Are Stochastic Multi-objective Bandits Harder than Single-objective Bandits?
Pith reviewed 2026-05-10 18:33 UTC · model grok-4.3
The pith
Multi-objective bandits achieve Pareto regret of O(log T / g†) with no dependence on the number of objectives d, matching single-objective scaling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
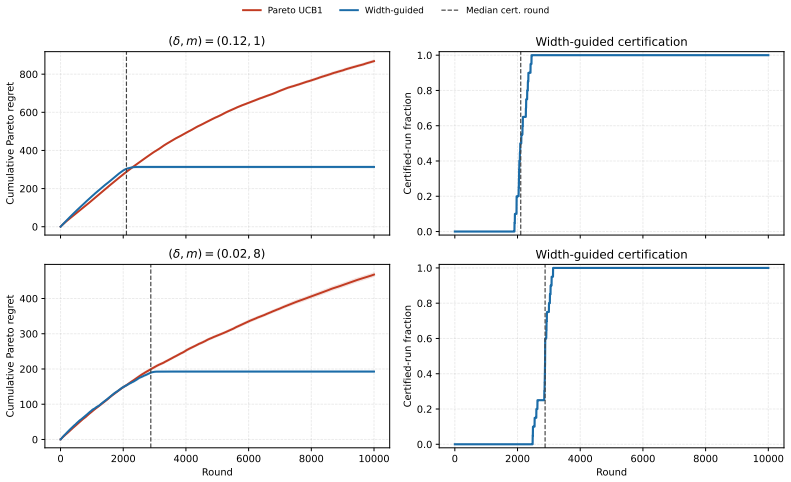
The algorithm uses upper and lower confidence-bound estimators for every arm-objective pair, top-two races to compare arms within each objective, and an uncertainty-greedy rule to allocate exploration toward the largest objective-wise gap g† until the corresponding Pareto-optimal arm is committed to. It proves Pareto regret O(log T / g†) with no dependence on d, and a matching Ω(log T / g†) lower bound establishes optimality.
What carries the argument
Top-two races per objective combined with uncertainty-greedy allocation that targets the largest objective-wise suboptimality gap g†.
If this is right
- Pareto regret can be achieved without any dependence on the number of objectives d.
- The algorithm eventually commits to one Pareto-optimal arm after finite exploration.
- Empirical evaluations on synthetic and real data achieve order-of-magnitude reductions versus baselines.
- The method may trade off empirical fairness when committing to the Pareto arm.
Where Pith is reading between the lines
- The per-objective top-two structure suggests multi-objective problems can often be decomposed into independent single-objective comparisons.
- Similar gap-driven allocation could extend to contextual or non-stationary multi-objective settings.
- The observed fairness cost when committing to a Pareto arm points to a tension between regret optimality and equitable reward distribution that single-objective bandits avoid.
Load-bearing premise
Rewards are stochastic, satisfy concentration inequalities, and there exists a strictly positive largest objective-wise gap g† > 0 that allows eventual commitment to a Pareto optimal arm.
What would settle it
A run in which the empirical Pareto regret either grows with d or fails to scale inversely with g† would falsify the claimed bound.
Figures

read the original abstract
Multi-objective bandits have attracted increasing attention for their broad applicability, with \(d\)-dimensional reward vectors inducing Pareto regret. There has been a subtle debate over whether this added structure makes the problem fundamentally harder than single-objective bandits. We answer this by showing that, in terms of Pareto regret, it is surprisingly no harder: Pareto regret scales inversely with \(g^\dagger\), the largest objective-wise suboptimality gap, and thus matches the smallest objective-wise classical regret. We formalize this idea via a novel method with upper and lower confidence-bound estimators for every arm-objective pair. It uses top-two races to compare arms within each objective and an uncertainty-greedy rule to allocate exploration toward the largest objective-wise gap \(g^\dagger\), until the corresponding Pareto-optimal arm is committed to. We prove that it achieves Pareto regret of \(O(\nicefrac{\log T}{g^\dagger})\), where \(T\) is the horizon, with \emph{no dependence on \(d\)}. A matching lower bound of \(\Omega(\nicefrac{\log T}{g^\dagger})\) implies optimality. We evaluate the method on synthetic and real-world datasets, confirming the theory and achieving order-of-magnitude reductions in Pareto regret over baselines. Real-world results further show that our method commits to a Pareto optimal arm, possibly at the cost of empirical fairness, suggesting a potential hardness absent in single-objective bandits.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that stochastic multi-objective bandits are not harder than single-objective bandits in terms of Pareto regret. It introduces an algorithm using upper/lower confidence bounds on every arm-objective pair, top-two races to compare arms per objective, and an uncertainty-greedy allocation rule that directs exploration toward the objective with the largest gap g† until a Pareto-optimal arm is committed to. The central theoretical result is an upper bound of O(log T / g†) on Pareto regret with no dependence on the number of objectives d, matched by a lower bound of Ω(log T / g†) that reduces to a single-objective instance on the critical objective while preserving Pareto optimality. Experiments on synthetic and real-world data are reported to confirm the bounds and show order-of-magnitude improvements over baselines, with a note on potential empirical fairness trade-offs.
Significance. If the bounds hold, the result is significant: it shows that Pareto regret can be controlled at the rate of the single hardest objective without incurring a dimension-dependent penalty, resolving a subtle debate in the literature. The proof avoids union bounds over d by focusing solely on the dominant gap g† > 0. Credit is due for the matching upper and lower bounds, the explicit algorithm design that isolates the critical objective, and the reproducible empirical validation on both synthetic and real datasets. The observation that committing to a Pareto arm may affect fairness metrics highlights a practical distinction from single-objective settings.
minor comments (3)
- The abstract and introduction refer to 'top-two races' and 'uncertainty-greedy rule' without a dedicated algorithm pseudocode block or explicit pseudocode line numbers; adding a clear Algorithm 1 box with line references would improve readability.
- Section on experiments (presumably §5 or §6) states 'order-of-magnitude reductions' but does not report exact Pareto regret values, standard deviations, or statistical significance tests against baselines; including a table with numerical results and confidence intervals would strengthen the empirical claims.
- The lower-bound construction is described as reducing to a single-objective instance; a brief remark on how the Pareto front is preserved under this reduction (e.g., via a short paragraph or footnote) would clarify the argument for readers unfamiliar with multi-objective regret definitions.
Simulated Author's Rebuttal
We thank the referee for the positive and insightful review, which recognizes the significance of showing that Pareto regret in stochastic multi-objective bandits matches the single-objective rate via dependence only on the dominant gap g†. We appreciate the acknowledgment of the algorithm design, matching bounds, and empirical validation. No major comments were raised, and we will address any minor suggestions in the revised version.
Circularity Check
No significant circularity in derivation chain
full rationale
The upper bound O(log T / g†) is obtained by applying standard concentration inequalities to the algorithm's top-two races and uncertainty-greedy allocation that focuses solely on the dominant gap g†; the proof shows that resolving this single gap suffices for committing to a Pareto-optimal arm without any union bound over d. The matching lower bound is constructed by embedding a single-objective hard instance on the critical objective while preserving Pareto optimality of the arm. No equation reduces to a fitted parameter renamed as a prediction, no self-citation supplies a load-bearing uniqueness theorem, and the d-independence follows directly from the algorithm design rather than from any self-referential definition or ansatz smuggled via prior work. The derivation is self-contained against external concentration bounds.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Rewards for each arm-objective pair are stochastic and satisfy sub-Gaussian concentration inequalities.
- domain assumption The largest objective-wise suboptimality gap g† is strictly positive.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We prove that it achieves Pareto regret of O(log T / g†), where T is the horizon, with no dependence on d. A matching lower bound of Ω(log T / g†) implies optimality.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
width-guided first-certification algorithm... top-two racing strategy... uncertainty-greedy rule for dimension selection
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Finite-time analysis of the multiarmed bandit problem
Peter Auer, Nicolo Cesa-Bianchi, and Paul Fischer. Finite-time analysis of the multiarmed bandit problem. Machine learning, 47 0 (2-3): 0 235--256, 2002 a
work page 2002
-
[2]
The nonstochastic multiarmed bandit problem
Peter Auer, Nicolo Cesa-Bianchi, Yoav Freund, and Robert E Schapire. The nonstochastic multiarmed bandit problem. SIAM Journal on Computing, 32 0 (1): 0 48--77, 2002 b
work page 2002
-
[3]
Multi-objective bandits: Optimizing the generalized G ini index
R \'o bert Busa-Fekete, Bal \'a zs Sz \"o r \'e nyi, Paul Weng, and Shie Mannor. Multi-objective bandits: Optimizing the generalized G ini index. In International Conference on Machine Learning, pages 625--634. Proceedings of Machine Learning Research, 2017
work page 2017
-
[4]
Multi-objective neural bandits with random scalarization
Ji Cheng, Bo Xue, Chengyu Lu, Ziqiang Cui, and Qingfu Zhang. Multi-objective neural bandits with random scalarization. In Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence, pages 4914--4922, 2025
work page 2025
-
[5]
Offline multi-objective bandits: From logged data to pareto-optimal policies
Ji Cheng, Song Lai, Shunyu Yao, and Bo Xue. Offline multi-objective bandits: From logged data to pareto-optimal policies. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 36636--36644, 2026
work page 2026
-
[6]
Designing multi-objective multi-armed bandits algorithms: A study
Madalina M Drugan and Ann Nowe. Designing multi-objective multi-armed bandits algorithms: A study. In The 2013 international joint conference on neural networks (IJCNN), pages 1--8. IEEE, 2013
work page 2013
-
[7]
Pareto upper confidence bounds algorithms: an empirical study
M a d a lina M Drugan, Ann Now \'e , and Bernard Manderick. Pareto upper confidence bounds algorithms: an empirical study. In 2014 IEEE Symposium on Adaptive Dynamic Programming and Reinforcement Learning, pages 1--8. IEEE, 2014
work page 2014
-
[8]
Multiobjective optimization under uncertainty: A multiobjective robust (relative) regret approach
Patrick Groetzner and Ralf Werner. Multiobjective optimization under uncertainty: A multiobjective robust (relative) regret approach. European Journal of Operational Research, 296 0 (1): 0 101--115, 2022
work page 2022
-
[9]
Evolutionary computation for large-scale multi-objective optimization: A decade of progresses
Wen-Jing Hong, Peng Yang, and Ke Tang. Evolutionary computation for large-scale multi-objective optimization: A decade of progresses. International Journal of Automation and Computing, 18 0 (2): 0 155--169, 2021
work page 2021
-
[10]
Direct preference-based evolutionary multi-objective optimization with dueling bandits
Tian Huang, Shengbo Wang, and Ke Li. Direct preference-based evolutionary multi-objective optimization with dueling bandits. Advances in Neural Information Processing Systems, 37: 0 122206--122258, 2024
work page 2024
-
[11]
Multi-objective multi-armed bandit with lexicographically ordered and satisficing objectives
Alihan H \"u y \"u k and Cem Tekin. Multi-objective multi-armed bandit with lexicographically ordered and satisficing objectives. Machine Learning, 110 0 (6): 0 1233--1266, 2021
work page 2021
-
[12]
Asymptotically efficient adaptive allocation rules
Tze Leung Lai and Herbert Robbins. Asymptotically efficient adaptive allocation rules. Advances in applied mathematics, 6 0 (1): 0 4--22, 1985
work page 1985
-
[13]
Bandit based optimization of multiple objectives on a music streaming platform
Rishabh Mehrotra, Niannan Xue, and Mounia Lalmas. Bandit based optimization of multiple objectives on a music streaming platform. In Proceedings of the 26th ACM SIGKDD I nternational C onference on K nowledge D iscovery & D ata M ining , pages 3224--3233, 2020
work page 2020
-
[14]
Multi-objective contextual bandit problem with similarity information
Eralp Turgay, Doruk Oner, and Cem Tekin. Multi-objective contextual bandit problem with similarity information. In International Conference on Artificial Intelligence and Statistics, pages 1673--1681. PMLR, 2018
work page 2018
-
[15]
Nirandika Wanigasekara, Yuxuan Liang, Siong Thye Goh, Ye Liu, Joseph Jay Williams, and David S Rosenblum. Learning multi-objective rewards and user utility function in contextual bandits for personalized ranking. In IJCAI, volume 19, pages 3835--3841, 2019
work page 2019
-
[16]
Pareto regret analyses in multi-objective multi-armed bandit
Mengfan Xu and Diego Klabjan. Pareto regret analyses in multi-objective multi-armed bandit. In Proceedings of the 40th International Conference on Machine Learning, ICML'23, 2023
work page 2023
-
[17]
Annealing-pareto multi-objective multi-armed bandit algorithm
Saba Q Yahyaa, Madalina M Drugan, and Bernard Manderick. Annealing-pareto multi-objective multi-armed bandit algorithm. In 2014 IEEE Symposium on Adaptive Dynamic Programming and Reinforcement Learning, pages 1--8. IEEE, 2014
work page 2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.