Cognitive Pivot Points and Visual Anchoring: Unveiling and Rectifying Hallucinations in Multimodal Reasoning Models
Pith reviewed 2026-05-10 15:59 UTC · model grok-4.3
The pith
Multimodal reasoning models hallucinate when they stop querying visual evidence at high-entropy decision points.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
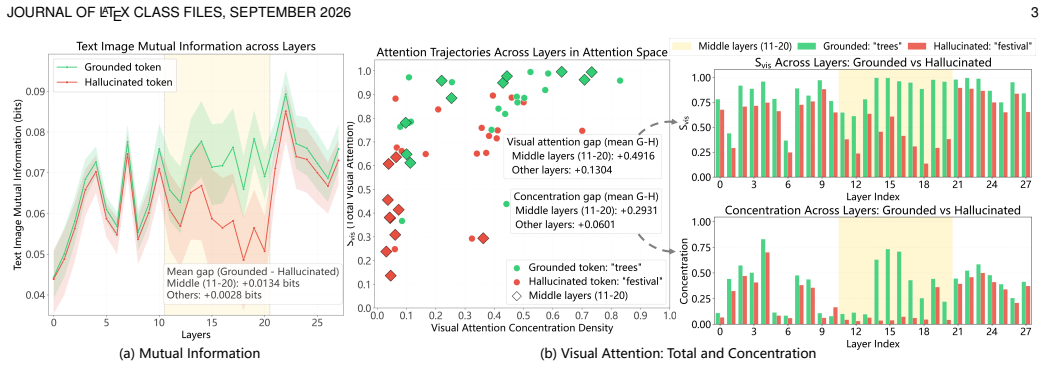
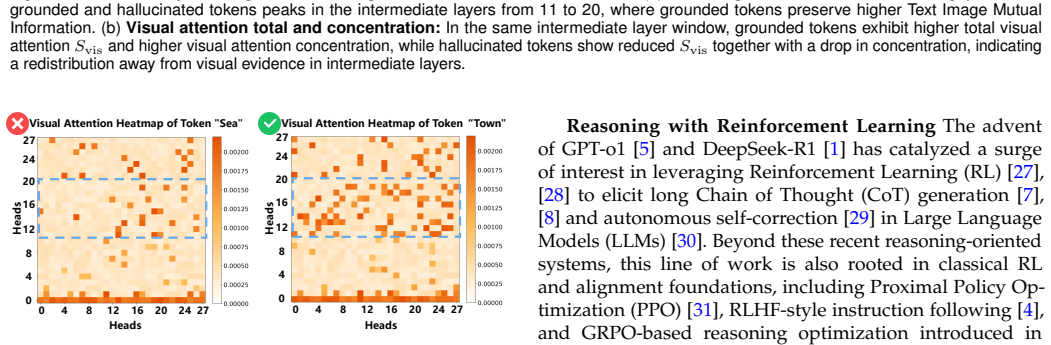
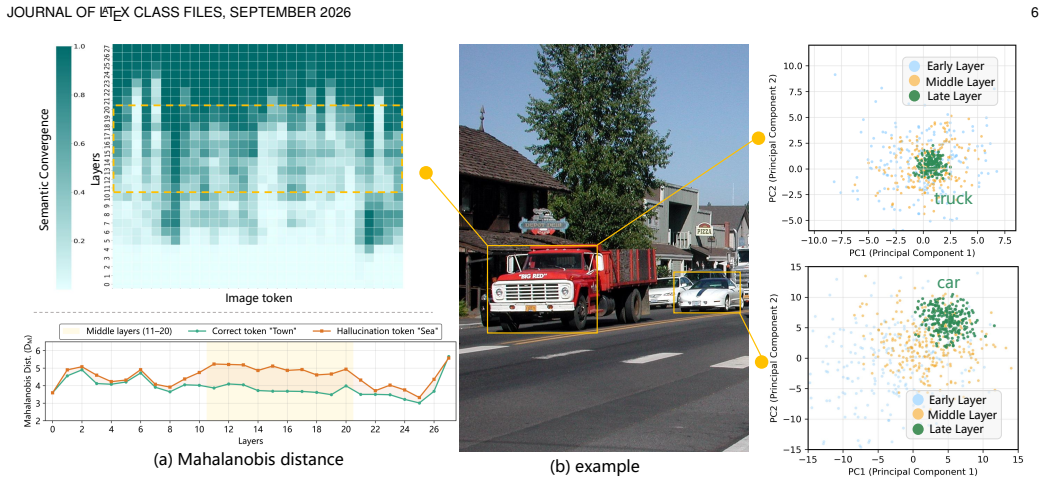
Multimodal Large Reasoning Models remain vulnerable to hallucinations during extended reasoning chains. These errors correlate strongly with cognitive bifurcation points that exhibit high entropy states. The root cause is a localized breakdown in visual semantic anchoring within intermediate network layers; at these high-uncertainty transitions the model fails to query visual evidence and reverts to language priors. The authors therefore introduce V-STAR, a training paradigm that augments outcome supervision with fine-grained internal attention guidance. Its central components are the Hierarchical Visual Attention Reward, which dynamically incentivizes visual attention across critical layers
What carries the argument
Hierarchical Visual Attention Reward (HVAR) within the GRPO framework, which detects high-entropy states and rewards visual attention in intermediate layers to restore anchoring to the visual input.
If this is right
- Outcome-level supervision alone is insufficient; fine-grained internal attention guidance at uncertain steps measurably reduces hallucinations.
- Detecting high-entropy states allows targeted reinforcement of visual queries that overrides language priors.
- Forced reflection around bifurcation points converts external debiasing into an internalized habit of visual verification.
- The resulting capability operates without added test-time compute or performance loss on standard reasoning metrics.
Where Pith is reading between the lines
- The same entropy-triggered anchoring technique could be tested on other chain-of-thought tasks where models drift from input evidence.
- Because the failure is localized to intermediate layers, lighter interventions focused on those layers may suffice for broader multimodal models.
- If entropy detection proves reliable across architectures, it offers a general signal for inserting verification steps in any long reasoning sequence.
Load-bearing premise
That dynamically rewarding visual attention at high-entropy points during training will cause the model to maintain visual anchoring automatically in later use without reducing overall reasoning performance.
What would settle it
Train a model with the proposed method, then measure whether hallucinations and visual attention metrics at previously identified high-entropy bifurcation points differ from those of an identical baseline model on the same long-chain visual reasoning tasks.
Figures










read the original abstract
Multimodal Large Reasoning Models (MLRMs) have achieved remarkable strides in visual reasoning through test time compute scaling, yet long chain reasoning remains prone to hallucinations. We identify a concerning phenomenon termed the Reasoning Vision Truth Disconnect (RVTD): hallucinations are strongly correlated with cognitive bifurcation points that often exhibit high entropy states. We attribute this vulnerability to a breakdown in visual semantic anchoring, localized within the network's intermediate layers; specifically, during these high uncertainty transitions, the model fails to query visual evidence, reverting instead to language priors. Consequently, we advocate a shift from solely outcome level supervision to augmenting it with fine grained internal attention guidance. To this end, we propose V-STAR (Visual Structural Training with Attention Reinforcement), a lightweight, holistic training paradigm designed to internalize visually aware reasoning capabilities. Central to our approach is the Hierarchical Visual Attention Reward (HVAR), integrated within the GRPO framework. Upon detecting high entropy states, this mechanism dynamically incentivizes visual attention across critical intermediate layers, thereby anchoring the reasoning process back to the visual input. Furthermore, we introduce the Forced Reflection Mechanism (FRM), a trajectory editing strategy that disrupts cognitive inertia by triggering reflection around high entropy cognitive bifurcation points and encouraging verification of subsequent steps against the visual input, thereby translating external debiasing interventions into an intrinsic capability for hallucination mitigation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies a phenomenon called Reasoning Vision Truth Disconnect (RVTD) in Multimodal Large Reasoning Models (MLRMs), claiming that hallucinations correlate strongly with high-entropy cognitive bifurcation points in intermediate layers where visual semantic anchoring breaks down and models revert to language priors. It proposes V-STAR, a training paradigm using Hierarchical Visual Attention Reward (HVAR) within the GRPO framework to dynamically incentivize visual attention at high-entropy states, plus Forced Reflection Mechanism (FRM) for trajectory editing to encourage verification against visual input, aiming to internalize hallucination mitigation.
Significance. If the correlation measurements, layer-localized attention breakdowns, and mitigation results hold under the reported experimental controls, this work offers a concrete internal mechanism for addressing hallucinations beyond outcome-level supervision, with potential to improve reliability in long-chain visual reasoning without external debiasing at inference time. The provision of attention visualizations, trajectory analyses, and integration with existing GRPO strengthens the case for practical adoption.
major comments (1)
- [Experimental Evaluation] The central RVTD correlation and layer-localization claims are supported by the experimental sections, attention maps, and trajectory analyses, but the assumption that HVAR+FRM translates to intrinsic capability without performance degradation requires explicit reporting of overall reasoning accuracy metrics (e.g., on standard VQA or reasoning benchmarks) alongside hallucination rates to confirm no trade-off.
minor comments (2)
- [Introduction] The abstract and introduction introduce multiple new terms (RVTD, HVAR, FRM, V-STAR) without a consolidated notation table; adding one would improve readability.
- [Method] Clarify the precise entropy threshold and detection method used to trigger HVAR in the GRPO integration, as the high-level description leaves implementation details ambiguous for reproduction.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation, recognition of the RVTD phenomenon and V-STAR contributions, and recommendation for minor revision. We address the single major comment below.
read point-by-point responses
-
Referee: The central RVTD correlation and layer-localization claims are supported by the experimental sections, attention maps, and trajectory analyses, but the assumption that HVAR+FRM translates to intrinsic capability without performance degradation requires explicit reporting of overall reasoning accuracy metrics (e.g., on standard VQA or reasoning benchmarks) alongside hallucination rates to confirm no trade-off.
Authors: We agree that confirming the absence of performance trade-offs is essential for validating that HVAR and FRM internalize hallucination mitigation as an intrinsic capability. The current manuscript emphasizes hallucination reduction in long-chain visual reasoning; to strengthen the claim, the revised version will include explicit accuracy results on standard benchmarks (e.g., VQA-v2 and visual reasoning tasks) reported alongside hallucination rates under identical experimental controls. This addition will directly demonstrate that V-STAR improves reliability without degrading overall reasoning performance. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper identifies RVTD as an empirical correlation between hallucinations and high-entropy bifurcation points, attributes it to visual anchoring failure in intermediate layers, and proposes V-STAR incorporating HVAR within the pre-existing GRPO framework plus FRM as a trajectory intervention. No equations, parameter fits, or first-principles derivations are present that reduce any claimed result to quantities defined by the paper's own outputs or self-citations. The central claims rest on experimental observations, attention visualizations, and trajectory analyses treated as independent evidence rather than self-referential constructions, rendering the argument self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption High-entropy states during reasoning correspond to cognitive bifurcation points at which visual semantic anchoring fails and language priors dominate.
- domain assumption Fine-grained internal attention guidance can be translated into an intrinsic model capability via reward shaping and trajectory editing.
invented entities (3)
-
Reasoning Vision Truth Disconnect (RVTD)
no independent evidence
-
Hierarchical Visual Attention Reward (HVAR)
no independent evidence
-
Forced Reflection Mechanism (FRM)
no independent evidence
Forward citations
Cited by 1 Pith paper
-
LatentOmni: Rethinking Omni-Modal Understanding via Unified Audio-Visual Latent Reasoning
LatentOmni proposes a latent-space cross-modal reasoning framework that uses feature-level supervision and Omni-Sync Position Embedding to align and synchronize audio-visual latents, supported by a new 35K interleaved...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.