RePL: Pseudo-label Refinement for Semi-supervised LiDAR Semantic Segmentation
Pith reviewed 2026-05-10 17:46 UTC · model grok-4.3
The pith
RePL refines noisy pseudo-labels via masked reconstruction to reach state-of-the-art LiDAR semantic segmentation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
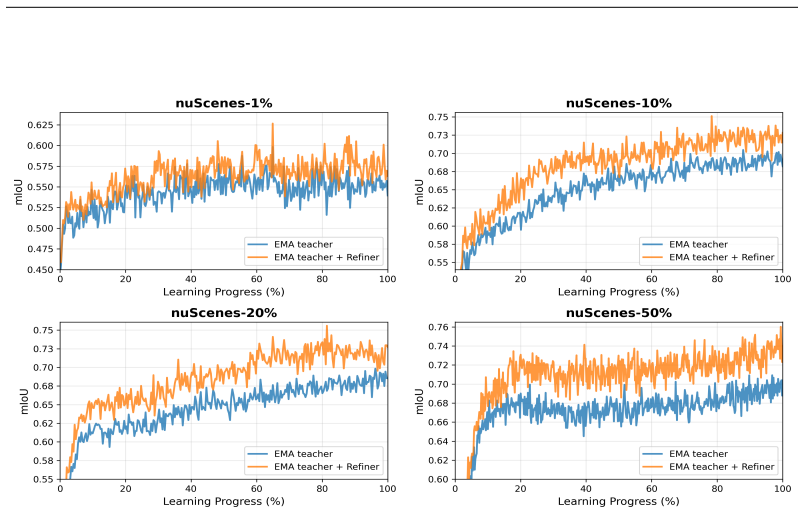
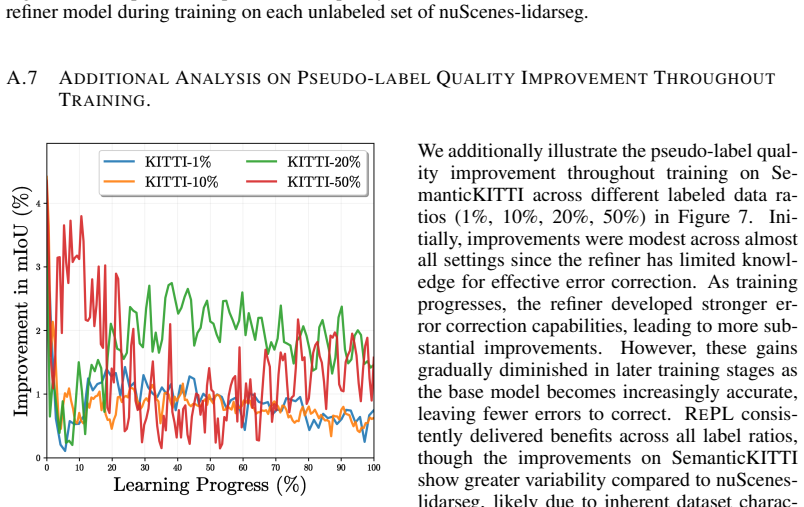
RePL enhances pseudo-label quality by identifying and correcting potential errors through masked reconstruction along with a dedicated training strategy; a theoretical analysis demonstrates that the condition under which pseudo-label refinement is beneficial is mild and is clearly satisfied by RePL, yielding state-of-the-art results on nuScenes-lidarseg and SemanticKITTI.
What carries the argument
Masked reconstruction applied to pseudo-labels to identify and correct errors within a semi-supervised LiDAR segmentation pipeline.
If this is right
- Refined pseudo-labels reduce confirmation bias and error propagation during semi-supervised training.
- The approach reaches state-of-the-art segmentation accuracy on the nuScenes-lidarseg and SemanticKITTI benchmarks.
- The theoretical condition required for refinement to be beneficial is mild and holds under the conditions tested.
- The dedicated training strategy complements the reconstruction-based correction step.
Where Pith is reading between the lines
- The same masked-reconstruction idea could be tested on other 3D perception tasks that rely on pseudo-labels.
- The mild theoretical condition suggests the method may transfer to new datasets with only modest hyper-parameter changes.
- Combining RePL with stronger data augmentation or consistency regularization might produce further gains beyond the reported results.
Load-bearing premise
Masked reconstruction can reliably detect and correct errors in pseudo-labels without introducing new biases.
What would settle it
If the refined pseudo-labels show no measurable accuracy gain over standard pseudo-labels on a held-out validation split of nuScenes-lidarseg or SemanticKITTI, or if end-to-end segmentation performance fails to improve, the central claim would be falsified.
Figures







read the original abstract
Semi-supervised learning for LiDAR semantic segmentation often suffers from error propagation and confirmation bias caused by noisy pseudo-labels. To tackle this chronic issue, we introduce RePL, a novel framework that enhances pseudo-label quality by identifying and correcting potential errors in pseudo-labels through masked reconstruction, along with a dedicated training strategy. We also provide a theoretical analysis demonstrating the condition under which the pseudo-label refinement is beneficial, and empirically confirm that the condition is mild and clearly met by RePL. Extensive evaluations on the nuScenes-lidarseg and SemanticKITTI datasets show that RePL improves pseudo-label quality a lot and, as a result, achieves the state of the art in LiDAR semantic segmentation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes RePL, a framework for semi-supervised LiDAR semantic segmentation that refines noisy pseudo-labels via masked reconstruction to reduce error propagation and confirmation bias. It provides a theoretical analysis of the condition under which refinement is beneficial, empirically confirms that this condition is mild and satisfied by RePL, and reports state-of-the-art results on nuScenes-lidarseg and SemanticKITTI.
Significance. If the claims hold, RePL could meaningfully advance reliable semi-supervised 3D perception for autonomous driving by directly targeting pseudo-label quality. The presence of a theoretical analysis is a credit, as is the focus on a chronic issue in the field. However, the significance is tempered by the need to verify that masked reconstruction corrects errors without introducing reconstruction artifacts or confirmation bias, and that the theoretical condition generalizes beyond idealized noise models.
major comments (3)
- [§3.2] §3.2 (Theoretical Analysis): The derivation of the beneficial-refinement condition relies on an idealized model of label noise. It is unclear whether the condition remains mild or is satisfied when the model is extended to the spatially correlated, class-imbalanced errors typical of LiDAR point clouds; this directly affects the central claim that the condition is 'mild and clearly met by RePL'.
- [§4.2] §4.2 (Ablation Studies): The reported SOTA gains are not accompanied by an ablation that isolates the masked-reconstruction refinement step from the dedicated training strategy and other implementation choices. Without this isolation, it is difficult to attribute performance improvements specifically to the pseudo-label correction mechanism.
- [§4.1] §4.1 (Experimental Setup): The manuscript does not report error bars, multiple random seeds, or statistical significance tests for the nuScenes-lidarseg and SemanticKITTI results. This weakens the strength of the empirical confirmation that the theoretical condition holds and that RePL improves pseudo-label quality.
minor comments (2)
- [§3.1] The notation for the masked reconstruction loss and the pseudo-label refinement operator could be introduced more explicitly with a single equation block to improve readability.
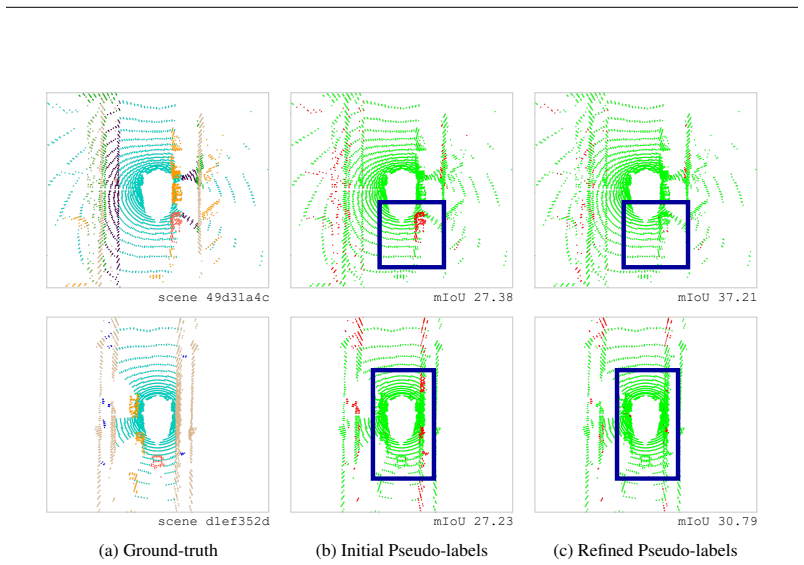
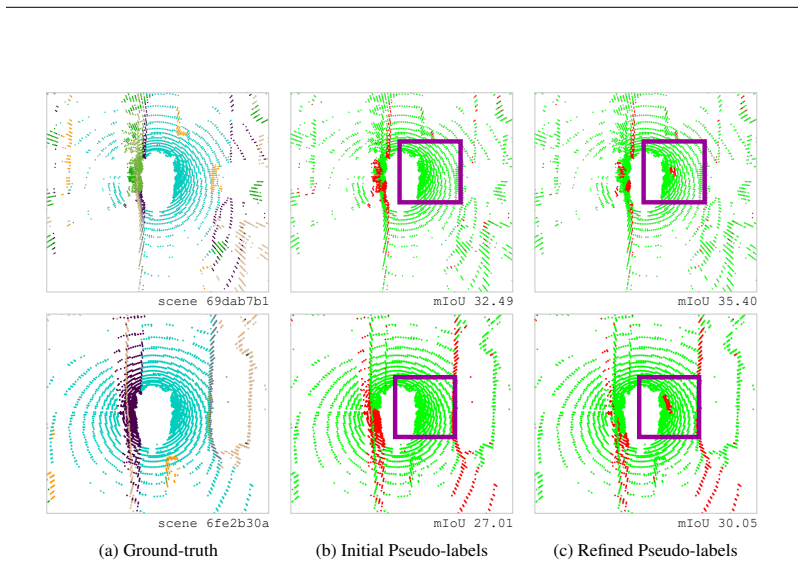
- [Figure 4] Figure 4 (qualitative results) would benefit from side-by-side comparison with a strong baseline pseudo-labeling method to visually demonstrate the specific corrections made by RePL.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and describe the revisions we will incorporate to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Theoretical Analysis): The derivation of the beneficial-refinement condition relies on an idealized model of label noise. It is unclear whether the condition remains mild or is satisfied when the model is extended to the spatially correlated, class-imbalanced errors typical of LiDAR point clouds; this directly affects the central claim that the condition is 'mild and clearly met by RePL'.
Authors: We acknowledge that the theoretical derivation employs an independent noise model chosen for analytical tractability. The resulting condition nevertheless isolates the dependence on noise rate and class priors, which remain relevant even under spatial correlation. Our empirical results on nuScenes-lidarseg and SemanticKITTI—datasets that exhibit precisely the correlated and imbalanced errors mentioned—show consistent pseudo-label improvement and performance gains, thereby confirming that the condition is satisfied in practice. In the revision we will add a dedicated paragraph discussing the idealized assumption and its relation to real LiDAR noise statistics. revision: partial
-
Referee: [§4.2] §4.2 (Ablation Studies): The reported SOTA gains are not accompanied by an ablation that isolates the masked-reconstruction refinement step from the dedicated training strategy and other implementation choices. Without this isolation, it is difficult to attribute performance improvements specifically to the pseudo-label correction mechanism.
Authors: We agree that a more targeted ablation is needed to isolate the contribution of masked reconstruction. The current ablations examine internal design choices of RePL, but do not directly compare against raw pseudo-labels under an otherwise identical training protocol. We will add this comparison (RePL versus the same pipeline without the refinement module) in the revised experimental section. revision: yes
-
Referee: [§4.1] §4.1 (Experimental Setup): The manuscript does not report error bars, multiple random seeds, or statistical significance tests for the nuScenes-lidarseg and SemanticKITTI results. This weakens the strength of the empirical confirmation that the theoretical condition holds and that RePL improves pseudo-label quality.
Authors: We recognize that reporting variability is important for robust claims. The original submission presented single-run results owing to the high computational cost of large-scale LiDAR training. In the revision we will rerun the main experiments with at least three random seeds, include error bars, and add statistical significance tests (paired t-tests) between RePL and the strongest baselines. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents a theoretical analysis of a condition for beneficial pseudo-label refinement followed by empirical confirmation that RePL meets it. No equations or steps are exhibited that reduce the claimed prediction, condition satisfaction, or SOTA result to a fitted parameter, self-definition, or self-citation chain by construction. The theoretical component is presented as independent analysis, and the empirical verification is described as confirmation rather than a tautological fit. This is the common honest case of a self-contained paper whose central claims rest on external benchmarks (nuScenes, SemanticKITTI) rather than internal redefinition.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
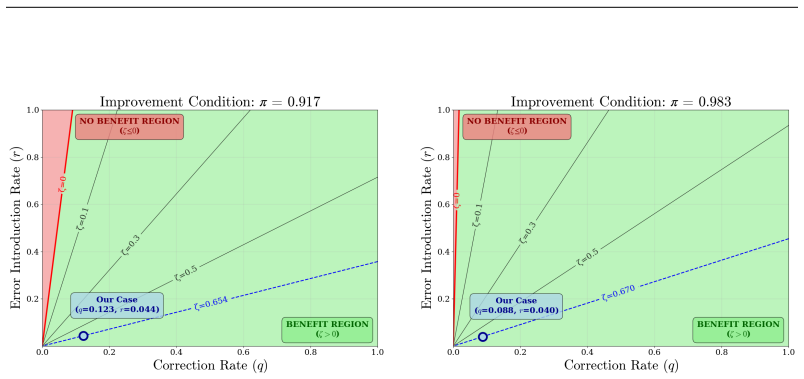
Proposition 2 … ζ_j := π_j − r_j/(q_j + r_j) > 0 … the condition is mild and clearly met by RePL
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
masked reconstruction … learnable mask token T … refiner g(X, Q̄)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Whye Kit Fong, Rohit Mohan, Juana Valeria Hurtado, Lubing Zhou, Holger Caesar, Oscar Beijbom, and Abhinav Valada. Panoptic nuscenes: A large-scale benchmark for lidar panoptic segmentation and tracking.arXiv preprint arXiv:2109.03805,
-
[2]
Qi, Boqing Gong, Hao Su, and Dragomir Anguelov
Minghua Liu, Yin Zhou, Charles R. Qi, Boqing Gong, Hao Su, and Dragomir Anguelov. Less: Label-efficient semantic segmentation for lidar point clouds.arXiv preprint arXiv:2210.08064,
-
[3]
Unsupervised Out-of-Distribution Detection by Maximum Clas- sifier Discrepancy
doi: 10.1109/ICCV .2019.00041. Xiang Xu, Lingdong Kong, Hui Shuai, Wenwei Zhang, Liang Pan, Kai Chen, Ziwei Liu, and Qing- shan Liu. 4d contrastive superflows are dense 3d representation learners. InProc. European Conference on Computer Vision (ECCV),
-
[4]
13 A APPENDIX A.1 THEORETICALANALYSIS ONTASKDIFFICULTY We investigate Proposition 1, describing the relationship between two tasks: the segmentation task and the refinement task, which refines pseudo-labels generated by another segmentation model. Definition 1(Segmentation and Refinement Tasks).LetXdenote the input 3D LiDAR point data andYthe segmentation...
work page 1998
-
[5]
Proof.By the chain rule of conditional entropy: D(Z)−D(Z ′) =H(Y|X)−H(Y|X, T)(15) =H(Y|X)−(H(Y|X)−I(Y;T|X))(16) =I(Y;T|X).(17) Since the mutual informationI(Y;T|X)≥0by definition, we obtainD(Z ′)≤D(Z)from Proposition 1, with equality if and only ifTprovides no information aboutYbeyond what is already contained inX(Cover & Thomas, 2006). Implication.In a s...
work page 2006
-
[6]
and SemanticKITTI (Behley et al., 2019), as reported in Table
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.