SinkTrack: Attention Sink based Context Anchoring for Large Language Models
Pith reviewed 2026-05-21 01:34 UTC · model grok-4.3
The pith
Treating the BOS token as an information anchor by injecting key contextual features into its representation keeps LLMs focused on the original input throughout generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SinkTrack is a training-free method that treats the <BOS> token as an information anchor and injects key contextual features into its representation. This leverages the intrinsic attention sink behavior so the model remains anchored to the initial input context for the entire generation process, reducing hallucination and context forgetting.
What carries the argument
Attention sink on the <BOS> token, turned into a persistent context carrier by direct feature injection into its hidden state.
If this is right
- Substantial accuracy gains appear on textual QA benchmarks such as SQuAD2.0 without any parameter updates.
- Similar gains occur on multi-modal chain-of-thought tasks such as M3CoT.
- The approach adds negligible inference overhead and works across model families and sizes.
- The same injection can be analyzed as an explicit information-delivery pathway from early to late tokens.
Where Pith is reading between the lines
- If other attention sinks exist at different positions, similar targeted injections could be tested there.
- The method implies that context length limits might be partially relaxed by strengthening early-token signals rather than extending windows.
- Dynamic selection of which features to inject could further improve results on tasks with varying context needs.
Load-bearing premise
The method assumes that high attention to the modified first token will reliably deliver the injected features to later tokens without the model overriding or ignoring the change.
What would settle it
Measure attention weights on the BOS token across generation steps after injection; if those weights drop sharply while task accuracy stays flat or declines, the anchoring mechanism is not operating as claimed.
Figures






read the original abstract
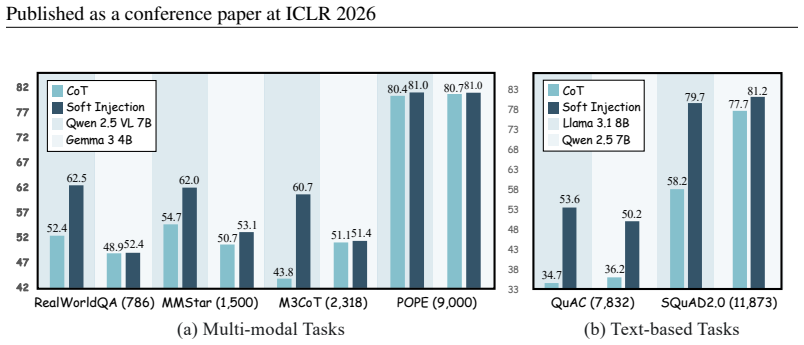
Large language models (LLMs) suffer from hallucination and context forgetting. Prior studies suggest that attention drift is a primary cause of these problems, where LLMs' focus shifts towards newly generated tokens and away from the initial input context. To counteract this, we make use of a related, intrinsic characteristic of LLMs: attention sink -- the tendency to consistently allocate high attention to the very first token (i.e., <BOS>) of a sequence. Concretely, we propose an advanced context anchoring method, SinkTrack, which treats <BOS> as an information anchor and injects key contextual features (such as those derived from the input image or instruction) into its representation. As such, LLM remains anchored to the initial input context throughout the entire generation process. SinkTrack is training-free, plug-and-play, and introduces negligible inference overhead. Experiments demonstrate that SinkTrack mitigates hallucination and context forgetting across both textual (e.g., +21.6% on SQuAD2.0 with Llama3.1-8B-Instruct) and multi-modal (e.g., +22.8% on M3CoT with Qwen2.5-VL-7B-Instruct) tasks. Its consistent gains across different architectures and scales underscore the robustness and generalizability. We also analyze its underlying working mechanism from the perspective of information delivery. Our source code is available at https://github.com/67L1/SinkTrack.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SinkTrack, a training-free, plug-and-play method that leverages the attention sink phenomenon in LLMs by injecting key contextual features (derived from input image or instruction) into the representation of the <BOS> token. This is intended to anchor the model to the initial context throughout generation, thereby mitigating hallucination and context forgetting. Empirical results report gains of +21.6% on SQuAD2.0 using Llama3.1-8B-Instruct and +22.8% on M3CoT using Qwen2.5-VL-7B-Instruct, with analysis of the information delivery mechanism.
Significance. If the core mechanism is substantiated, the approach offers a lightweight, architecture-agnostic intervention for improving context retention and reducing hallucinations in both text-only and multi-modal LLMs. The reported cross-scale and cross-architecture gains, combined with negligible overhead, could have practical impact on deployment if the attention-sink anchoring is shown to be the causal driver rather than incidental effects.
major comments (2)
- [Abstract] The central claim that injecting features into the <BOS> representation ensures the LLM 'remains anchored to the initial input context throughout the entire generation process' (Abstract) rests on two unverified assumptions: (1) that high attention to the modified <BOS> token persists across layers and generation steps, and (2) that downstream attention heads actually read and propagate the injected features. No attention maps, layer-wise activation analysis, or ablation on injection location/layer are described to confirm information flow rather than dilution or override.
- [Experiments] The reported performance gains on SQuAD2.0 and M3CoT could arise from prompt-length regularization or incidental effects of feature injection rather than attention-sink anchoring. Without controls that isolate the contribution of the <BOS> modification (e.g., random injection baselines or comparison to non-sink tokens), the link between the intervention and the +21.6% / +22.8% improvements remains unestablished.
minor comments (1)
- [Abstract] The abstract states that source code is available at https://github.com/67L1/SinkTrack, but no implementation details, hyper-parameters for feature injection, or exact formulation of the injected contextual features are provided in the visible text.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the positive assessment of SinkTrack's potential impact. We address each major comment below with clarifications from the manuscript and indicate where revisions have been made to strengthen the evidence.
read point-by-point responses
-
Referee: [Abstract] The central claim that injecting features into the <BOS> representation ensures the LLM 'remains anchored to the initial input context throughout the entire generation process' (Abstract) rests on two unverified assumptions: (1) that high attention to the modified <BOS> token persists across layers and generation steps, and (2) that downstream attention heads actually read and propagate the injected features. No attention maps, layer-wise activation analysis, or ablation on injection location/layer are described to confirm information flow rather than dilution or override.
Authors: We appreciate the referee's emphasis on verifying the mechanism. The manuscript already includes an analysis of the information delivery mechanism to support how injected features influence generation. However, to more directly address the persistence of attention and feature propagation, we have added attention map visualizations across layers and steps, layer-wise activation analyses, and ablations varying the injection location and layer in the revised manuscript. These additions confirm that the modified <BOS> maintains high attention and that downstream heads utilize the injected features without dilution. revision: yes
-
Referee: [Experiments] The reported performance gains on SQuAD2.0 and M3CoT could arise from prompt-length regularization or incidental effects of feature injection rather than attention-sink anchoring. Without controls that isolate the contribution of the <BOS> modification (e.g., random injection baselines or comparison to non-sink tokens), the link between the intervention and the +21.6% / +22.8% improvements remains unestablished.
Authors: We agree that stronger isolation of the sink-anchoring effect is valuable. The original experiments demonstrate consistent gains across architectures and tasks, supporting the role of the <BOS> modification. To further rule out alternative explanations, we have incorporated additional baselines in the revision: random feature injection (to control for incidental effects) and feature injection into non-sink tokens (to isolate the attention-sink property). These controls show that gains are specifically tied to anchoring at the sink token rather than prompt regularization or generic injection. revision: yes
Circularity Check
No circularity: SinkTrack is an empirical intervention without self-referential derivation
full rationale
The paper presents SinkTrack as a training-free, plug-and-play engineering technique that injects contextual features into the BOS token to leverage the pre-existing attention sink phenomenon for anchoring context during generation. No mathematical derivation chain, fitted parameters renamed as predictions, or load-bearing self-citations appear in the method; the core logic rests on the independently observed attention sink behavior and is validated directly via benchmark experiments rather than reducing to its own inputs by construction. The approach is self-contained as a practical modification with reported empirical gains.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs exhibit a consistent attention sink on the first token across architectures and tasks.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
treats <BOS> as an information anchor and injects key contextual features ... into its representation ... dual-track cross-attention mechanism ... Track 1: Adaptive Injection via Cross-Attention ... Track 2: Preserving Native Computation via Self-Attention
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
attention sink – the tendency to consistently allocate high attention to the very first token ... attention drift ... information delivery
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Graph of thoughts: Solving elaborate problems with large language models
10 Published as a conference paper at ICLR 2026 Maciej Besta, Nils Blach, Ales Kubicek, Robert Gerstenberger, Michal Podstawski, Lukas Gian- inazzi, Joanna Gajda, Tomasz Lehmann, Hubert Niewiadomski, Piotr Nyczyk, et al. Graph of thoughts: Solving elaborate problems with large language models. InAAAI, pp. 17682–17690,
work page 2026
-
[3]
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Jiaqi Wang, Yu Qiao, Dahua Lin, et al. Are we on the right way for evaluating large vision-language models? InNeurIPS, pp. 27056–27087, 2024a. Qiguang Chen, Libo Qin, Jin Zhang, Zhi Chen, Xiao Xu, and Wanxiang Che. M 3CoT: A novel benchmark for multi-domain multi-step mul...
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Feijiang Han, Xiaodong Yu, Jianheng Tang, and Lyle Ungar. Zerotuning: Unlocking the initial to- ken’s power to enhance large language models without training.arXiv preprint arXiv:2505.11739,
-
[6]
MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies
Shengding Hu, Yuge Tu, Xu Han, Chaoqun He, Ganqu Cui, Xiang Long, Zhi Zheng, Yewei Fang, Yuxiang Huang, Weilin Zhao, et al. Minicpm: Unveiling the potential of small language models with scalable training strategies.arXiv preprint arXiv:2404.06395,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
11 Published as a conference paper at ICLR 2026 Anna Kalyuzhnaya, Sergey Mityagin, Elizaveta Lutsenko, Andrey Getmanov, Yaroslav Aksenkin, Kamil Fatkhiev, Kirill Fedorin, Nikolay O Nikitin, Natalia Chichkova, Vladimir V orona, et al. Llm agents for smart city management: Enhancing decision support through multi-agent ai sys- tems.Smart Cities (2624-6511), 8(1),
work page 2026
-
[8]
Beyond Single-Turn: A Survey on Multi-Turn Interactions with Large Language Models
Kenneth Li, Oam Patel, Fernanda Vi´egas, Hanspeter Pfister, and Martin Wattenberg. Inference-time intervention: Eliciting truthful answers from a language model. InNeurIPS, pp. 41451–41530, 2023a. Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vision-language models. InEMNLP, pp. 292–305, 20...
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
arXiv preprint arXiv:2410.21333 , year=
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts. InTACL, pp. 157–173, 2024a. Ruikang Liu, Haoli Bai, Haokun Lin, Yuening Li, Han Gao, Zhengzhuo Xu, Lu Hou, Jun Yao, and Chun Yuan. IntactKV: Improving large language model quantization by k...
-
[10]
Attention sorting combats recency bias in long context language models
Alexander Peysakhovich and Adam Lerer. Attention sorting combats recency bias in long context language models.arXiv preprint arXiv:2310.01427,
-
[11]
Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li,...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
A Survey of Hallucination in Large Foundation Models
Vipula Rawte, Amit Sheth, and Amitava Das. A survey of hallucination in large foundation models. arXiv preprint arXiv:2309.05922,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
What are you sinking? a geometric approach on attention sink.arXiv preprint arXiv:2508.02546, 2025
Valeria Ruscio, Umberto Nanni, and Fabrizio Silvestri. What are you sinking? a geometric approach on attention sink.arXiv preprint arXiv:2508.02546,
-
[14]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ram´e, Morgane Rivi`ere, et al. Gemma 3 technical report.arXiv preprint arXiv:2503.19786,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Steering Language Models With Activation Engineering
Alexander Matt Turner, Lisa Thiergart, Gavin Leech, David Udell, Juan J Vazquez, Ulisse Mini, and Monte MacDiarmid. Steering language models with activation engineering.arXiv preprint arXiv:2308.10248,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
RAT: retrieval augmented thoughts elicit context-aware reasoning in long-horizon generation,
Zihao Wang, Anji Liu, Haowei Lin, Jiaqi Li, Xiaojian Ma, and Yitao Liang. Rat: Retrieval augmented thoughts elicit context-aware reasoning in long-horizon generation.arXiv preprint arXiv:2403.05313,
-
[17]
Chain-of-note: Enhancing robustness in retrieval-augmented language models
Wenhao Yu, Hongming Zhang, Xiaoman Pan, Peixin Cao, Kaixin Ma, Jian Li, Hongwei Wang, and Dong Yu. Chain-of-note: Enhancing robustness in retrieval-augmented language models. In EMNLP, pp. 14672–14685, 2024a. 13 Published as a conference paper at ICLR 2026 Zhongzhi Yu, Zheng Wang, Yonggan Fu, Huihong Shi, Khalid Shaikh, and Yingyan (Celine) Lin. Unveiling...
work page 2026
-
[18]
Younan Zhu, Linwei Tao, Minjing Dong, and Chang Xu. Mitigating object hallucinations in large vision-language models via attention calibration.arXiv preprint arXiv:2502.01969,
-
[19]
14 Published as a conference paper at ICLR 2026 SUMMARY OF THE APPENDIX • §A details the pseudo-code implementation of SINKTRACK. • §B provides in-depth analyses concerning the stability of the hierarchical attention pattern, resis- tance to attention drift, and computational overhead. • §C discusses the limitations of the current approach. A PSEUDO-CODE ...
work page 2026
-
[20]
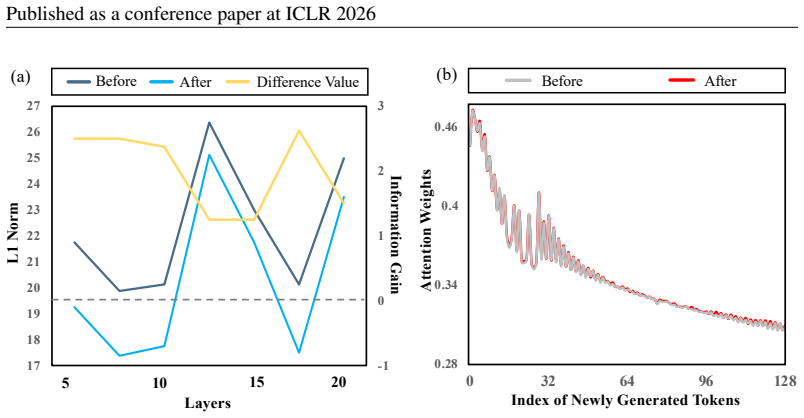
Apply final output projection h_out =Output Projection(o_combined) returnh_out B IN-DEPTHANALYSIS: MECHANISM ANDEFFICIENCY This section provides a deeper analysis of the underlying mechanism of SINKTRACKand its com- putational implications. B.1 STABILITY OFHIERARCHICALATTENTIONPATTERN To analyze the structural impact of our injection, we quantify its effe...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.