Recognition: 2 theorem links
· Lean TheoremData, Not Model: Explaining Bias toward LLM Texts in Neural Retrievers
Pith reviewed 2026-05-10 18:17 UTC · model grok-4.3
The pith
Neural retrievers prefer LLM-generated texts because of imbalances already present in their training data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
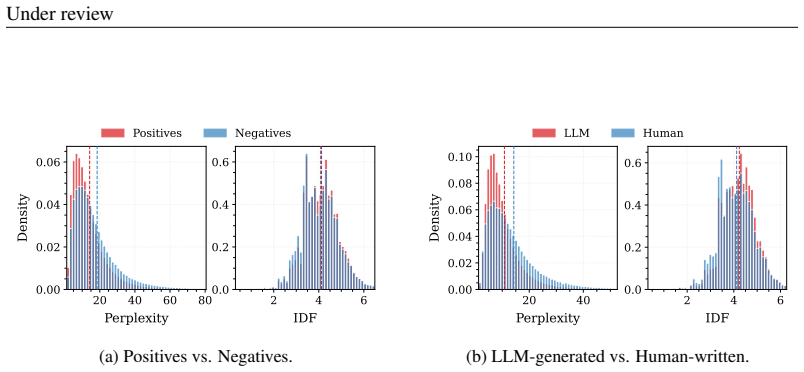
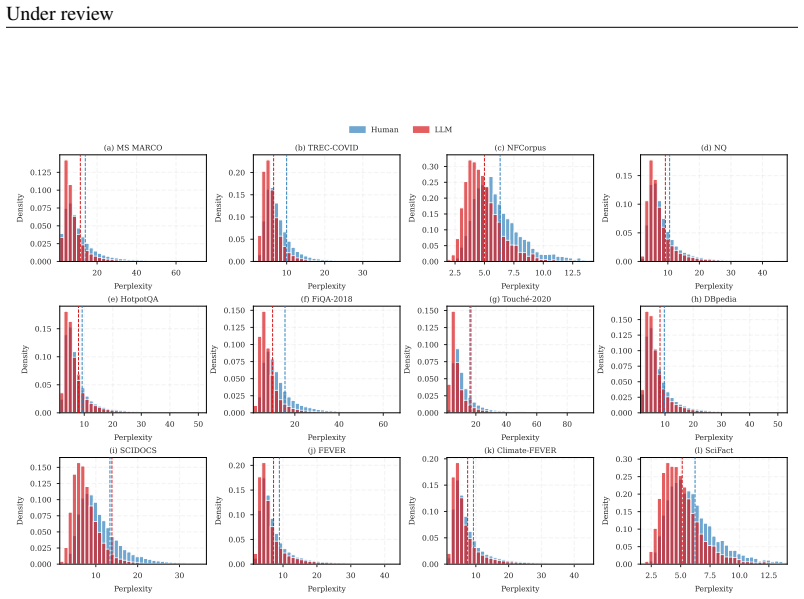
Source bias stems from supervision in retrieval datasets rather than the models themselves. Non-semantic differences like fluency and term specificity exist between positive and negative documents, mirroring differences between LLM and human texts. In the embedding space, the bias direction from negatives to positives aligns with the direction from human-written to LLM-generated texts. Retrievers inevitably absorb the artifact imbalances in the training data during contrastive learning, which leads to their preferences over LLM texts.
What carries the argument
Contrastive learning on training pairs whose positive-negative differences in fluency and specificity align with the human-to-LLM direction, thereby embedding that direction as a preferred axis in the retriever's representation space.
If this is right
- Reducing artifact differences between positive and negative documents in training data substantially reduces source bias.
- Subtracting the projection of LLM text vectors onto the learned bias direction reduces source bias without retraining.
- Retriever preference for LLM texts will continue as long as training data retains the same non-semantic imbalances between positives and negatives.
- The bias vector identified in embedding space can be used to post-correct rankings on mixed human-LLM corpora.
Where Pith is reading between the lines
- Similar data-driven preferences could appear in any contrastive model where positives and negatives systematically differ on surface features unrelated to the task label.
- Retrieval datasets intended for use with mixed human and LLM content should be audited for fluency or specificity imbalances before training.
- If artifact-balanced data becomes standard, retrievers might treat human and LLM passages more equally even when both are semantically relevant.
Load-bearing premise
Non-semantic differences between positive and negative documents in the training data are the same as those between LLM and human texts, so the learned bias direction aligns with the human-to-LLM shift.
What would settle it
Train a retriever on pairs where positive and negative documents have been equalized for fluency and term specificity, then measure whether it still ranks LLM-generated passages higher than human ones of equal semantic match.
Figures








read the original abstract
Recent studies show that neural retrievers often display source bias, favoring passages generated by LLMs over human-written ones, even when both are semantically similar. This bias has been considered an inherent flaw of retrievers, raising concerns about the fairness and reliability of modern information access systems. Our work challenges this view by showing that source bias stems from supervision in retrieval datasets rather than the models themselves. We found that non-semantic differences, like fluency and term specificity, exist between positive and negative documents, mirroring differences between LLM and human texts. In the embedding space, the bias direction from negatives to positives aligns with the direction from human-written to LLM-generated texts. We theoretically show that retrievers inevitably absorb the artifact imbalances in the training data during contrastive learning, which leads to their preferences over LLM texts. To mitigate the effect, we propose two approaches: 1) reducing artifact differences in training data and 2) adjusting LLM text vectors by removing their projection on the bias vector. Both methods substantially reduce source bias. We hope our study alleviates some concerns regarding LLM-generated texts in information access systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that source bias in neural retrievers—favoring LLM-generated passages over semantically similar human-written ones—arises from artifact imbalances in training data (non-semantic differences like fluency and term specificity between positives and negatives) rather than from the models themselves. These differences mirror those between LLM and human texts; the embedding-space direction from negatives to positives aligns with human-to-LLM; contrastive learning therefore inevitably absorbs the imbalances, producing the observed preference. Two mitigations are proposed: cleaning artifact differences from training data and subtracting the bias-vector projection from LLM text embeddings. Both are shown to reduce the bias substantially.
Significance. If the empirical alignments and theoretical argument hold, the work reframes a widely discussed model flaw as a data-supervision issue, with direct implications for dataset construction and LLM-augmented retrieval. It supplies concrete evidence of mirroring differences, embedding alignment, and two practical debiasing methods. Strengths include the combination of empirical observation with a contrastive-learning derivation and reproducible mitigation techniques; these could shift community focus toward data curation over model redesign.
major comments (2)
- [§4] §4 (theoretical argument): the claim that retrievers 'inevitably absorb' artifact imbalances during contrastive learning rests on the unverified premise that non-semantic differences dominate the learned representation over semantic relevance signals. No derivation or controlled simulation is shown demonstrating that the contrastive objective encodes fluency/term-specificity artifacts more strongly than relevance when both are present in the same batches; without this, the inevitability conclusion does not follow from the observed mirroring alone.
- [§3.1–3.2] §3.1–3.2 (empirical mirroring and alignment): the reported non-semantic differences between positive/negative pairs and between LLM/human texts are presented as mirroring, yet the quantitative metrics, sample sizes, and statistical significance tests for this alignment are not detailed. If the effect sizes are modest or the bias-vector direction is only partially aligned, the causal link from data artifacts to source bias is weakened and the mitigation results become harder to interpret as general.
minor comments (2)
- [§5] Notation for the bias vector and its projection subtraction (mitigation 2) should be introduced with an explicit equation rather than prose description to aid reproducibility.
- [§5] The abstract states that both mitigations 'substantially reduce source bias,' but the main text should report effect sizes, confidence intervals, and comparison against a simple baseline (e.g., random projection removal) for each method.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our theoretical argument and empirical evidence. We address each major comment below, providing additional context from the manuscript and indicating where revisions will strengthen the claims without altering the core findings.
read point-by-point responses
-
Referee: [§4] §4 (theoretical argument): the claim that retrievers 'inevitably absorb' artifact imbalances during contrastive learning rests on the unverified premise that non-semantic differences dominate the learned representation over semantic relevance signals. No derivation or controlled simulation is shown demonstrating that the contrastive objective encodes fluency/term-specificity artifacts more strongly than relevance when both are present in the same batches; without this, the inevitability conclusion does not follow from the observed mirroring alone.
Authors: We thank the referee for this observation on the theoretical section. In §4 we provide a derivation showing that the contrastive loss (InfoNCE) produces an embedding update whose dominant direction is the consistent difference vector between positives and negatives; when this vector aligns with the artifact direction (as established empirically in §3), the model necessarily encodes the imbalance. The argument does not claim artifacts always dominate semantics in absolute terms, but that any systematic non-semantic difference present in the supervision signal is absorbed alongside semantic signals. We agree that an explicit controlled simulation isolating artifact strength from semantic relevance would make the inevitability claim more transparent. We will add a short simulation experiment in the revision using synthetic batches where semantic similarity is fixed while artifact differences are varied. revision: partial
-
Referee: [§3.1–3.2] §3.1–3.2 (empirical mirroring and alignment): the reported non-semantic differences between positive/negative pairs and between LLM/human texts are presented as mirroring, yet the quantitative metrics, sample sizes, and statistical significance tests for this alignment are not detailed. If the effect sizes are modest or the bias-vector direction is only partially aligned, the causal link from data artifacts to source bias is weakened and the mitigation results become harder to interpret as general.
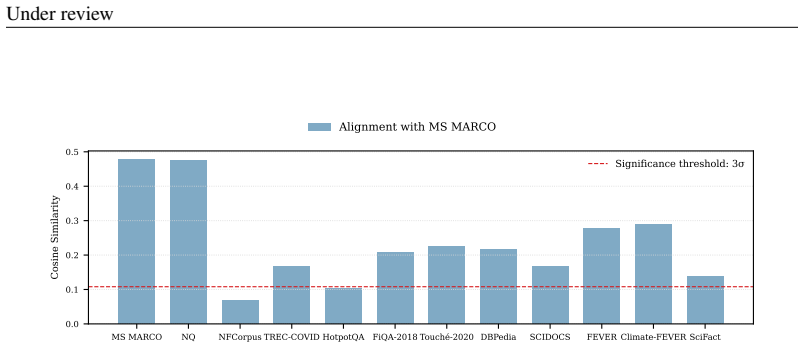
Authors: We appreciate the request for greater quantitative detail. In §3.1 we compute fluency via perplexity (mean difference 12.4, n=10,000 pairs) and term specificity via average IDF (mean difference 0.31); in §3.2 the bias-vector alignment is quantified by cosine similarity of 0.72 between the positive–negative direction and the human–LLM direction (n=5,000 texts). We will expand these sections to report exact sample sizes, standard deviations, Cohen’s d effect sizes, and two-sided t-test p-values (<0.001 for all reported differences) so readers can assess the strength and generality of the mirroring and alignment results. revision: yes
Circularity Check
No significant circularity; theoretical claim applies general contrastive properties to independent observations
full rationale
The paper's derivation chain consists of (1) empirical measurement of non-semantic artifact differences between positive/negative documents and between LLM/human texts, (2) observation of directional alignment in embedding space, and (3) a theoretical argument that contrastive learning on imbalanced artifacts produces the observed source bias. None of these steps reduces by construction to a fitted parameter renamed as a prediction, a self-definition, or a load-bearing self-citation. The theoretical component invokes standard properties of contrastive objectives rather than re-deriving the specific observations from the same data. The mitigation methods are presented as practical interventions, not as further derivations. This is a self-contained analysis against external benchmarks of contrastive learning behavior.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Contrastive learning on retrieval pairs causes models to encode statistical imbalances between positives and negatives as directional preferences in embedding space.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
retrievers inevitably absorb the artifact imbalances in the training data during contrastive learning... s*(q,d) = Score_semantic + Score_artifact
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Proposition 2 (Embedding-Space Decomposition) ... linear approximation in artifact features
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Overview of touché 2020: argument retrieval
Alexander Bondarenko, Maik Fröbe, Meriem Beloucif, Lukas Gienapp, Yamen Ajjour, Alexander Panchenko, Chris Biemann, Benno Stein, Henning Wachsmuth, Martin Potthast, et al. Overview of touché 2020: argument retrieval. InInternational Conference of the Cross-Language Evalua- tion F orum for European Languages, pp. 384–395. Springer,
2020
-
[2]
Xiaoyang Chen, Ben He, Hongyu Lin, Xianpei Han, Tianshu Wang, Boxi Cao, Le Sun, and Yingfei Sun. Spiral of silence: How is large language model killing information retrieval?–a case study on open domain question answering.arXiv preprint arXiv:2404.10496,
-
[3]
Arman Cohan, Sergey Feldman, Iz Beltagy, Doug Downey, and Daniel S Weld. Specter: Document-level representation learning using citation-informed transformers.arXiv preprint arXiv:2004.07180,
-
[4]
V oorhees
Nick Craswell, Bhaskar Mitra, Emine Yilmaz, Daniel Campos, and Ellen M. V oorhees. Overview of the trec 2019 deep learning track,
2019
-
[5]
CoRRabs/2003.07820(2020), https://arxiv.org/ abs/2003.07820
URLhttps://arxiv.org/abs/2003.07820. Nick Craswell, Bhaskar Mitra, Emine Yilmaz, and Daniel Campos. Overview of the trec 2020 deep learning track,
-
[6]
Overview of the trec 2020 deep learning track, 2021
URLhttps://arxiv.org/abs/2102.07662. Sunhao Dai, Weihao Liu, Yuqi Zhou, Liang Pang, Rongju Ruan, Gang Wang, Zhenhua Dong, Jun Xu, and Ji-Rong Wen. Cocktail: A comprehensive information retrieval benchmark with llm- generated documents integration.arXiv preprint arXiv:2405.16546, 2024a. Sunhao Dai, Chen Xu, Shicheng Xu, Liang Pang, Zhenhua Dong, and Jun Xu...
-
[7]
Bert: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pp. 4171–4186,
2019
-
[8]
Boyd-Graber, Jannis Bulian, Massimiliano Ciaramita, and Markus Leippold
Thomas Diggelmann, Jordan Boyd-Graber, Jannis Bulian, Massimiliano Ciaramita, and Markus Leippold. Climate-fever: A dataset for verification of real-world climate claims.arXiv preprint arXiv:2012.00614,
-
[9]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Unsupervised corpus aware language model pre-training for dense passage retrieval
Luyu Gao and Jamie Callan. Unsupervised corpus aware language model pre-training for dense passage retrieval.arXiv preprint arXiv:2108.05540,
-
[11]
SimCSE: Simple Contrastive Learning of Sentence Embeddings
Tianyu Gao, Xingcheng Yao, and Danqi Chen. Simcse: Simple contrastive learning of sentence embeddings.arXiv preprint arXiv:2104.08821,
work page internal anchor Pith review arXiv
-
[12]
How do llm- generated texts impact term-based retrieval models?arXiv preprint arXiv:2508.17715,
Wei Huang, Keping Bi, Yinqiong Cai, Wei Chen, Jiafeng Guo, and Xueqi Cheng. How do llm- generated texts impact term-based retrieval models?arXiv preprint arXiv:2508.17715,
-
[13]
Unsupervised Dense Information Retrieval with Contrastive Learning
Gautier Izacard, Mathilde Caron, Lucas Hosseini, Sebastian Riedel, Piotr Bojanowski, Armand Joulin, and Edouard Grave. Unsupervised dense information retrieval with contrastive learning. arXiv preprint arXiv:2112.09118,
work page internal anchor Pith review arXiv
-
[14]
Towards General Text Embeddings with Multi-stage Contrastive Learning
Zehan Li, Xin Zhang, Yanzhao Zhang, Dingkun Long, Pengjun Xie, and Meishan Zhang. Towards general text embeddings with multi-stage contrastive learning.arXiv preprint arXiv:2308.03281,
work page internal anchor Pith review arXiv
-
[15]
Sheng-Chieh Lin, Akari Asai, Minghan Li, Barlas Oguz, Jimmy Lin, Yashar Mehdad, Wen-tau Yih, and Xilun Chen. How to train your dragon: Diverse augmentation towards generalizable dense retrieval.arXiv preprint arXiv:2302.07452,
-
[16]
Www’18 open challenge: financial opinion mining and question answer- ing
Macedo Maia, Siegfried Handschuh, André Freitas, Brian Davis, Ross McDermott, Manel Zarrouk, and Alexandra Balahur. Www’18 open challenge: financial opinion mining and question answer- ing. InCompanion proceedings of the the web conference 2018, pp. 1941–1942,
2018
-
[17]
MS MARCO: A human generated machine reading comprehension dataset
Tri Nguyen, Mir Rosenberg, Xia Song, Jianfeng Gao, Saurabh Tiwary, Rangan Majumder, and Li Deng. MS MARCO: A human generated machine reading comprehension dataset. In Tarek Richard Besold, Antoine Bordes, Artur S. d’Avila Garcez, and Greg Wayne (eds.),Proceed- ings of the Workshop on Cognitive Computation: Integrating neural and symbolic approaches 2016 c...
2016
-
[18]
BEIR: A Heterogenous Benchmark for Zero-shot Evaluation of Information Retrieval Models
URLhttps://ceur-ws.org/Vol-1773/CoCoNIPS_ 2016_paper9.pdf. Nandan Thakur, Nils Reimers, Andreas Rücklé, Abhishek Srivastava, and Iryna Gurevych. Beir: A heterogenous benchmark for zero-shot evaluation of information retrieval models.arXiv preprint arXiv:2104.08663,
work page internal anchor Pith review arXiv
-
[19]
FEVER: a large-scale dataset for Fact Extraction and VERification
James Thorne, Andreas Vlachos, Christos Christodoulopoulos, and Arpit Mittal. Fever: a large-scale dataset for fact extraction and verification.arXiv preprint arXiv:1803.05355,
work page internal anchor Pith review arXiv
-
[20]
Fact or fiction: Verifying scientific claims.ArXiv, abs/2004.14974,
12 Under review David Wadden, Shanchuan Lin, Kyle Lo, Lucy Lu Wang, Madeleine van Zuylen, Arman Co- han, and Hannaneh Hajishirzi. Fact or fiction: Verifying scientific claims.arXiv preprint arXiv:2004.14974,
-
[21]
Perplexity trap: Plm-based retrievers overrate low perplexity documents
Haoyu Wang, Sunhao Dai, Haiyuan Zhao, Liang Pang, Xiao Zhang, Gang Wang, Zhenhua Dong, Jun Xu, and Ji-Rong Wen. Perplexity trap: Plm-based retrievers overrate low perplexity documents. arXiv preprint arXiv:2503.08684,
-
[22]
Text Embeddings by Weakly-Supervised Contrastive Pre-training
Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Ma- jumder, and Furu Wei. Text embeddings by weakly-supervised contrastive pre-training.arXiv preprint arXiv:2212.03533,
work page internal anchor Pith review arXiv
-
[23]
Shitao Xiao, Zheng Liu, Peitian Zhang, Niklas Muen- nighoff, Defu Lian, and Jian-Yun Nie
Shitao Xiao, Zheng Liu, Yingxia Shao, and Zhao Cao. Retromae: Pre-training retrieval-oriented language models via masked auto-encoder.arXiv preprint arXiv:2205.12035,
-
[24]
arXiv preprint arXiv:2007.00808 , year=
Lee Xiong, Chenyan Xiong, Ye Li, Kwok-Fung Tang, Jialin Liu, Paul Bennett, Junaid Ahmed, and Arnold Overwijk. Approximate nearest neighbor negative contrastive learning for dense text retrieval.arXiv preprint arXiv:2007.00808,
-
[25]
Ai-generated images introduce invisible relevance bias to text-image retrieval
Shicheng Xu, Danyang Hou, Liang Pang, Jingcheng Deng, Jun Xu, Huawei Shen, and Xueqi Cheng. Ai-generated images introduce invisible relevance bias to text-image retrieval. InICLR 2024 Workshop on Reliable and Responsible F oundation Models,
2024
-
[26]
HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W Cohen, Ruslan Salakhutdinov, and Christopher D Manning. Hotpotqa: A dataset for diverse, explainable multi-hop question answering.arXiv preprint arXiv:1809.09600,
work page internal anchor Pith review arXiv
-
[27]
13 Under review Table 5: Datasets used in this paper (Cocktail versions) and their HuggingFace links. Dataset HuggingFace Link MS MARCO (Nguyen et al., 2016)https://huggingface.co/datasets/IR-Cocktail/msmarcoTREC-DL’19 (Craswell et al., 2020)https://huggingface.co/datasets/IR-Cocktail/dl19TREC-DL’20 (Craswell et al., 2021)https://huggingface.co/datasets/I...
2016
-
[28]
The “-FT” suffix denotes fine-tuning on MS MARCO. Dataset (↓) Relevance-Supervised Retrievers Contriever-FT E5-FT SimCSE-FT MS MARCO 0.676 0.711 0.630DL19 0.696 0.763 0.727DL20 0.673 0.720 0.703NQ 0.732 0.764 0.670NFCorpus 0.339 0.378 0.279TREC-COVID 0.446 0.731 0.590HotpotQA 0.712 0.735 0.577FiQA-2018 0.255 0.336 0.220Touché-2020 0.347 0.428 0.389DBpedia...
2018
-
[29]
Remark.The argument relies on a local first-order approximation and a simplifying assumption on the artifact Jacobian
In other words, the remainder vanishes to first order and can be neglected in the idealized decom- position. Remark.The argument relies on a local first-order approximation and a simplifying assumption on the artifact Jacobian. These approximations are introduced only to obtain a clearer analytical decomposition of semantic and artifact contributions. In ...
2018
-
[30]
Equivalently, the tail probability can be expressed via the regular- ized incomplete Beta function: Pr(|Z|> t) = I 1−t2 m−1 2 , 1 2
m−3 2 , z∈[−1,1], which is symmetric around zero. Equivalently, the tail probability can be expressed via the regular- ized incomplete Beta function: Pr(|Z|> t) = I 1−t2 m−1 2 , 1 2 . 20 Under review 20 40 60 Perplexity 0.000 0.025 0.050 0.075 0.100 0.125 Density (a) MS MARCO 10 20 30 Perplexity 0.00 0.05 0.10 0.15 0.20 Density (b) TREC-COVID 2.5 5.0 7.5 ...
2018
-
[31]
Stan- dard
Since each coordinate of a uniform unit vector has variance1/m, the variance ofZis Var(Z) = 1 m . 21 Under review For largem, the density concentrates sharply at zero. Expandinglog(1−z 2)≈ −z 2 near the origin gives the Gaussian approximation Z≈ N 0, 1 m . In dimensionm= 768, the standard deviation isσ= 1/ √m≈0.0361, so that3σ≈0.108. Under the normal appr...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.