IntentScore: Intent-Conditioned Action Evaluation for Computer-Use Agents
Pith reviewed 2026-05-25 06:54 UTC · model grok-4.3
The pith
A reward model that embeds planning intent into action scoring can improve computer-use agent success by 6.9 points on environments never seen in training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
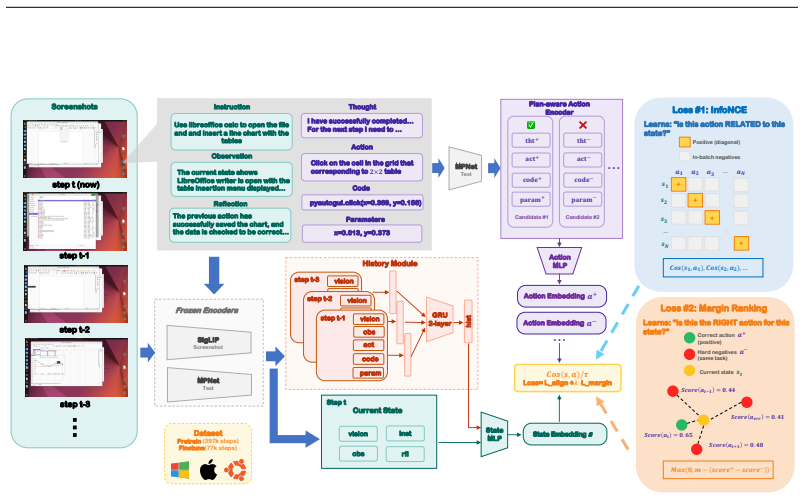
IntentScore is a plan-aware reward model that embeds each candidate action's planning intent in the action encoder. It is trained with contrastive alignment for state-action relevance and margin ranking for action correctness on 398K offline GUI interaction steps spanning three operating systems. The model achieves 97.5% pairwise discrimination accuracy on held-out data and, when deployed as a re-ranker, improves Agent S3 task success rate by 6.9 points on the unseen OSWorld environment.
What carries the argument
The intent-conditioned action encoder that incorporates planning intent to distinguish actions with similar surface forms but different rationales.
If this is right
- Reward estimation learned from heterogeneous offline trajectories generalizes to unseen agents and task distributions.
- Embedding planning intent allows discrimination between candidates with similar actions but different rationales.
- Deploying the model as a re-ranker improves task success rate without retraining the base agent.
- High pairwise discrimination accuracy of 97.5% supports reliable selection of higher-quality actions at each step.
Where Pith is reading between the lines
- The same intent-conditioned scoring could be tested on non-GUI sequential tasks such as web navigation or command-line agents.
- Collecting larger and more diverse offline trajectories might increase the observed generalization gap closure.
- Using the scorer inside the agent's training loop instead of only at inference time could produce additional gains.
Load-bearing premise
A reward model trained on offline trajectories from three operating systems will generalize to entirely unseen agents and task distributions in OSWorld.
What would settle it
Measuring task success rate on OSWorld with and without the IntentScore re-ranker to check whether the reported 6.9-point gain disappears.
Figures






read the original abstract
Computer-Use Agents (CUAs) leverage large language models to execute GUI operations on desktop environments, yet they generate actions without evaluating action quality, leading to irreversible errors that cascade through subsequent steps. We propose IntentScore, a plan-aware reward model that learns to score candidate actions from 398K offline GUI interaction steps spanning three operating systems. IntentScore trains with two complementary objectives: contrastive alignment for state-action relevance and margin ranking for action correctness. Architecturally, it embeds each candidate's planning intent in the action encoder, enabling discrimination between candidates with similar actions but different rationales. IntentScore achieves 97.5% pairwise discrimination accuracy on held-out evaluation. Deployed as a re-ranker for Agent S3 on OSWorld, an environment entirely unseen during training, IntentScore improves task success rate by 6.9 points, demonstrating that reward estimation learned from heterogeneous offline trajectories generalizes to unseen agents and task distributions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes IntentScore, a plan-aware reward model for computer-use agents (CUAs) that embeds planning intent into action scoring. It is trained on 398K offline GUI interaction steps across three operating systems using contrastive alignment for state-action relevance and margin ranking for action correctness. The model reports 97.5% pairwise discrimination accuracy on held-out evaluation and, when deployed as a re-ranker for Agent S3 on the unseen OSWorld benchmark, yields a 6.9-point gain in task success rate.
Significance. If the out-of-distribution generalization claim holds, the work offers a concrete, offline-trainable mechanism to mitigate cascading errors in GUI agents without requiring online interaction or environment-specific fine-tuning. The intent-conditioned architecture and dual-objective training provide a reusable component for CUA pipelines.
major comments (3)
- [Abstract / Experiments] Abstract and Experiments section: The assertion that OSWorld is 'entirely unseen' during training is load-bearing for the 6.9-point gain claim, yet the manuscript supplies no quantitative check (task-category overlap, application-domain similarity, or action-sequence distribution distance) between the 398K training trajectories and OSWorld tasks. Without such evidence, the reported lift cannot be distinguished from possible memorization of similar patterns.
- [Evaluation protocol] Evaluation protocol (presumably §4 or §5): The 97.5% pairwise discrimination accuracy is presented without details on data splits, number of evaluation pairs, sampling procedure, or statistical significance testing. This absence prevents assessment of whether the held-out result is robust or sensitive to unstated choices in pair construction.
- [OSWorld experiments] OSWorld re-ranking results: The 6.9-point improvement is reported without the baseline Agent S3 success rate, number of evaluated tasks, run-to-run variance, or comparison against alternative re-ranking or reward-model baselines, making the magnitude and reliability of the gain difficult to interpret.
minor comments (2)
- [Method] Notation for the two training objectives (contrastive and margin-ranking) should be defined with explicit loss equations rather than prose descriptions to allow exact reproduction.
- [Figures] Figure captions for any architecture or trajectory diagrams should explicitly state the input dimensions and embedding sizes used in the intent-conditioned encoder.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. We address each major comment below and commit to revisions that improve clarity and completeness without altering the core claims.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: The assertion that OSWorld is 'entirely unseen' during training is load-bearing for the 6.9-point gain claim, yet the manuscript supplies no quantitative check (task-category overlap, application-domain similarity, or action-sequence distribution distance) between the 398K training trajectories and OSWorld tasks. Without such evidence, the reported lift cannot be distinguished from possible memorization of similar patterns.
Authors: We agree that a quantitative characterization of distribution shift would make the generalization claim more robust. The 398K trajectories were collected from open-ended GUI interactions across three operating systems using multiple agents, whereas OSWorld consists of curated, goal-directed tasks in a standardized benchmark setting with different application distributions. In the revision we will add a new subsection that tabulates task-category overlap (e.g., browser vs. file-manager actions) and qualitatively contrasts action-sequence statistics; a full distributional-distance computation is not feasible with the current offline dataset but the added analysis will clarify the degree of novelty. revision: partial
-
Referee: [Evaluation protocol] Evaluation protocol (presumably §4 or §5): The 97.5% pairwise discrimination accuracy is presented without details on data splits, number of evaluation pairs, sampling procedure, or statistical significance testing. This absence prevents assessment of whether the held-out result is robust or sensitive to unstated choices in pair construction.
Authors: We apologize for the missing protocol details. The revised manuscript will include an expanded evaluation subsection that specifies the train/validation/test split ratios, the exact number of held-out pairs, the procedure used to sample positive and negative pairs (including how negatives were drawn from the same state), and the results of statistical significance tests (paired t-test and bootstrap confidence intervals) confirming that accuracy is reliably above chance. revision: yes
-
Referee: [OSWorld experiments] OSWorld re-ranking results: The 6.9-point improvement is reported without the baseline Agent S3 success rate, number of evaluated tasks, run-to-run variance, or comparison against alternative re-ranking or reward-model baselines, making the magnitude and reliability of the gain difficult to interpret.
Authors: We will revise both the abstract and the experiments section to explicitly report the baseline Agent S3 success rate, the precise number of OSWorld tasks evaluated, standard deviation across repeated runs, and additional comparisons against simple heuristic re-rankers and an ablated reward model. These numbers and controls are already present in our internal experimental logs and will be added to the main text and a new supplementary table. revision: yes
Circularity Check
No circularity; empirical training and held-out evaluation
full rationale
The paper describes training a reward model (IntentScore) on 398K offline GUI trajectories using standard contrastive alignment and margin-ranking objectives, followed by held-out accuracy measurement (97.5%) and deployment as a re-ranker on the unseen OSWorld benchmark. No equations, derivations, or first-principles claims are presented that reduce to fitted quantities by construction. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing steps. The central results rest on conventional supervised learning with train/test separation and external environment testing, making the derivation chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Offline GUI interaction steps collected from three operating systems are representative enough to train a model that generalizes to unseen agents and tasks.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.