Fusion or Confusion? Multimodal Complexity Is Not All You Need
Pith reviewed 2026-05-16 18:47 UTC · model grok-4.3
The pith
Complex multimodal architectures do not reliably outperform unimodal baselines or a simple baseline called SimBaMM.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under standardized experimental conditions, including hyperparameter tuning, weight initialization, cross-validation, and statistical testing, increased multimodal complexity often yields confusion rather than effective fusion of data modalities. Accordingly, complex multimodal architectures do not reliably outperform unimodal baselines and a Simple Baseline for Multimodal Learning (SimBaMM).
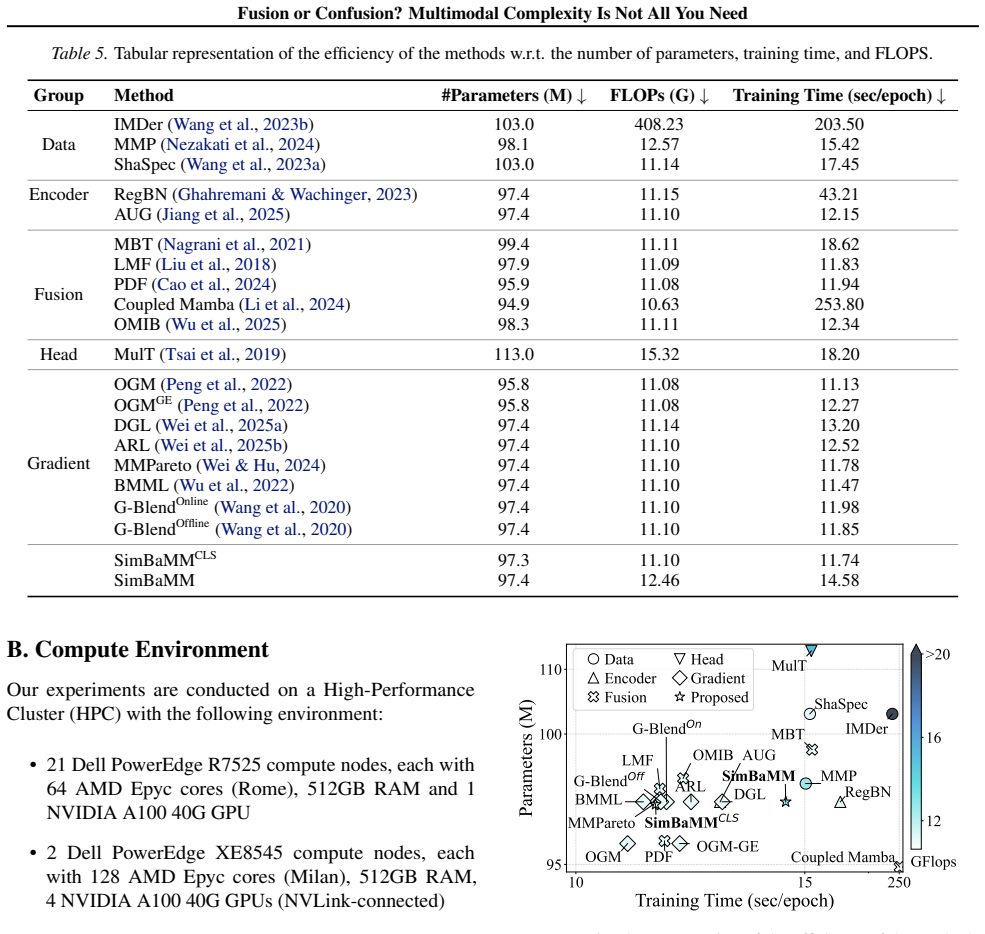
What carries the argument
The standardized reimplementation protocol applied to 19 multimodal methods across nine datasets, which isolates the effect of architectural complexity on modality fusion.
If this is right
- Multimodal research should prioritize rigorous, standardized evaluation over the introduction of novel architectures.
- Unimodal baselines must be reported as a minimum requirement in multimodal papers.
- Simple multimodal baselines such as SimBaMM can serve as competitive reference points for future work.
- Many published multimodal performance claims may need re-examination under controlled conditions.
- Methodological rigor in evaluation practices should become a central focus of the field.
Where Pith is reading between the lines
- Apparent multimodal gains in the literature may often trace to differences in tuning effort rather than true cross-modal integration.
- Adopting uniform evaluation standards could reduce the rate of overstated claims across machine learning subfields.
- Unimodal models may remain sufficient for many practical tasks where added modalities do not demonstrably help.
- Similar controlled reimplementation studies could usefully be applied to other areas that favor architectural complexity.
Load-bearing premise
That the standardized experimental conditions, including hyperparameter tuning, weight initialization, cross-validation, and reimplementations of the 19 methods, provide an unbiased and faithful assessment of each method's capabilities.
What would settle it
An independent replication that applies the same hyperparameter search, initialization, and cross-validation protocol to the identical 19 methods and finds multiple complex multimodal models statistically outperform both the unimodal baselines and SimBaMM on the same nine datasets.
Figures





read the original abstract
Multimodal learning has become a prominent research area, with the potential of substantial performance gains by combining information across modalities. At the same time, model development has trended toward increasingly complex deep learning architectures, motivated by the assumption that multimodal-specific methods improve performance. We challenge this assumption through a large-scale empirical study by reimplementing 19 high-impact multimodal methods across nine diverse datasets with up to 23 modalities. Under standardized experimental conditions, including hyperparameter tuning, weight initialization, cross-validation, and statistical testing, increased multimodal complexity often yields confusion rather than effective fusion of data modalities. Accordingly, complex multimodal architectures do not reliably outperform unimodal baselines and a Simple Baseline for Multimodal Learning (SimBaMM). Through a focused case study, we further demonstrate concrete methodological shortcomings even in top-tier multimodal learning publications, underscoring the need for standardized evaluation practices. In summary, we argue for a shift in focus for multimodal learning: away from the pursuit of architectural novelty and toward methodological rigor.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports a large-scale empirical study reimplementing 19 high-impact multimodal methods on nine datasets (up to 23 modalities). Under standardized conditions that include hyperparameter tuning, weight initialization, cross-validation, and statistical testing, it finds that increased architectural complexity does not reliably improve performance over unimodal baselines or the authors' proposed Simple Baseline for Multimodal Learning (SimBaMM). A focused case study illustrates methodological shortcomings in prior top-tier work, leading to the recommendation that the field shift emphasis from architectural novelty to rigorous, standardized evaluation.
Significance. If the empirical comparisons prove robust, the result would be significant for multimodal learning: it would provide concrete evidence that many complex fusion architectures add confusion rather than value, justify greater reliance on simple baselines, and incentivize the community to adopt stricter standardization protocols. The scale (19 methods, 9 datasets) and inclusion of statistical testing are strengths that could influence future benchmarking practices.
major comments (2)
- [§4] §4 (Experimental Setup): The claim of standardized hyperparameter tuning is load-bearing for the central conclusion yet lacks quantitative detail on search budget, number of trials, and range adaptation. Complex multimodal methods introduce additional hyperparameters (modality encoders, fusion modules, cross-attention weights) whose search spaces are larger than those of SimBaMM or unimodal baselines; equal trial counts across methods would systematically under-optimize the former and artifactually favor the latter.
- [§5] §5 (Results): The assertion that complex methods 'do not reliably outperform' requires explicit reporting of effect sizes, confidence intervals, and correction for multiple comparisons across the 19 methods and 9 datasets. Without these, the statistical support for the headline claim remains incomplete even if the reimplementations are faithful.
minor comments (2)
- [§3] The description of SimBaMM should include an explicit algorithmic listing or pseudocode so readers can reproduce the baseline without ambiguity.
- [Figures 2-4] Figure captions and axis labels in the performance comparison plots should state the exact metric (e.g., accuracy, F1) and whether error bars represent standard deviation or standard error.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the presentation of our empirical findings. We address each major comment below and have revised the manuscript to incorporate additional quantitative details and statistical measures where appropriate.
read point-by-point responses
-
Referee: [§4] §4 (Experimental Setup): The claim of standardized hyperparameter tuning is load-bearing for the central conclusion yet lacks quantitative detail on search budget, number of trials, and range adaptation. Complex multimodal methods introduce additional hyperparameters (modality encoders, fusion modules, cross-attention weights) whose search spaces are larger than those of SimBaMM or unimodal baselines; equal trial counts across methods would systematically under-optimize the former and artifactually favor the latter.
Authors: We agree that explicit reporting of the hyperparameter search protocol is necessary to substantiate the standardization claim. In the revised manuscript, we will add a dedicated subsection in §4 that specifies the search budget (fixed at 200 trials per method via random search), the ranges explored for each hyperparameter class, and confirmation that identical trial counts were used across all methods. We also acknowledge the referee's point on search-space size and have added a brief discussion noting that this equal-budget design reflects common practice but may indeed under-optimize more complex models; we therefore frame our results as a conservative test of whether added complexity yields gains under realistic tuning constraints. revision: yes
-
Referee: [§5] §5 (Results): The assertion that complex methods 'do not reliably outperform' requires explicit reporting of effect sizes, confidence intervals, and correction for multiple comparisons across the 19 methods and 9 datasets. Without these, the statistical support for the headline claim remains incomplete even if the reimplementations are faithful.
Authors: We concur that effect sizes, confidence intervals, and multiple-comparison corrections would strengthen the statistical presentation. The revised §5 will include Cohen's d effect sizes for all pairwise comparisons against the unimodal and SimBaMM baselines, 95% bootstrap confidence intervals on performance differences, and Bonferroni-adjusted p-values to account for the 19 × 9 = 171 comparisons. These additions will be presented both in the main tables and in a supplementary statistical appendix, directly supporting the claim that performance differences are neither reliable nor practically meaningful in most cases. revision: yes
Circularity Check
No circularity: pure empirical benchmarking with external comparisons
full rationale
The paper performs a large-scale reimplementation and comparison of 19 multimodal methods against unimodal baselines and a proposed SimBaMM across nine datasets. All claims rest on measured performance metrics (accuracy, F1, etc.) obtained under standardized protocols for hyperparameter tuning, initialization, cross-validation, and statistical testing. No derivations, equations, fitted parameters renamed as predictions, or self-citation chains appear in the load-bearing argument. The central claim—that complex architectures do not reliably outperform simpler baselines—is directly supported by the external experimental outcomes rather than by any internal reduction to the paper's own inputs or prior self-citations. The skeptic concern about unequal hyperparameter budgets is a methodological limitation that affects empirical validity but does not constitute circularity in the derivation sense.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Reimplementations of the 19 methods faithfully capture their original intended behavior
- domain assumption Standardized hyperparameter tuning and cross-validation produce fair comparisons across methods
Forward citations
Cited by 1 Pith paper
-
Hidden in the Multiplicative Interaction: Uncovering Fragility in Multimodal Contrastive Learning
Multimodal contrastive learning using multilinear products is fragile to single bad modalities, and a gated version improves top-1 retrieval accuracy on synthetic and real trimodal data.
Reference graph
Works this paper leans on
-
[1]
Vivit: A video vision transformer
Arnab, A., Dehghani, M., Heigold, G., Sun, C., Lucic, M., and Schmid, C. Vivit: A video vision transformer. In 2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, October 10- 17, 2021, pp. 6816–6826. IEEE,
work page 2021
-
[2]
Walk in the cloud: Learning curves for point clouds shape analysis, pp
doi: 10.1109/ ICCV48922.2021.00676. Baevski, A., Zhou, Y ., Mohamed, A., and Auli, M. wav2vec 2.0: A framework for self-supervised learning of speech representations. In Larochelle, H., Ranzato, M., Had- sell, R., Balcan, M.-F., and Lin, H.-T. (eds.),Advances in Neural Information Processing Systems 33: Annual Con- ference on Neural Information Processing...
-
[3]
Bastico, M., Ryckelynck, D., Cort ´e, L., Tillier, Y ., and Decenci`ere, E. A simple and robust framework for cross- modality medical image segmentation applied to vision transformers. InIEEE/CVF International Conference on Computer Vision, ICCV 2023 - Workshops, Paris, France, October 2-6, 2023, pp. 4130–4140. IEEE,
work page 2023
-
[4]
doi: 10.1109/ICCVW60793.2023.00446. Benavoli, A., Corani, G., Demˇsar, J., and Zaffalon, M. Time for a change: a tutorial for comparing multiple classifiers through bayesian analysis.Journal of Machine Learning Research, 18(77):1–36,
-
[5]
doi: 10.1109/TAFFC.2014. 2336244. Caranzano, I., Pancotti, C., Rollo, C., Sartori, F., Li `o, P., Fariselli, P., and Sanavia, T. Sparsity is all you need: Rethinking biological pathway-informed approaches in deep learning. arXiv:2505.04300 [q-bio], May
-
[6]
ISSN 1057-7149, 1941-0042. doi: 10.1109/TIP.2015.2475625. arXiv:1404.3606 [cs]. Chen, H., Luong, V ., Mukherjee, L., and Singh, V . Sim- pletm: A simple baseline for multivariate time series forecasting. InProceedings of the 13th International Con- ference on Learning Representations, Singapore,
-
[7]
A simple multi-modality transfer learning baseline for sign lan- guage translation
Chen, Y ., Wei, F., Sun, X., Wu, Z., and Lin, S. A simple multi-modality transfer learning baseline for sign lan- guage translation. InIEEE/CVF Conference on Com- puter Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022, pp. 5110–5120. IEEE,
work page 2022
-
[8]
doi: 10.1109/CVPR52688.2022.00506. Corani, G., Benavoli, A., Demˇsar, J., Mangili, F., and Zaf- falon, M. Statistical comparison of classifiers through bayesian hierarchical modelling.Machine Learning, 106: 1817–1837,
-
[9]
Defazio, A., Yang, X., Khaled, A., Mishchenko, K., Mehta, H., and Cutkosky, A. The road less scheduled. In Glober- sons, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J. M., and Zhang, C. (eds.),Advances in Neu- ral Information Processing Systems 38: Annual Confer- ence on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, ...
work page 2024
-
[10]
Bert: Pre-training of deep bidirectional transformers for lan- guage understanding
Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. Bert: Pre-training of deep bidirectional transformers for lan- guage understanding. In Burstein, J., Doran, C., and Solorio, T. (eds.),Proceedings of the 2019 Conference of 9 Fusion or Confusion? Multimodal Complexity Is Not All You Need the North American Chapter of the Association for Com- putational ...
work page 2019
-
[11]
BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding
doi: 10.18653/V1/N19-1423. Dong, H., Nejjar, I., Sun, H., Chatzi, E., and Fink, O. Simm- mdg: A simple and effective framework for multi-modal domain generalization. InAdvances in Neural Informa- tion Processing Systems (NeurIPS),
-
[12]
An image is worth 16x16 words: Transformers for image recognition at scale
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., and Houlsby, N. An image is worth 16x16 words: Transformers for image recognition at scale. In9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7,
work page 2021
-
[13]
Ghahremani, M. and Wachinger, C. Regbn: Batch normal- ization of multimodal data with regularization. In Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., and Levine, S. (eds.),Advances in Neural Information Processing Systems 36: Annual Conference on Neural In- formation Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - ...
work page 2023
-
[14]
Goyal, A., Law, H., Liu, B., Newell, A., and Deng, J
Version 1.0. Goyal, A., Law, H., Liu, B., Newell, A., and Deng, J. Re- visiting point cloud shape classification with a simple and effective baseline. In Meila, M. and Zhang, T. (eds.), Proceedings of the 38th International Conference on Ma- chine Learning, ICML 2021, 18-24 July 2021, Virtual Event, volume 139 ofProceedings of Machine Learning Research, p...
work page 2021
-
[15]
Global context vision transformers
Hatamizadeh, A., Yin, H., Heinrich, G., Kautz, J., and Molchanov, P. Global context vision transformers. In Krause, A., Brunskill, E., Cho, K., Engelhardt, B., Sabato, S., and Scarlett, J. (eds.),International Conference on Ma- chine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA, volume 202 ofProceedings of Machine Learning Research, pp. 126...
work page 2023
-
[16]
Gomatching: A simple baseline for video text spotting via long and short term matching
He, H., Ye, M., Zhang, J., Liu, J., Du, B., and Tao, D. Gomatching: A simple baseline for video text spotting via long and short term matching. In Globersons, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J. M., and Zhang, C. (eds.),Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Syste...
work page 2024
-
[17]
Deep residual learning for image recognition
He, K., Zhang, X., Ren, S., and Sun, J. Deep residual learning for image recognition. In2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV , USA, June 27-30, 2016, pp. 770–778. IEEE Computer Society,
work page 2016
-
[18]
doi: 10.1109/CVPR.2016
-
[19]
Large Language Models are Powerful Electronic Health Record Encoders
Hegselmann, S., Arnim, G. v., Rheude, T., Kronenberg, N., Sontag, D., Hindricks, G., Eils, R., and Wild, B. Large language models are powerful electronic health record encoders. arXiv:2502.17403 [cs], October
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
doi: 10.1038/s41592-021-01256-7
ISSN 1548-7091, 1548-7105. doi: 10.1038/s41592-021-01256-7. Huang, S.-C., Huo, Z., Steinberg, E., Chiang, C.-C., Lun- gren, M. P., Langlotz, C., Yeung, S., Shah, N., and Fries, J. A. Inspect: A multimodal dataset for pulmonary em- bolism diagnosis and prognosis. InThirty-seventh Confer- ence on Neural Information Processing Systems Datasets and Benchmarks Track,
-
[21]
arXiv preprint arXiv:2508.02669 , year=
Huang, X., Wu, J., Liu, H., Tang, X., and Zhou, Y . Medvl- thinker: Simple baselines for multimodal medical reason- ing. arXiv:2508.02669 [cs], August
-
[22]
ISSN 26663899. doi: 10.1016/j.patter.2023.100804. Kirsch, A., Farquhar, S., Atighehchian, P., Jesson, A., Branchaud-Charron, F., and Gal, Y . Stochastic batch acquisition: A simple baseline for deep active learning. Transactions on Machine Learning Research, 2023,
-
[23]
ISSN 0028-0836, 1476-4687. doi: 10.1038/nature14539. Li, D., Shi, X., Zhang, Y ., Cheung, K. C., See, S., Wang, X., Qin, H., and Li, H. A simple baseline for video restora- tion with grouped spatial-temporal shift. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24, 2023, 10 Fusion or Confusion? ...
-
[24]
Li, J., Ohanyan, M., Goel, V ., Navasardyan, S., Wei, Y ., and Shi, H. Videomatt: A simple baseline for accessible real-time video matting. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, pp. 2177–2186, June 2023b. Li, S., Chen, C., and Han, J. Simmlm: A simple frame- work for multi-modal learning with...
-
[25]
doi: 10.48550/ARXIV . 2507.19264. arXiv: 2507.19264. Li, W., Zhou, H., Yu, J., Song, Z., and Yang, W. Coupled mamba: Enhanced multimodal fusion with coupled state space model. In Globerson, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J., and Zhang, C. (eds.), Advances in Neural Information Processing Systems, vol- ume 37, pp. 59808–59832. ...
work page internal anchor Pith review doi:10.48550/arxiv
-
[26]
Swintrack: A simple and strong baseline for transformer tracking
Lin, L., Fan, H., Zhang, Z., Xu, Y ., and Ling, H. Swintrack: A simple and strong baseline for transformer tracking. In Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., and Oh, A. (eds.),Advances in Neural Infor- mation Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, N...
work page 2022
-
[27]
ISSN 0001-0782, 1557-7317. doi: 10.1145/3316774. Liu, Y ., Yuan, Z., Mao, H., Liang, Z., Yang, W., Qiu, Y ., Cheng, T., Li, X., Xu, H., and Gao, K. Make acoustic and visual cues matter: Ch-sims v2.0 dataset and av- mixup consistent module. In Tumuluri, R., Sebe, N., Pin- gali, G., Jayagopi, D. B., Dhall, A., Singh, R., Anthony, L., and Salah, A. A. (eds.)...
-
[28]
Liu, Z., Mao, H., Wu, C.-Y ., Feichtenhofer, C., Dar- rell, T., and Xie, S
doi: 10.18653/V1/P18-1209. Liu, Z., Mao, H., Wu, C.-Y ., Feichtenhofer, C., Dar- rell, T., and Xie, S. A convnet for the 2020s. In IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022, pp. 11966–11976. IEEE, 2022b. doi: 10.1109/CVPR52688.2022.01167. Liu, Z., Liu, Q., Chen, J., Huang, S., and L...
-
[29]
Smil: Multimodal learning with severely missing modality
Ma, M., Ren, J., Zhao, L., Tulyakov, S., Wu, C., and Peng, X. Smil: Multimodal learning with severely missing modality. InThirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2021, Thirty-Third Conference on In- novative Applications of Artificial Intelligence, IAAI 2021, The Eleventh Symposium on Educational Advances in Artificial Intelligence, ...
work page 2021
-
[30]
SMIL: Multimodal learning with severely missing modality
doi: 10.1609/AAAI.V35I3.16330. Ma, M., Ren, J., Zhao, L., Testuggine, D., and Peng, X. Are multimodal transformers robust to missing modality? In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022, pp. 18156–18165. IEEE,
-
[31]
1109/CVPR52688.2022.01764. Maaten, L. v. d. and Hinton, G. Visualizing data using t-sne.Journal of Machine Learning Research, 9(86): 2579–2605,
-
[32]
J., Izmailov, P., Garipov, T., Vetrov, D
Maddox, W. J., Izmailov, P., Garipov, T., Vetrov, D. P., and Wilson, A. G. A simple baseline for bayesian uncertainty in deep learning. In Wallach, H. M., Larochelle, H., 11 Fusion or Confusion? Multimodal Complexity Is Not All You Need Beygelzimer, A., d’Alch´e Buc, F., Fox, E. B., and Garnett, R. (eds.),Advances in Neural Information Processing Systems ...
work page 2019
-
[33]
Molmix: A simple yet effective baseline for multimodal molecular representation learning
Manolache, A.-M., Tantaru, D.-C., and Niepert, M. Molmix: A simple yet effective baseline for multimodal molecular representation learning. InAdvances in Neural Infor- mation Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, Machine Learning in Structural Biology Workshop, NeurIPS 2024, Vancouver, BC, Canada, December...
work page 2024
-
[34]
Attention bottlenecks for multimodal fusion
Nagrani, A., Yang, S., Arnab, A., Jansen, A., Schmid, C., and Sun, C. Attention bottlenecks for multimodal fusion. In Ranzato, M., Beygelzimer, A., Dauphin, Y . N., Liang, P., and Vaughan, J. W. (eds.),Advances in Neural Infor- mation Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, December 6-14, 2021,...
work page 2021
-
[35]
K., Patil, A., Solh, M., and Asif, M
Nezakati, N., Reza, M. K., Patil, A., Solh, M., and Asif, M. S. Mmp: Towards robust multi-modal learning with masked modality projection. arXiv:2410.03010 [cs], Oc- tober
-
[36]
Peebles, W. and Xie, S. Scalable diffusion models with transformers. InIEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023, pp. 4172–4182. IEEE,
work page 2023
-
[37]
In: 2023 IEEE/CVF International Conference on Computer Vision (ICCV)
doi: 10.1109/ ICCV51070.2023.00387. Peng, X., Wei, Y ., Deng, A., Wang, D., and Hu, D. Bal- anced multimodal learning via on-the-fly gradient mod- ulation. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022, pp. 8228–8237. IEEE,
-
[38]
doi: 10.1109/CVPR52688.2022.00806. Pineau, J., Vincent-Lamarre, P., Sinha, K., Lariviere, V ., Beygelzimer, A., d’Alche Buc, F., Fox, E., and Larochelle, H. Improving reproducibility in machine learning research(a report from the neurips 2019 repro- ducibility program).Journal of Machine Learning Re- search, 22(164):1–20,
-
[39]
Prabhu, A., Torr, P. H. S., and Dokania, P. K. Gdumb: A simple approach that questions our progress in contin- ual learning. In Vedaldi, A., Bischof, H., Brox, T., and Frahm, J.-M. (eds.),Computer Vision - ECCV 2020 - 16th European Conference, Glasgow, UK, August 23-28, 2020, Proceedings, Part II, volume 12347 ofLecture Notes in Computer Science, pp. 524–...
work page 2020
-
[40]
doi: 10.1007/978-3-030-58536-5
-
[41]
Rdumb: A simple approach that questions our progress in continual test-time adaptation
Press, O., Schneider, S., K ¨ummerer, M., and Bethge, M. Rdumb: A simple approach that questions our progress in continual test-time adaptation. In Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., and Levine, S. (eds.),Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2...
work page 2023
-
[42]
Cohort-Based Active Modality Acquisition
Rheude, T., Eils, R., and Wild, B. Cohort-based active modality acquisition. arXiv:2505.16791 [cs], December
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
Shi, J., Zhong, Y ., Xu, N., Li, Y ., and Xu, C
doi: 10.1002/AAAI.70002. Shi, J., Zhong, Y ., Xu, N., Li, Y ., and Xu, C. A simple baseline for weakly-supervised scene graph generation. In2021 IEEE/CVF International Conference on Com- puter Vision, ICCV 2021, Montreal, QC, Canada, Oc- tober 10-17, 2021, pp. 16373–16382. IEEE,
-
[44]
Walk in the cloud: Learning curves for point clouds shape analysis, pp
doi: 10.1109/ICCV48922.2021.01608. Shukor, M., Fini, E., Costa, V . G. T. d., Cord, M., Susskind, J., and El-Nouby, A. Scaling laws for native multi- modal models scaling laws for native multimodal models. arXiv:2504.07951 [cs], April
-
[45]
Soenksen, L. R., Ma, Y ., Zeng, C., Boussioux, L., Vil- lalobos Carballo, K., Na, L., Wiberg, H. M., Li, M. L., Fuentes, I., and Bertsimas, D. Integrated multimodal arti- ficial intelligence framework for healthcare applications. npj Digital Medicine, 5(1):149, September 2022a. ISSN 2398-6352. doi: 10.1038/s41746-022-00689-4. 12 Fusion or Confusion? Multi...
-
[46]
doi:10.1371/journal.pmed.1001779
ISSN 1549-1676. doi: 10.1371/journal.pmed.1001779. Tsai, Y .-H. H., Bai, S., Liang, P. P., Kolter, J. Z., Morency, L.-P., and Salakhutdinov, R. Multimodal transformer for unaligned multimodal language sequences. In Korhonen, A., Traum, D. R., and M `arquez, L. (eds.),Proceedings of the 57th Conference of the Association for Computa- tional Linguistics, AC...
-
[47]
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A
doi: 10.18653/V1/P19-1656. Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., and Polosukhin, I. Attention is all you need. In Guyon, I., Luxburg, U. v., Bengio, S., Wallach, H. M., Fergus, R., Vishwanathan, S. V . N., and Garnett, R. (eds.),Advances in Neural Information Processing Systems 30: Annual Conference on N...
-
[48]
In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp
Wang, H., Chen, Y ., Ma, C., Avery, J., Hull, L., and Carneiro, G. Multi-modal learning with missing modality via shared-specific feature modelling. InIEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24, 2023, pp. 15878–15887. IEEE, 2023a. doi: 10.1109/CVPR52729. 2023.01524. Wang, W., Tran, D., an...
-
[49]
In: Proceedings of the IEEE/CVF Conference on Computer 25 Vision and Pattern Recognition, pp
doi: 10.1109/CVPR42600.2020.01271. Wang, Y ., Li, Y ., and Cui, Z. Incomplete multimodality- diffused emotion recognition. In Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., and Levine, S. (eds.),Advances in Neural Information Processing Sys- tems 36: Annual Conference on Neural Information Pro- cessing Systems 2023, NeurIPS 2023, New Orleans, ...
-
[50]
IEEE, 2025a. Wei, S., Luo, C., and Luo, Y . Improving multimodal learn- ing via imbalanced learning. In2025 IEEE/CVF Inter- national Conference on Computer Vision, ICCV 2025, Honolulu, Hawaii, October 19-23,
work page 2025
-
[51]
Deep Multimodal Learning with Missing Modality: A Survey
Wu, R., Wang, H., Chen, H.-T., and Carneiro, G. Deep multimodal learning with missing modality: A survey. arXiv:2409.07825 [cs], October
work page internal anchor Pith review arXiv
-
[52]
Xia, Y ., Yang, X., Liu, Z., Liu, Z., Song, L., and Bian, J. Position: Rethinking post-hoc search-based neural approaches for solving large-scale traveling salesman 13 Fusion or Confusion? Multimodal Complexity Is Not All You Need problems. InForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27,
work page 2024
-
[53]
arXiv preprint arXiv:2503.20047 , year=
Xin, Y ., Ates, G. C., Gong, K., and Shao, W. Med3dvlm: An efficient vision-language model for 3d medical image analysis. arXiv: 2503.20047,
-
[54]
Xmodel- vlm: A simple baseline for multimodal vision language model
Xu, W., Liu, Y ., He, L., Huang, X., and Jiang, L. Xmodel- vlm: A simple baseline for multimodal vision language model. arXiv:2405.09215 [cs], June
-
[55]
MOSI: Multimodal Corpus of Sentiment Intensity and Subjectivity Analysis in Online Opinion Videos
Association for Computational Linguistics. doi: 10.18653/v1/2020.acl-main.343. Zadeh, A., Zellers, R., Pincus, E., and Morency, L.-P. Mosi: Multimodal corpus of sentiment intensity and subjectivity analysis in online opinion videos. arXiv:1606.06259 [cs], August
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2020.acl-main.343 2020
-
[56]
Zhang, Y ., Pfahringer, B., Frank, E., Bifet, A., Lim, N. J. S., and Jia, Y . A simple but strong baseline for online contin- ual learning: Repeated augmented rehearsal. In Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., and Oh, A. (eds.),Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing ...
work page 2022
-
[57]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Zhang, Y ., Li, M., Long, D., Zhang, X., Lin, H., Yang, B., Xie, P., Yang, A., Liu, D., Lin, J., Huang, F., and Zhou, J. Qwen3 embedding: Advancing text embedding and reranking through foundation models. arXiv:2506.05176 [cs], June
work page internal anchor Pith review Pith/arXiv arXiv
-
[58]
A simple baseline for spoken language to sign lan- guage translation with 3d avatars
Zuo, R., Wei, F., Chen, Z., Mak, B., Yang, J., and Tong, X. A simple baseline for spoken language to sign lan- guage translation with 3d avatars. In Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., and Varol, G. (eds.),Computer Vision - ECCV 2024 - 18th European Conference, Milan, Italy, September 29-October 4, 2024, Proceedings, Part XLI...
work page 2024
-
[59]
doi: 10.1007/978-3-031-72967-6
-
[60]
14 Fusion or Confusion? Multimodal Complexity Is Not All You Need A. Method Re-Implementation Details For every method, weight initialization is applied through- out the entire architecture, including encoders and method- specific extensions (Kaiming initialization for linear and convolutional layers with biases set to zero, constant values for the weight...
work page 2025
-
[61]
embeddings based on previously used serializations (Hegselmann et al., 2025). Individual miss- ing entries within a modality were imputed with zeros, and instances where a feature vector was entirely absent were excluded. Table 7.Unimodal performance of the modalities for the UKB without zero imputation, i.e.,only the available modality subset is used. Mo...
work page 2025
-
[62]
Simi- lar to MOS(E)I, they are trimodal but provide raw data
video clips of speakers expressing emotions. Simi- lar to MOS(E)I, they are trimodal but provide raw data. We use Wav2Vec2, ViViT, and BERT for the audio, video, and language data, respectively. Crema-DCrema-D is a dataset for multimodal sentiment analysis with six emotion classes (such as anger and fear) that can be further subdivided into a more fine-gr...
work page 2017
-
[63]
and to 0.04 under ϵ= 0.02 (Table 10), while P(≈) increases from 0.28→0.67→0.95 . Thus, if a ≥1% improvement is considered practically meaningful (as in Section 4.2), no method shows strong evidence of outperforming SimBaMM- CLS; if a tighter threshold is used, CoupledMamba appears more likely to beslightlybetter, consistent with a small estimated mean eff...
work page 2017
-
[64]
20 Fusion or Confusion? Multimodal Complexity Is Not All You Need Table 10.Comparison with SimBaMM-CLS (ROPE±2%). Method P(base >other) P(≈) P(other >base) E[δ0]95% CI CoupledMamba 0.01 0.95 0.04 -0.006 [-0.021,0.006] Best unimodal 0.25 0.53 0.22 0.002 [-0.031,0.031] MMPareto 0.05 0.91 0.04 -0.002 [-0.019,0.022] ARL 0.11 0.84 0.06 0.002 [-0.019,0.028] GBl...
work page 2048
-
[65]
Table 11.Comparison with the best unimodal baseline (ROPE ±0.5%). Method P(base >other) P(≈) P(other >base) E[δ0]95% CI CoupledMamba 0.20 0.02 0.79 -0.010 [-0.038,0.024] SimBaMM-CLS 0.44 0.00 0.56 -0.002 [-0.031,0.031] MMPareto 0.69 0.02 0.29 0.013 [-0.026,0.066] ARL 0.23 0.02 0.76 -0.008 [-0.034,0.024] GBlend-On 0.65 0.02 0.33 0.011 [-0.029,0.062] BMML 0...
work page 2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.