AMA: Adaptive Memory via Multi-Agent Collaboration
Pith reviewed 2026-05-16 11:00 UTC · model grok-4.3
The pith
Multi-agent collaboration lets LLM agents adapt memory granularity to tasks and cut token use by 80 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
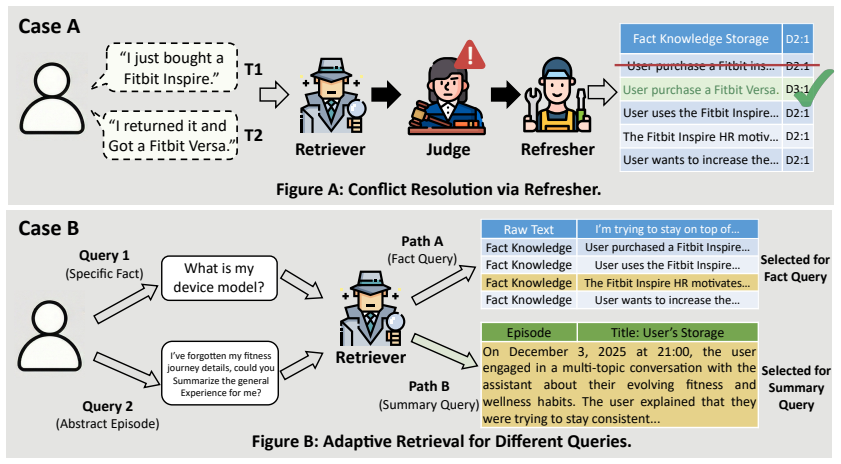
AMA employs a hierarchical memory design in which the Constructor and Retriever jointly build and route queries across granularities, the Judge checks retrieved content for relevance and consistency, and the Refresher performs targeted updates or deletions when conflicts appear. This coordinated process dynamically aligns memory detail with task complexity, enabling iterative retrieval when needed and enforcing long-term consistency without unchecked accumulation of outdated entries.
What carries the argument
The multi-agent collaboration loop with Constructor, Retriever, Judge, and Refresher agents that dynamically selects memory granularity and enforces consistency through verification and targeted refresh.
If this is right
- Agents maintain higher retrieval precision across sessions because granularity matches query needs instead of staying fixed.
- Token consumption drops sharply since only relevant memory slices are retrieved rather than full context.
- Logical inconsistencies are reduced over time through explicit detection and removal by the Refresher.
- Long-term interaction coherence improves because memory updates target only conflicting entries.
Where Pith is reading between the lines
- The same collaboration pattern could apply to domains like multi-step planning where conflict detection between subgoals is critical.
- Scaling the number of memory layers or agents might further reduce inconsistency rates in very long histories.
- Integration into existing agent frameworks could decrease reliance on hand-crafted prompts for memory management.
Load-bearing premise
The agents can accurately detect logical conflicts and task complexity so that granularity adjustments and refreshes improve rather than degrade retrieval accuracy.
What would settle it
Insert deliberate factual contradictions into a long-context benchmark and measure whether AMA's retrieval precision remains higher than rigid baselines or collapses when the Judge and Refresher are active.
Figures











read the original abstract
The rapid evolution of Large Language Model (LLM) agents has necessitated robust memory systems to support cohesive long-term interaction and complex reasoning. Benefiting from the strong capabilities of LLMs, recent research focus has shifted from simple context extension to the development of dedicated agentic memory systems. However, existing approaches typically rely on rigid retrieval granularity, accumulation-heavy maintenance strategies, and coarse-grained update mechanisms. These design choices create a persistent mismatch between stored information and task-specific reasoning demands, while leading to the unchecked accumulation of logical inconsistencies over time. To address these challenges, we propose Adaptive Memory via Multi-Agent Collaboration (AMA), a novel framework that leverages coordinated agents to manage memory across multiple granularities. AMA employs a hierarchical memory design that dynamically aligns retrieval granularity with task complexity. Specifically, the Constructor and Retriever jointly enable multi-granularity memory construction and adaptive query routing. The Judge verifies the relevance and consistency of retrieved content, triggering iterative retrieval when evidence is insufficient or invoking the Refresher upon detecting logical conflicts. The Refresher then enforces memory consistency by performing targeted updates or removing outdated entries. Extensive experiments on challenging long-context benchmarks show that AMA significantly outperforms state-of-the-art baselines while reducing token consumption by approximately 80% compared to full-context methods, demonstrating its effectiveness in maintaining retrieval precision and long-term memory consistency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AMA (Adaptive Memory via Multi-Agent Collaboration), a framework for LLM agent memory management. It introduces a hierarchical memory structure with four coordinated agents—Constructor for multi-granularity construction, Retriever for adaptive query routing, Judge for relevance/consistency verification and iterative retrieval, and Refresher for targeted updates or removal of inconsistent entries. The design aims to dynamically align memory granularity with task complexity while enforcing long-term consistency. Extensive experiments on long-context benchmarks are claimed to demonstrate significant outperformance over state-of-the-art baselines together with an approximately 80% reduction in token consumption relative to full-context methods.
Significance. If the empirical results hold under rigorous verification, this work offers a substantive contribution to agentic memory systems by moving beyond rigid granularity and accumulation-heavy strategies toward dynamic, multi-agent coordination. The token-efficiency gains and consistency mechanisms address practical bottlenecks in long-term LLM interactions, with potential to influence designs for conversational agents and complex reasoning pipelines. The explicit multi-agent decomposition for memory tasks is a clear strength that could be extended in follow-on research.
major comments (2)
- [Abstract and Experiments] Abstract and Experiments section: the central claims of significant outperformance and ~80% token reduction rest on empirical results, yet the provided manuscript text supplies no concrete details on the specific long-context benchmarks, the exact SOTA baselines, evaluation metrics (e.g., retrieval precision, consistency scores), or ablation studies isolating each agent's contribution. Without these, the load-bearing empirical support cannot be fully assessed.
- [Framework description] Framework description (Judge and Refresher roles): the assumption that multi-agent collaboration can reliably detect logical conflicts and adjust granularity without introducing new retrieval errors or inconsistencies is load-bearing for the consistency claims, but the text lacks quantitative evidence or concrete detection rules showing that the Judge's verification step improves rather than degrades overall performance.
minor comments (2)
- [Notation and figures] Clarify notation for memory granularity levels and query routing logic to ensure readers can reproduce the adaptive mechanism without ambiguity.
- [Methods] Add explicit pseudocode or algorithmic description for the iterative retrieval loop triggered by the Judge to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that greater specificity on benchmarks, baselines, metrics, ablations, and quantitative validation of the Judge component will strengthen the manuscript and will incorporate these elements in the revision.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: the central claims of significant outperformance and ~80% token reduction rest on empirical results, yet the provided manuscript text supplies no concrete details on the specific long-context benchmarks, the exact SOTA baselines, evaluation metrics (e.g., retrieval precision, consistency scores), or ablation studies isolating each agent's contribution. Without these, the load-bearing empirical support cannot be fully assessed.
Authors: We acknowledge the need for more explicit detail. The Experiments section describes the use of long-context benchmarks such as LongBench and multi-hop QA tasks, compares against baselines including MemGPT and standard RAG variants, and reports accuracy together with token consumption. To make the empirical support fully transparent, we will add a summary table listing the exact datasets, baseline scores with numerical values, retrieval precision and consistency metrics, and a dedicated ablation table that isolates the contribution of each agent (Constructor, Retriever, Judge, Refresher). revision: yes
-
Referee: [Framework description] Framework description (Judge and Refresher roles): the assumption that multi-agent collaboration can reliably detect logical conflicts and adjust granularity without introducing new retrieval errors or inconsistencies is load-bearing for the consistency claims, but the text lacks quantitative evidence or concrete detection rules showing that the Judge's verification step improves rather than degrades overall performance.
Authors: The manuscript outlines the Judge's verification as an LLM-prompted check for relevance and logical contradictions, with the Refresher performing targeted edits or deletions. We agree that explicit rules and direct quantitative evidence are required. In the revision we will (1) provide the precise prompting templates and decision rules used for conflict detection and (2) add an ablation that reports inconsistency rates, retrieval error rates, and end-task performance with versus without the Judge step, thereby demonstrating that the verification improves rather than degrades results. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes a new multi-agent framework (AMA) for adaptive memory in LLM agents, with roles for Constructor, Retriever, Judge, and Refresher to handle granularity, consistency, and updates. Claims of outperformance and ~80% token reduction rest on empirical results from long-context benchmarks rather than any mathematical derivation, fitted parameters renamed as predictions, or self-citation chains that reduce to inputs. The design is presented as a direct response to limitations in prior rigid-retrieval approaches, with no equations or self-definitional loops identified. The argument structure remains self-contained and externally falsifiable via the reported experiments.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
AMA employs a hierarchical memory design that dynamically aligns retrieval granularity with task complexity... The Judge verifies the relevance and consistency... triggering iterative retrieval... or invoking the Refresher upon detecting logical conflicts.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The Retriever... generates... a four-dimensional binary intent vector B... routing function fM dynamically selects the appropriate retrieval operator
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Fatemeh Haji, Mazal Bethany, Maryam Tabar, Ja- son Chiang, Anthony Rios, and Peyman Najafi- rad
The faiss library.IEEE Transactions on Big Data. Fatemeh Haji, Mazal Bethany, Maryam Tabar, Ja- son Chiang, Anthony Rios, and Peyman Najafi- rad. 2024. Improving llm reasoning with multi- agent tree-of-thought validator agent.arXiv preprint arXiv:2409.11527. Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zi...
-
[2]
From isolated conversations to hierarchical schemas: Dynamic tree memory representation for llms.arXiv preprint arXiv:2410.14052. Theodore Sumers, Shunyu Yao, Karthik Narasimhan, and Thomas Griffiths. 2023. Cognitive architectures for language agents.Transactions on Machine Learn- ing Research. Zhen Tan, Jun Yan, I-Hung Hsu, Rujun Han, Zifeng Wang, Long L...
-
[3]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Shaowei Zhang and Deyi Xiong. 2025. Debate4math: Multi-agent debate for fine-grained reasoning in math. InFindings of the Association for Computational Linguistics: ACL 2025, pages 16810–16824. Zeyu Zhang, Quanyu Dai, Xiaohe Bo, Chen Ma, Rui Li, Xu Chen, Jieming Zhu, Zhenhua Dong, and Ji-Rong Wen. 20...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
C = Complement (attribute or state)
-
[5]
L = Location or explicit time [Sentence Pattern Constraint] Each fact MUST follow exactly one of the following forms:
-
[6]
S–V–O–L Any fact not matching these patterns is invalid. [Atomicity Rules] • Each fact representsone single relation only. • Do NOT merge actions, attributes, locations, or roles. • Descriptive or prepositional phrases must be split into separate facts. [Appositive Rule] If the input contains appositive or implicit equivalence (e.g., “my friend John”, “my...
-
[7]
The episode represents one coherent event or topic
-
[8]
The description must preserve factual accuracy and chronological order
-
[9]
Do not introduce information that is not present in the conversation. Time Handling Rules: • Identify the episode time from explicit timestamps in the dialogue. • If relative time expressions appear in the conversation, convert them into absolute dates based on available context, and keep the converted time consistent throughout the episode. • If no relia...
-
[10]
a standalone rewritten queryu ′ t with resolved references,
-
[11]
a four-dimensional binary intent vectorB,
-
[12]
a dynamic retrieval budgetK dyn,
-
[13]
a target memory type for retrieval. Intent Vector Definition: B= [b f ine, babs, bevent, batomic] •b f ine = 1if the query requires fine-grained or exact details. •b abs = 1if the query is abstract or summary-oriented. •b event = 1if the query involves cross-turn, cross-time, or event-level semantics. •b atomic = 1if the query is short, single-point, and ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.