CycleRL: Sim-to-Real Deep Reinforcement Learning for Robust Autonomous Bicycle Control
Pith reviewed 2026-05-15 10:41 UTC · model grok-4.3
The pith
CycleRL trains a PPO policy in simulation that transfers directly to physical bicycle hardware for balance and tracking.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
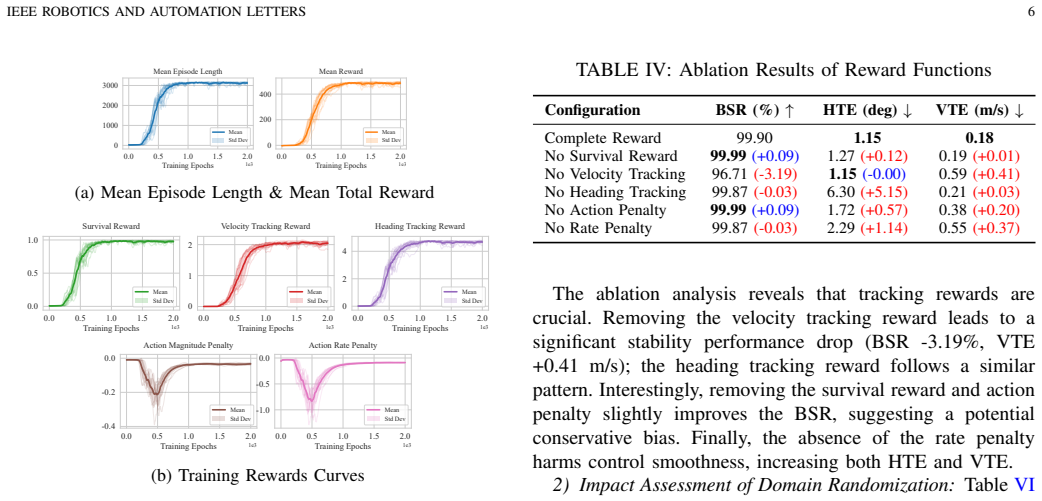
CycleRL establishes a direct perception-to-action policy for autonomous bicycle control by training with PPO in NVIDIA Isaac Sim. Systematic domain randomization reduces dependence on precise dynamics models and enables transfer to hardware. In simulation the policy reaches 99.90 percent balance success, 1.15 degree heading error, and 0.18 m/s velocity error; the same policy succeeds on physical hardware and demonstrates greater adaptability than conventional methods.
What carries the argument
PPO policy with composite reward and systematic domain randomization that learns perception-to-action mapping while covering real-world parameter variations.
If this is right
- The learned policy can be deployed on hardware with no additional fine-tuning.
- DRL provides better robustness to model mismatch than traditional controllers for underactuated nonlinear systems.
- Autonomous bicycles become feasible for urban mobility and logistics applications.
- The framework validates end-to-end learning for concurrent balance, velocity, and steering objectives.
Where Pith is reading between the lines
- The same randomization-plus-PPO recipe may apply to other underactuated platforms such as motorcycles or single-wheel robots.
- Adding perception for obstacle avoidance could turn the current balance controller into a full navigation system.
- Performance limits would appear in regimes the randomization never sampled, such as very low speeds or steep slopes.
Load-bearing premise
Systematic domain randomization over a limited set of simulation parameters is sufficient to cover all real-world uncertainties and enable zero-shot transfer to physical hardware without further adaptation.
What would settle it
A physical bicycle deployment fails to maintain balance or track headings when exposed to wind, friction, or mass variations outside the randomized ranges used in simulation.
Figures




read the original abstract
Autonomous bicycles offer a promising agile solution for urban mobility and last-mile logistics. However, conventional control strategies often struggle with underactuated nonlinear dynamics, suffering from sensitivity to model mismatches and limited adaptability to real-world uncertainties. To address this, we develop CycleRL, a comprehensive sim-to-real framework for robust autonomous bicycle control. Our approach establishes a direct perception-to-action mapping within the high-fidelity NVIDIA Isaac Sim environment, leveraging Proximal Policy Optimization (PPO) to optimize the control policy. The framework features a composite reward function tailored for concurrent balance maintenance, velocity tracking, and steering control. Crucially, systematic domain randomization is employed to reduce the reliance on precise system modeling, bridge the simulation-to-reality gap and facilitate direct transfer. In simulation, CycleRL achieves promising performance, including a 99.90% balance success rate, a heading tracking error of 1.15{\deg}, and a velocity tracking error of 0.18 m/s. These quantitative results, coupled with successful hardware deployment, validate DRL as an effective paradigm for autonomous bicycle control, offering superior adaptability over traditional methods. Video demonstrations are available at https://cpnt-lab.github.io/CycleRL/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CycleRL, a sim-to-real deep reinforcement learning framework for autonomous bicycle control. It employs Proximal Policy Optimization (PPO) within the NVIDIA Isaac Sim environment to learn a direct perception-to-action policy, using a composite reward function for simultaneous balance maintenance, velocity tracking, and steering control. Systematic domain randomization is applied to mitigate model mismatches and enable zero-shot transfer to physical hardware. Simulation results report a 99.90% balance success rate, 1.15° heading tracking error, and 0.18 m/s velocity tracking error, with the work claiming successful hardware deployment that demonstrates superior adaptability compared to traditional control methods.
Significance. If the domain randomization and zero-shot transfer claims are substantiated with detailed parameter ranges and hardware metrics, the work would provide concrete evidence that DRL can robustly handle the underactuated nonlinear dynamics of bicycles in uncertain real-world conditions. This could advance practical applications in agile robotics and last-mile logistics by offering greater adaptability than model-based controllers. The quantitative simulation metrics and availability of video demonstrations offer a useful benchmark for the field.
major comments (3)
- [Abstract] Abstract: The central claim of successful hardware deployment validating superior DRL adaptability rests on zero-shot transfer via domain randomization, yet the abstract (and by extension the experimental reporting) provides no quantitative hardware metrics such as balance success rate or tracking errors on the physical platform. This omission is load-bearing because it prevents direct evaluation of the sim-to-real performance gap.
- [Experimental Setup] Experimental Setup (domain randomization description): No explicit list of randomized parameters (mass, friction, disturbances, sensor noise) or their numerical ranges is given, nor is there justification or sensitivity analysis for these choices. This directly undermines assessment of whether the randomization sufficiently covers real-world uncertainties, as required by the weakest assumption in the sim-to-real claim.
- [Results] Results section: The simulation performance numbers (99.90% success, 1.15° heading error, 0.18 m/s velocity error) are presented without baselines, ablations on reward weights, or statistical details on training variability. This is load-bearing for the superiority claim over traditional methods, as the reported metrics cannot be contextualized without these comparisons.
minor comments (2)
- [Abstract] Abstract: The notation '1.15{°}' uses an escaped degree symbol; ensure consistent rendering of units (e.g., ° or deg) across all sections and figures.
- Consider adding a dedicated table or subsection that directly compares simulation versus hardware quantitative results to strengthen the transfer validation.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment point by point below and describe the revisions we will make to strengthen the presentation of the sim-to-real results.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of successful hardware deployment validating superior DRL adaptability rests on zero-shot transfer via domain randomization, yet the abstract (and by extension the experimental reporting) provides no quantitative hardware metrics such as balance success rate or tracking errors on the physical platform. This omission is load-bearing because it prevents direct evaluation of the sim-to-real performance gap.
Authors: We agree that quantitative hardware metrics would allow readers to directly assess the sim-to-real gap. The current abstract and results emphasize simulation performance while noting successful hardware deployment (supported by the linked video demonstrations). In the revised manuscript we will update the abstract and add a dedicated hardware results subsection that reports the corresponding balance success rate, heading error, and velocity error measured on the physical platform. revision: yes
-
Referee: [Experimental Setup] Experimental Setup (domain randomization description): No explicit list of randomized parameters (mass, friction, disturbances, sensor noise) or their numerical ranges is given, nor is there justification or sensitivity analysis for these choices. This directly undermines assessment of whether the randomization sufficiently covers real-world uncertainties, as required by the weakest assumption in the sim-to-real claim.
Authors: We acknowledge that the manuscript describes domain randomization at a high level without the requested parameter details. To address this, the revised version will include a table enumerating all randomized parameters (mass, friction coefficients, sensor noise, external disturbances, etc.) together with their numerical ranges. We will also add a short justification based on our hardware characterization and a sensitivity analysis showing policy robustness across the chosen ranges. revision: yes
-
Referee: [Results] Results section: The simulation performance numbers (99.90% success, 1.15° heading error, 0.18 m/s velocity error) are presented without baselines, ablations on reward weights, or statistical details on training variability. This is load-bearing for the superiority claim over traditional methods, as the reported metrics cannot be contextualized without these comparisons.
Authors: We agree that additional context is needed to substantiate the superiority claim. In the revised results section we will add (i) baseline comparisons against tuned PID and LQR controllers on the same simulation tasks, (ii) ablations that vary the relative weights of the balance, velocity, and steering reward terms, and (iii) statistical summaries (mean and standard deviation) of the reported metrics across multiple independent training seeds. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper trains a PPO policy in NVIDIA Isaac Sim using a composite reward for balance, velocity, and steering, then applies systematic domain randomization for sim-to-real transfer. Reported metrics (99.90% balance success, 1.15° heading error, 0.18 m/s velocity error) and hardware deployment are direct empirical outputs of the optimization and physical validation, not quantities defined by or reduced to the same fitted parameters. No equations, self-definitional steps, fitted-input predictions, or load-bearing self-citations appear in the abstract or description. The chain is self-contained against external simulator and hardware benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- composite reward weights
- domain randomization ranges
axioms (1)
- domain assumption NVIDIA Isaac Sim supplies sufficiently accurate rigid-body and contact dynamics for the bicycle once parameters are randomized.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
composite reward function ... Rt = λsurv·rsurv + λvel·rvel + λhead·rhead + λact·ract + λrate·rrate; Proximal Policy Optimization (PPO) ... domain randomization strategy
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
systematic domain randomization ... Dynamics Randomization (Physical Parameters) ... Initial State Randomization ... Task / Command Randomization
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.