DEFT: Differentiable Automatic Test Pattern Generation
Pith reviewed 2026-05-21 16:24 UTC · model grok-4.3
The pith
DEFT reformulates automatic test pattern generation as continuous optimization to cut test pattern counts for hard-to-detect faults.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
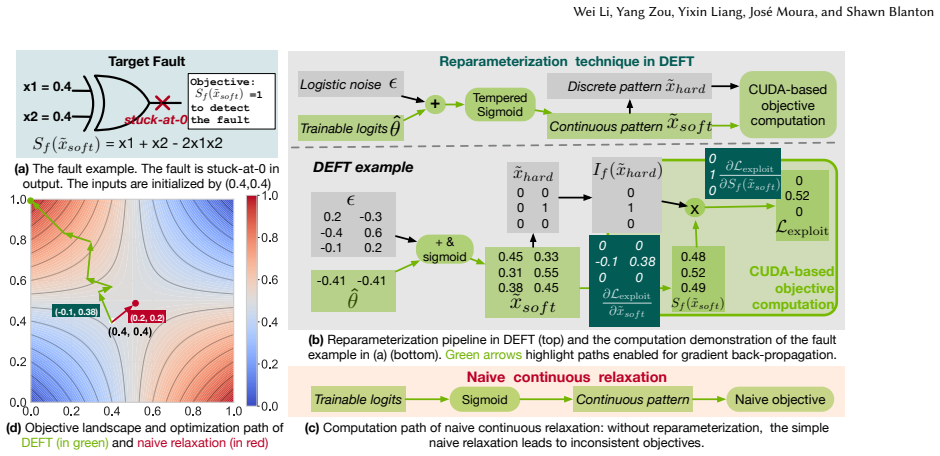
DEFT reformulates the discrete ATPG problem as a continuous optimization task. It introduces a mathematically grounded reparameterization that aligns the expected continuous objective with discrete fault-detection semantics, enabling reliable gradient-based pattern generation. To ensure scalability and stability on deep circuit graphs, DEFT integrates a custom CUDA kernel for efficient forward-backward propagation and applies gradient normalization to mitigate vanishing gradients. On benchmarks it reduces pattern count by 27.3% on average and up to 75.9%.
What carries the argument
The reparameterization that aligns the continuous objective with discrete fault-detection semantics for gradient-based optimization on circuit graphs.
If this is right
- DEFT reduces the number of test patterns by 27.3 percent on average compared to leading commercial tools.
- It can produce partial assignment patterns with 19.3 percent fewer specified bits while detecting 35 percent more faults.
- The method serves as a valuable complement to existing heuristic-based ATPG approaches.
Where Pith is reading between the lines
- This differentiable formulation could be adapted to optimize other aspects of circuit design that currently rely on discrete searches.
- Future work might combine DEFT with learning-based models to predict hard-to-detect faults more accurately before optimization.
- The approach may scale to even larger circuits if the custom kernel is further optimized for modern hardware.
Load-bearing premise
The reparameterization makes the continuous loss function correspond accurately to the discrete outcome of whether a pattern detects a given fault.
What would settle it
A direct comparison on a new suite of large industrial circuits where DEFT fails to produce fewer patterns than the commercial tool while maintaining fault coverage would disprove the practical advantage.
Figures





read the original abstract
Modern IC complexity drives test pattern growth, with the majority of patterns targeting a small set of hard-to-detect (HTD) faults. This motivates new ATPG algorithms to improve test effectiveness specifically for HTD faults. This paper presents DEFT (Differentiable Automatic Test Pattern Generation), a new ATPG approach that reformulates the discrete ATPG problem as a continuous optimization task. DEFT introduces a mathematically grounded reparameterization that aligns the expected continuous objective with discrete fault-detection semantics, enabling reliable gradient-based pattern generation. To ensure scalability and stability on deep circuit graphs, DEFT integrates a custom CUDA kernel for efficient forward-backward propagation and applies gradient normalization to mitigate vanishing gradients. Compared to a leading commercial tool on a wide range of benchmarks, DEFT reduced the pattern count by 27.3% on average and by up to 75.9%. DEFT also supports practical ATPG settings such as partial assignment pattern generation, producing patterns with 19.3% fewer 0/1 bits while still detecting 35% more faults. These results indicate DEFT is a promising and effective ATPG engine, offering a valuable complement to existing heuristics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DEFT, a differentiable automatic test pattern generation (ATPG) method that reformulates the discrete ATPG problem as a continuous optimization task. It proposes a mathematically grounded reparameterization to align the continuous objective with discrete fault-detection semantics, augmented by a custom CUDA kernel for forward-backward propagation on deep circuits and gradient normalization to mitigate vanishing gradients. On a range of benchmarks, DEFT is reported to reduce pattern counts by 27.3% on average (up to 75.9%) versus a leading commercial tool while also supporting partial-assignment generation with 19.3% fewer assigned bits and 35% more detected faults.
Significance. If the reparameterization reliably preserves discrete fault-detection semantics under gradient flow, the work would offer a meaningful complement to heuristic ATPG by enabling gradient-based search specifically for hard-to-detect faults. The reported pattern-count reductions would be practically relevant for test-cost reduction in IC manufacturing, and the custom CUDA kernel plus normalization demonstrate engineering attention to scalability on realistic circuit depths.
major comments (2)
- [§3] §3 (reparameterization): the manuscript asserts that the continuous relaxation 'aligns the expected continuous objective with discrete fault-detection semantics' yet provides neither a derivation showing preservation of monotonicity/ranking after reconvergence and fanout nor an empirical check (e.g., correlation between surrogate loss decrease and true fault-coverage increase) on circuits containing reconvergent paths. This alignment is load-bearing for the claim that gradient descent produces patterns that actually improve discrete detection.
- [§5] §5 (experimental results): the central performance figures (27.3% average, 75.9% max reduction) are presented without error bars, standard deviations across runs, or statistical significance tests, and without ablation isolating the reparameterization from the CUDA kernel and normalization; this weakens attribution of the gains to the core technical contribution.
minor comments (2)
- [§4] The description of the custom CUDA kernel would benefit from a short pseudocode listing or explicit reference to the forward and backward passes to aid reproducibility.
- Benchmark selection criteria and circuit characteristics (depth, reconvergence density) are not summarized in a table; adding such a table would help readers assess the scope of the claimed improvements.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments on our manuscript. We address each of the major comments below and are prepared to revise the paper accordingly to strengthen the presentation and validation of our claims.
read point-by-point responses
-
Referee: [§3] §3 (reparameterization): the manuscript asserts that the continuous relaxation 'aligns the expected continuous objective with discrete fault-detection semantics' yet provides neither a derivation showing preservation of monotonicity/ranking after reconvergence and fanout nor an empirical check (e.g., correlation between surrogate loss decrease and true fault-coverage increase) on circuits containing reconvergent paths. This alignment is load-bearing for the claim that gradient descent produces patterns that actually improve discrete detection.
Authors: We appreciate this observation. The reparameterization in Section 3 is derived to ensure that the continuous objective is a faithful relaxation of the discrete fault detection, with the expectation that gradient steps correspond to improvements in detection probability. However, to more rigorously address potential issues with reconvergent paths, we will add a formal proof sketch demonstrating preservation of monotonicity under fanout and reconvergence in the revised manuscript. Additionally, we will include an empirical study correlating the decrease in the surrogate loss with increases in actual fault coverage on benchmark circuits known to have reconvergent paths. revision: yes
-
Referee: [§5] §5 (experimental results): the central performance figures (27.3% average, 75.9% max reduction) are presented without error bars, standard deviations across runs, or statistical significance tests, and without ablation isolating the reparameterization from the CUDA kernel and normalization; this weakens attribution of the gains to the core technical contribution.
Authors: We agree that including variability measures and ablations would improve the robustness of the experimental claims. In the revised version, we will report standard deviations over multiple independent runs with different random seeds and include p-values from statistical tests comparing DEFT to the commercial tool. Furthermore, we will add an ablation study that isolates the effect of the reparameterization by comparing the full DEFT against a variant that uses a simpler continuous relaxation while retaining the CUDA kernel and gradient normalization. This will help attribute the performance gains more clearly to the proposed reparameterization. revision: yes
Circularity Check
No circularity: reparameterization is presented as novel ansatz without reduction to inputs
full rationale
The provided abstract and context introduce DEFT as a reformulation of discrete ATPG into continuous optimization via a 'mathematically grounded reparameterization' that aligns objectives with fault-detection semantics, followed by custom CUDA kernels and gradient normalization for scalability. No equations, fitted parameters, or self-citations are quoted that would make any prediction or result equivalent to its inputs by construction. The performance claims rest on empirical comparison to a commercial tool rather than on quantities defined in terms of the method's own outputs. This is a standard application of differentiable programming to a new domain, with the derivation chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Gradient-based methods can be made to respect the discrete 0/1 semantics of circuit fault detection through reparameterization
invented entities (1)
-
Differentiable reparameterization for ATPG
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DEFT introduces a mathematically grounded reparameterization that aligns the expected continuous objective with discrete fault-detection semantics... hybrid surrogate... L_exploit = E[ S_f(˜x_soft) · I_f(˜x_hard) ]
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
custom CUDA kernel... gradient normalization... probabilistic logic relaxations
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
“Chapter 17: Test technology, ” inHeterogeneous Integration Roadmap (HIR), 2024 Edition, 2024, online: https://eps.ieee.org/hir
work page 2024
-
[2]
F. Hapke, W. Redemund, A. Glowatz, J. Rajski, M. Reese, M. Hustava, M. Keim, J. Schloeffel, and A. Fast, “Cell-aware test, ”IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol. 33, no. 9, pp. 1396–1409, 2014
work page 2014
-
[3]
Pepr: Pseudo-exhaustive physically- aware region testing,
W. Li, C. Nigh, D. Duvalsaint, and S. Mitra, “Pepr: Pseudo-exhaustive physically- aware region testing, ” in2022 IEEE International Test Conference (ITC). IEEE, 2022, pp. 314–323
work page 2022
-
[4]
W. Li, H. Lyu, S. Liang, T. Wang, and H. Li, “Smartatpg: Learning-based automatic test pattern generation with graph convolutional network and reinforcement learning, ” inProceedings of the 61st ACM/IEEE Design Automation Conference, 2024, pp. 1–6
work page 2024
-
[5]
Pastatpg: A hybrid atpg framework for better test compaction with partial assignment sat,
Z. Chao, X. Zhang, X. Zhang, J. Mu, Z. Liu, S. Liang, S. Cai, J. Ye, X. Li, and H. Li, “Pastatpg: A hybrid atpg framework for better test compaction with partial assignment sat, ” in2025 62nd ACM/IEEE Design Automation Conference (DAC). IEEE, 2025, pp. 1–7
work page 2025
-
[6]
Deep graph library: Towards efficient and scalable deep learning on graphs,
M. Y. Wang, “Deep graph library: Towards efficient and scalable deep learning on graphs, ” inICLR workshop on representation learning on graphs and manifolds, 2019
work page 2019
-
[7]
An implicit enumeration algorithm to generate tests for combinational logic circuits,
Goel, “An implicit enumeration algorithm to generate tests for combinational logic circuits, ”IEEE transactions on Computers, vol. 100, no. 3, pp. 215–222, 1981
work page 1981
-
[8]
On the acceleration of test generation algorithms,
Fujiwara and Shimono, “On the acceleration of test generation algorithms, ”IEEE transactions on Computers, vol. 100, no. 12, pp. 1137–1144, 1983
work page 1983
-
[9]
Recent advances in sat- based atpg: Non-standard fault models, multi constraints and optimization,
B. Becker, R. Drechsler, S. Eggersglüß, and M. Sauer, “Recent advances in sat- based atpg: Non-standard fault models, multi constraints and optimization, ” in 2014 9th IEEE International Conference on Design & Technology of Integrated Systems in Nanoscale Era (DTIS). IEEE, 2014, pp. 1–10
work page 2014
-
[10]
Dreamplace: Deep learn- ing toolkit-enabled gpu acceleration for modern vlsi placement,
Y. Lin, S. Dhar, W. Li, H. Ren, B. Khailany, and D. Z. Pan, “Dreamplace: Deep learn- ing toolkit-enabled gpu acceleration for modern vlsi placement, ” inProceedings of the 56th Annual Design Automation Conference 2019, 2019, pp. 1–6
work page 2019
-
[11]
Dgr: Dif- ferentiable global router,
W. Li, R. Liang, A. Agnesina, H. Yang, C.-T. Ho, A. Rajaram, and H. Ren, “Dgr: Dif- ferentiable global router, ” inProceedings of the 61st ACM/IEEE Design Automation Conference, 2024, pp. 1–6
work page 2024
-
[12]
Y.-C. Lu, Z. Guo, K. Kunal, R. Liang, and H. Ren, “Insta: An ultra-fast, differ- entiable, statistical static timing analysis engine for industrial physical design applications, ” in2025 62nd ACM/IEEE Design Automation Conference (DAC). IEEE, 2025, pp. 1–7
work page 2025
-
[13]
Towards next-generation logic synthesis: A scalable neural circuit genera- tion framework,
Z. Wang, J. Wang, Q. Yang, Y. Bai, X. Li, L. Chen, J. Hao, M. Yuan, B. Li, Y. Zhang et al., “Towards next-generation logic synthesis: A scalable neural circuit genera- tion framework, ”Advances in Neural Information Processing Systems, vol. 37, pp. 99 202–99 231, 2024
work page 2024
-
[14]
Deep differentiable logic gate networks,
F. Petersen, C. Borgelt, H. Kuehne, and O. Deussen, “Deep differentiable logic gate networks, ”Advances in Neural Information Processing Systems, vol. 35, pp. 2006–2018, 2022
work page 2006
-
[15]
Safety-guided test generation for structural faults,
X. Tan, D. Thapar, D. Sahoo, A. Chaudhuri, S. Banerjee, K. Chakrabarty, and R. Parekhji, “Safety-guided test generation for structural faults, ” in2024 IEEE International Test Conference (ITC). IEEE, 2024, pp. 233–242
work page 2024
-
[16]
Categorical Reparameterization with Gumbel-Softmax
E. Jang, S. Gu, and B. Poole, “Categorical reparameterization with gumbel- softmax, ”arXiv preprint arXiv:1611.01144, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[17]
Differentiable integer linear programming,
Z. Geng, J. Wang, X. Li, F. Zhu, J. Hao, B. Li, and F. Wu, “Differentiable integer linear programming, ” inThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[18]
Defect modeling using fault tuples,
R. D. Blanton, K. N. Dwarakanath, and R. Desineni, “Defect modeling using fault tuples, ”IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol. 25, no. 11, pp. 2450–2464, 2006
work page 2006
-
[19]
Opensparc t2 system-on-chip (soc) design,
Sun Microsystems, Inc., “Opensparc t2 system-on-chip (soc) design, ” https:// www.oracle.com/servers/technologies/opensparc-t2-page.html, 2008
work page 2008
-
[20]
NVIDIA Corporation, “Nvdla open source hardware, ” https://github.com/nvdla/ hw, 2017
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.