Recognition: 2 theorem links
· Lean TheoremAmortized Molecular Optimization via Group Relative Policy Optimization
Pith reviewed 2026-05-16 02:05 UTC · model grok-4.3
The pith
A graph transformer optimizes constrained molecules in one forward pass with no oracle calls at inference time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
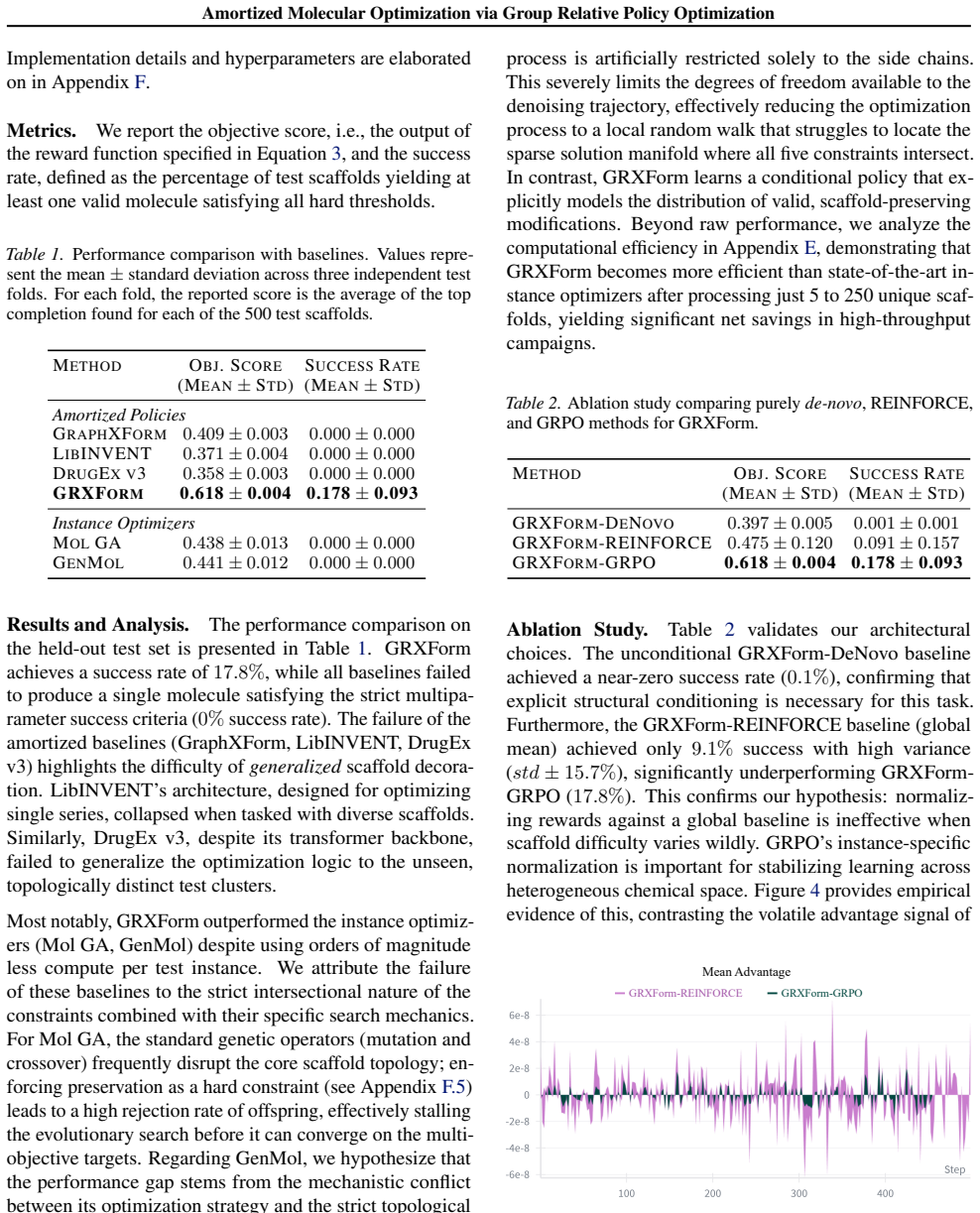
AMORTIX is an amortized Graph Transformer model that natively supports structural constraints and optimizes molecular structures in a single forward pass with zero inference-time oracle calls. The central innovation is group relative policy optimization, which addresses training instability from heterogeneous optimization difficulties by normalizing rewards within groups of completions sharing the same starting structure.
What carries the argument
Group Relative Policy Optimization applied to a Graph Transformer policy that generates molecular modifications from constrained starting structures.
If this is right
- Optimization scales to many starting structures without proportional increase in oracle evaluations.
- Learned policies transfer to unseen drug structures, as shown in the prodrug case study.
- Outperforms instance-optimization baselines on goal-directed scaffold decoration for kinase inhibitors.
- Ranks first among amortized methods on the PMO benchmark for molecular optimization.
- Supports single- and multi-target optimization tasks under structural constraints.
Where Pith is reading between the lines
- Similar group-normalization techniques could stabilize training in other reinforcement learning settings with heterogeneous task difficulties.
- The single-pass nature suggests potential for integration into high-throughput virtual screening pipelines.
- Further work might explore combining this with more expressive generative models for broader chemical space coverage.
Load-bearing premise
That normalizing rewards within groups of completions sharing the same starting structure is sufficient to stabilize training when optimization difficulty varies drastically across starting structures.
What would settle it
Observing that removing the group normalization leads to unstable training or poor generalization on a diverse set of starting kinase inhibitor scaffolds would falsify the claim.
Figures



read the original abstract
In structurally constrained molecular optimization, state-of-the-art methods restart an expensive oracle-driven search from scratch for every new input structure, scaling poorly to settings with many starting structures or expensive oracles. While amortized approaches that learn a transferable policy could in principle remove this bottleneck, existing methods struggle to generalize to diverse structural constraints at inference time. We present AMORTIX, an amortized Graph Transformer model that natively supports such constraints, optimizing molecular structures in a single forward pass with zero inference-time oracle calls. A central challenge for amortized training in this domain is that optimization difficulty varies drastically across starting structures. We show that, under this heterogeneity, standard reinforcement learning methods fail to stabilize training, and address this by normalizing rewards within groups of completions sharing the same starting structure. We evaluate on structurally constrained single- and multi-target kinase inhibitor design, and on a few-shot prodrug case study. AMORTIX outperforms both amortized and instance-optimization baselines on goal-directed scaffold decoration and ranks first among amortized methods on the PMO benchmark; the prodrug case study further demonstrates transfer of a learned modification rule to unseen drug structures. Code is available at https://github.com/Hash-hh/AMORTIX/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents AMORTIX, an amortized Graph Transformer policy for structurally constrained molecular optimization. It claims to solve the problem of repeated expensive oracle searches by learning a transferable policy that optimizes molecules in a single forward pass with zero inference-time oracle calls. The key technical contribution is group-relative policy optimization, which normalizes rewards within groups of completions sharing the same starting structure to stabilize training under heterogeneous optimization difficulty. Empirical results show outperformance over both amortized and instance-optimization baselines on kinase inhibitor scaffold decoration tasks, first place among amortized methods on the PMO benchmark, and successful transfer in a prodrug case study.
Significance. If the central empirical claims hold after addressing experimental details, the work offers a practical route to scalable amortized molecular design that removes the per-instance oracle bottleneck. The public code release is a clear strength that aids verification and extension.
major comments (3)
- [§3.2 and §4.1] §3.2 and §4.1: The claim that standard RL fails due to varying optimization difficulty across starting structures is central to motivating group normalization, yet the manuscript provides only qualitative training curves without quantitative metrics (e.g., reward variance per group or divergence rates) comparing training with and without the normalization step.
- [§5.1, Table 2] §5.1, Table 2: The PMO benchmark ranking as first among amortized methods is load-bearing for the amortized advantage claim, but the table and surrounding text omit exact oracle budgets, number of independent runs, and statistical significance tests for the reported scores.
- [§5.2] §5.2: Details on data splits, exact oracle definitions, and hyperparameter selection for the kinase inhibitor tasks are insufficient to assess whether the reported outperformance generalizes or depends on particular choices of group size and Graph Transformer architecture.
minor comments (2)
- [§4.2] The group size hyperparameter is listed as free but its sensitivity is not analyzed in an ablation; a brief sensitivity plot would clarify robustness.
- [Figure 4] Figure captions and axis labels in the training dynamics plots are occasionally ambiguous regarding which curves correspond to which baselines.
Circularity Check
No circularity in derivation chain
full rationale
The paper introduces AMORTIX as a Graph Transformer policy trained via group-relative policy optimization, where rewards are normalized within groups of completions from the same starting structure to address training instability under heterogeneous optimization difficulty. This is presented as an empirical stabilization technique rather than a derived result. No equations reduce reported performance metrics to fitted parameters by construction, and no load-bearing claims rely on self-citations that themselves reduce to the current work. The central claims rest on standard RL training plus the proposed normalization, evaluated on external benchmarks (PMO, kinase tasks) with code released for independent verification. The derivation chain is self-contained and does not exhibit any of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
free parameters (2)
- group size for reward normalization
- Graph Transformer hyperparameters (layers, heads, embedding dim)
axioms (2)
- domain assumption The environment can be modeled as a Markov decision process where actions correspond to molecular edits and rewards reflect property improvement under constraints.
- ad hoc to paper Reward normalization within groups sharing the same starting structure removes the effect of varying optimization difficulty.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We employ Group Relative Policy Optimization (GRPO) ... normalizing rewards relative to the group mean ... Ai,j = R(Oi,j) − μi
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
validity mask M(st) ... valence constraints
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
URL https://openreview.net/forum? id=Arn2E4IRjEB. Bickerton, G. R., Paolini, G. V ., Besnard, J., Muresan, S., and Hopkins, A. L. Quantifying the chemical beauty of drugs.Nature chemistry, 4(2):90–98, 2012. Butina, D. Unsupervised data base clustering based on daylight’s fingerprint and tanimoto similarity: A fast and automated way to cluster small and la...
-
[2]
Ghugare, R., Geist, M., Berseth, G., and Eysenbach, B
URL https://openreview.net/forum? id=yCZRdI0Y7G. Ghugare, R., Geist, M., Berseth, G., and Eysenbach, B. Closing the gap between TD learning and supervised learning - a generalisation point of view. InThe Twelfth International Conference on Learning Representations,
-
[3]
Haarnoja, T., Zhou, A., Abbeel, P., and Levine, S
URL https://openreview.net/forum? id=qg5JENs0N4. Haarnoja, T., Zhou, A., Abbeel, P., and Levine, S. Soft actor-critic: Off-policy maximum entropy deep reinforce- ment learning with a stochastic actor. InInternational conference on machine learning, pp. 1861–1870. Pmlr, 2018. Hetzel, L., Sommer, J., Rieck, B., Theis, F., and G¨unnemann, S. Magnet: Motif-ag...
-
[4]
Jin, W., Barzilay, R., and Jaakkola, T
PMLR, 2018. Jin, W., Barzilay, R., and Jaakkola, T. Multi-objective molecule generation using interpretable substructures. In International conference on machine learning, pp. 4849–
work page 2018
-
[5]
Kim, H., Kim, M., Choi, S., and Park, J
PMLR, 2020. Kim, H., Kim, M., Choi, S., and Park, J. Genetic-guided GFlownets for sample efficient molecular optimization. InThe Thirty-eighth Annual Conference on Neural In- formation Processing Systems, 2024. URL https: //openreview.net/forum?id=B4q98aAZwt. Kong, X., Huang, W., Tan, Z., and Liu, Y . Molecule gen- eration by principal subgraph mining and...
-
[6]
Proximal Policy Optimization Algorithms
doi: 10.1186/s13321-024-00812-5. URL https: //doi.org/10.1186/s13321-024-00812-5. Luo, Y ., Yan, K., and Ji, S. Graphdf: A discrete flow model for molecular graph generation. InInternational conference on machine learning, pp. 7192–7203. PMLR, 2021. Maziarz, K., Jackson-Flux, H. R., Cameron, P., Sirockin, F., Schneider, N., Stiefl, N., Segler, M., and Bro...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1186/s13321-024-00812-5 2021
-
[7]
URL https: //doi.org/10.1021/acs.jcim.5b00559
doi: 10.1021/acs.jcim.5b00559. URL https: //doi.org/10.1021/acs.jcim.5b00559. Tripp, A. and Hern´andez-Lobato, J. M. Genetic algorithms are strong baselines for molecule generation.arXiv preprint arXiv:2310.09267, 2023. Vignac, C., Krawczuk, I., Siraudin, A., Wang, B., Cevher, V ., and Frossard, P. Digress: Discrete denoising diffusion for graph generatio...
-
[8]
cc/paper_files/paper/2018/file/ d60678e8f2ba9c540798ebbde31177e8-Paper
URL https://proceedings.neurips. cc/paper_files/paper/2018/file/ d60678e8f2ba9c540798ebbde31177e8-Paper. pdf. Zhou, Z., Kearnes, S., Li, L., Zare, R. N., and Riley, P. Op- timization of molecules via deep reinforcement learning. Scientific Reports, 9(1):10752, Jul 2019. ISSN 2045-
work page 2018
-
[9]
doi: 10.1038/s41598-019-47148-x. URL https: //doi.org/10.1038/s41598-019-47148-x. 12 Amortized Molecular Optimization via Group Relative Policy Optimization A. Taxonomy of Generative Optimization We structure our analysis of the generative molecular design landscape through the lens of two distinct optimization paradigms: instance optimization, which trea...
-
[10]
with a non-autoregressive, bidirectional parallel decoding scheme. However, to perform goal-directed tasks like lead optimization, it relies explicitly on an iterative “fragment remasking” loop. As the authors note, this process functions as a mutation operation where specific fragments are masked and regenerated iteratively based on oracle feedback. This...
work page 2017
-
[11]
to update the model, while SAFE-GPT leverages a textual fragment representation (SAFE) to generate molecules token-by-token and uses PPO to update the model. Unlike the vocabulary-mining approaches (discussed below) which focus on extracting specific rationales, these methods focus on learning a flexible policy to assemble a fixed library of fragments. Re...
work page 2020
-
[12]
Action Level 0 (Operation Selection):The agent first decides the nature of the modification. It produces a distribution over three categories of moves: •Termination:The STOPtoken, ending the generation process. • Add Atom:Selecting a new element type T∈Σ (e.g., C, N, O, ...) from the vocabulary to add to the graph. For all our experiments, the vocabulary ...
-
[13]
Action Level 2 (Bond Specification):Finally, the agent determines the bond order b∈ {1,2,3,4,5,6} for the edge connecting the two atoms identified in the previous steps. To ensure chemical validity, we employ a validity maskM(st). At each action level, probabilities of actions that would violate valence constraints (e.g., exceeding the maximum bond capaci...
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.