Bag of Bags: Adaptive Visual Vocabularies for Genizah Join Image Retrieval
Pith reviewed 2026-05-10 18:16 UTC · model grok-4.3
The pith
Manuscript join retrieval improves when each fragment image builds its own visual vocabulary instead of sharing one global codebook.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
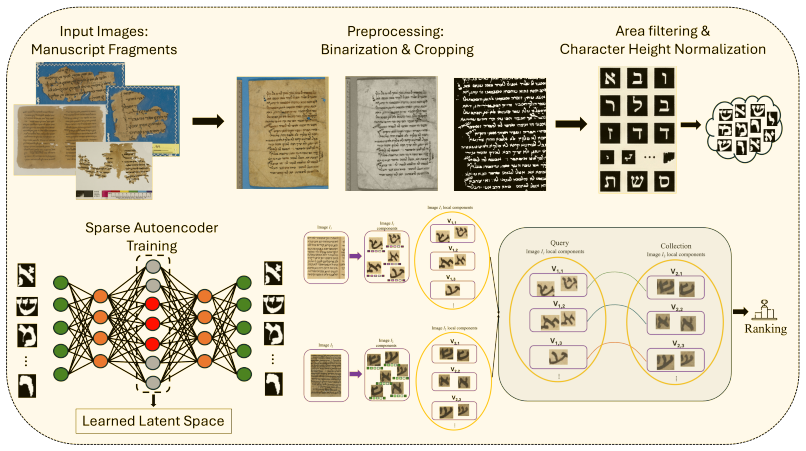
Bag of Bags replaces the global-level visual codebook of classical Bag of Words with a fragment-specific vocabulary of local visual words. The pipeline trains a sparse convolutional autoencoder on binarized fragment patches, encodes connected components from each page, clusters the resulting embeddings with per-image k-means, and compares images using set-to-set distances between their local vocabularies. On the Genizah test set the Chamfer variant achieves Hit@1 of 0.78 and MRR of 0.84 versus 0.74 and 0.80 for the strongest BoW baseline; a mass-weighted BoB-OT variant supplies a formal approximation guarantee bounding its deviation from full component-level optimal transport.
What carries the argument
Bag of Bags, the per-image vocabulary obtained by k-means clustering of autoencoder embeddings of connected-component patches, compared by set-to-set distances such as Chamfer or optimal transport.
Load-bearing premise
Binarized connected-component patches clustered separately per image capture the identity of the original manuscript rather than imaging artifacts or noise.
What would settle it
Performance would not rise, or would fall, when the same pipeline is run on a second collection of manuscript fragments whose joins have been verified independently by scholars.
Figures

read the original abstract
A join is a set of manuscript fragments identified as originally emanating from the same manuscript. We study manuscript join retrieval: Given a query image of a fragment, retrieve other fragments originating from the same physical manuscript. We propose Bag of Bags (BoB), an image-level representation that replaces the global-level visual codebook of classical Bag of Words (BoW) with a fragment-specific vocabulary of local visual words. Our pipeline trains a sparse convolutional autoencoder on binarized fragment patches, encodes connected components from each page, clusters the resulting embeddings with per-image k-means, and compares images using set-to-set distances between their local vocabularies. Evaluated on fragments from the Cairo Genizah, the best BoB variant (viz. Chamfer) achieves Hit@1 of 0.78 and MRR of 0.84, compared to 0.74 and 0.80, respectively, for the strongest BoW baseline (BoW-RawPatches-$\chi^2$), a 6.1% relative improvement in top-1 accuracy. We furthermore study a mass-weighted BoB-OT variant that incorporates cluster population into prototype matching and present a formal approximation guarantee bounding its deviation from full component-level optimal transport. A two-stage pipeline using a BoW shortlist followed by BoB-OT reranking provides a practical compromise between retrieval strength and computational cost, supporting applicability to larger manuscript collections. The code and dataset are available at https://github.com/TAU-CH/midrash_bob.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce 'Bag of Bags' (BoB), an adaptive visual vocabulary approach for retrieving joins (fragments from the same manuscript) in images from the Cairo Genizah collection. The method involves training a sparse convolutional autoencoder on binarized patches, extracting embeddings for connected components, performing per-image k-means clustering to create fragment-specific vocabularies, and using set-to-set distances (e.g., Chamfer) for comparison. It reports superior performance over Bag of Words baselines (Hit@1 of 0.78 vs. 0.74) and provides a formal approximation guarantee for a mass-weighted optimal transport variant (BoB-OT), along with a two-stage retrieval pipeline.
Significance. If validated, this work could have significance for computer vision applications in digital humanities, particularly for large-scale manuscript fragment matching where global vocabularies may not suffice. The explicit provision of code and dataset supports reproducibility, and the formal approximation guarantee for BoB-OT adds theoretical grounding to the empirical method.
major comments (2)
- [Abstract and Experimental Evaluation] The central performance claim of a 6.1% relative improvement in Hit@1 (0.78 for BoB-Chamfer vs. 0.74 for BoW-RawPatches-χ²) and MRR (0.84 vs. 0.80) is load-bearing for the paper's contribution. However, the evaluation is conducted exclusively on fragments from the Cairo Genizah collection. This raises a correctness-risk concern: the per-image k-means on autoencoder embeddings of binarized connected components may align on collection-specific imaging artifacts or binarization effects rather than scribe- or page-specific features. A concrete test to address this would be an ablation varying the binarization threshold or evaluating transfer to a different manuscript collection with distinct scanning conditions.
- [BoB-OT Approximation Guarantee] The formal approximation guarantee bounding the deviation of mass-weighted BoB-OT from full component-level optimal transport is presented as a strength. However, the manuscript should clarify in which section or theorem this bound is derived and whether it assumes specific properties of the cluster populations or embeddings that may not hold in practice for noisy manuscript images.
minor comments (2)
- In the abstract, the notation for the baseline (BoW-RawPatches-χ²) uses LaTeX that may not render consistently; consider spelling out 'chi-squared' for clarity in text.
- The two-stage pipeline is mentioned as a practical compromise, but details on how the shortlist size is chosen and its impact on overall efficiency could be expanded for better understanding.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below, indicating revisions where appropriate to improve clarity and robustness.
read point-by-point responses
-
Referee: [Abstract and Experimental Evaluation] The central performance claim of a 6.1% relative improvement in Hit@1 (0.78 for BoB-Chamfer vs. 0.74 for BoW-RawPatches-χ²) and MRR (0.84 vs. 0.80) is load-bearing for the paper's contribution. However, the evaluation is conducted exclusively on fragments from the Cairo Genizah collection. This raises a correctness-risk concern: the per-image k-means on autoencoder embeddings of binarized connected components may align on collection-specific imaging artifacts or binarization effects rather than scribe- or page-specific features. A concrete test to address this would be an ablation varying the binarization threshold or evaluating transfer to a different manuscript collection with distinct scanning conditions.
Authors: We agree that restricting evaluation to the Genizah collection introduces a risk of capturing domain-specific artifacts. We will add an ablation study varying the binarization threshold (e.g., testing thresholds around the default value) and report the resulting Hit@1 and MRR to demonstrate stability. For transfer to another collection, we lack access to comparable annotated data with different scanning conditions, but we will expand the limitations and future work sections to discuss potential domain effects and the method's design for per-fragment adaptation. This is a partial revision. revision: partial
-
Referee: [BoB-OT Approximation Guarantee] The formal approximation guarantee bounding the deviation of mass-weighted BoB-OT from full component-level optimal transport is presented as a strength. However, the manuscript should clarify in which section or theorem this bound is derived and whether it assumes specific properties of the cluster populations or embeddings that may not hold in practice for noisy manuscript images.
Authors: We apologize for the insufficient clarity. The bound is derived in Section 4.3 as Theorem 1, which shows that the mass-weighted BoB-OT distance deviates from full component-level OT by at most a term depending on the maximum cluster radius and mass imbalance. The proof assumes positive cluster masses and embeddings in a metric space but does not require noise-free data; k-means is applied to the embeddings as in the main pipeline. We will revise the manuscript to explicitly cite the section and theorem, and add a paragraph analyzing robustness to noise in binarized manuscript images. revision: yes
Circularity Check
No circularity: purely empirical claims with separate formal bound
full rationale
The paper's central results are measured retrieval metrics (Hit@1 0.78, MRR 0.84) obtained by training a sparse convolutional autoencoder on binarized patches, per-image k-means clustering, and set-to-set distance evaluation on the Genizah test set. These are direct experimental outcomes, not derived quantities that reduce to fitted parameters or self-definitions by construction. The mass-weighted BoB-OT approximation guarantee is stated as an independent formal bound on deviation from full optimal transport and is not used to justify or derive the reported performance numbers. No self-citation chains, ansatzes smuggled via prior work, or renamings of known results appear in the load-bearing steps. The pipeline is self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
free parameters (2)
- number of clusters per image in k-means
- autoencoder training hyperparameters
axioms (1)
- domain assumption Binarized patches from connected components contain sufficient visual information to distinguish manuscript identity
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Bag of Bags (BoB) ... per-image k-means ... set-to-set distances (Chamfer, Hungarian, OT) ... approximation guarantee bounding deviation from full component-level optimal transport
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
BoB-Chamfer ... mass-weighted BoB-OT ... formal approximation guarantee
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
A. A. Brink, J. Smit, M. L. Bulacu, and Lambert R. B. Schomaker. Writer identification using directional ink-trace width measurements.Pattern Recognition, 45(1):162–171,
-
[2]
Automatic hand- writing identification on medieval documents
Marius Bulacu and Lambert Schomaker. Automatic hand- writing identification on medieval documents. In14th In- ternational Conference on Image Analysis and Processing (ICIAP 2007), pages 279–284. IEEE, 2007
work page 2007
-
[3]
Writer identification using edge-based directional features
Marius Bulacu, Lambert Schomaker, and Louis Vuurpijl. Writer identification using edge-based directional features. InProceedings of the Seventh International Conference on Document Analysis and Recognition (ICDAR), pages 937– 941, 2003. 3
work page 2003
-
[4]
Writer identification using VLAD encoded contour-Zernike moments
Vincent Christlein, David Bernecker, and Elli Angelopoulou. Writer identification using VLAD encoded contour-Zernike moments. In13th International Conference on Document Analysis and Recognition (ICDAR), pages 906–910. IEEE,
-
[5]
Unsupervised feature learning for writer identifica- tion and writer retrieval
Vincent Christlein, Martin Gropp, Stefan Fiel, and Andreas Maier. Unsupervised feature learning for writer identifica- tion and writer retrieval. In14th IAPR International Confer- ence on Document Analysis and Recognition (ICDAR), pages 991–997. IEEE, 2017. 3
work page 2017
-
[6]
Shaveta Dargan and Munish Kumar. Writer identification system for Indic and non-Indic scripts: State-of-the-art sur- vey.Archives of Computational Methods in Engineering, 26 (4):1283–1311, 2019. 3
work page 2019
-
[7]
Local binary pattern for word spotting in hand- written historical document
Sounak Dey, Anguelos Nicolaou, Josep Llados, and Uma- pada Pal. Local binary pattern for word spotting in hand- written historical document. InStructural, Syntactic, and Statistical Pattern Recognition, pages 574–583, Cham, 2016. Springer International Publishing. 2
work page 2016
-
[8]
Spot it! Find- ing words and patterns in historical documents
Vladislavs Dovgalecs, Alexandre Burnett, Pierrick Tra- nouez, St´ephane Nicolas, and Laurent Heutte. Spot it! Find- ing words and patterns in historical documents. In12th Inter- national Conference on Document Analysis and Recognition (DAR), pages 1039–1043, 2013. 2
work page 2013
-
[9]
Writer retrieval and writer identification using local features
Stefan Fiel and Robert Sablatnig. Writer retrieval and writer identification using local features. In10th IAPR Inter- national Workshop on Document Analysis Systems (DAS), pages 145–149. IEEE, 2012. 3
work page 2012
-
[10]
Writer identification and writer retrieval using the Fisher vector on visual vocabular- ies
Stefan Fiel and Robert Sablatnig. Writer identification and writer retrieval using the Fisher vector on visual vocabular- ies. In12th International Conference on Document Analysis and Recognition (ICDAR), pages 545–549. IEEE, 2013. 3
work page 2013
-
[11]
R ´emi Flamary, Nicolas Courty, Alexandre Gramfort, Mokhtar Z. Alaya, Aur ´elie Boisbunon, Stanislas Cham- bon, Laetitia Chapel, Adrien Corenflos, Kilian Fatras, Nemo Fournier, L´eo Gautheron, Nathalie T. H. Gayraud, Hicham Janati, Alain Rakotomamonjy, Ievgen Redko, Antoine Rolet, Antony Schutz, Vivien Seguy, Danica J. Sutherland, Romain Tavenard, Alexand...
work page 2021
-
[12]
Samuel Grieggs, C. E. M. Henderson, Sebastian Sobecki, Alexandra Gillespie, and Walter Scheirer. The paleogra- pher’s eye ex machina: Using computer vision to assist hu- manists in scribal hand identification. InIEEE/CVF Win- ter Conference on Applications of Computer Vision (WACV), pages 7216–7225, 2024. 3
work page 2024
-
[13]
Combining local features for offline writer identification
Rajiv Jain and David Doermann. Combining local features for offline writer identification. In14th International Confer- ence on Frontiers in Handwriting Recognition, pages 583–
-
[14]
Heidi G. Lerner and Seth Jerchower. The Penn/Cambridge Genizah fragment project: Issues in description, access, and reunification.Cataloging & Classification Quarterly, 42(1): 21–39, 2006. 2
work page 2006
-
[15]
A novel earth mover’s distance methodology for image matching with Gaussian mixture models
Peihua Li, Qilong Wang, and Lei Zhang. A novel earth mover’s distance methodology for image matching with Gaussian mixture models. InIEEE International Conference on Computer Vision, pages 1689–1696, 2013. 2
work page 2013
-
[16]
Stylistic similarities in Greek papyri based on letter shapes: A deep learning approach
Isabelle Marthot-Santaniello, Manh Tu Vu, Olga Serbaeva, and Marie Beurton-Aimar. Stylistic similarities in Greek papyri based on letter shapes: A deep learning approach. InProceedings of the Document Analysis and Recognition Workshop (DAR), pages 307–323, Berlin, Heidelberg, 2023. Springer-Verlag. 2
work page 2023
-
[17]
Yossi Rubner, Carlo Tomasi, and Leonidas J. Guibas. The earth mover’s distance as a metric for image retrieval.Inter- national Journal of Computer Vision, 40(2):99–121, 2000. 2
work page 2000
-
[18]
Ravi Shekhar and C. V . Jawahar. Word image retrieval using bag of visual words. In10th IAPR International Workshop on Document Analysis Systems (DAS), pages 297–301, 2012. 2
work page 2012
-
[19]
Video Google: A text retrieval approach to object matching in videos
Josef Sivic and Andrew Zisserman. Video Google: A text retrieval approach to object matching in videos. InProceed- ings Ninth IEEE International Conference on Computer Vi- sion, pages 1470–1477 vol.2, 2003. 2
work page 2003
-
[20]
Assembling frag- ments of ancient papyrus via artificial intelligence
Eugenio V ocaturo and Ester Zumpano. Assembling frag- ments of ancient papyrus via artificial intelligence. InPer- vasive Knowledge and Collective Intelligence on Web and Social Media, pages 3–13, Cham, 2023. Springer Nature. 2
work page 2023
-
[21]
Lior Wolf, Rotem Littman, Naama Mayer, Tanya German, Nachum Dershowitz, Roni Shweka, and Yaacov Choueka. Identifying join candidates in the Cairo Genizah.Interna- tional Journal of Computer Vision, 94(1):118–135, 2011. 2
work page 2011
-
[22]
Text-independent writer identification using SIFT descriptor and contour-directional feature
Yu-Jie Xiong, Ying Wen, Patrick SP Wang, and Yue Lu. Text-independent writer identification using SIFT descriptor and contour-directional feature. In13th International Con- ference on Document Analysis and Recognition (ICDAR), pages 91–95. IEEE, 2015. 3 9
work page 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.