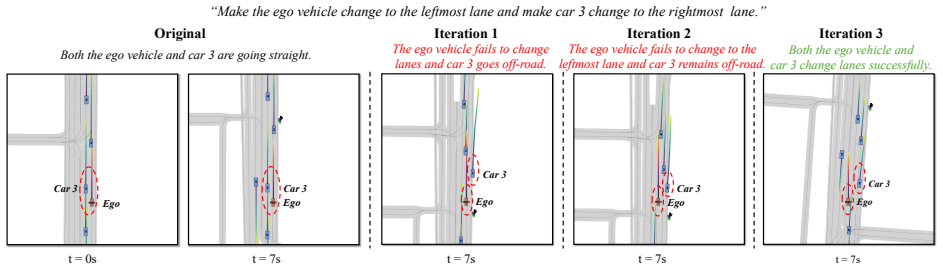
LangDriveCTRL represents each driving video as an explicit 3D scene graph that decomposes the scene into a static background and dynamic object nodes, then applies a feedback-driven agentic pipeline in which an orchestrator converts user instructions into executable graphs that coordinate an Object Grounding Agent, a Behavior Editing Agent, a Behavior Reviewer Agent, and a Video Reviewer Agent; the edited graph is rendered and refined with a video diffusion tool to produce photorealistic outputs that support both object-level edits and multi-object behavior changes from natural language.
What carries the argument
The feedback-driven agentic pipeline operating on a 3D scene graph representation, where an orchestrator coordinates object grounding, trajectory generation, iterative review, and video diffusion harmonization to translate language instructions into scene edits.
If this is right
- Object nodes support removal, insertion, and replacement directly from text instructions.
- Multi-object behaviors are generated as trajectories that can be iteratively reviewed and refined.
- Final videos achieve nearly 2 times higher alignment with user instructions than prior state-of-the-art methods.
- Photorealism, structural preservation, and traffic realism remain superior through the review and diffusion stages.
Where Pith is reading between the lines
- The same pipeline could generate synthetic variations of rare traffic events for training safety models without requiring new real-world captures.
- Closed-loop integration with motion planners might create on-demand test scenarios for autonomous driving systems.
- Extending the agents to handle longer sequences or denser urban scenes would test whether the current grounding and review steps scale without additional human oversight.
- Analogous agentic decompositions could apply to editing other structured video domains such as surveillance footage or robotic manipulation sequences.
Load-bearing premise
The multi-modal agents and video diffusion tool can reliably ground language to objects, produce realistic trajectories, and generate photorealistic renderings that preserve scene structure without artifacts in complex real-world driving footage.
What would settle it
A side-by-side comparison on the same input videos where edited outputs show mismatched object identities, trajectories that violate road geometry or physics, or visible artifacts that reduce photorealism relative to the original footage.
Figures














read the original abstract
LangDriveCTRL is a natural-language-controllable framework for editing real-world driving videos to synthesize diverse traffic scenarios. It represents each video as an explicit 3D scene graph, decomposing the scene into a static background and dynamic object nodes. To enable fine-grained editing and realism, it introduces a feedback-driven agentic pipeline. An Orchestrator converts user instructions into executable graphs that coordinate specialized multi-modal agents and tools. An Object Grounding Agent aligns free-form text with target object nodes in the scene graph; a Behavior Editing Agent generates multi-object trajectories from language instructions; and a Behavior Reviewer Agent iteratively reviews and refines the generated trajectories. The edited scene graph is rendered and harmonized using a video diffusion tool, and then further refined by a Video Reviewer Agent to ensure photorealism and appearance alignment. LangDriveCTRL supports both object node editing (removal, insertion, and replacement) and multi-object behavior editing from natural-language instructions. Quantitatively, it achieves nearly $2\times$ higher instruction alignment than the previous SoTA, with superior photorealism, structural preservation, and traffic realism. Project page is available at: https://yunhe24.github.io/langdrivectrl/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LangDriveCTRL, a framework for natural-language editing of real-world driving videos. Scenes are represented as explicit 3D scene graphs separating static background from dynamic object nodes. An Orchestrator agent decomposes instructions into executable graphs that coordinate specialized multi-modal agents: Object Grounding Agent for text-to-node alignment, Behavior Editing Agent for multi-object trajectory generation, Behavior Reviewer Agent for iterative refinement, and Video Reviewer Agent after video diffusion rendering. The system supports object insertion/removal/replacement and behavior editing. It reports nearly 2× higher instruction alignment than prior SoTA along with gains in photorealism, structural preservation, and traffic realism.
Significance. If the multi-agent pipeline proves reliable for accurate grounding, collision-free trajectories, and artifact-free rendering on complex real-world scenes, the work would provide a practical natural-language interface for synthesizing diverse driving scenarios, aiding data augmentation and simulation for autonomous driving. The explicit scene-graph representation and feedback-driven agents represent a coherent integration of language models with vision tools; the quantitative claim of doubled alignment would be a notable empirical advance if supported by rigorous controls.
major comments (3)
- [§5.1, Table 2] §5.1 and Table 2: the headline claim of nearly 2× higher instruction alignment is presented without ablations isolating the contribution of each agent (Orchestrator, Object Grounding, Behavior Editing, Reviewers) or per-agent success rates; without these, it is impossible to determine whether the reported gain stems from the proposed pipeline or from other factors, which is load-bearing for the central quantitative result.
- [§4.3] §4.3: the Behavior Editing Agent is stated to generate collision-free trajectories consistent with traffic rules, yet no quantitative metrics (collision rate, rule-violation count, or trajectory realism scores) are reported on dense/occluded nuScenes-style intersections; this omission leaves the traffic-realism superiority claim unsupported.
- [§5.2] §5.2: the Video Reviewer Agent is described as ensuring photorealism and 3D structure preservation after diffusion rendering, but the manuscript provides neither failure-case analysis nor metrics on introduced artifacts (e.g., ghosting, inconsistent lighting) across scene types; this is critical because the final output quality directly determines the photorealism and structural-preservation claims.
minor comments (2)
- [Figure 3] Figure 3: the pipeline diagram would be clearer if the feedback arrows between the Behavior Reviewer and Behavior Editing agents were labeled with the exact review criteria used.
- [§3.2] §3.2: the definition of the scene-graph node attributes (position, velocity, class) is introduced without an explicit equation; adding a compact notation would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: [§5.1, Table 2] §5.1 and Table 2: the headline claim of nearly 2× higher instruction alignment is presented without ablations isolating the contribution of each agent (Orchestrator, Object Grounding, Behavior Editing, Reviewers) or per-agent success rates; without these, it is impossible to determine whether the reported gain stems from the proposed pipeline or from other factors, which is load-bearing for the central quantitative result.
Authors: We agree that component-wise ablations and per-agent success rates would strengthen the central quantitative claim. In the revised manuscript we will add a dedicated ablation study that systematically disables or replaces each agent (Orchestrator, Object Grounding Agent, Behavior Editing Agent, Behavior Reviewer, and Video Reviewer) while keeping the rest of the pipeline fixed, and we will report per-agent success rates on the instruction-alignment metric. These results will be included in an expanded §5.1 and updated Table 2. revision: yes
-
Referee: [§4.3] §4.3: the Behavior Editing Agent is stated to generate collision-free trajectories consistent with traffic rules, yet no quantitative metrics (collision rate, rule-violation count, or trajectory realism scores) are reported on dense/occluded nuScenes-style intersections; this omission leaves the traffic-realism superiority claim unsupported.
Authors: We acknowledge that quantitative metrics are needed to substantiate the traffic-realism claims for the Behavior Editing Agent. In the revision we will add collision-rate and rule-violation statistics evaluated on dense and occluded nuScenes intersections, together with trajectory-realism scores (e.g., against ground-truth trajectories). These metrics will be reported in an extended §4.3 and compared against baseline trajectory generators to support the superiority claim. revision: yes
-
Referee: [§5.2] §5.2: the Video Reviewer Agent is described as ensuring photorealism and 3D structure preservation after diffusion rendering, but the manuscript provides neither failure-case analysis nor metrics on introduced artifacts (e.g., ghosting, inconsistent lighting) across scene types; this is critical because the final output quality directly determines the photorealism and structural-preservation claims.
Authors: We agree that failure-case analysis and artifact metrics are important for validating the Video Reviewer Agent. The revised manuscript will include a new subsection in §5.2 that presents failure cases across scene types (e.g., urban, highway, occluded) and reports quantitative artifact scores for ghosting, lighting inconsistency, and structural drift. These additions will directly support the photorealism and structural-preservation claims. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes an empirical agentic pipeline for natural-language driving scene editing, built from an orchestrator, specialized multi-modal agents, scene-graph representation, and video diffusion rendering. No equations, fitted parameters, or first-principles derivations are presented that reduce by construction to their own inputs. Quantitative claims rest on direct comparisons to prior SoTA methods rather than self-referential definitions or load-bearing self-citations. The approach is self-contained as a new system description with external empirical validation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Driving scenes can be decomposed into static background and dynamic object nodes in a 3D scene graph
invented entities (5)
-
Orchestrator agent
no independent evidence
-
Object Grounding Agent
no independent evidence
-
Behavior Editing Agent
no independent evidence
-
Behavior Reviewer Agent
no independent evidence
-
Video Reviewer Agent
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
LangDriveCTRL ... explicit 3D scene graph ... Object Grounding Agent ... Behavior Editing Agent ... video diffusion tool
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
SceneOrchestra: Efficient Agentic 3D Scene Synthesis via Full Tool-Call Trajectory Generation
SceneOrchestra trains an orchestrator to generate full tool-call trajectories for 3D scene synthesis and uses a discriminator during training to select high-quality plans, yielding state-of-the-art results with lower runtime.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023. 2, 4, 6, 7, 13
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
World Simulation with Video Foundation Models for Physical AI
Arslan Ali, Junjie Bai, Maciej Bala, Yogesh Balaji, Aaron Blakeman, Tiffany Cai, Jiaxin Cao, Tianshi Cao, Elizabeth Cha, Yu-Wei Chao, et al. World simulation with video foundation models for physical ai.arXiv preprint arXiv:2511.00062, 2025. 1, 2, 3, 6, 7, 8, 13, 14, 16
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023. 13
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learn- ers.Advances in neural information processing systems, 33:1877–1901, 2020. 4
work page 1901
-
[5]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv ´e J´egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InProceedings of the IEEE/CVF interna- tional conference on computer vision, pages 9650–9660,
-
[6]
Wei-Jer Chang, Wei Zhan, Masayoshi Tomizuka, Man- mohan Chandraker, and Francesco Pittaluga. Langtraj: Diffusion model and dataset for language-conditioned trajectory simulation.arXiv preprint arXiv:2504.11521,
-
[7]
Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images
Ziyu Chen, Jiawei Yang, Jiahui Huang, Riccardo de Lu- tio, Janick Martinez Esturo, Boris Ivanovic, Or Litany, Zan Gojcic, Sanja Fidler, Marco Pavone, et al. Om- nire: Omni urban scene reconstruction.arXiv preprint arXiv:2408.16760, 2024. 2, 3, 4, 13, 14
-
[8]
arXiv preprint arXiv:2305.06558 (2023)
Yangming Cheng, Liulei Li, Yuanyou Xu, Xiaodi Li, Zongxin Yang, Wenguan Wang, and Yi Yang. Segment and track anything.arXiv preprint arXiv:2305.06558,
-
[9]
Carla: An open ur- ban driving simulator
Alexey Dosovitskiy, German Ros, Felipe Codevilla, An- tonio Lopez, and Vladlen Koltun. Carla: An open ur- ban driving simulator. InConference on robot learning, pages 1–16. PMLR, 2017. 1
work page 2017
-
[10]
Density-based spatial clustering of applica- tions with noise
Martin Ester, Hans-Peter Kriegel, J ¨org Sander, and Xi- aowei Xu. Density-based spatial clustering of applica- tions with noise. InInt. Conf. knowledge discovery and data mining, volume 240, 1996. 14
work page 1996
-
[11]
Obbtree: A hierarchical structure for rapid interference detection
Stefan Gottschalk, Ming C Lin, and Dinesh Manocha. Obbtree: A hierarchical structure for rapid interference detection. InProceedings of the 23rd annual conference on Computer graphics and interactive techniques, pages 171–180, 1996. 15
work page 1996
-
[12]
Mariam Hassan, Sebastian Stapf, Ahmad Rahimi, Pedro Rezende, Yasaman Haghighi, David Br¨uggemann, Isinsu Katircioglu, Lin Zhang, Xiaoran Chen, Suman Saha, et al. Gem: A generalizable ego-vision multimodal world model for fine-grained ego-motion, object dynamics, and scene composition control. InProceedings of the Com- puter Vision and Pattern Recognition ...
work page 2025
-
[13]
Liu He, Yizhi Song, Hejun Huang, Pinxin Liu, Yunlong Tang, Daniel Aliaga, and Xin Zhou. Kubrick: Multi- modal agent collaborations for synthetic video genera- tion.arXiv preprint arXiv:2408.10453, 2024. 3
-
[14]
Density-preserving deep point cloud compression
Yun He, Xinlin Ren, Danhang Tang, Yinda Zhang, Xiangyang Xue, and Yanwei Fu. Density-preserving deep point cloud compression. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2333–2342, 2022. 3
work page 2022
-
[15]
Yun He, Danhang Tang, Yinda Zhang, Xiangyang Xue, and Yanwei Fu. Grad-pu: Arbitrary-scale point cloud up- sampling via gradient descent with learned distance func- tions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5354– 5363, 2023. 3
work page 2023
-
[16]
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017. 6
work page 2017
-
[17]
Autovfx: Physically realistic video editing from natural language instructions
Hao-Yu Hsu, Chih-Hao Lin, Albert J Zhai, Hongchi Xia, and Shenlong Wang. Autovfx: Physically realistic video editing from natural language instructions. In2025 In- ternational Conference on 3D Vision (3DV), pages 769–
- [18]
-
[19]
Scenecraft: An llm agent for synthesizing 3d scenes as blender code
Ziniu Hu, Ahmet Iscen, Aashi Jain, Thomas Kipf, Yisong Yue, David A Ross, Cordelia Schmid, and Alireza Fathi. Scenecraft: An llm agent for synthesizing 3d scenes as blender code. InForty-first International Conference on Machine Learning, 2024. 3 9
work page 2024
-
[20]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Ak- ila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024. 4, 6, 7, 13
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
3d gaussian splatting for real-time radiance field rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk¨uhler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4):139–1, 2023. 2, 3, 4, 5, 13
work page 2023
-
[22]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. Segment anything. InProceedings of the IEEE/CVF international conference on computer vision, pages 4015–4026, 2023. 4, 12
work page 2023
-
[23]
Minghan Li, Chenxi Xie, Yichen Wu, Lei Zhang, and Mengyu Wang. Five: A fine-grained video editing benchmark for evaluating emerging diffusion and rec- tified flow models.arXiv preprint arXiv:2503.13684,
-
[24]
4d langsplat: 4d language gaussian splatting via multimodal large language models
Wanhua Li, Renping Zhou, Jiawei Zhou, Yingwei Song, Johannes Herter, Minghan Qin, Gao Huang, and Hanspeter Pfister. 4d langsplat: 4d language gaussian splatting via multimodal large language models. InPro- ceedings of the Computer Vision and Pattern Recognition Conference, pages 22001–22011, 2025. 4, 12, 13
work page 2025
-
[25]
Dif- fusion renderer: Neural inverse and forward rendering with video diffusion models
Ruofan Liang, Zan Gojcic, Huan Ling, Jacob Munkberg, Jon Hasselgren, Chih-Hao Lin, Jun Gao, Alexander Keller, Nandita Vijaykumar, Sanja Fidler, et al. Dif- fusion renderer: Neural inverse and forward rendering with video diffusion models. InProceedings of the Com- puter Vision and Pattern Recognition Conference, pages 26069–26080, 2025. 3
work page 2025
-
[26]
Yiyuan Liang, Zhiying Yan, Liqun Chen, Jiahuan Zhou, Luxin Yan, Sheng Zhong, and Xu Zou. Driveeditor: A unified 3d information-guided framework for control- lable object editing in driving scenes. InProceedings of the AAAI Conference on Artificial Intelligence, vol- ume 39, pages 5164–5172, 2025. 2, 3, 13, 14
work page 2025
-
[27]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. InEuropean conference on computer vision, pages 38–
-
[28]
Springer, 2024. 4, 12
work page 2024
-
[29]
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis.Communications of the ACM, 65(1):99– 106, 2021. 3
work page 2021
-
[30]
Sung-Yeon Park, Adam Lee, Juanwu Lu, Can Cui, Luyang Jiang, Rohit Gupta, Kyungtae Han, Ahmadreza Moradipari, and Ziran Wang. Simsplat: Predictive driv- ing scene editing with language-aligned 4d gaussian splatting.arXiv preprint arXiv:2510.02469, 2025. 13
-
[31]
Langsplat: 3d language gaus- sian splatting
Minghan Qin, Wanhua Li, Jiawei Zhou, Haoqian Wang, and Hanspeter Pfister. Langsplat: 3d language gaus- sian splatting. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, pages 20051–20060, 2024. 4
work page 2024
-
[32]
Learning transferable visual models from natural lan- guage supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sas- try, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural lan- guage supervision. InInternational conference on ma- chine learning, pages 8748–8763. PmLR, 2021. 12
work page 2021
-
[33]
Trace and pace: Controllable pedestrian animation via guided trajectory diffusion
Davis Rempe, Zhengyi Luo, Xue Bin Peng, Ye Yuan, Kris Kitani, Karsten Kreis, Sanja Fidler, and Or Litany. Trace and pace: Controllable pedestrian animation via guided trajectory diffusion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13756–13766, 2023. 9
work page 2023
-
[34]
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
Tianhe Ren, Shilong Liu, Ailing Zeng, Jing Lin, Kun- chang Li, He Cao, Jiayu Chen, Xinyu Huang, Yukang Chen, Feng Yan, et al. Grounded sam: Assembling open- world models for diverse visual tasks.arXiv preprint arXiv:2401.14159, 2024. 4, 6, 12, 13, 15
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Airsim: High-fidelity visual and physical sim- ulation for autonomous vehicles
Shital Shah, Debadeepta Dey, Chris Lovett, and Ashish Kapoor. Airsim: High-fidelity visual and physical sim- ulation for autonomous vehicles. InField and service robotics: Results of the 11th international conference, pages 621–635. Springer, 2017. 1
work page 2017
-
[36]
Language embedded 3d gaussians for open- vocabulary scene understanding
Jin-Chuan Shi, Miao Wang, Hao-Bin Duan, and Shao- Hua Guan. Language embedded 3d gaussians for open- vocabulary scene understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5333–5343, 2024. 4
work page 2024
-
[37]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020. 3
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[38]
Zhihang Song, Zimin He, Xingyu Li, Qiming Ma, Ruibo Ming, Zhiqi Mao, Huaxin Pei, Lihui Peng, Jianming Hu, Danya Yao, et al. Synthetic datasets for autonomous driv- ing: A survey.IEEE Transactions on Intelligent Vehicles, 9(1):1847–1864, 2023. 1
work page 2023
-
[39]
Eliza Strickland. Are Self-Driving Cars Closer Than We Think? Discover How Synthetic Data Is Paving the Way — spectrum.ieee.org.https://spectrum. ieee.org/synthetic- data- self- driving,
-
[40]
[Accessed 13-11-2025]. 1
work page 2025
-
[41]
Bane Sullivan and Alexander Kaszynski. PyVista: 3D plotting and mesh analysis through a streamlined inter- face for the Visualization Toolkit (VTK).Journal of Open Source Software, 4(37):1450, May 2019. 5
work page 2019
-
[42]
Scal- ability in perception for autonomous driving: Waymo open dataset
Pei Sun, Henrik Kretzschmar, Xerxes Dotiwalla, Aure- lien Chouard, Vijaysai Patnaik, Paul Tsui, James Guo, Yin Zhou, Yuning Chai, Benjamin Caine, et al. Scal- ability in perception for autonomous driving: Waymo open dataset. InProceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition, pages 2446–2454, 2020. 6, 15
work page 2020
-
[43]
Coma: Compositional human motion generation with multi-modal agents,
Shanlin Sun, Gabriel De Araujo, Jiaqi Xu, Shenghan Zhou, Hanwen Zhang, Ziheng Huang, Chenyu You, and Xiaohui Xie. Coma: Compositional human mo- tion generation with multi-modal agents.arXiv preprint arXiv:2412.07320, 2024. 3 10
-
[44]
Lidarf: Delv- ing into lidar for neural radiance field on street scenes
Shanlin Sun, Bingbing Zhuang, Ziyu Jiang, Buyu Liu, Xiaohui Xie, and Manmohan Chandraker. Lidarf: Delv- ing into lidar for neural radiance field on street scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19563–19572,
-
[45]
Block- nerf: Scalable large scene neural view synthesis
Matthew Tancik, Vincent Casser, Xinchen Yan, Sabeek Pradhan, Ben Mildenhall, Pratul P Srinivasan, Jonathan T Barron, and Henrik Kretzschmar. Block- nerf: Scalable large scene neural view synthesis. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8248–8258, 2022. 3
work page 2022
-
[46]
Decentnerfs: Decentralized neural radiance fields from crowdsourced images
Zaid Tasneem, Akshat Dave, Abhishek Singh, Kusha- gra Tiwary, Praneeth Vepakomma, Ashok Veeraragha- van, and Ramesh Raskar. Decentnerfs: Decentralized neural radiance fields from crowdsourced images. InEu- ropean Conference on Computer Vision, pages 144–161. Springer, 2024. 3
work page 2024
-
[47]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timoth´ee Lacroix, Bap- tiste Rozi`ere, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023. 13
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[48]
Towards Accurate Generative Models of Video: A New Metric & Challenges
Thomas Unterthiner, Sjoerd Van Steenkiste, Karol Ku- rach, Raphael Marinier, Marcin Michalski, and Syl- vain Gelly. Towards accurate generative models of video: A new metric & challenges.arXiv preprint arXiv:1812.01717, 2018. 6
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[49]
Pacer+: On-demand pedestrian animation controller in driving scenarios
Jingbo Wang, Zhengyi Luo, Ye Yuan, Yixuan Li, and Bo Dai. Pacer+: On-demand pedestrian animation controller in driving scenarios. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion, pages 718–728, 2024. 9
work page 2024
-
[50]
Yuxi Wei, Jingbo Wang, Yuwen Du, Dingju Wang, Liang Pan, Chenxin Xu, Yao Feng, Bo Dai, and Siheng Chen. Chatdyn: Language-driven multi-actor dynamics gener- ation in street scenes.arXiv preprint arXiv:2412.08685,
-
[51]
Ed- itable scene simulation for autonomous driving via col- laborative llm-agents
Yuxi Wei, Zi Wang, Yifan Lu, Chenxin Xu, Changxing Liu, Hao Zhao, Siheng Chen, and Yanfeng Wang. Ed- itable scene simulation for autonomous driving via col- laborative llm-agents. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion, pages 15077–15087, 2024. 1, 2, 3, 6, 7, 8, 13, 14, 16
work page 2024
-
[52]
4d gaussian splatting for real-time dy- namic scene rendering
Guanjun Wu, Taoran Yi, Jiemin Fang, Lingxi Xie, Xi- aopeng Zhang, Wei Wei, Wenyu Liu, Qi Tian, and Xing- gang Wang. 4d gaussian splatting for real-time dy- namic scene rendering. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 20310–20320, 2024. 12
work page 2024
-
[53]
Difix3d+: Improving 3d re- constructions with single-step diffusion models
Jay Zhangjie Wu, Yuxuan Zhang, Haithem Turki, Xu- anchi Ren, Jun Gao, Mike Zheng Shou, Sanja Fidler, Zan Gojcic, and Huan Ling. Difix3d+: Improving 3d re- constructions with single-step diffusion models. InPro- ceedings of the Computer Vision and Pattern Recognition Conference, pages 26024–26035, 2025. 6
work page 2025
-
[54]
Yajiao Xiong, Xiaoyu Zhou, Yongtao Wan, Deqing Sun, and Ming-Hsuan Yang. Drivinggaussian++: To- wards realistic reconstruction and editable simulation for surrounding dynamic driving scenes.arXiv preprint arXiv:2508.20965, 2025. 2, 3, 13, 14
-
[55]
Runsheng Xu, Hubert Lin, Wonseok Jeon, Hao Feng, Yuliang Zou, Liting Sun, John Gorman, Kate Tolstaya, Sarah Tang, Brandyn White, et al. Wod-e2e: Waymo open dataset for end-to-end driving in challenging long- tail scenarios.arXiv preprint arXiv:2510.26125, 2025. 1
-
[56]
arXiv preprint arXiv:2304.11968 (2023)
Jinyu Yang, Mingqi Gao, Zhe Li, Shang Gao, Fangjing Wang, and Feng Zheng. Track anything: Segment any- thing meets videos.arXiv preprint arXiv:2304.11968,
-
[57]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert trans- former.arXiv preprint arXiv:2408.06072, 2024. 6, 7
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[58]
Mark YU, Wenbo Hu, Jinbo Xing, and Ying Shan. Trajectorycrafter: Redirecting camera trajectory for monocular videos via diffusion models.arXiv preprint arXiv:2503.05638, 2025. 7
-
[59]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. InProceedings of the IEEE/CVF international conference on computer vision, pages 3836–3847, 2023. 3
work page 2023
-
[60]
Drivedreamer-2: Llm-enhanced world models for di- verse driving video generation
Guosheng Zhao, Xiaofeng Wang, Zheng Zhu, Xinze Chen, Guan Huang, Xiaoyi Bao, and Xingang Wang. Drivedreamer-2: Llm-enhanced world models for di- verse driving video generation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 10412–10420, 2025. 3
work page 2025
-
[61]
Hunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation
Zibo Zhao, Zeqiang Lai, Qingxiang Lin, Yunfei Zhao, Haolin Liu, Shuhui Yang, Yifei Feng, Mingxin Yang, Sheng Zhang, Xianghui Yang, et al. Hunyuan3d 2.0: Scaling diffusion models for high resolution textured 3d assets generation.arXiv preprint arXiv:2501.12202,
work page internal anchor Pith review Pith/arXiv arXiv
-
[62]
Tong Zheng, Hongming Zhang, Wenhao Yu, Xiaoyang Wang, Runpeng Dai, Rui Liu, Huiwen Bao, Chengsong Huang, Heng Huang, and Dong Yu. Parallel-r1: To- wards parallel thinking via reinforcement learning.arXiv preprint arXiv:2509.07980, 2025. 13
-
[63]
Scenecrafter: Controllable multi-view driving scene editing
Zehao Zhu, Yuliang Zou, Chiyu Max Jiang, Bo Sun, Vincent Casser, Xiukun Huang, Jiahao Wang, Zhenpei Yang, Ruiqi Gao, Leonidas Guibas, et al. Scenecrafter: Controllable multi-view driving scene editing. InPro- ceedings of the Computer Vision and Pattern Recognition Conference, pages 6812–6822, 2025. 2, 3, 13, 14 11 In the supplementary material, we provide...
work page 2025
-
[64]
Ablation on Object Grounding Agent.For the open vocabulary object query task, we use Grounding SAM
Additional Experiments In this section, we conduct more experiments to val- idate the effectiveness of ourObject Grounding Agent andBehavior Editing Agent. Ablation on Object Grounding Agent.For the open vocabulary object query task, we use Grounding SAM
-
[65]
The vehicle to the left of the red sedan
and 4DLangSplat [23] as baselines. Grounding SAM [32] first performs open vocabulary detection on images through Grounding DINO [26] to obtain ob- ject bounding boxes. It then uses SAM [21] to gen- erate object masks based on these bounding boxes. 4DLangSplat [23] first reconstructs the dynamic scene through 4D Gaussian Splatting [49]. Each Gaussian primi...
-
[66]
Prior work can be roughly grouped into three categories
Detailed Comparison with Related Work We provide a detailed comparison with previous driv- ing scene editing methods in Table 8. Prior work can be roughly grouped into three categories. The first category consists of diffusion-based meth- ods [2, 25, 60]. Among them, DriveEditor [25] and 1For Cosmos [2], we use Cosmos-Predict2.5 Base instead of Cosmos-Pre...
-
[67]
Implementation Details 8.1. Behavior Description Generation and Be- havior Validation Building upon [6], we extract semantic behavior de- scriptions from original object trajectory and introduce a novel automated engine for reasoning about the phys- ical and semantic consistency of counterfactual behav- iors. These technologies are leveraged by the Object...
-
[68]
is used to detect overlaps between vehicles for col- lision checking. 8.1.4 Behavior Alignment Metric In Table 1, we calculate the behavior alignment metric using the same logic as in behavior description genera- tion. Although our method generates explicit trajecto- ries during the editing process, we do not use them di- rectly for evaluation. Instead, t...
work page 2005
-
[69]
Extra Qualitative Results In this section, we provide additional qualitative results. Specifically, Figure 7 shows editing results of different methods across various instruction types. As observed, Cosmos [2] modifies the original back- ground, while ChatSim [48] suffers from poor photo- realism. Moreover, neither method follows instructions well (e.g., ...
-
[70]
Failure Cases In this section, we present two common failure cases
-
[71]
Generated trajectories sometimes still contain traffic violations. For instance, the system may fail to properly recognize road separations such as median barriers, in- correctly treating them as drivable areas. In Figure 10, the newly inserted vehicle drives on the median barrier
-
[72]
The video diffusion model (VDM) sometimes alters the type and color of inserted vehicles. For example, in Figure 11, while a green convertible mesh is inserted, it becomes a black sedan after refinement. This occurs because the VDM was trained primarily on common ve- hicle types (e.g., sedans and SUVs) and colors, resulting in poor handling of uncommon ve...
-
[73]
Object Manipulation: Remove object: logging.info("@@- Removing object") remove object(...) Add new object: target obj = retrieve from hunyuan(...) # IMPORTANT: Rescale and transform the generated mesh: target obj = rescale and transform mesh(...) Replace with new object: logging.info("@@- Replacing with new object") new obj = replace object(...)
-
[74]
Trajectory/Behavior Generation: generate counterfactual behavior(...) generate trajectory(...) review and refine trajectories(...)
-
[75]
Add a red sports car to the right of the yellow car and make it turn right
Camera Operations: 23 translate camera(...) rotate camera(...) Example: Input: “Add a red sports car to the right of the yellow car and make it turn right.” Output: Template A + Core Editing + Template B + Template C Core Editing Operation: logging.info("@@- Adding the new generated vehicle") target obj = retrieve from hunyuan(...) logging.info("@@@@• Ali...
-
[76]
Decompose the description into structured triplets
-
[77]
Identify the reference object and filter candidates by direction
-
[78]
Match attributes to find the target object
-
[79]
Return the ID(s) of matching object(s) Step 1: Triplet Decomposition Extract natural-language descriptions of EXISTING objects that need ID conversion from the instruction. IMPORTANT RULES:
-
[80]
IGNORE descriptions that already specify an ID (like “car 2”, “vehicle id 5”) - leave them unchanged in the final instruction
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.