Toward Robust GraphRAG: Mitigating Retrieval Drift and Hallucination from Imperfect Knowledge Graphs
Pith reviewed 2026-05-21 11:41 UTC · model grok-4.3
The pith
CS-RAG mitigates retrieval drift and hallucination in GraphRAG by planning atomic constraints and recovering from text when graphs fall short.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
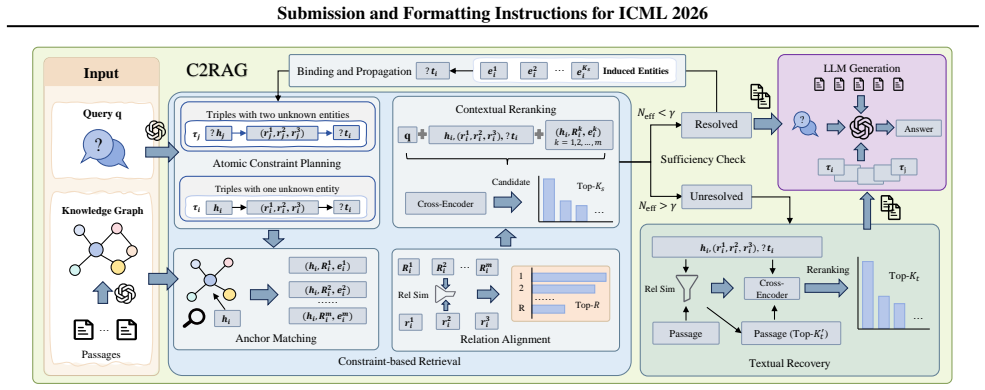
CS-RAG mitigates the impact of imperfect KGs during retrieval rather than relying on KG repair by planning each query as an ordered sequence of executable atomic constraints, performing fine-grained anchor- and relation-aware retrieval, applying a sufficiency check to decide whether the retrieved evidence can safely induce variable bindings for subsequent propagation, and activating textual recovery when structural support is insufficient, thereby reducing hallucinated structural continuation from spurious noise and incomplete information.
What carries the argument
CS-RAG pipeline that plans queries as ordered atomic constraints and uses a sufficiency check to trigger textual recovery instead of forcing graph continuation.
If this is right
- CS-RAG is less sensitive to the choice of knowledge graph builder.
- It remains stable when spurious noise or incomplete links are injected into the graph.
- It reduces drift toward plausible but unsupported triples.
- It avoids forcing continuation through under-supported graph structure via text fallback.
Where Pith is reading between the lines
- The same constraint-planning and sufficiency-check pattern could be tested in non-graph retrieval settings that face noisy indexes.
- Developers might add the sufficiency check as a lightweight module to existing GraphRAG pipelines without rebuilding their graphs.
- The method implies that query decomposition into executable steps is more effective than post-hoc graph cleaning for robustness.
Load-bearing premise
The sufficiency check can reliably determine whether retrieved evidence is adequate to induce variable bindings for subsequent propagation without introducing hallucinated structural continuation.
What would settle it
Removing or randomizing the sufficiency check in CS-RAG and then measuring whether robustness to injected spurious noise and missing links on multi-hop QA benchmarks collapses to baseline levels.
Figures




read the original abstract
Graph Retrieval-Augmented Generation (GraphRAG) has become a common approach for multi-hop reasoning by using knowledge graphs (KGs) as structured retrieval indexes. However, most existing GraphRAG methods implicitly assume that LLM-constructed KGs provide structural support for evidence chaining. In this paper, we show that this assumption does not always hold in practice through an empirical analysis, and identify two recurring KG issue modes often overlooked by current retrievers: spurious noise and incomplete information. Spurious noise induces retrieval drift toward plausible but unsupported triples, whereas incomplete information leads to retrieval hallucination by forcing continuation through under-supported graph structure. To address these challenges, we propose CS-RAG, a robust GraphRAG framework that mitigates the impact of imperfect KGs during retrieval rather than relying on KG repair. CS-RAG first plans each query as an ordered sequence of executable atomic constraints and performs fine-grained anchor- and relation-aware retrieval to constrain evidence acquisition around the intended hop semantics. It then applies a sufficiency check to decide whether the retrieved evidence can safely induce variable bindings for subsequent propagation and activates textual recovery when structural support is insufficient, thereby reducing hallucinated structural continuation. Experiments on three multi-hop QA benchmarks show that CS-RAG is less sensitive to builder choice and remains stable under controlled KG issue injection. Code is available at: https://github.com/myz12138/CS-RAG/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper empirically identifies two issue modes in LLM-constructed KGs for GraphRAG—spurious noise causing retrieval drift and incomplete information causing hallucinated structural continuation—and proposes CS-RAG to mitigate them at retrieval time. CS-RAG decomposes queries into ordered atomic constraints, performs anchor- and relation-aware fine-grained retrieval, applies an LLM-based sufficiency check to decide on variable binding and propagation, and falls back to textual recovery when structural support is insufficient. Experiments on three multi-hop QA benchmarks are reported to show reduced sensitivity to KG builder choice and stability under controlled issue injection.
Significance. If the sufficiency check reliably distinguishes insufficient support without introducing its own errors, the framework offers a practical alternative to KG repair by constraining retrieval semantics and enabling graceful degradation to text. The explicit separation of spurious-noise versus incomplete-information failure modes and the stability claims under injection would strengthen the case for retrieval-focused robustness in GraphRAG, provided the supporting measurements are detailed and reproducible.
major comments (2)
- [CS-RAG pipeline description] Description of the CS-RAG pipeline (after fine-grained retrieval): the sufficiency check is presented as an LLM judgment on retrieved evidence to decide whether structural support suffices for variable bindings and to trigger textual recovery. No ablation, error analysis, or ground-truth comparison is described that isolates the check’s precision on spurious-noise versus incomplete-information cases; because the check itself operates on imperfect evidence, any systematic misclassification directly affects the central claim of reduced hallucinated structural continuation.
- [Experiments] Experiments section: stability under controlled KG issue injection and reduced sensitivity to builder choice are asserted, yet the manuscript provides neither quantitative performance deltas, implementation details of the sufficiency check, nor ablation data that would allow assessment of whether the observed gains are attributable to the check versus the atomic-constraint planning or fine-grained retrieval steps.
minor comments (1)
- The abstract states that code is available at the cited GitHub repository; the manuscript should include a short reproducibility note describing the repository contents, required dependencies, and how the three benchmarks and injection experiments can be reproduced.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, clarifying our current presentation and outlining planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [CS-RAG pipeline description] Description of the CS-RAG pipeline (after fine-grained retrieval): the sufficiency check is presented as an LLM judgment on retrieved evidence to decide whether structural support suffices for variable bindings and to trigger textual recovery. No ablation, error analysis, or ground-truth comparison is described that isolates the check’s precision on spurious-noise versus incomplete-information cases; because the check itself operates on imperfect evidence, any systematic misclassification directly affects the central claim of reduced hallucinated structural continuation.
Authors: We agree that the manuscript would benefit from a more explicit evaluation of the sufficiency check. While the current version describes the check as an LLM-based judgment on retrieved evidence and reports overall end-to-end gains, it does not isolate the check’s classification accuracy separately for spurious-noise and incomplete-information cases. In the revision we will add a dedicated error-analysis subsection that annotates a sample of retrieval outputs with ground-truth sufficiency labels and reports precision/recall broken down by issue mode. This will allow readers to assess whether misclassifications undermine the central claim. revision: yes
-
Referee: [Experiments] Experiments section: stability under controlled KG issue injection and reduced sensitivity to builder choice are asserted, yet the manuscript provides neither quantitative performance deltas, implementation details of the sufficiency check, nor ablation data that would allow assessment of whether the observed gains are attributable to the check versus the atomic-constraint planning or fine-grained retrieval steps.
Authors: We acknowledge the absence of quantitative deltas and component ablations in the submitted version. The reported experiments demonstrate reduced sensitivity to KG builder choice and stability under issue injection, but do not yet decompose the contribution of the sufficiency check from the atomic-constraint planning and fine-grained retrieval stages. In the revised manuscript we will (1) provide the exact prompt template and temperature settings used for the sufficiency check, (2) include ablation tables that remove the check while keeping the other components fixed, and (3) report per-issue-mode performance deltas (with and without injection) relative to the baselines. These additions will make the attribution of gains transparent. revision: yes
Circularity Check
No circularity: CS-RAG is an independent engineering framework
full rationale
The paper proposes CS-RAG as a retrieval pipeline that plans queries into atomic constraints, performs anchor- and relation-aware retrieval, applies a sufficiency check, and falls back to textual recovery. No equations, derivations, or predictions are defined; the sufficiency check is presented as a procedural step rather than a fitted or self-referential quantity. Experiments rely on external benchmarks and controlled KG injections, keeping all load-bearing claims independent of internal fits or self-citation chains.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM-constructed knowledge graphs frequently contain spurious noise and incomplete information that affect retrieval behavior.
Reference graph
Works this paper leans on
-
[1]
Domain-specific knowledge graphs: A survey
Abu-Salih, B. Domain-specific knowledge graphs: A survey. CoRR, abs/2011.00235,
-
[2]
Chen, B., Guo, Z., Yang, Z., Chen, Y ., Chen, J., Liu, Z., Shi, C., and Yang, C. Pathrag: Pruning graph-based re- trieval augmented generation with relational paths.CoRR, abs/2502.14902,
-
[3]
Dong, J., An, S., Yu, Y ., Zhang, Q., Luo, L., Huang, X., Wu, Y ., Yin, D., and Sun, X. Youtu-graphrag: Vertically unified agents for graph retrieval-augmented complex reasoning.CoRR, abs/2508.19855,
-
[4]
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
Edge, D., Trinh, H., Cheng, N., Bradley, J., Chao, A., Mody, A., Truitt, S., and Larson, J. From local to global: A graph RAG approach to query-focused summarization. CoRR, abs/2404.16130,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
LightRAG: Simple and Fast Retrieval-Augmented Generation
Guo, Z., Xia, L., Yu, Y ., Ao, T., and Huang, C. Lightrag: Simple and fast retrieval-augmented generation.CoRR, abs/2410.05779,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Hurst, A., Lerer, A., Goucher, A. P., Perelman, A., Ramesh, A., and Clark., A. Gpt-4o system card.CoRR, abs/2410.21276,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Kang, X., Qu, L., Soon, L., Li, Z., and Trakic, A. Bridg- ing law and data: Augmenting reasoning via a semi- structured dataset with IRAC methodology.CoRR, abs/2406.13217,
-
[8]
Li, J., Wang, R., Huang, Y ., Chen, Q., Zhang, J., and Liang, S. Neuropath: Neurobiology-inspired path tracking and reflection for semantically coherent retrieval.CoRR, abs/2511.14096, 2025a. Li, J., Wang, R., Ma, Y ., Liang, S., Luo, G., and Qin, K. DSAS: A universal plug-and-play framework for atten- tion optimization in multi-document question answerin...
-
[9]
Beyond random: Automatic inner-loop optimization in dataset distillation
Li, M., Gou, H., Zhang, D., Liang, S., Xie, X., Ouyang, D., and Qin, K. Beyond random: Automatic inner-loop optimization in dataset distillation. InNeurIPS, 2025c. Li, M., Miao, S., and Li, P. Simple is effective: The roles of graphs and large language models in knowledge-graph- based retrieval-augmented generation. InICLR, 2025d. Li, M., Zhang, D., Dong,...
-
[10]
Luo, L., Zhao, Z., Haffari, G., Phung, D. Q., Gong, C., and Pan, S. GFM-RAG: graph foundation model for retrieval augmented generation.CoRR, abs/2502.01113,
-
[11]
Ma, S., Xu, C., Jiang, X., Li, M., Qu, H., Yang, C., Mao, J., and Guo, J. Think-on-graph 2.0: Deep and faithful large language model reasoning with knowledge-guided retrieval augmented generation. InICLR, 2025a. Ma, Y ., Qin, K., and Liang, S. Beta-lr: Interpretable logi- cal reasoning based on beta distribution. InFindings of NAACL, pp. 1945–1955,
work page 1945
-
[12]
MultiHop-RAG: Benchmarking Retrieval-Augmented Generation for Multi-Hop Queries
Tang, Y . and Yang, Y . Multihop-rag: Benchmarking retrieval-augmented generation for multi-hop queries. CoRR, abs/2401.15391,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Wang, R., Chen, Q., Huang, Y ., Ma, Y ., Li, M., Li, J., Qin, K., Luo, G., and Liang, S. Graphcogent: Overcom- ing llms’ working memory constraints via multi-agent collaboration in complex graph understanding.CoRR, abs/2508.12379, 2025a. Wang, R., Liang, S., Chen, Q., Zhang, J., and Qin, K. Graphtool-instruction: Revolutionizing graph reasoning in llms th...
-
[14]
Zhang, Q., Chen, S., Bei, Y ., Yuan, Z., Zhou, H., Hong, Z., Dong, J., Chen, H., Chang, Y ., and Huang, X. A survey of graph retrieval-augmented generation for customized large language models.CoRR, abs/2501.13958,
-
[15]
Zhu, Z., Huang, T., Wang, K., Ye, J., Chen, X., and Luo, S. Graph-based approaches and functionalities in retrieval- augmented generation: A comprehensive survey.CoRR, abs/2504.10499,
-
[16]
Justification ofN eff This appendix provides theoretical support for the sufficiency check
10 Submission and Formatting Instructions for ICML 2026 A. Justification ofN eff This appendix provides theoretical support for the sufficiency check. Here {pi,c}c∈Ctop i is the normalized candidate distribution computed from cross-encoder scores (Eq. 7), andC top i is the refined structural candidate pool for constraintτ i. A.1. Properties ofN eff Letpbe...
work page 2026
-
[17]
Proposition A.3 explains why Neff is a suitable score for sufficiency check in C2RAG. WhenNeff is large, the candidate distribution lacks a dominant option and any structural binding is inherently ambiguous. Applying the thresholdNeff(τi)≤γ therefore suppresses hallucinated bindings by allowing structural propagation only when the distribution admits a cl...
work page 2026
-
[18]
may further reduce deployment overhead under the same retrieval logic. Specifically, the number of generated relation variants is fixed to m∈ {1,2,3,4,5} ; anchor entities are chosen with top- E where E∈ {1,2,3,4,5} ; relation-similarity filtering keeps top-R candidates with R ∈ {6,8,10} ; the structural candidate pool after contextual reranking uses top-...
work page 2026
-
[19]
Finally, the QA model is prompted with the query and the constraint-aligned evidence for both hops to generate the answer. 14 Submission and Formatting Instructions for ICML 2026 Query.What year did the prison whereNo Cross, No Crownwas written stop being used as a prison? Block 0: Query decomposition (unknowns carried across hops). τ0: No Cross, No Crown...
work page 2026
-
[20]
The castle was used as a prison . . . until 1952
Retrieved sentences: (1) “The castle was used as a prison . . . until 1952.” (2) “A grand palace early in its history, it served as a royal residence . . . ” (3) “The White Tower was built in 1078 . . . ” Decision:Resolved. Bind ?year =
work page 1952
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.