Identification and Anonymization of Named Entities in Unstructured Information Sources for Use in Social Engineering Detection
Pith reviewed 2026-05-10 17:52 UTC · model grok-4.3
The pith
A pipeline collects Telegram data, transcribes audio with Parakeet, and applies custom NER to identify and anonymize sensitive entities for legal cybercrime research.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
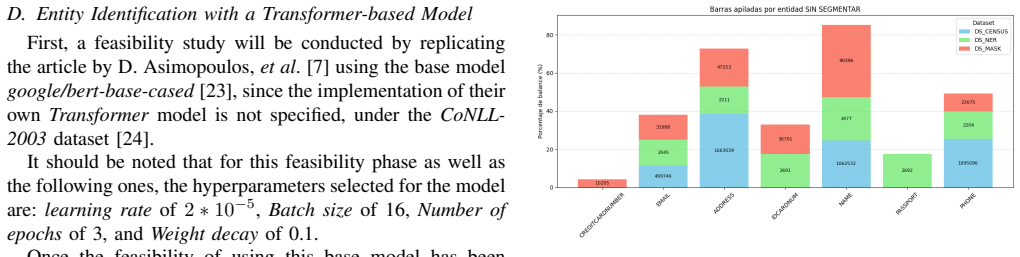
The authors propose and test a workflow that collects multimodal data from the Telegram platform, transcribes audio using Parakeet, and applies named entity recognition solutions—both Microsoft Presidio and custom transformer architectures—to detect and anonymize sensitive information. Their NER approaches attain the highest F1-score values, and they introduce metrics that verify the retention of structural coherence in the anonymized outputs, thereby enabling legal and ethical cybersecurity research.
What carries the argument
Transformer-based NER models paired with Microsoft Presidio for detecting and masking named entities, integrated with Parakeet for audio transcription, to support anonymization of unstructured Telegram sources.
Load-bearing premise
The NER models will correctly identify all relevant sensitive named entities in varied Telegram content without missing critical items or removing so much context that the data loses utility for social engineering detection.
What would settle it
A manual review of held-out Telegram messages in which human annotators find either missed sensitive entities or loss of structural elements required to recognize attack patterns.
Figures

read the original abstract
This study addresses the challenge of creating datasets for cybercrime analysis while complying with the requirements of regulations such as the General Data Protection Regulation (GDPR) and Organic Law 10/1995 of the Penal Code. To this end, a system is proposed for collecting information from the Telegram platform, including text, audio, and images; the implementation of speech-to-text transcription models incorporating signal enhancement techniques; and the evaluation of different Named Entity Recognition (NER) solutions, including Microsoft Presidio and AI models designed using a transformer-based architecture. Experimental results indicate that Parakeet achieves the best performance in audio transcription, while the proposed NER solutions achieve the highest f1-score values in detecting sensitive information. In addition, anonymization metrics are presented that allow evaluation of the preservation of structural coherence in the data, while simultaneously guaranteeing the protection of personal information and supporting cybersecurity research within the current legal framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a data collection and processing pipeline for Telegram-sourced unstructured information (text, audio, images) to enable social engineering detection research while remaining compliant with GDPR and Spanish penal code requirements. The pipeline incorporates speech-to-text transcription with signal enhancement (Parakeet reported as best-performing), Named Entity Recognition for sensitive entities using Microsoft Presidio and custom transformer-based models (proposed solutions reported as highest F1), and anonymization steps evaluated via structural coherence metrics that aim to preserve utility for downstream analysis.
Significance. If the performance claims hold under full experimental scrutiny, the work would offer a concrete, legally grounded framework for generating privacy-compliant datasets from real-world messaging platforms, directly supporting cybersecurity research on social engineering. Credit is given for the end-to-end integration of transcription, NER, and anonymization components, the use of established baselines such as Presidio, and explicit discussion of domain-specific difficulties including slang and context-dependent sensitivity.
major comments (1)
- [Abstract and Experimental Results] Abstract and Experimental Results section: the claims that Parakeet achieves the best transcription performance and that the proposed NER solutions attain the highest F1 scores are presented without any description of the underlying datasets (size, source channels, annotation process), training/validation/test splits, exact model architectures or fine-tuning procedures, baseline implementations, or statistical measures such as error bars or significance tests. This absence is load-bearing because the central contribution rests on these comparative performance assertions.
minor comments (3)
- [Methods] The description of signal enhancement techniques in the transcription pipeline would benefit from explicit references to the algorithms or libraries employed.
- [Anonymization Evaluation] Anonymization metrics for structural coherence are mentioned but lack concrete formulas, pseudocode, or worked examples showing how they are computed from the processed data.
- [Throughout] Ensure all figures and tables are explicitly referenced in the text and include self-contained captions that allow interpretation without the main body.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We agree that additional experimental details are necessary to support the performance claims and will revise the manuscript accordingly to enable proper scrutiny of the results.
read point-by-point responses
-
Referee: Abstract and Experimental Results section: the claims that Parakeet achieves the best transcription performance and that the proposed NER solutions attain the highest F1 scores are presented without any description of the underlying datasets (size, source channels, annotation process), training/validation/test splits, exact model architectures or fine-tuning procedures, baseline implementations, or statistical measures such as error bars or significance tests. This absence is load-bearing because the central contribution rests on these comparative performance assertions.
Authors: We acknowledge that the Experimental Results section in the current manuscript lacks the level of detail required for independent verification of the reported performance comparisons. In the revised version, we will substantially expand this section to describe: the datasets used for transcription and NER evaluation (including total size, source Telegram channels, and the annotation process); the training/validation/test splits; the exact architectures and fine-tuning procedures for the custom transformer-based NER models; the implementation details and configurations of all baselines including Microsoft Presidio; and statistical measures such as standard deviations, error bars, and significance tests for the F1 scores and transcription metrics. These additions will directly address the load-bearing nature of the claims and allow readers to assess the comparative results for Parakeet and the proposed NER solutions. revision: yes
Circularity Check
No significant circularity
full rationale
The manuscript describes an applied pipeline for Telegram data collection, speech-to-text transcription (Parakeet), transformer-based NER, and anonymization, with results reported via standard F1 scores and structural coherence metrics. No equations, parameter fittings, derivations, or load-bearing self-citations appear in the method or evaluation sections. Claims rest on direct experimental comparisons to baselines (Presidio, transformers) that are externally verifiable and do not reduce to the inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Anonymization of detected named entities will simultaneously protect personal data and retain structural coherence useful for social engineering detection
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Experimental results indicate that Parakeet achieves the best performance in audio transcription, while the proposed NER solutions achieve the highest f1-score values in detecting sensitive information.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Information loss(X, X') = E(X) - E(X') ... Per-token Consistency (C) ... Collision Degree (G)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Parlamento Europeo y Consejo de la Uni ´on Europea, “Reglamento (ue) 2016/679 del parlamento europeo y del consejo, de 27 de abril de 2016, relativo a la protecci ´on de las personas f´ısicas en lo que respecta al tratamiento de datos personales y a la libre circulaci ´on de estos datos,” Diario Oficial de la Uni´on Europea, 2016, accedido: 23-jun-2025. [...
work page 2016
-
[2]
Ley Org ´anica 10/1995, de 23 de noviembre, del C´odigo Penal,
Jefatura del Estado, “Ley Org ´anica 10/1995, de 23 de noviembre, del C´odigo Penal,” Nov. 1995, bOE-A-1995-25444. [Online]. Available: https://www.boe.es/eli/es/lo/1995/11/23/10/con
work page 1995
-
[3]
P. Samarati and L. Sweeney, “Protecting privacy when disclosing information: k-anonymity and its enforcement through generalization and suppression,”EPIC, Electronic Privacy Information Center, 1998
work page 1998
-
[4]
A. Machanavajjhala, D. Kifer, J. Gehrke, and M. Venkitasubramaniam, “L-diversity: Privacy beyond k-anonymity,”ACM Trans. Knowl. Discov. Data, vol. 1, no. 1, p. 3–es, Mar. 2007. [Online]. Available: https://doi.org/10.1145/1217299.1217302
-
[5]
t-closeness: Privacy beyond k-anonymity and l-diversity,
N. Li, T. Li, and S. Venkatasubramanian, “t-closeness: Privacy beyond k-anonymity and l-diversity,” in2007 IEEE 23rd International Confer- ence on Data Engineering, 2007, pp. 106–115
work page 2007
-
[6]
Hiding the presence of individuals from shared databases,
M. E. Nergiz, M. Atzori, and C. Clifton, “Hiding the presence of individuals from shared databases,” inProceedings of the 2007 ACM SIGMOD international conference on Management of data, 2007, pp. 665–676
work page 2007
-
[7]
D. Asimopoulos, I. Siniosoglou, V . Argyriou, T. Karamitsou, E. Foun- toukidis, S. K. Goudos, I. D. Moscholios, K. E. Psannis, and P. Sa- rigiannidis, “Benchmarking advanced text anonymisation methods: A comparative study on novel and traditional approaches,” in2024 13th International Conference on Modern Circuits and Systems Technologies (MOCAST), 2024, pp. 1–6
work page 2024
-
[8]
Evaluating the efficacy of AI techniques in textual anonymization: A comparative study,
D. Asimopouloset al., “Evaluating the efficacy of AI techniques in textual anonymization: A comparative study,” in2024 7th International Balkan Conference on Communications and Networking (BalkanCom), Ljubljana, Slovenia, 2024, pp. 242–246
work page 2024
-
[9]
Anonymization of unstructured data via named-entity recognition,
F. Hassan, J. Domingo-Ferrer, and J. Soria-Comas, “Anonymization of unstructured data via named-entity recognition,” inModeling Decisions for Artificial Intelligence (MDAI 2018), ser. Lecture Notes in Computer Science, V . Torra, Y . Narukawa, I. Aguil´o, and M. Gonz ´alez-Hidalgo, Eds. Cham: Springer, 2018, vol. 11144, pp. 313–324
work page 2018
-
[10]
F. Hassan, D. S ´anchez, J. Soria-Comas, and J. Domingo-Ferrer, “Auto- matic anonymization of textual documents: Detecting sensitive informa- tion via word embeddings,” in2019 18th IEEE International Conference on Trust, Security and Privacy in Computing and Communications / 13th IEEE International Conference on Big Data Science and Engineer- ing (TrustCo...
work page 2019
-
[11]
Enhancing text anonymisation: A study on CRF, LSTM, and ELMo for advanced entity recognition,
I. Siniosoglouet al., “Enhancing text anonymisation: A study on CRF, LSTM, and ELMo for advanced entity recognition,” in2024 Panhellenic Conference on Electronics & Telecommunications (PACET), Thessa- loniki, Greece, 2024, pp. 1–6
work page 2024
-
[12]
Data anonymization in ai and ml engineering: Balancing privacy and model performance using presidio,
S. Patchipala, “Data anonymization in ai and ml engineering: Balancing privacy and model performance using presidio,”IRE Journals, vol. V olume 6, p. 13, 04 2023
work page 2023
-
[13]
Audio-to- text translation for the hard of hearing: A whisper model-based study,
A. Aben, G. Kazbekova, Z. Ismagulova, and G. Ibrayeva, “Audio-to- text translation for the hard of hearing: A whisper model-based study,” Scientific Journal of Astana IT University, pp. 24–36, 2025
work page 2025
-
[14]
How to calculate the word er- ror rate in python,
J. D. Marangon, “How to calculate the word er- ror rate in python,” Nov. 2023, accedido: 23-jun-2025. [Online]. Available: https://medium.com/@johnidouglasmarangon/ how-to-calculate-the-word-error-rate-in-python-ce0751a46052
work page 2023
-
[15]
What is accuracy, precision, recall and f1 score?
T. Tigerschiold, “What is accuracy, precision, recall and f1 score?” La- belf Blog, Nov. 2022, accedido: 23-jun-2025. [Online]. Available: https: //www.labelf.ai/blog/what-is-accuracy-precision-recall-and-f1-score
work page 2022
-
[16]
Y . Karaca and M. Moonis, “Chapter 14 - shannon entropy- based complexity quantification of nonlinear stochastic process: diagnostic and predictive spatiotemporal uncertainty of multiple sclerosis subgroups,” inMulti-Chaos, Fractal and Multi-Fractional Artificial Intelligence of Different Complex Systems, Y . Karaca, D. Baleanu, Y .-D. Zhang, O. Gervasi, ...
work page 2022
-
[17]
Distancia de levenshtein como clasificador de textos,
A. D. Prieto, “Distancia de levenshtein como clasificador de textos,” Proyecto de Fin de M ´aster, Universidade de Santiago de Compostela, Santiago de Compostela, Espa ˜na, Feb. 2023, directores: Jose Ameijeiras Alonso y Mar ´ıa Jos ´e Ginzo Villamayor. Lectura: 16-feb-2023 (online). [Online]. Available: http://eio.usc.es/pub/mte/ descargas/ProyectosFinMa...
work page 2023
-
[18]
Granary: Speech recognition and translation dataset in 25 european languages,
N. R. Koluguri, M. Sekoyan, G. Zelenfroynd, S. Meister, S. Ding, S. Kostandian, H. Huang, N. Karpov, J. Balam, V . Lavrukhin, Y . Peng, S. Papi, M. Gaido, A. Brutti, and B. Ginsburg, “Granary: Speech recognition and translation dataset in 25 european languages,” 2025. [Online]. Available: https://arxiv.org/abs/2505.13404
-
[19]
Gliner: Generalist model for named entity recognition using bidirectional transformer,
U. Zaratiana, N. Tomeh, P. Holat, and T. Charnois, “Gliner: Generalist model for named entity recognition using bidirectional transformer,”
-
[21]
Text anonymization benchmark (tab) v1.0,
I. Pil ´an and P. Lison, “Text anonymization benchmark (tab) v1.0,” Hug- ging Face Datasets, Apr. 2025, [Online]. Available: https://huggingface. co/datasets/ildpil/text-anonymization-benchmark (Last accessed: June 23, 2025)
work page 2025
-
[22]
U. Zaratiana, N. Tomeh, P. Holat, and T. Charnois, “Gliner: Generalist model for named entity recognition using bidirectional transformer,” arXiv preprint arXiv:2311.08526, 2023
-
[23]
bert-large- cased-finetuned-conll03-english,
D. Fliegner, T. Khatri, F. Strobel, and R. Krestel, “bert-large- cased-finetuned-conll03-english,” Hugging Face Model Hub, dbmdz, 2023, [Online]. Available: https://huggingface.co/dbmdz/ bert-large-cased-finetuned-conll03-english (Last accessed: June 23, 2025)
work page 2023
-
[24]
Google, “bert-base-cased,” Hugging Face Model Hub, 2025, accedido: 28-ago-2025. [Online]. Available: https://huggingface.co/google-bert/ bert-base-cased
work page 2025
-
[25]
Introduction to the CoNLL-2003 shared task: Language-independent named entity recognition,
E. F. Tjong Kim Sang and F. De Meulder, “Introduction to the CoNLL-2003 shared task: Language-independent named entity recognition,” inProceedings of the Seventh Conference on Natural Language Learning at HLT-NAACL 2003, 2003, pp. 142–147. [Online]. Available: https://www.aclweb.org/anthology/W03-0419
work page 2003
-
[26]
E. Hovy, M. Marcus, M. Palmer, L. Ramshaw, and R. Weischedel, “OntoNotes: The 90% solution,” inProceedings of the Human Language Technology Conference of the NAACL, Companion Volume: Short Papers. New York City, USA: Association for Computational Linguistics, Jun. 2006, pp. 57–60. [Online]. Available: https: //aclanthology.org/N06-2015
work page 2006
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.