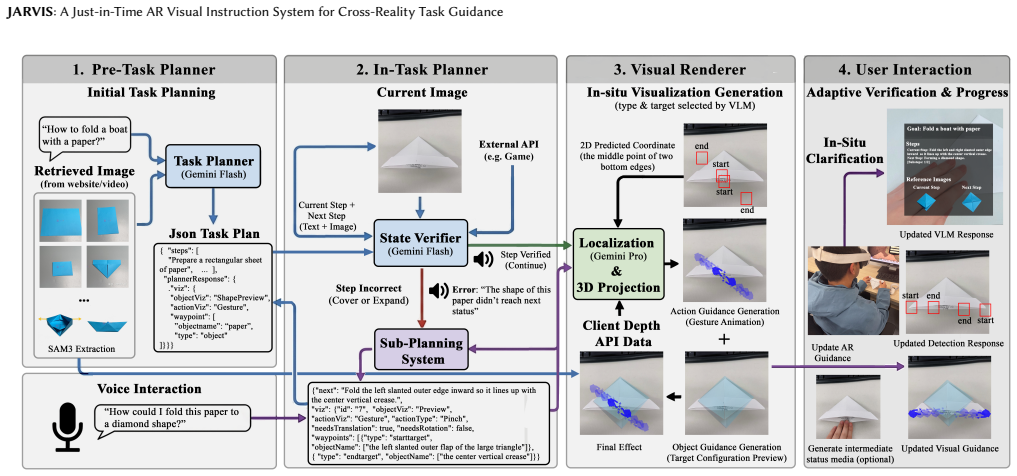
JARVIS: A Just-in-Time Augmented Reality VLM-Powered Instruction System for Cross-Reality Task Guidance
Pith reviewed 2026-05-21 01:24 UTC · model grok-4.3
The pith
JARVIS uses a vision-language model to generate real-time adaptive AR guidance for tasks that mix physical and virtual actions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
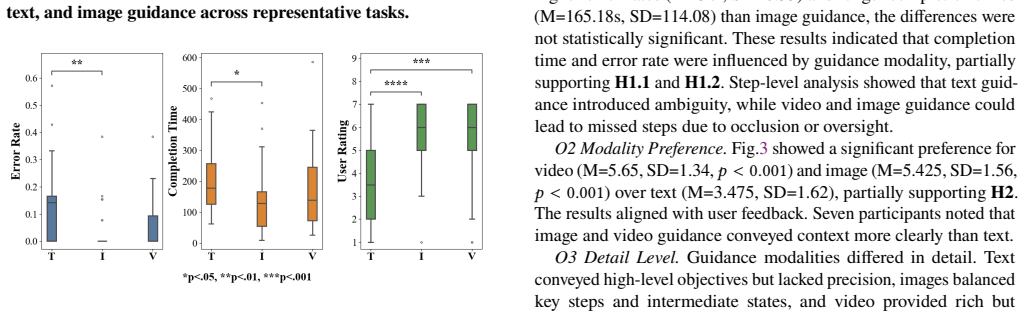
JARVIS generates contextual step-by-step guidance from one prompt, performs real-time state verification across physical-virtual boundaries, and supplies adaptive visual feedback; a within-subjects evaluation across four domains shows this raises usability, lowers workload, increases success rate, and improves visualization effectiveness relative to existing AR tutorial approaches.
What carries the argument
VLM-powered real-time state verification with adaptive visual feedback that bridges physical and virtual workspaces.
If this is right
- Users can stay focused on the task instead of switching attention between instructions and actions.
- Guidance automatically adjusts when the user completes or skips a step in a hybrid environment.
- Single-prompt input lowers the effort needed to create instructions for complex cross-reality work.
- Higher completion rates become possible in domains that require tight coordination between real tools and digital interfaces.
Where Pith is reading between the lines
- The same state-verification loop could be applied to longer sessions to check whether error rates stay low over time.
- Domains such as remote maintenance or procedural training might see similar gains if the four task categories are represented.
- Future versions could test whether adding explicit user correction channels further reduces the impact of occasional VLM perception slips.
Load-bearing premise
The vision-language model must correctly perceive and verify the combined physical and virtual state at each moment so that the generated guidance stays accurate.
What would settle it
A sequence of trials in which the system repeatedly issues a guidance step that no longer matches the actual combined state, such as telling the user to manipulate a virtual object after a physical change has already occurred.
Figures









read the original abstract
Many everyday tasks rely on external tutorials such as manuals and videos, requiring users to constantly switch between reading instructions and performing actions, which disrupts workflow and increases cognitive load. Augmented reality (AR) enables in-situ guidance, while recent advances in large language models (LLMs) and vision-language models (VLMs) make it possible to automatically generate such guidance. However, existing AI-powered AR tutorial systems primarily focus on physical procedural tasks and provide limited support for hybrid physical and virtual workspaces. To address this gap, we conduct a formative study of cross-reality tasks and identify key requirements for state awareness and cross-reality coordination. We present JARVIS, a VLM-driven AR instruction system that generates contextual, step-by-step guidance from a single prompt, with real-time state verification and adaptive visual feedback. To inform the system design, we conducted a formative study to understand guidance needs across cross-reality tasks, which we categorize into four types, real-to-real (R2R), real-to-virtual (R2V), virtual-to-real (V2R), and virtual-to-virtual (V2V). A within-subjects study (N=14) across four domains shows JARVIS improves usability, workload, success rate, and visualization effectiveness over baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces JARVIS, a VLM-driven augmented reality instruction system for cross-reality task guidance. It reports a formative study that categorizes tasks into four types (R2R, R2V, V2R, V2V) and identifies requirements for state awareness and cross-reality coordination. The system generates contextual step-by-step guidance from a single prompt with real-time state verification and adaptive visual feedback. A within-subjects user study (N=14) across four domains is claimed to demonstrate improvements in usability, workload, success rate, and visualization effectiveness over baselines.
Significance. If the central claims hold, the work could advance HCI research on AR guidance by extending VLM capabilities to hybrid physical-virtual workspaces, a growing area with limited prior support. The taxonomy of cross-reality task types and the emphasis on real-time verification represent useful contributions to system design. The modest N and absence of reliability metrics for the VLM component, however, constrain the strength of the reported outcomes.
major comments (2)
- [Evaluation / User Study] Evaluation section (user study results): The reported improvements in usability, workload, success rate, and visualization effectiveness are presented as aggregate outcomes without accompanying details on statistical tests, specific baseline conditions, error rates, or participant exclusion criteria. This is load-bearing because the headline claim attributes gains to VLM-powered adaptive guidance across physical-virtual boundaries.
- [System / Evaluation] System description and evaluation: No quantitative assessment of VLM perception accuracy, false-negative rates for cross-reality state detection (R2R/R2V/V2R/V2V), or frequency of fallback to non-adaptive modes is provided. Without these data, it is unclear whether the measured benefits stem from the claimed real-time verification or primarily from the AR visualization layer.
minor comments (1)
- [Abstract] Abstract: The summary of study outcomes would be strengthened by brief mention of the statistical approach or effect sizes to allow readers to gauge the robustness of the positive results.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive review of our manuscript. We address each of the major comments below and have made revisions to the manuscript to incorporate the suggested improvements where possible.
read point-by-point responses
-
Referee: [Evaluation / User Study] Evaluation section (user study results): The reported improvements in usability, workload, success rate, and visualization effectiveness are presented as aggregate outcomes without accompanying details on statistical tests, specific baseline conditions, error rates, or participant exclusion criteria. This is load-bearing because the headline claim attributes gains to VLM-powered adaptive guidance across physical-virtual boundaries.
Authors: We agree that these details are essential to substantiate the claims. In the revised manuscript we now report the statistical tests performed (paired t-tests with effect sizes and p-values for the within-subjects design), explicitly describe the two baseline conditions (a non-adaptive AR overlay and a conventional video tutorial), provide success rates and error breakdowns by task type (R2R, R2V, V2R, V2V) and condition, and confirm that all 14 participants completed every task with no exclusions. These additions clarify that the observed gains are attributable to the VLM-driven state verification and adaptive feedback rather than the AR visualization layer alone. revision: yes
-
Referee: [System / Evaluation] System description and evaluation: No quantitative assessment of VLM perception accuracy, false-negative rates for cross-reality state detection (R2R/R2V/V2R/V2V), or frequency of fallback to non-adaptive modes is provided. Without these data, it is unclear whether the measured benefits stem from the claimed real-time verification or primarily from the AR visualization layer.
Authors: We acknowledge the value of component-level metrics. Our evaluation centers on end-to-end user performance and task success rather than isolated VLM benchmarks. In the revision we have added a dedicated limitations paragraph that reports qualitative observations from the user study on state-detection failures and fallback frequency, and we explicitly note the absence of quantitative VLM accuracy figures as a limitation. A separate benchmark study measuring perception accuracy across the four task categories lies outside the scope of this HCI-focused contribution but is identified as valuable future work. revision: partial
Circularity Check
No circularity: empirical user study with independent evaluation
full rationale
The paper describes a VLM-powered AR system for cross-reality guidance, informed by a formative study that identifies four task categories (R2R/R2V/V2R/V2V), then evaluates the system via a within-subjects user study (N=14) measuring usability, workload, success rate, and visualization effectiveness against baselines. No equations, fitted parameters, or self-citations appear in the provided text that would reduce any claim to its own inputs by construction. The central results rest on direct participant measurements rather than any derivation that loops back to definitions or prior author work, satisfying the criteria for a self-contained empirical evaluation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption In-situ AR guidance reduces cognitive load and workflow disruption compared with external manuals or videos for everyday tasks.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
JARVIS... generates contextual, step-by-step guidance... with real-time state verification and adaptive visual feedback... across four types: real-to-real (R2R), real-to-virtual (R2V), virtual-to-real (V2R), and virtual-to-virtual (V2V)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
within-subjects study (N=14) across four domains shows JARVIS improves usability, workload, success rate
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Alexander Barquero, Rodrigo Luis Calvo, Daniel Alexander Delgado, Isaac Wang, Lisa Anthony, and Jaime Ruiz. 2024. Understanding User Needs for Task Guidance Systems Through the Lens of Cooking. InProceedings of the 2024 ACM Designing Interactive Systems Conference(Copenhagen, Denmark)(DIS ’24). Association for Computing Machinery, New York, NY, USA, 2006–...
-
[2]
JonasBlattgerste,PatrickRenner,andThiesPfeiffer.2019. Authorableaugmented realityinstructionsforassistanceandtraininginworkenvironments.InProceedings of the 18th International Conference on Mobile and Ubiquitous Multimedia(Pisa, Italy)(MUM ’19). Association for Computing Machinery, New York, NY, USA, Article 34, 11 pages. doi:10.1145/3365610.3365646
-
[3]
SUS:A’Quick’and’Dirty’UsabilityScale
JohnBrooke.1996. SUS:A’Quick’and’Dirty’UsabilityScale. InUsabilityEval- uation in Industry, Patrick W. Jordan, Bruce Thomas, Bernard A. Weerdmeester, and Ian Lyall McClelland (Eds.). Taylor and Francis, Chapter 21, 189–194
work page 1996
-
[4]
YuanzhiCao,AnnaFuste,andValentinHeun.2022. MobileTutAR:aLightweight AugmentedRealityTutorialSystemusingSpatiallySituatedHumanSegmentation Videos. InExtended Abstracts of the 2022 CHI Conference on Human Factors in Computing Systems(New Orleans, LA, USA)(CHI EA ’22). Association for Computing Machinery, New York, NY, USA, Article 396, 8 pages. doi:10.1145/...
-
[5]
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, et al. 2025. Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Boyuan Chen, Xinan Yan, Xuning Hu, Dominic Kao, and Hai-Ning Liang. 2024. Impact of Tutorial Modes with Different Time Flow Rates in Virtual Reality Games.Proc. ACM Comput. Graph. Interact. Tech.7, 1, Article 6 (May 2024), 19 pages. doi:10.1145/3651296
-
[7]
Chen Chen, Cuong Nguyen, Jane Hoffswell, Jennifer Healey, Trung Bui, and Nadir Weibel. 2023. PaperToPlace: Transforming Instruction Documents into Spatialized and Context-Aware Mixed Reality Experiences. InProceedings of the 36th Annual ACM Symposium on User Interface Software and Technology(San Francisco, CA, USA)(UIST ’23). Association for Computing Mac...
-
[8]
Subramanian Chidambaram, Hank Huang, Fengming He, Xun Qian, Ana M Villanueva, Thomas S Redick, Wolfgang Stuerzlinger, and Karthik Ramani. 2021. ProcessAR: An augmented reality-based tool to create in-situ procedural 2D/3D AR Instructions. InProceedings of the 2021 ACM Designing Interactive Systems Conference(VirtualEvent,USA)(DIS’21).AssociationforComputi...
-
[9]
Mustafa Doga Dogan, Eric J Gonzalez, Karan Ahuja, Ruofei Du, Andrea Colaço, Johnny Lee, Mar Gonzalez-Franco, and David Kim. 2024. Augmented Object IntelligencewithXR-Objects.InProceedingsofthe37thAnnualACMSymposium on User Interface Software and Technology(Pittsburgh, PA, USA)(UIST ’24). Association for Computing Machinery, New York, NY, USA, Article 19, ...
-
[10]
Mustafa Doga Dogan, Eric J Gonzalez, Karan Ahuja, Ruofei Du, Andrea Colaço, Johnny Lee, Mar Gonzalez-Franco, and David Kim. 2024. Augmented object intelligence with xr-objects. InProceedings of the 37th Annual ACM Symposium on User Interface Software and Technology. 1–15
work page 2024
-
[11]
DuckDuckGo. 2026. DuckDuckGo. https://duckduckgo.com/. Search engine. Accessed March 30, 2026
work page 2026
-
[12]
Google. 2026. Gemini API. https://ai.google.dev/api. Accessed: 2026-03-31
work page 2026
-
[13]
Sandra G Hart and Lowell E Staveland. 1988. Development of NASA-TLX (Task Load Index): Results of empirical and theoretical research.Human mental workload1, 3 (1988), 139–183
work page 1988
-
[14]
GaopingHuang,XunQian,TianyiWang,FagunPatel,MaitreyaSreeram,Yuanzhi Cao, Karthik Ramani, and Alexander J. Quinn. 2021. AdapTutAR: An Adaptive Tutoring System for Machine Tasks in Augmented Reality. InProceedings of the 2021 CHI Conference on Human Factors in Computing Systems(Yokohama, Japan)(CHI ’21). Association for Computing Machinery, New York, NY, USA...
-
[15]
Mina Huh, Zihui Xue, Ujjaini Das, Kumar Ashutosh, Kristen Grauman, and Amy Pavel. 2025. Vid2Coach: Transforming How-To Videos into Task Assistants. In Proceedings of the 38th Annual ACM Symposium on User Interface Software and Technology (UIST ’25). Association for Computing Machinery, New York, NY, USA, Article 46, 24 pages. doi:10.1145/3746059.3747612
-
[16]
Panayu Keelawat and Ryo Suzuki. 2024. Transforming Procedural Instructions into In-Situ Augmented Reality Guides with InstructAR. InAdjunct Proceedings of the 37th Annual ACM Symposium on User Interface Software and Technology (Pittsburgh,PA,USA)(UISTAdjunct’24).AssociationforComputingMachinery, New York, NY, USA, Article 70, 3 pages. doi:10.1145/3672539.3686321
-
[17]
Junhan Kong, Dena Sabha, Jeffrey P Bigham, Amy Pavel, and Anhong Guo
-
[18]
InProceedings of the 2021 ACM Symposium on Spatial User Interaction(Virtual Event, USA)(SUI ’21)
TutorialLens: Authoring Interactive Augmented Reality Tutorials Through Narration and Demonstration. InProceedings of the 2021 ACM Symposium on Spatial User Interaction(Virtual Event, USA)(SUI ’21). Association for Computing Machinery, New York, NY, USA, Article 16, 11 pages. doi:10.1145/ 3485279.3485289
-
[19]
Tobias Langlotz, Holger Regenbrecht, Stefanie Zollmann, and Dieter Schmalstieg
-
[20]
Audio stickies: visually-guided spatial audio annotations on a mobile aug- mented reality platform. InProceedings of the 25th Australian Computer-Human Interaction Conference: Augmentation, Application, Innovation, Collaboration Sun et al. (Adelaide, Australia)(OzCHI ’13). Association for Computing Machinery, New York, NY, USA, 545–554. doi:10.1145/254101...
-
[21]
Jaewook Lee, Filippo Aleotti, Diego Mazala, Guillermo Garcia-Hernando, Sara Vicente, Oliver James Johnston, Isabel Kraus-Liang, Jakub Powierza, Donghoon Shin,JonE.Froehlich,GabrielBrostow,andJessicaVanBrummelen.2025. Imag- inateAR: AI-Assisted In-Situ Authoring in Augmented Reality. InProceedings of the 38th Annual ACM Symposium on User Interface Software...
-
[22]
Satori: Towards Proactive AR Assistant with Belief-Desire-Intention User Modeling
Chenyi Li, Guande Wu, Gromit Yeuk-Yin Chan, Dishita Gdi Turakhia, Sonia CasteloQuispe,DongLi,LeslieWelch,ClaudioSilva,andJingQian.2025. Satori: Towards Proactive AR Assistant with Belief-Desire-Intention User Modeling. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI ’25). Association for Computing Machinery, New York, N...
-
[23]
Ziyi Liu, Zhengzhe Zhu, Enze Jiang, Feichi Huang, Ana M Villanueva, Xun Qian, Tianyi Wang, and Karthik Ramani. 2023. InstruMentAR: Auto-Generation of AugmentedRealityTutorialsforOperatingDigitalInstrumentsThroughRecording Embodied Demonstration. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems(Hamburg, Germany)(CHI ’23). Asso...
-
[24]
Peter Mohr, Bernhard Kerbl, Michael Donoser, Dieter Schmalstieg, and Denis Kalkofen. 2015. Retargeting Technical Documentation to Augmented Reality. In Proceedings of the 33rd Annual ACM Conference on Human Factors in Comput- ing Systems(Seoul, Republic of Korea)(CHI ’15). Association for Computing Machinery, New York, NY, USA, 3337–3346. doi:10.1145/2702...
-
[25]
Peter Mohr, David Mandl, Markus Tatzgern, Eduardo Veas, Dieter Schmalstieg, and Denis Kalkofen. 2017. Retargeting Video Tutorials Showing Tools With SurfaceContacttoAugmentedReality.InProceedingsofthe2017CHIConference on Human Factors in Computing Systems(Denver, Colorado, USA)(CHI ’17). Association for Computing Machinery, New York, NY, USA, 6547–6558. d...
-
[26]
Nguyen, Bilal Mirza, Dorothy Tan, and Jose Sepulveda
Tam V. Nguyen, Bilal Mirza, Dorothy Tan, and Jose Sepulveda. 2018. AS- MIM: Augmented Reality Authoring System for Mobile Interactive Manuals. In Proceedings of the 12th International Conference on Ubiquitous Information Management and Communication(Langkawi, Malaysia)(IMCOM ’18). Asso- ciation for Computing Machinery, New York, NY, USA, Article 3, 6 page...
-
[27]
Lev Poretski and Anthony Tang. 2022. Press A to Jump: Design Strategies for Video Game Learnability. InProceedings of the 2022 CHI Conference on Human Factors in Computing Systems(New Orleans, LA, USA)(CHI ’22). AssociationforComputingMachinery,NewYork,NY,USA,Article155,26pages. doi:10.1145/3491102.3517685
-
[28]
HyunA Seo, Juheon Yi, Rajesh Balan, and Youngki Lee. 2024. GradualReality: Enhancing Physical Object Interaction in Virtual Reality via Interaction State- Aware Blending. InProceedings of the 37th Annual ACM Symposium on User InterfaceSoftwareandTechnology(Pittsburgh,PA,USA)(UIST’24).Association for Computing Machinery, New York, NY, USA, Article 82, 14 p...
-
[29]
Jingyu Shi, Rahul Jain, Seunggeun Chi, Hyungjun Doh, Hyung-gun Chi, Alexan- der J. Quinn, and Karthik Ramani. 2025. CARING-AI: Towards Authoring Context-aware Augmented Reality INstruction through Generative Artificial In- telligence. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI ’25). Association for Computing Machin...
-
[30]
Sruti Srinidhi, Edward Lu, and Anthony Rowe. 2024. XaiR: An XR Platform that Integrates Large Language Models with the Physical World. In2024 IEEE International Symposium on Mixed and Augmented Reality (ISMAR). 759–767. doi:10.1109/ISMAR62088.2024.00091
-
[31]
Daniel Stover and Doug Bowman. 2024. TAGGAR: General-Purpose Task Guidance from Natural Language in Augmented Reality using Vision-Language Models. InProceedings of the 2024 ACM Symposium on Spatial User Interaction (Trier, Germany)(SUI ’24). Association for Computing Machinery, New York, NY, USA, Article 12, 12 pages. doi:10.1145/3677386.3682095
-
[32]
Yiliu Tang, Jason Situ, Andrea Yaoyun Cui, Mengke Wu, and Yun Huang
-
[33]
LLM Integration in Extended Reality: A Comprehensive Review of Current Trends, Challenges, and Future Perspectives. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI ’25). Association for Computing Machinery, New York, NY, USA, Article 1054, 24 pages. doi:10.1145/3706598.3714224
-
[34]
Balasaravanan Thoravi Kumaravel, Fraser Anderson, George Fitzmaurice, Bjoern Hartmann, and Tovi Grossman. 2019. Loki: Facilitating Remote Instruction of Physical Tasks Using Bi-Directional Mixed-Reality Telepresence. InProceedings of the 32nd Annual ACM Symposium on User Interface Software and Technology (NewOrleans,LA,USA)(UIST’19).AssociationforComputin...
-
[35]
Nhan (Nathan) Tran, Ethan Yang, and Abe Davis. 2025. ARticulate: Interactive Visual Guidance for Demonstrated Rotational Degrees of Freedom in Mobile AR. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI ’25). Association for Computing Machinery, New York, NY, USA, Article 28, 8 pages. doi:10.1145/3706598.3713179
-
[36]
Julia Woodward and Jaime Ruiz. 2023. Analytic Review of Using Augmented Reality for Situational Awareness.IEEE Transactions on Visualization and Computer Graphics29, 4 (2023), 2166–2183. doi:10.1109/TVCG.2022.3141585
-
[37]
Masahiro Yamaguchi, Shohei Mori, Peter Mohr, Markus Tatzgern, Ana Stanescu, Hideo Saito, and Denis Kalkofen. 2020. Video-Annotated Augmented Reality Assembly Tutorials. InProceedings of the 33rd Annual ACM Symposium on User Interface Software and Technology(Virtual Event, USA)(UIST ’20). Association for Computing Machinery, New York, NY, USA, 1010–1022. d...
- [38]
-
[39]
yt-dlp contributors. 2026. yt-dlp. https://github.com/yt-dlp/yt-dlp. Software repository. Accessed March 30, 2026
work page 2026
-
[40]
Xingyao Yu, Benjamin Lee, and Michael Sedlmair. 2024. Design Space of Visual Feedforward And Corrective Feedback in XR-Based Motion Guidance Systems. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems(Honolulu, HI, USA)(CHI ’24). Association for Computing Machinery, New York, NY, USA, Article 723, 15 pages. doi:10.1145/3613904.3642143
-
[41]
Ada Yi Zhao, Aditya Gunturu, Ellen Yi-Luen Do, and Ryo Suzuki. 2025. Guided Reality: Generating Visually-Enriched AR Task Guidance with LLMs and Vision Models. InProceedings of the 38th Annual ACM Symposium on User Interface Software and Technology (UIST ’25). Association for Computing Machinery, New York, NY, USA, Article 146, 15 pages. doi:10.1145/37460...
-
[42]
Chenfei Zhu, Shao-Kang Hsia, Xiyun Hu, Ziyi Liu, Jingyu Shi, and Karthik Ramani. 2025. agentAR: Creating Augmented Reality Applications with Tool- Augmented LLM-based Autonomous Agents. InProceedings of the 38th Annual ACM Symposium on User Interface Software and Technology (UIST ’25). Asso- ciation for Computing Machinery, New York, NY, USA, Article 54, ...
-
[43]
objectViz: How to visualize the object to operate on - "Outline": Green bounding box to identify object location (use when object position needs highlighting) - "ShapePreview": Shape/area preview image (use when object shape or area needs to be shown, especially with SAM3 segmentation)
-
[44]
Arrow": For movement/rotation (translation or rotation). Requireswaypointswithstartandendpositions.-
actionViz: How to visualize the hand/target object action or move- ment - "Arrow": For movement/rotation (translation or rotation). Requireswaypointswithstartandendpositions.-"Gesture":Forhand JARVIS: A Just-in-Time AR Visual Instruction System for Cross-Reality Task Guidance gestures (e.g., pinch, poke, grip). System will search for matching imageinResou...
-
[45]
-success:Pleasechecktheimageandconfirmifcurrentstepisreached, only answer true or false
FILL IN these three fields based on the current photo: - next: The specific sub-goal for the next step (if current step is not successfully reached). -success:Pleasechecktheimageandconfirmifcurrentstepisreached, only answer true or false. - check: If you are not sure of the result of success, tell me what you need to further check. If you are sure, leave ...
-
[46]
starttarget | endtarget | object
VERIFY the field from the existing plannerResponse: - waypoints: Verify that the waypoint objectNames and types are still relevant and suitable for current visualization. Keep the existing waypoint structure unless it’s completely inappropriate. IMPORTANT:UsetheexistingplannerResponseasyourbasetemplate. Ignoreanyunnecessarydetailswhenjudgingthestatus.e.g....
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.