What's Missing in Screen-to-Action? Towards a UI-in-the-Loop Paradigm for Multimodal GUI Reasoning
Pith reviewed 2026-05-10 17:40 UTC · model grok-4.3
The pith
Treating GUI reasoning as a cyclic Screen-UI-Action process lets MLLMs explicitly learn element localization, semantics, and usage for more precise and interpretable decisions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
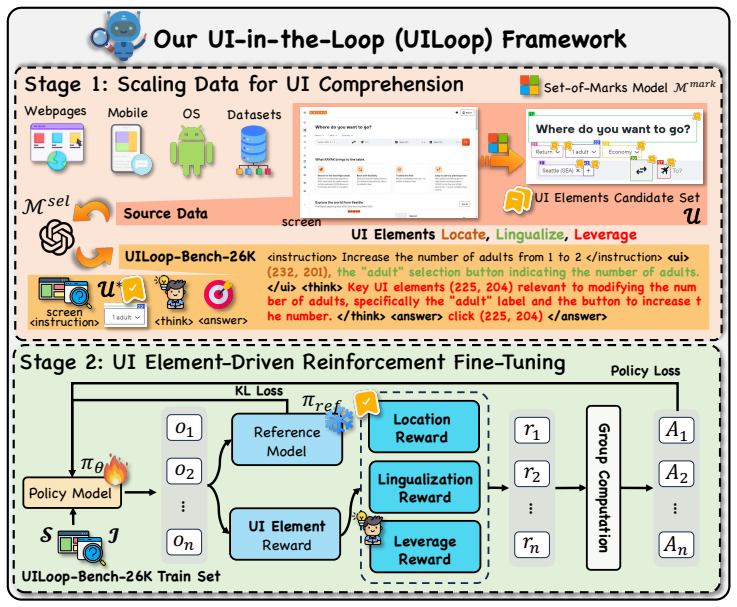
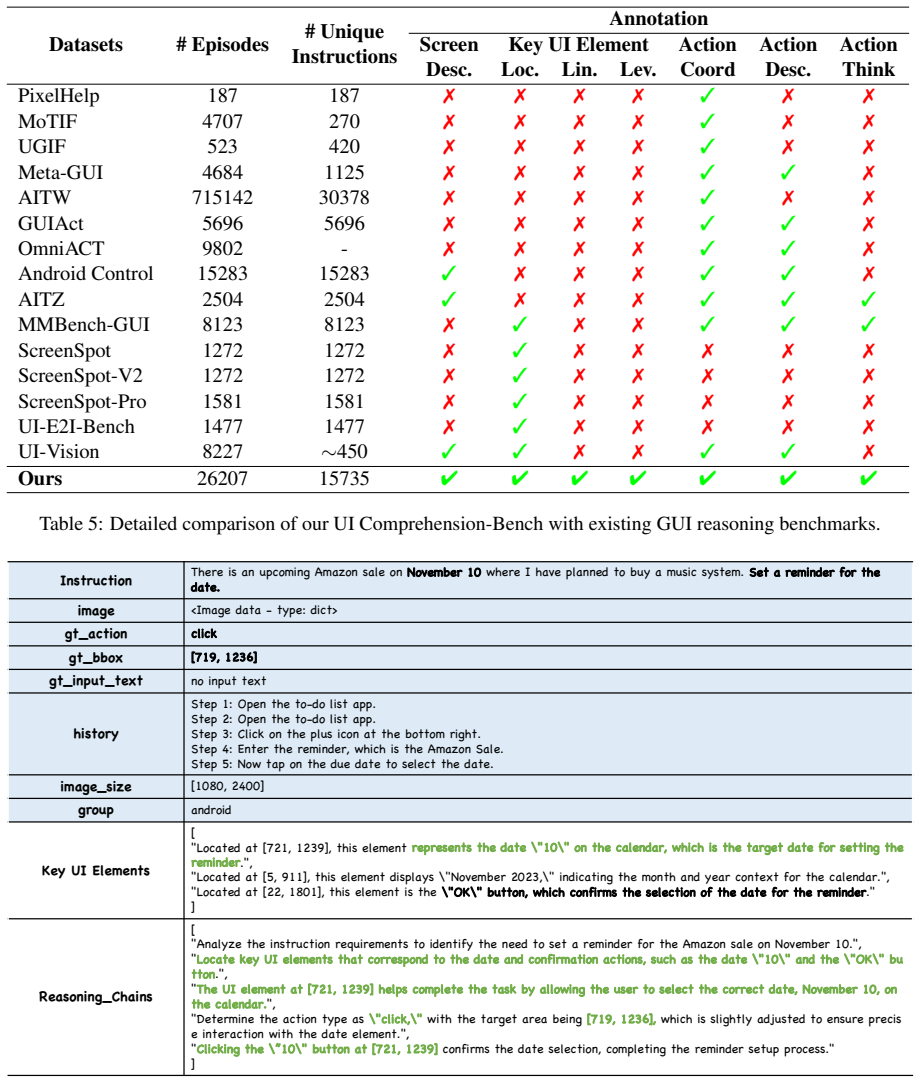
UILoop reframes GUI reasoning as a cyclic Screen-UI elements-Action process. By training Multimodal Large Language Models to explicitly learn the localization, semantic functions, and practical usage of key UI elements, the approach achieves precise element discovery and interpretable reasoning. It further introduces a UI Comprehension task with three evaluation metrics and contributes the UI Comprehension-Bench containing 26K samples to test mastery of UI elements. Experiments show state-of-the-art UI understanding performance along with superior results on GUI reasoning tasks.
What carries the argument
The UI-in-the-Loop (UILoop) paradigm, which structures the reasoning task as a cyclic Screen-UI elements-Action process that inserts explicit learning of UI element localization, semantics, and usage.
If this is right
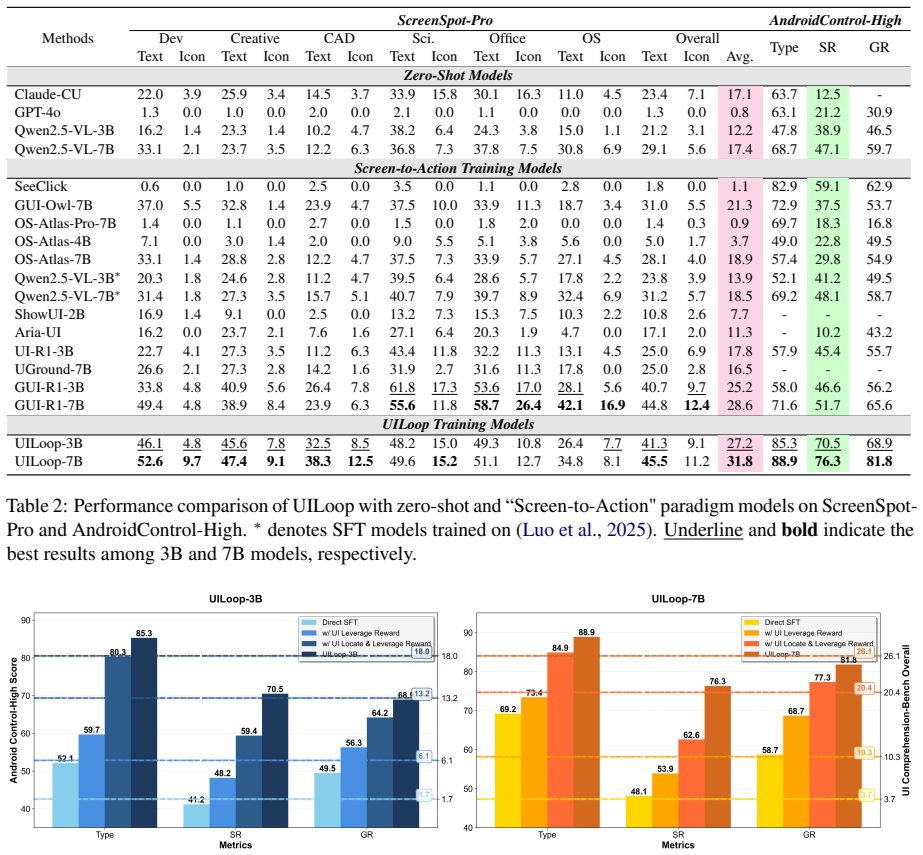
- UILoop reaches state-of-the-art performance on UI understanding tasks.
- GUI reasoning tasks obtain superior results compared with direct screen-based methods.
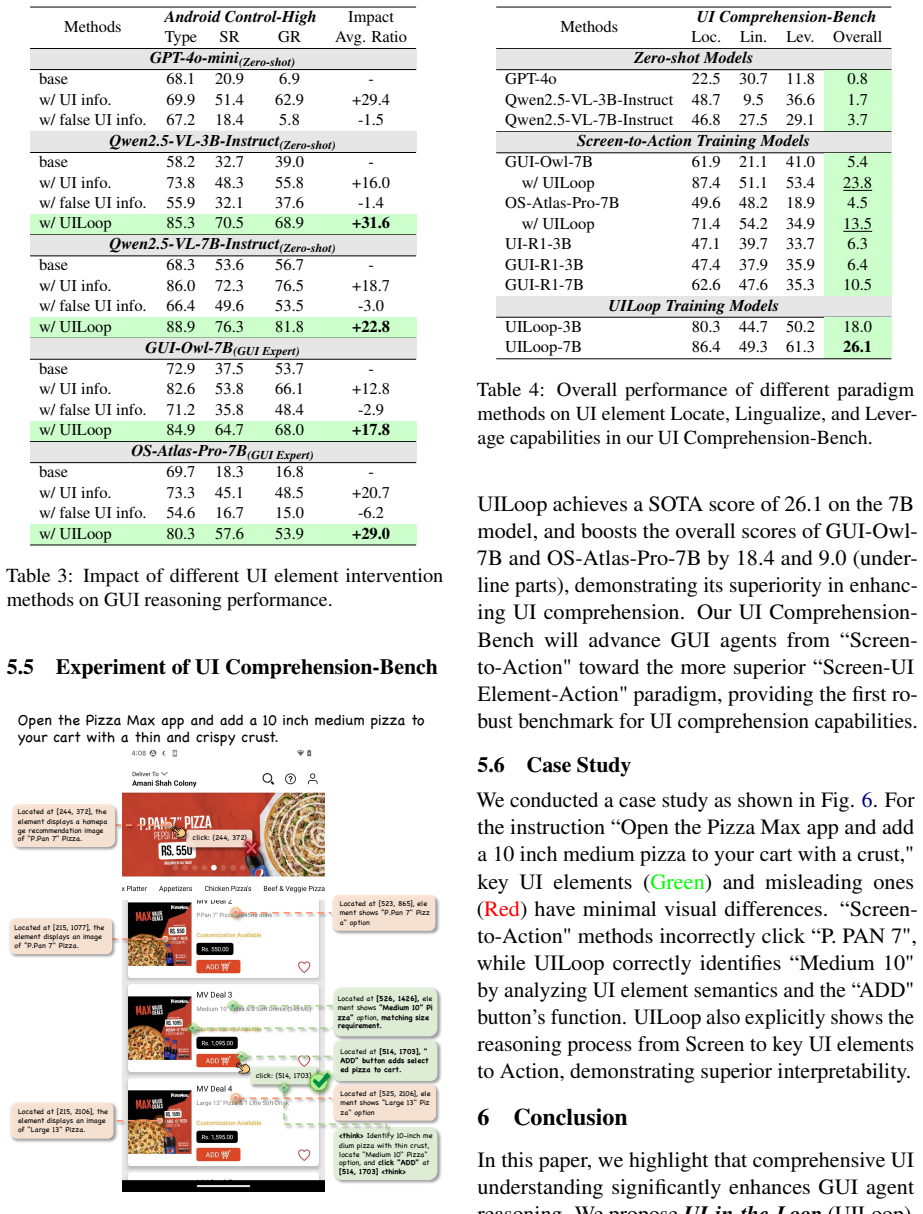
- The UI Comprehension task with its three metrics provides a standardized test of how well models grasp element functions and usage.
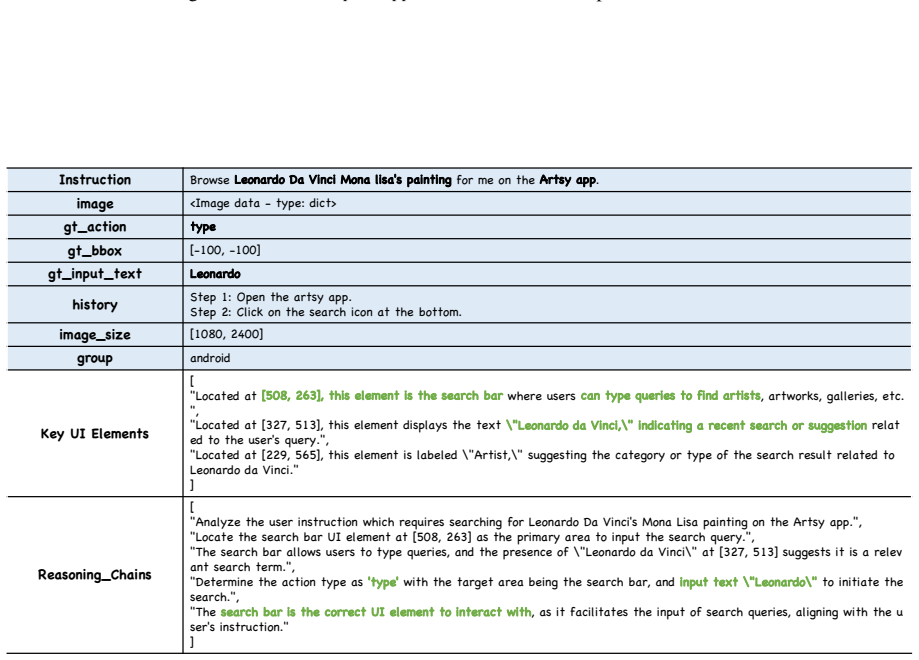
- The 26K-sample UI Comprehension-Bench enables comprehensive measurement of existing methods' mastery of UI elements.
Where Pith is reading between the lines
- The same cyclic structure could be tested on other multimodal tasks that require fine-grained localization of interface objects.
- Explicit element steps may make it easier to debug why a GUI agent chose a wrong action.
- Training data that annotates UI element locations and functions will become more important if the loop approach scales.
Load-bearing premise
Inserting an explicit UI-element learning step into the cyclic Screen-UI-Action process will raise both accuracy and interpretability without creating new failure modes or requiring impractical amounts of supervision.
What would settle it
A side-by-side evaluation on the UI Comprehension-Bench in which UILoop models show no accuracy gain over direct screen-to-action baselines or produce reasoning traces that humans rate no more interpretable.
Figures





read the original abstract
Existing Graphical User Interface (GUI) reasoning tasks remain challenging, particularly in UI understanding. Current methods typically rely on direct screen-based decision-making, which lacks interpretability and overlooks a comprehensive understanding of UI elements, ultimately leading to task failure. To enhance the understanding and interaction with UIs, we propose an innovative GUI reasoning paradigm called UI-in-the-Loop (UILoop). Our approach treats the GUI reasoning task as a cyclic Screen-UI elements-Action process. By enabling Multimodal Large Language Models (MLLMs) to explicitly learn the localization, semantic functions, and practical usage of key UI elements, UILoop achieves precise element discovery and performs interpretable reasoning. Furthermore, we introduce a more challenging UI Comprehension task centered on UI elements with three evaluation metrics. Correspondingly, we contribute a benchmark of 26K samples (UI Comprehension-Bench) to comprehensively evaluate existing methods' mastery of UI elements. Extensive experiments demonstrate that UILoop achieves state-of-the-art UI understanding performance while yielding superior results in GUI reasoning tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes UI-in-the-Loop (UILoop), a new paradigm for GUI reasoning that treats the task as a cyclic Screen-UI elements-Action process. MLLMs are trained to explicitly learn localization, semantic functions, and practical usage of key UI elements for precise discovery and interpretable reasoning. It introduces a UI Comprehension task with three metrics and the UI Comprehension-Bench dataset of 26K samples, with experiments showing SOTA performance on UI understanding and GUI reasoning tasks.
Significance. This paradigm could improve the robustness and interpretability of multimodal GUI agents by incorporating explicit UI element understanding, addressing limitations in direct screen-to-action methods. The contributed benchmark may serve as a standard for evaluating UI comprehension in future work, potentially influencing the development of more reliable interface-interacting AI systems.
major comments (2)
- [Abstract] Abstract: The assertion of state-of-the-art results on UI understanding and GUI reasoning supplies no experimental details, baselines, error bars, dataset construction method, or splits, which is load-bearing because the central claim of superior performance cannot be assessed or reproduced from the given information.
- [UILoop paradigm] UILoop paradigm (method section): The cyclic Screen-UI-Action process contains no described recovery mechanism, verification step, confidence thresholding, or backtracking for errors in UI localization or semantic assignment. This directly undermines the claim of improved accuracy and interpretability, as localization failures propagate unchecked into the Action step and may create new failure modes on ambiguous or dynamic UIs.
minor comments (1)
- [Abstract] Abstract: The three evaluation metrics for the new UI Comprehension task are named but not defined or motivated, which reduces clarity even if they are detailed later.
Simulated Author's Rebuttal
We sincerely thank the referee for their thorough and constructive review of our manuscript. Their comments identify key areas for improving clarity and robustness, and we address each point below with specific responses and planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion of state-of-the-art results on UI understanding and GUI reasoning supplies no experimental details, baselines, error bars, dataset construction method, or splits, which is load-bearing because the central claim of superior performance cannot be assessed or reproduced from the given information.
Authors: We agree that the abstract's brevity limits inclusion of full experimental details, which are essential for assessing the central claims. The full manuscript details the UI Comprehension-Bench (26K samples), three metrics, baselines, dataset construction, splits, and results with error bars in Section 4. In the revised version, we will expand the abstract to include a concise statement on the benchmark scale, key baselines compared, and quantitative SOTA improvements on both tasks. This provides better context while keeping the abstract concise; complete reproducibility information remains in the experiments section. revision: partial
-
Referee: [UILoop paradigm] UILoop paradigm (method section): The cyclic Screen-UI-Action process contains no described recovery mechanism, verification step, confidence thresholding, or backtracking for errors in UI localization or semantic assignment. This directly undermines the claim of improved accuracy and interpretability, as localization failures propagate unchecked into the Action step and may create new failure modes on ambiguous or dynamic UIs.
Authors: The UILoop design prioritizes explicit UI element localization and semantic learning in the cyclic loop to reduce initial errors compared to direct screen-to-action methods, with the iteration intended to support refinement. We acknowledge that the current method description does not detail explicit recovery mechanisms such as confidence thresholding or backtracking. In the revision, we will add a dedicated paragraph in the method section discussing error propagation risks and outlining how confidence scores from the UI comprehension step can enable verification, with optional re-localization on low-confidence cases. This strengthens the interpretability claims without altering the core paradigm. revision: yes
Circularity Check
No circularity: new paradigm proposal with independent benchmark and experiments
full rationale
The paper introduces UILoop as a methodological paradigm (cyclic Screen-UI-Action process) plus a new UI Comprehension task and 26K-sample benchmark, then reports experimental results. No equations, fitted parameters renamed as predictions, or derivations appear in the provided text. Claims rest on contributed external data and SOTA comparisons rather than self-definitional loops, self-citation chains, or ansatzes smuggled from prior author work. The central argument is therefore self-contained against the new benchmark and does not reduce to its own inputs by construction.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
TEMA: Anchor the Image, Follow the Text for Multi-Modification Composed Image Retrieval
TEMA is the first framework for multi-modification composed image retrieval, using entity mapping to improve accuracy on both new complex datasets and existing benchmarks while balancing efficiency.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.