PhySe-RPO: Physics and Semantics Guided Relative Policy Optimization for Diffusion-Based Surgical Smoke Removal
Pith reviewed 2026-05-15 01:19 UTC · model grok-4.3
The pith
PhySe-RPO converts diffusion-based surgical smoke removal into a stochastic policy guided by physics and semantic rewards for consistent restoration under limited data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PhySe-RPO transforms deterministic restoration into a stochastic policy, enabling trajectory-level exploration and critic-free updates via group-relative optimization. A physics-guided reward imposes illumination and color consistency, while a visual-concept semantic reward learned from CLIP-based surgical concepts promotes smoke-free and anatomically coherent restoration.
What carries the argument
Relative Policy Optimization (RPO) that turns the diffusion denoising process into a stochastic policy updated by group-relative rewards combining physics-based illumination consistency and CLIP-derived semantic coherence.
If this is right
- Diffusion restoration pipelines gain the ability to explore multiple denoising trajectories instead of committing to a single deterministic path.
- Illumination and color fidelity become explicit optimization targets rather than post-hoc checks.
- Anatomical coherence can be promoted through semantic concepts without paired clean-smoke image pairs.
- The approach supplies a route to robust performance on real robotic surgery data where paired supervision remains scarce.
Where Pith is reading between the lines
- The same reward structure could be adapted to other medical image restoration problems such as haze removal or low-light enhancement where physical consistency matters.
- Uncertainty estimates derived from policy variance might flag regions where restoration is least reliable for surgeon review.
- Replacing the CLIP semantic component with domain-specific visual encoders could further tighten anatomical fidelity in specialized procedures.
Load-bearing premise
The combination of physics and CLIP semantic rewards will consistently produce anatomically coherent outputs without introducing artifacts or losing critical details under real surgical lighting and tissue conditions.
What would settle it
Restored real surgical videos that show new color shifts, lost vessel detail, or persistent smoke artifacts after PhySe-RPO application would contradict the claim of reliable physical and semantic consistency.
Figures






read the original abstract
Surgical smoke severely degrades intraoperative video quality, obscuring anatomical structures and limiting surgical perception. Existing learning-based desmoking approaches rely on scarce paired supervision and deterministic restoration pipelines, making it difficult to perform exploration or reinforcement-driven refinement under real surgical conditions. We propose PhySe-RPO, a diffusion restoration framework optimized through Physics- and Semantics-Guided Relative Policy Optimization. The core idea is to transform deterministic restoration into a stochastic policy, enabling trajectory-level exploration and critic-free updates via group-relative optimization. A physics-guided reward imposes illumination and color consistency, while a visual-concept semantic reward learned from CLIP-based surgical concepts promotes smoke-free and anatomically coherent restoration. Together with a reference-free perceptual constraint, PhySe-RPO produces results that are physically consistent, semantically faithful, and clinically interpretable across synthetic and real robotic surgical datasets, providing a principled route to robust diffusion-based restoration under limited paired supervision.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PhySe-RPO, a diffusion-based surgical smoke removal framework that reformulates deterministic restoration as a stochastic policy optimized via group-relative policy optimization. It introduces a physics-guided reward enforcing illumination and color consistency together with a CLIP-derived semantic reward for smoke-free, anatomically coherent outputs, plus a reference-free perceptual constraint, claiming physically consistent and clinically interpretable results on both synthetic and real robotic surgical datasets under limited paired supervision.
Significance. If the empirical claims are substantiated, the work would offer a principled way to incorporate domain-specific physics and semantic priors into diffusion restoration via critic-free RL, addressing the scarcity of paired data in intraoperative video enhancement and potentially improving robustness for real surgical conditions where smoke obscures critical anatomy.
major comments (2)
- [Abstract] Abstract: the central claim that PhySe-RPO 'produces results that are physically consistent, semantically faithful, and clinically interpretable' across datasets is unsupported by any quantitative metrics, ablation studies, tables, or figures in the manuscript text, rendering the effectiveness of the combined reward formulation impossible to evaluate.
- [Method] Method description (rewards section): the physics-guided reward is defined on aggregate illumination histograms and color constancy, which does not model spatially varying smoke scattering or subsurface tissue optics; combined with the coarse CLIP semantic term, this leaves the guarantee of local anatomical fidelity (vessels, tissue boundaries) without an explicit penalty for hallucination or erasure once global consistency is met.
minor comments (1)
- Notation for the group-relative optimization and the precise weighting between physics, semantic, and perceptual rewards should be formalized with equations and hyper-parameter values for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important aspects of clarity and rigor in presenting our claims and method. We address each major comment point-by-point below, indicating the revisions we will incorporate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that PhySe-RPO 'produces results that are physically consistent, semantically faithful, and clinically interpretable' across datasets is unsupported by any quantitative metrics, ablation studies, tables, or figures in the manuscript text, rendering the effectiveness of the combined reward formulation impossible to evaluate.
Authors: We agree that the abstract claim requires direct linkage to supporting evidence in the manuscript. In the revised version, we will update the abstract to explicitly reference the quantitative metrics (PSNR, SSIM, LPIPS), ablation studies, and visual results from Sections 4 and 5, including tables and figures on both synthetic and real datasets. This will substantiate the claims of physical consistency, semantic fidelity, and clinical interpretability without altering the core contribution. revision: yes
-
Referee: [Method] Method description (rewards section): the physics-guided reward is defined on aggregate illumination histograms and color constancy, which does not model spatially varying smoke scattering or subsurface tissue optics; combined with the coarse CLIP semantic term, this leaves the guarantee of local anatomical fidelity (vessels, tissue boundaries) without an explicit penalty for hallucination or erasure once global consistency is met.
Authors: We acknowledge the limitation in the reward formulation: the physics-guided component relies on global histogram-based illumination and color constancy for computational efficiency under limited supervision, and the CLIP term provides high-level semantic guidance rather than pixel-level local constraints. This design choice prioritizes robustness in real surgical scenarios where detailed physics models are unavailable. However, the reference-free perceptual constraint and trajectory-level exploration in the group-relative optimization empirically reduce local artifacts, as validated in our real robotic dataset experiments. We will add a new paragraph in the Discussion section explicitly discussing this limitation, including why spatially varying scattering is not modeled, and outline potential future extensions such as incorporating local physics priors. Additional qualitative close-ups of vessel and tissue boundaries will be included to demonstrate local fidelity. revision: partial
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper defines a new stochastic policy optimization framework (PhySe-RPO) by introducing physics-guided illumination/color rewards and CLIP-derived semantic rewards as independent components applied to diffusion trajectories. These rewards are constructed from external principles and models rather than fitted parameters or self-referential equations. No load-bearing steps reduce predictions to inputs by construction, no self-citation chains justify uniqueness, and no ansatzes or renamings of known results are smuggled in. The central claims rest on the joint sufficiency of the newly specified rewards under limited supervision, which is an independent modeling choice rather than a definitional tautology.
Axiom & Free-Parameter Ledger
axioms (3)
- domain assumption Diffusion models can be reframed as stochastic policies for image restoration
- domain assumption CLIP embeddings reliably capture surgical visual concepts for reward computation
- ad hoc to paper Illumination and color consistency constraints are sufficient physics guidance for smoke removal
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
A physics-guided reward imposes illumination and color consistency, while a visual-concept semantic reward learned from CLIP-based surgical concepts promotes smoke-free and anatomically coherent restoration.
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Inter-channel Prior... Intra-channel Prior... RP G = R A + R B
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
The perception-distortion tradeoff
Yochai Blau and Tomer Michaeli. The perception-distortion tradeoff. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 6228–6237, 2018. 6
work page 2018
-
[2]
Lsd3k: A benchmark for smoke removal from laparoscopic surgery images
Wenhui Chang, Yufeng Li, Zebang Zhu, and Yuchen Yang. Lsd3k: A benchmark for smoke removal from laparoscopic surgery images. In2024 3rd International Conference on Ar- tificial Intelligence, Internet of Things and Cloud Computing Technology (AIoTC), pages 1–5. IEEE, 2024. 1, 2
work page 2024
-
[3]
Long Chen, Wen Tang, Nigel W John, Tao Ruan Wan, and Jian Jun Zhang. De-smokegcn: generative cooperative net- works for joint surgical smoke detection and removal.IEEE transactions on medical imaging, 39(5):1615–1625, 2019. 2
work page 2019
-
[4]
Renjie Chen, Wenfeng Lin, Yichen Zhang, Jiangchuan Wei, Boyuan Liu, Chao Feng, Jiao Ran, and Mingyu Guo. To- wards self-improvement of diffusion models via group pref- erence optimization.arXiv preprint arXiv:2505.11070,
-
[5]
Lightdiff: surgical endoscopic image low-light enhancement with t-diffusion
Tong Chen, Qingcheng Lyu, Long Bai, Erjian Guo, Huxin Gao, Xiaoxiao Yang, Hongliang Ren, and Luping Zhou. Lightdiff: surgical endoscopic image low-light enhancement with t-diffusion. InInternational Conference on Medical Im- age Computing and Computer-Assisted Intervention, pages 369–379. Springer, 2024. 1, 2, 6, 7
work page 2024
-
[6]
Lark Kwon Choi, Jaehee You, and Alan Conrad Bovik. Ref- erenceless prediction of perceptual fog density and percep- tual image defogging.IEEE Transactions on Image Process- ing, 24(11):3888–3901, 2015. 6
work page 2015
-
[7]
Temporal as a plugin: Unsuper- vised video denoising with pre-trained image denoisers
Zixuan Fu, Lanqing Guo, Chong Wang, Yufei Wang, Zhi- hao Li, and Bihan Wen. Temporal as a plugin: Unsuper- vised video denoising with pre-trained image denoisers. In European Conference on Computer Vision, pages 349–367. Springer, 2024. 1, 2, 6, 7
work page 2024
-
[8]
Image dehazing transformer with transmission-aware 3d position embedding
Chun-Le Guo, Qixin Yan, Saeed Anwar, Runmin Cong, Wenqi Ren, and Chongyi Li. Image dehazing transformer with transmission-aware 3d position embedding. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5812–5820, 2022. 6, 7, 1
work page 2022
-
[9]
Yanjiang Guo, Jianke Zhang, Xiaoyu Chen, Xiang Ji, Yen- Jen Wang, Yucheng Hu, and Jianyu Chen. Improving vision- language-action model with online reinforcement learning. arXiv preprint arXiv:2501.16664, 2025. 2
-
[10]
Kaiming He, Jian Sun, and Xiaoou Tang. Single image haze removal using dark channel prior.IEEE transactions on pat- tern analysis and machine intelligence, 33(12):2341–2353,
-
[11]
Denoising diffu- sion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffu- sion probabilistic models. InNeurIPS, 2020. 2
work page 2020
-
[12]
Cycle-consistent adversarial net- works for smoke detection and removal in endoscopic im- ages
Zhisen Hu and Xiyuan Hu. Cycle-consistent adversarial net- works for smoke detection and removal in endoscopic im- ages. In2021 43rd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), pages 3070–3073. IEEE, 2021. 2
work page 2021
-
[13]
Structure representation network and uncertainty feedback learning for dense non-uniform fog removal
Yeying Jin, Wending Yan, Wenhan Yang, and Robby T Tan. Structure representation network and uncertainty feedback learning for dense non-uniform fog removal. InAsian Con- ference on Computer Vision, pages 155–172. Springer, 2022. 7, 8
work page 2022
-
[14]
Musiq: Multi-scale image quality transformer
Junjie Ke, Qifei Wang, Yilin Wang, Peyman Milanfar, and Feng Yang. Musiq: Multi-scale image quality transformer. InProceedings of the IEEE/CVF international conference on computer vision, pages 5148–5157, 2021. 6
work page 2021
-
[15]
Kang Liao, Zongsheng Yue, Zhouxia Wang, and Chen Change Loy. Denoising as adaptation: Noise- space domain adaptation for image restoration.arXiv preprint arXiv:2406.18516, 2024. 1, 2, 6, 7
-
[16]
Wang Lin, Liyu Jia, Wentao Hu, Kaihang Pan, Zhongqi Yue, Wei Zhao, Jingyuan Chen, Fei Wu, and Hanwang Zhang. Reasoning physical video generation with diffusion timestep tokens via reinforcement learning.arXiv preprint arXiv:2504.15932, 2025. 2
-
[17]
Lixiong Liu, Bao Liu, Hua Huang, and Alan Conrad Bovik. No-reference image quality assessment based on spatial and spectral entropies.Signal processing: Image communica- tion, 29(8):856–863, 2014. 6
work page 2014
-
[18]
Mixdehazenet: Mix structure block for image dehazing net- work
LiPing Lu, Qian Xiong, Bingrong Xu, and Duanfeng Chu. Mixdehazenet: Mix structure block for image dehazing net- work. In2024 International Joint Conference on Neural Net- works (IJCNN), pages 1–10. IEEE, 2024. 1, 2
work page 2024
-
[19]
Vision-based surgical field defogging.IEEE transactions on medical imaging, 36(10):2021–2030, 2017
Xiongbiao Luo, A Jonathan McLeod, Stephen E Pautler, Christopher M Schlachta, and Terry M Peters. Vision-based surgical field defogging.IEEE transactions on medical imaging, 36(10):2021–2030, 2017. 8
work page 2021
-
[20]
arXiv preprint arXiv:2310.01018 , volume=
Ziwei Luo, Fredrik K Gustafsson, Zheng Zhao, Jens Sj¨olund, and Thomas B Sch¨on. Controlling vision-language models for multi-task image restoration.arXiv preprint arXiv:2310.01018, 2023. 1, 2, 6
-
[21]
Segment anything in medical images.Nature communications, 15(1):654, 2024
Jun Ma, Yuting He, Feifei Li, Lin Han, Chenyu You, and Bo Wang. Segment anything in medical images.Nature communications, 15(1):654, 2024. 8
work page 2024
-
[22]
Anish Mittal, Rajiv Soundararajan, and Alan C Bovik. Mak- ing a “completely blind” image quality analyzer.IEEE Sig- nal processing letters, 20(3):209–212, 2012. 6
work page 2012
-
[23]
Jiadong Pan, Zhiyuan Ma, Kaiyan Zhang, Ning Ding, and Bowen Zhou. Self-reflective reinforcement learning for diffusion-based image reasoning generation.arXiv preprint arXiv:2505.22407, 2025. 2
-
[24]
Yirou Pan, Sophia Bano, Francisco Vasconcelos, Hyun Park, Taikyeong Ted Jeong, and Danail Stoyanov. Desmoke-lap: improved unpaired image-to-image translation for desmok- ing in laparoscopic surgery.International Journal of Com- puter Assisted Radiology and Surgery, 17(5):885–893, 2022. 2, 6, 7, 8, 1
work page 2022
-
[25]
Sebasti ´an Salazar-Colores, Hugo Moreno Jim ´enez, C´esar Javier Ortiz-Echeverri, and Gerardo Flores. Desmok- ing laparoscopy surgery images using an image-to-image translation guided by an embedded dark channel.IEEE Access, 8:208898–208909, 2020. 2, 8
work page 2020
-
[26]
Improved techniques for training gans.Advances in neural information processing systems, 29, 2016
Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved techniques for training gans.Advances in neural information processing systems, 29, 2016. 6
work page 2016
-
[27]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models, 2024.URL https://arxiv. org/abs/2402.03300, 2(3):5, 2024. 1, 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Mingyu Sheng, Jianan Fan, Dongnan Liu, Ron Kikinis, and Weidong Cai. Amncutter: Affinity-attention-guided multi- view normalized cutter for unsupervised surgical instrument segmentation. In2025 IEEE/CVF Winter Conference on Ap- plications of Computer Vision (WACV), pages 4533–4544. IEEE, 2025. 8
work page 2025
-
[29]
Oleksii Sidorov, Congcong Wang, and Faouzi Alaya Cheikh. Generative smoke removal. InMachine Learning for Health Workshop, pages 81–92. PMLR, 2020. 8
work page 2020
-
[30]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Ab- hishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equa- tions.arXiv preprint arXiv:2011.13456, 2020. 2
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[31]
Yuda Song, Zhuqing He, Hui Qian, and Xin Du. Vision transformers for single image dehazing.IEEE Transactions on Image Processing, 32:1927–1941, 2023. 7, 8
work page 1927
-
[32]
Xinpei Su and Qiuxia Wu. Multi-stages de-smoking model based on cyclegan for surgical de-smoking.International Journal of Machine Learning and Cybernetics, 14(11): 3965–3978, 2023. 8
work page 2023
-
[33]
Vishal Venkatesh, Neeraj Sharma, Vivek Srivastava, and Munendra Singh. Unsupervised smoke to desmoked la- paroscopic surgery images using contrast driven cyclic- desmokegan.Computers in Biology and Medicine, 123: 103873, 2020. 2
work page 2020
-
[34]
Congcong Wang, Faouzi Alaya Cheikh, Mounir Kaaniche, Azeddine Beghdadi, and Ole Jacob Elle. Variational based smoke removal in laparoscopic images.Biomedical engi- neering online, 17(1):139, 2018. 8
work page 2018
-
[35]
Feng Wang, Xinan Sun, and Jinhua Li. Surgical smoke re- moval via residual swin transformer network.International Journal of Computer Assisted Radiology and Surgery, 18(8): 1417–1427, 2023. 2
work page 2023
-
[36]
Simplear: Pushing the frontier of autoregressive visual generation through pretraining, sft, and rl
Junke Wang, Zhi Tian, Xun Wang, Xinyu Zhang, Weilin Huang, Zuxuan Wu, and Yu-Gang Jiang. Simplear: Pushing the frontier of autoregressive visual generation through pre- training, sft, and rl.arXiv preprint arXiv:2504.11455, 2025. 2
-
[37]
Self-supervised video desmoking for laparoscopic surgery
Renlong Wu, Zhilu Zhang, Shuohao Zhang, Longfei Gou, Haobin Chen, Lei Zhang, Hao Chen, and Wangmeng Zuo. Self-supervised video desmoking for laparoscopic surgery. InEuropean Conference on Computer Vision, pages 307–
-
[38]
Springer, 2024. 6, 7, 1
work page 2024
-
[39]
A new benchmark in vivo paired dataset for laparoscopic im- age de-smoking, 2024
Wenyao Xia, Victoria Fan, Terry Peters, and Elvis CS Chen. A new benchmark in vivo paired dataset for laparoscopic im- age de-smoking, 2024. 4, 6
work page 2024
-
[40]
Cheng Xue, Shiyu Zhao, Danqiong Wang, Cheng Chen, Guanyu Yang, and Yang Chen. Td-sam: Temporal and distance-guided adaptations of sam for accurate surgical in- strument segmentation.IEEE Journal of Biomedical and Health Informatics, 2025. 8
work page 2025
-
[41]
No-Reference Quality Assessment of Contrast-Distorted Images using Contrast Enhancement
Jia Yan, Jie Li, and Xin Fu. No-reference quality assess- ment of contrast-distorted images using contrast enhance- ment.arXiv preprint arXiv:1904.08879, 2019. 5
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[42]
Maniqa: Multi-dimension attention network for no-reference image quality assessment
Sidi Yang, Tianhe Wu, Shuwei Shi, Shanshan Lao, Yuan Gong, Mingdeng Cao, Jiahao Wang, and Yujiu Yang. Maniqa: Multi-dimension attention network for no-reference image quality assessment. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1191–1200, 2022. 6
work page 2022
-
[43]
Seg-r1: Segmentation can be surprisingly simple with reinforcement 33 ConceptSeg-R1 learning
Zuyao You and Zuxuan Wu. Seg-r1: Segmentation can be surprisingly simple with reinforcement learning.arXiv preprint arXiv:2506.22624, 2025. 2
-
[44]
Progressive frequency-aware network for laparo- scopic image desmoking
Jiale Zhang, Wenfeng Huang, Xiangyun Liao, and Qiong Wang. Progressive frequency-aware network for laparo- scopic image desmoking. InChinese Conference on Pattern Recognition and Computer Vision (PRCV), pages 479–492. Springer, 2023. 6, 7, 1
work page 2023
-
[45]
Blind image quality assessment via vision- language correspondence: A multitask learning perspective
Weixia Zhang, Guangtao Zhai, Ying Wei, Xiaokang Yang, and Kede Ma. Blind image quality assessment via vision- language correspondence: A multitask learning perspective. InProceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 14071–14081, 2023. 5
work page 2023
-
[46]
Lirong Zheng, Yanshan Li, Rui Yu, and Kaihao Zhang. Ef- ficient dual-domain image dehazing with haze prior percep- tion.arXiv preprint arXiv:2507.11035, 2025. 6, 7, 1
-
[47]
Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. Learning to prompt for vision-language models.In- ternational Journal of Computer Vision, 130(9):2337–2348,
-
[48]
Yichao Zhou, Zhisen Hu, Zuxing Xuan, Yangang Wang, and Xiyuan Hu. Synchronizing detection and removal of smoke in endoscopic images with cyclic consistency adver- sarial nets.IEEE/ACM Transactions on Computational Biol- ogy and Bioinformatics, 21(4):670–680, 2022. 2 PhySe-RPO: Physics and Semantics Guided Relative Policy Optimization for Diffusion-Based S...
work page 2022
-
[49]
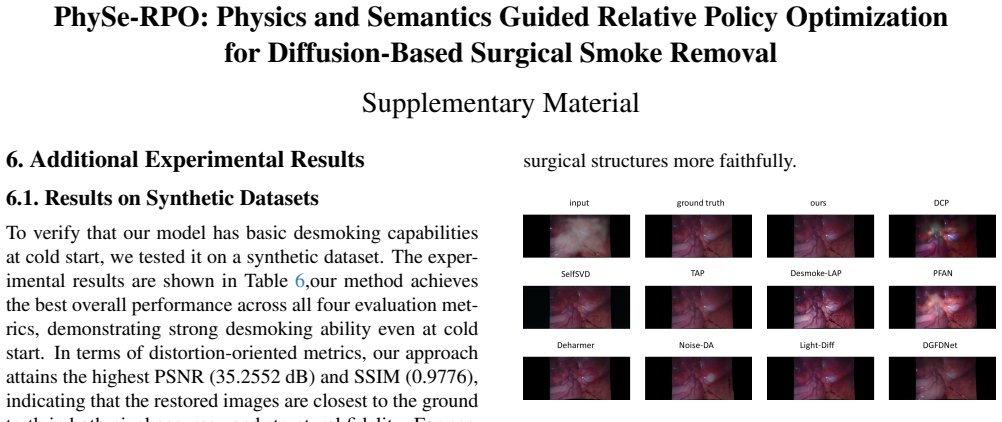
Additional Experimental Results 6.1. Results on Synthetic Datasets To verify that our model has basic desmoking capabilities at cold start, we tested it on a synthetic dataset. The exper- imental results are shown in Table 6,our method achieves the best overall performance across all four evaluation met- rics, demonstrating strong desmoking ability even a...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.