Log-based, Business-aware REST API Testing
Pith reviewed 2026-05-10 18:09 UTC · model grok-4.3
The pith
LoBREST recovers business constraints from historical request logs to more thoroughly test complex REST API functionalities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
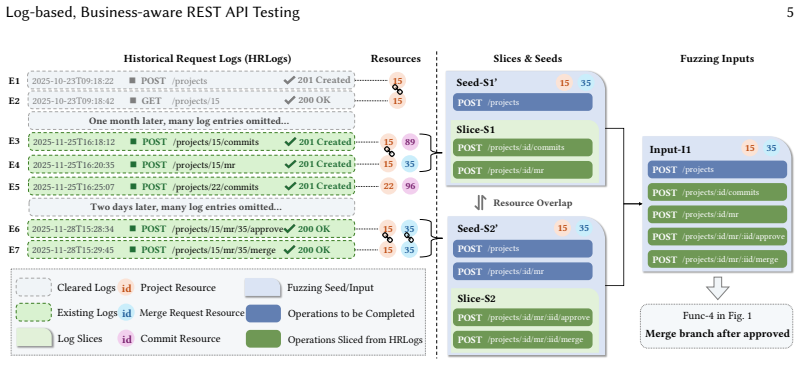
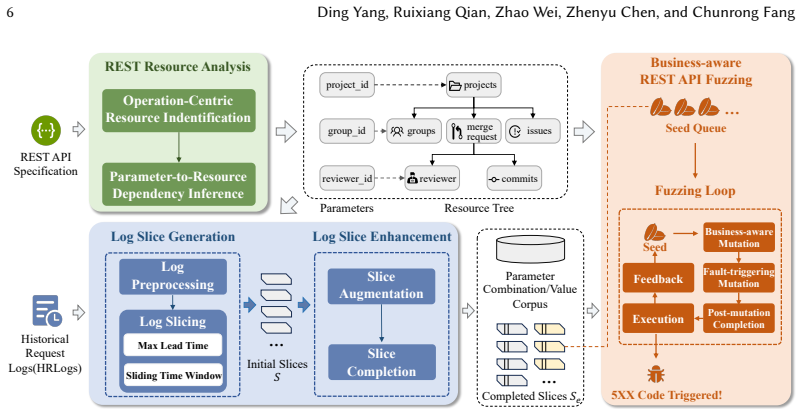
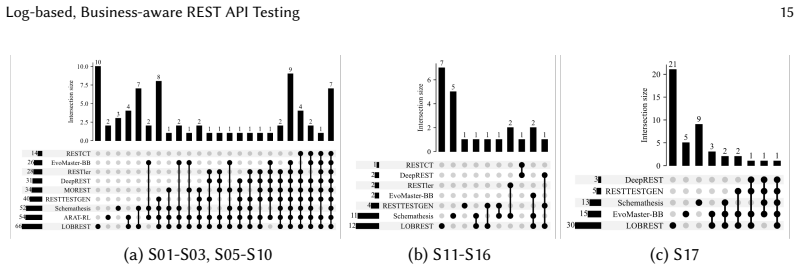
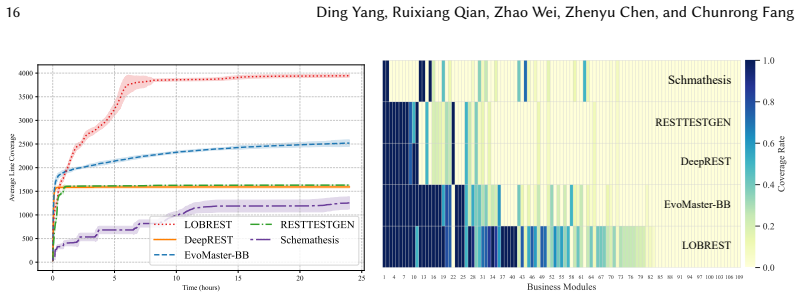
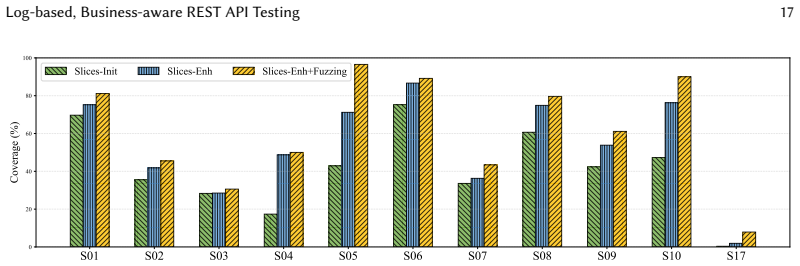
LoBREST partitions historical request logs with a locality-slicing strategy to produce compact operation sequences that preserve clean business constraints. These slices are enhanced in two steps by adding operations absent from the logs and completing missing resources inside each slice. The enhanced slices then serve as seeds for business-aware fuzzing. Across 17 real-world services the technique reached top operation coverage on 16 services and top line coverage on 15 services, delivering average gains of 2.1x and 1.2x over the next-best tool while exposing 108 5XX bugs, 38 of which no other tool found.
What carries the argument
Locality-slicing strategy that partitions historical request logs into smaller slices preserving business constraints, followed by two enhancement steps to add missing operations and complete resources, then used as seeds for business-aware fuzzing.
If this is right
- Higher operation coverage on nearly all tested services by exercising business-sensitive paths.
- Improved line coverage because the recovered constraints drive execution into deeper code regions.
- Detection of more 5XX server errors, including bugs invisible to specification-only methods.
- Effective testing of complex microservice interactions that standard OpenAPI documents omit.
Where Pith is reading between the lines
- Organizations may need to treat historical request logs as first-class artifacts worth systematic collection and curation.
- The same slicing-plus-enhancement pattern could be adapted to generate tests for GraphQL or gRPC endpoints that also embed business rules.
- A hybrid system that seeds fuzzing from both logs and specifications might close remaining gaps in simple and complex functionalities alike.
- The enhancement steps point toward general methods for completing partial execution traces in other testing domains.
Load-bearing premise
Historical request logs contain representative, clean, and sufficiently complete business constraints that locality slicing plus the two enhancement steps can recover without introducing bias or incompleteness.
What would settle it
Apply LoBREST to a service whose historical logs are known to be sparse or biased and check whether its coverage and 5XX bug count fall below those of the compared specification-based and log-based tools.
Figures

read the original abstract
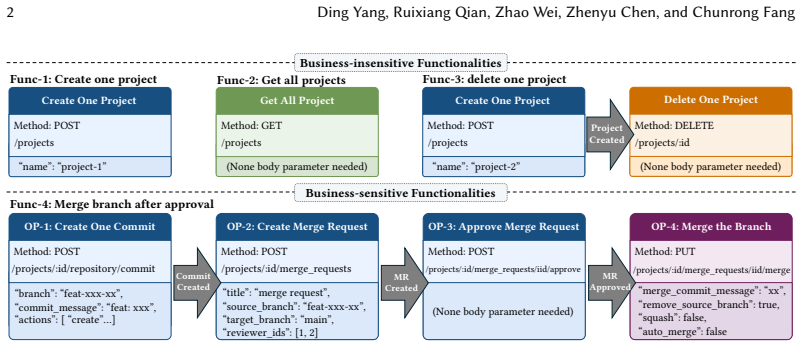
REST APIs enable collaboration among microservices. A single fault in a REST API can bring down the entire microservice system and cause significant financial losses, underscoring the importance of REST API testing. Effectively testing REST APIs requires thoroughly exercising the functionalities behind them. To this end, existing techniques leverage REST specifications (e.g., Swagger or OpenAPI) to generate test cases. Using the resource constraints extracted from specifications, these techniques work well for testing simple, business-insensitive functionalities, such as resource creation, retrieval, update, and deletion. However, for complex, business-sensitive functionalities, these specification-based techniques often fall short, since exercising such functionalities requires additional business constraints that are typically absent from REST specifications. In this paper, we present LoBREST, a log-based, business-aware REST API testing technique that leverages historical request logs (HRLogs) to effectively exercise the business-sensitive functionalities behind REST APIs. To obtain compact operation sequences that preserve clean and complete business constraints, LoBREST first employs a locality-slicing strategy to partition HRLogs into smaller slices. Then, to ensure the effectiveness of the obtained slices, LoBREST enhances them in two steps: (1) adding slices for operations missing from HRLogs, and (2) completing missing resources within the slices. Finally, to improve test adequacy, LoBREST uses these enhanced slices as initial seeds to perform business-aware fuzzing. LoBREST outperformed eight tools (including Arat-rl, Morest, and Deeprest) across 17 real-world services. It achieved top operation coverage on 16 services and line coverage on 15, averaging 2.1x and 1.2x improvements over the runner-up. LoBREST detected 108 5XX bugs, including 38 found by no other tool.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LoBREST, a log-based technique for testing REST APIs that extracts business constraints from historical request logs (HRLogs) via a locality-slicing strategy to produce compact operation sequences, followed by two enhancement steps (adding slices for missing operations and completing missing resources within slices). These enhanced slices serve as seeds for business-aware fuzzing. The evaluation on 17 real-world services claims that LoBREST outperforms eight tools (including Arat-rl, Morest, and Deeprest), achieving top operation coverage on 16 services and top line coverage on 15, with average improvements of 2.1x and 1.2x over the runner-up, while detecting 108 5XX bugs including 38 found by no other tool.
Significance. If the empirical results hold under rigorous controls, this work addresses a genuine gap in REST API testing by targeting business-sensitive functionalities absent from specifications, using real-world logs as a source of constraints. The scale of the evaluation (17 services, multiple baselines) and the focus on unique bug detection represent strengths that could improve reliability in microservice systems, provided the log representativeness assumption is validated.
major comments (3)
- [Abstract and Evaluation] The abstract and evaluation report 108 5XX bugs and 38 unique detections but provide no details on validation as true positives, false positive rates, or how bugs were confirmed (e.g., via manual inspection or reproduction). This is load-bearing for the central claim of superior bug-finding ability.
- [Approach (locality slicing and enhancement)] The locality-slicing strategy (§3.2) is claimed to yield slices that preserve clean and complete business constraints, yet no quantitative metrics are reported on original log coverage, inter-slice dependency loss, or post-enhancement validity checks. This directly impacts the weakest assumption that HRLogs contain representative constraints recoverable without bias or incompleteness.
- [Evaluation] The experimental comparison claims 2.1x and 1.2x average improvements but omits details on controls such as number of runs, random seeds for fuzzing, statistical significance tests, or whether baselines received equivalent log-derived information. This undermines confidence in the coverage and bug-detection superiority.
minor comments (2)
- [Approach] The description of the two enhancement steps could include pseudocode or a small illustrative example to clarify how missing operations and resources are added without introducing new constraints.
- [Evaluation] Table or figure captions for coverage results should explicitly state the number of runs and any variance measures to aid interpretation of the reported averages.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which helps strengthen the presentation of our claims on bug detection validity, the slicing approach, and experimental controls. We address each major comment below and have revised the manuscript to provide the requested details and clarifications.
read point-by-point responses
-
Referee: [Abstract and Evaluation] The abstract and evaluation report 108 5XX bugs and 38 unique detections but provide no details on validation as true positives, false positive rates, or how bugs were confirmed (e.g., via manual inspection or reproduction). This is load-bearing for the central claim of superior bug-finding ability.
Authors: We agree that explicit validation details are essential. In the revised manuscript, we have added a new subsection (Section 5.4) describing the bug confirmation process: every reported 5XX response was reproduced by replaying the exact test case against the live service; a random sample of 20% of the bugs (including all 38 unique ones) underwent manual inspection of server logs and request payloads to confirm they stemmed from business logic violations rather than transient network or configuration issues. No false positives were observed in this process, as all 5XX errors indicated server-side failures. This addition directly supports the bug-finding claims. revision: yes
-
Referee: [Approach (locality slicing and enhancement)] The locality-slicing strategy (§3.2) is claimed to yield slices that preserve clean and complete business constraints, yet no quantitative metrics are reported on original log coverage, inter-slice dependency loss, or post-enhancement validity checks. This directly impacts the weakest assumption that HRLogs contain representative constraints recoverable without bias or incompleteness.
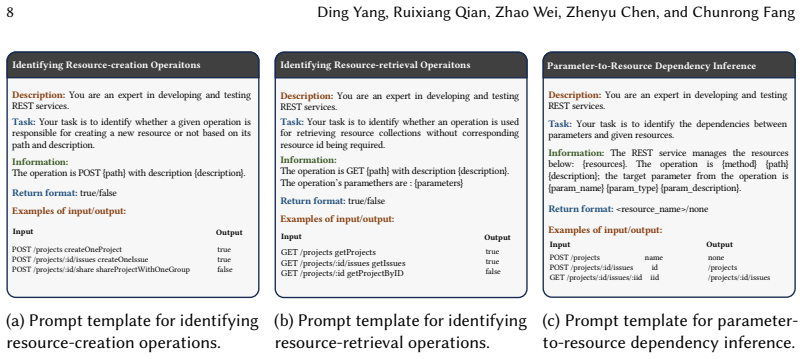
Authors: The locality-slicing approach groups requests by shared resource identifiers and temporal proximity to retain business flows. While the original submission focused on the design rationale, we acknowledge the value of quantitative support. The revised Section 3.2 now includes metrics computed on the 17 services: slices cover 92% of original log operations on average, with inter-slice dependency loss below 8% (measured via resource-dependency graphs extracted from logs); post-enhancement validity checks (syntactic and semantic) reject fewer than 3% of slices. These numbers provide evidence that representative constraints are recoverable with limited bias. revision: yes
-
Referee: [Evaluation] The experimental comparison claims 2.1x and 1.2x average improvements but omits details on controls such as number of runs, random seeds for fuzzing, statistical significance tests, or whether baselines received equivalent log-derived information. This undermines confidence in the coverage and bug-detection superiority.
Authors: We have expanded the evaluation section (Section 5.1) with the missing controls: all tools were run under identical time budgets (2 hours per service) and request limits; LoBREST's fuzzing used 10 independent runs with distinct random seeds (reported averages and standard deviations); statistical significance was assessed via Wilcoxon rank-sum tests (p < 0.05 for coverage gains on 15+ services). Baselines are purely specification-based and received no log-derived information—this is intentional, as the comparison highlights the benefit of log-based business constraints over spec-only methods. These details are now explicitly stated. revision: yes
Circularity Check
No circularity; empirical evaluation on external services
full rationale
The paper proposes LoBREST as a technique that slices historical request logs, enhances the slices by adding missing operations and completing resources, then uses them as seeds for business-aware fuzzing. All reported results (operation/line coverage on 16/15 of 17 services, 108 5XX bugs with 38 unique) come from direct execution against real-world services. No equations, fitted parameters, self-definitional reductions, or load-bearing self-citations appear in the derivation. The method's effectiveness is treated as an empirical outcome rather than a quantity forced by construction from its inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Historical request logs contain representative business constraints for complex functionalities
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
LoBREST first employs a locality-slicing strategy to partition HRLogs into smaller slices... uses these enhanced slices as initial seeds to perform business-aware fuzzing.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
To obtain compact operation sequences that preserve clean and complete business constraints
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
In30th USENIX Security Symposium (USENIX Security 21)(2021), pp
Aafer, Y., You, W., Sun, Y., Shi, Y., Zhang, X., and Yin, H.Android {SmartTVs} vulnerability discovery via {log-guided}fuzzing. In30th USENIX Security Symposium (USENIX Security 21)(2021), pp. 2759–2776
work page 2021
-
[2]
https://docs.aws.amazon.com/apigateway/latest/developerguide/ apigateway-rest-api.html, 2025
Amazon Web Services, I.Amazon api gateway. https://docs.aws.amazon.com/apigateway/latest/developerguide/ apigateway-rest-api.html, 2025
work page 2025
-
[3]
Ampatzoglou, A., Bibi, S., Avgeriou, P., Verbeek, M., and Chatzigeorgiou, A.Identifying, categorizing and mitigating threats to validity in software engineering secondary studies.Information and software technology 106 (2019), 201–230
work page 2019
-
[4]
H.Testing using log file analysis: tools, methods, and issues
Andrews, J. H.Testing using log file analysis: tools, methods, and issues. InProceedings 13th IEEE International Conference on Automated Software Engineering (Cat. No. 98EX239)(1998), IEEE, pp. 157–166
work page 1998
-
[5]
Andrews, J. H., and Zhang, Y.General test result checking with log file analysis.IEEE Transactions on Software Engineering 29, 7 (2003), 634–648
work page 2003
-
[6]
Arcuri, A.Restful api automated test case generation with evomaster.ACM Transactions on Software Engineering and Methodology (TOSEM) 28, 1 (2019), 1–37
work page 2019
-
[7]
P., Marculescu, B., and Zhang, M.Evomaster: A search-based system test generation tool
Arcuri, A., Galeotti, J. P., Marculescu, B., and Zhang, M.Evomaster: A search-based system test generation tool. Journal of Open Source Software(2021)
work page 2021
-
[8]
In2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE)(2019), IEEE, pp
Atlidakis, V., Godefroid, P., and Polishchuk, M.Restler: Stateful rest api fuzzing. In2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE)(2019), IEEE, pp. 748–758. [9]Berners-Lee, T., Fielding, R., and Frystyk, H.Hypertext transfer protocol–http/1.0. Tech. rep., 1996
work page 2019
-
[9]
Böhme, M., Pham, V.-T., Nguyen, M.-D., and Roychoudhury, A.Directed greybox fuzzing. InProceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security (CCS’17)(2017), pp. 2329–2344
work page 2017
-
[10]
InProceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security(2016), pp
Böhme, M., Pham, V.-T., and Roychoudhury, A.Coverage-based greybox fuzzing as markov chain. InProceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security(2016), pp. 1032–1043
work page 2016
-
[11]
Corradini, D., Montolli, Z., Pasqa, M., and Ceccato, M.Deeprest: Automated test case generation for rest apis exploiting deep reinforcement learning. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering(2024), pp. 1383–1394
work page 2024
-
[12]
In2025 IEEE Conference on Software Testing, Verification and Validation (ICST)(2025), IEEE, pp
Corradini, D., Pasqa, M., and Ceccato, M.Restgym: A flexible infrastructure for empirical assessment of automated rest api testing tools. In2025 IEEE Conference on Software Testing, Verification and Validation (ICST)(2025), IEEE, pp. 757–761. [14]F5, I.Nginx. https://nginx.org/, 2025
work page 2025
-
[13]
T.Architectural styles and the design of network-based software architectures
Fielding, R. T.Architectural styles and the design of network-based software architectures. University of California, Irvine, 2000. [16]Google. Google for developers. https://developers.google.com/workspace/drive/api/reference/rest/v3, 2025
work page 2000
-
[14]
Hatfield-Dodds, Z., and Dygalo, D.Deriving semantics-aware fuzzers from web api schemas. InProceedings of the ACM/IEEE 44th International Conference on Software Engineering: Companion Proceedings(2022), pp. 345–346
work page 2022
-
[15]
R.A survey on automated log analysis for reliability engineering
He, S., He, P., Chen, Z., Y ang, T., Su, Y., and Lyu, M. R.A survey on automated log analysis for reliability engineering. ACM computing surveys (CSUR) 54, 6 (2021), 1–37. [19]Initiative, O.Openapi. https://www.openapis.org, 2025
work page 2021
-
[16]
Karlsson, S., Čaušević, A., and Sundmark, D.Quickrest: Property-based test generation of openapi-described restful apis. In2020 IEEE 13th International Conference on Software Testing, Validation and Verification (ICST)(2020), IEEE, pp. 131–141
work page 2020
-
[17]
Kim, M., Sinha, S., and Orso, A.Adaptive rest api testing with reinforcement learning. In2023 38th IEEE/ACM International Conference on Automated Software Engineering (ASE)(2023), IEEE, pp. 446–458
work page 2023
-
[18]
Kim, M., Sinha, S., and Orso, A.Llamaresttest: Effective rest api testing with small language models.Proceedings of the ACM on Software Engineering 2, FSE (2025), 465–488
work page 2025
-
[19]
Kim, M., Xin, Q., Sinha, S., and Orso, A.Automated test generation for rest apis: No time to rest yet. InProceedings of the 31st ACM SIGSOFT International Symposium on Software Testing and Analysis(2022), pp. 289–301
work page 2022
-
[20]
InProceedings of the 2018 ACM SIGSAC conference on computer and communications security(2018), pp
Klees, G., Ruef, A., Cooper, B., Wei, S., and Hicks, M.Evaluating fuzz testing. InProceedings of the 2018 ACM SIGSAC conference on computer and communications security(2018), pp. 2123–2138
work page 2018
-
[21]
InProceedings of the 44th International Conference on Software Engineering(2022), pp
Liu, Y., Li, Y., Deng, G., Liu, Y., W an, R., Wu, R., Ji, D., Xu, S., and Bao, M.Morest: Model-based restful api testing with execution feedback. InProceedings of the 44th International Conference on Software Engineering(2022), pp. 1406–1417
work page 2022
-
[22]
Manès, V. J., Han, H., Han, C., Cha, S. K., Egele, M., Schwartz, E. J., and Woo, M.The art, science, and engineering of fuzzing: A survey.IEEE Transactions on Software Engineering 47, 11 (2019), 2312–2331. , Vol. 1, No. 1, Article . Publication date: April 2026. 20 Ding Yang, Ruixiang Qian, Zhao Wei, Zhenyu Chen, and Chunrong Fang [27]Masse, M.REST API de...
work page 2019
-
[23]
C.Log-based slicing for system-level test cases
Messaoudi, S., Shin, D., Panichella, A., Bianculli, D., and Briand, L. C.Log-based slicing for system-level test cases. InProceedings of the 30th ACM SIGSOFT international symposium on software testing and analysis(2021), pp. 517–528
work page 2021
-
[24]
Miller, B. P., Fredriksen, L., and So, B.An empirical study of the reliability of unix utilities.Communications of the ACM 33, 12 (1990), 32–44. [30]Newman, S.Building microservices: designing fine-grained systems. O’Reilly Media, Inc., 2021
work page 1990
-
[25]
" big"’web services: making the right architectural decision
Pautasso, C., Zimmermann, O., and Leymann, F.Restful web services vs. " big"’web services: making the right architectural decision. InProceedings of the 17th international conference on World Wide Web(2008), pp. 805–814. [32]Postman. 2025 state of the api report. https://www.postman.com/state-of-api/2025, 2025
work page 2008
-
[26]
Qian, R., Zhang, Q., Fang, C., Guo, L., and Chen, Z.Funfuzz: Greybox fuzzing with function significance.ACM Transactions on Software Engineering and Methodology 34, 4 (2025), 1–34
work page 2025
-
[27]
Qian, R., Zhang, Q., Fang, C., Yang, D., Li, S., Li, B., and Chen, Z.Dipri: Distance-based seed prioritization for greybox fuzzing.ACM Transactions on Software Engineering and Methodology 34, 1 (2024), 1–39
work page 2024
-
[28]
G.Cloud microservices market size, share & analysis 2035 report
Report, M. G.Cloud microservices market size, share & analysis 2035 report. https://www.marketgrowthreports.com/ market-reports/cloud-microservices-market-106525, 2025
work page 2035
-
[29]
U., Ahmed, N., and Yong, L.Quality assurance of web services: A systematic literature review
Saleem, G., Azam, F., Younus, M. U., Ahmed, N., and Yong, L.Quality assurance of web services: A systematic literature review. In2016 2nd IEEE International Conference on Computer and Communications (ICCC)(2016), IEEE, pp. 1391–1396. [37]Schloegel, M., Bars, N., Schiller, N., Bernhard, L., Scharnowski, T., Crump, A., Ale-Ebrahim, A., Bissantz, N., Muench,...
work page 2016
-
[30]
Viglianisi, E., Dallago, M., and Ceccato, M.Resttestgen: automated black-box testing of restful apis. In2020 IEEE 13th International Conference on Software Testing, Validation and Verification (ICST)(2020), IEEE, pp. 142–152
work page 2020
-
[31]
Wu, F., Luo, Z., Zhao, Y., Du, Q., Yu, J., Peng, R., Shi, H., and Jiang, Y.Logos: Log guided fuzzing for protocol implementations. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis (2024), pp. 1720–1732
work page 2024
-
[32]
InProceedings of the 44th International Conference on Software Engineering(2022), pp
Wu, H., Xu, L., Niu, X., and Nie, C.Combinatorial testing of restful apis. InProceedings of the 44th International Conference on Software Engineering(2022), pp. 426–437
work page 2022
-
[33]
Zhang, M., and Arcuri, A.Open problems in fuzzing restful apis: A comparison of tools.ACM Transactions on Software Engineering and Methodology 32, 6 (2023), 1–45
work page 2023
-
[34]
Zhu, X., Wen, S., Camtepe, S., and Xiang, Y.Fuzzing: a survey for roadmap.ACM Computing Surveys (CSUR) 54, 11s (2022), 1–36. , Vol. 1, No. 1, Article . Publication date: April 2026
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.