BareBones: Benchmarking Zero-Shot Geometric Comprehension in VLMs
Pith reviewed 2026-05-10 16:15 UTC · model grok-4.3
The pith
Current vision-language models lack genuine geometric comprehension and instead rely on texture and contextual shortcuts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
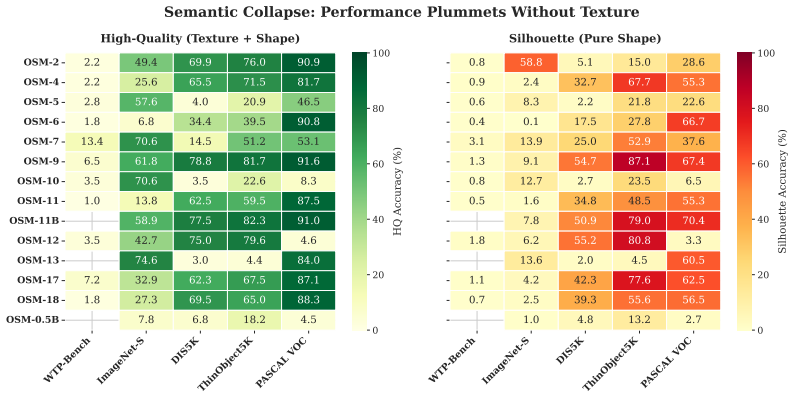
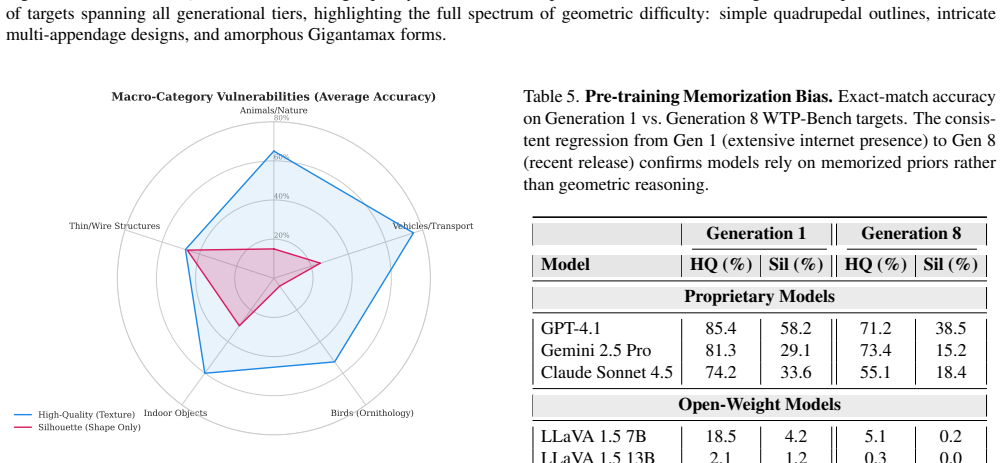
By depriving VLMs of RGB information and presenting only boundary contours from a noise-free geometric taxonomy, the benchmark reveals a universal 'Texture Bias Cliff' where even the most advanced models like GPT-4.1 and Claude fail to identify shapes based on geometry alone.
What carries the argument
The WTP-Bench collection and overall BareBones benchmark, which curates pixel-level silhouettes from segmentation datasets to create fine-grained geometric puzzles that force reliance on shape alone.
If this is right
- Advancements in VLMs will require methods that explicitly model geometric structure rather than texture patterns.
- Tasks involving precise spatial or shape-based reasoning may remain unreliable for current models.
- New training approaches could use silhouette data to reduce texture dependence.
- Evaluation protocols for multimodal models should include RGB-deprived tests to assess genuine comprehension.
Where Pith is reading between the lines
- Similar texture biases might affect performance in other zero-shot tasks like object detection or scene understanding.
- Developing models that can handle abstract shape recognition could improve generalization to novel environments.
- Researchers could test if fine-tuning on these benchmarks improves overall robustness.
Load-bearing premise
That the pixel-level silhouettes and the taxonomy in WTP-Bench provide no unintended semantic or contextual information that models could exploit beyond pure geometry.
What would settle it
Demonstrating that any current or future VLM achieves accuracy on the silhouette benchmark close to its performance on the original RGB images would challenge the existence of a universal texture bias.
Figures









read the original abstract
While Vision-Language Models (VLMs) demonstrate remarkable zero-shot recognition capabilities across a diverse spectrum of multimodal tasks, it yet remains an open question whether these architectures genuinely comprehend geometric structure or merely exploit RGB textures and contextual priors as statistical shortcuts. Existing evaluations fail to isolate this mechanism, conflating semantic reasoning with texture mapping and relying on imprecise annotations that inadvertently leak environmental cues. To address this gap, we introduce $\textbf{BareBones}$, a zero-shot benchmark designed to stress-test pure geometric shape comprehension. We curate pixel-level silhouettes of geometrically distinct classes across six datasets: five established segmentation sources (ImageNet-S, DIS5K, ThinObject5K, PASCAL VOC, CUB-200) and our novel flagship collection, WTP-Bench, establishing a noise-free geometric taxonomy. WTP-Bench is an extreme, fine-grained visual puzzle that forces models to identify inter-class geometric concepts from boundary contours alone. Our evaluation of 26 state-of-the-art proprietary and open-weight VLMs (eg. GPT-4.1, Gemini, Claude Sonnet 4.5, LLaVA) reveals a consistent, severe performance collapse under RGB deprivation, a phenomenon we term the $\textit{Texture Bias Cliff}$. By documenting universal structural blindspots, BareBones establishes a rigorous yardstick for genuine geometric grounding. Project Page: https://eternal-f1ame.github.io/WTP-Bench/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BareBones, a zero-shot benchmark using pixel-level silhouettes curated from ImageNet-S, DIS5K, ThinObject5K, PASCAL VOC, CUB-200 and a new flagship WTP-Bench collection. It evaluates 26 proprietary and open-weight VLMs and reports a consistent, severe performance collapse when RGB texture is removed, which the authors term the Texture Bias Cliff, to argue that current models lack genuine geometric comprehension.
Significance. If the silhouettes and WTP-Bench taxonomy truly isolate geometric structure without semantic or class-prior leakage, the documented universal structural blindspots would provide a valuable, falsifiable yardstick for measuring progress toward geometric grounding in VLMs.
major comments (3)
- [Abstract and WTP-Bench construction] The central claim of a 'noise-free geometric taxonomy' and 'Texture Bias Cliff' rests on the assumption that boundary contours from the six datasets contain no exploitable class-specific shape statistics or annotation cues. No controls (novel synthetic shapes, prompt ablations, or human contour-only baselines) are described to rule out pre-training leakage via contour statistics when the zero-shot prompt supplies the class vocabulary.
- [Evaluation methodology] Exact prompts, the silhouette generation pipeline, and the annotation verification procedure are not reported in sufficient detail to allow independent reproduction or verification that semantic/contextual cues have been eliminated. This directly affects the soundness of the performance-collapse measurements across the 26 models.
- [Results and analysis] No error bars, confidence intervals, or statistical significance tests are provided for the reported performance differences between RGB and silhouette conditions, weakening the assertion of a 'consistent, severe' collapse.
minor comments (1)
- [Abstract] The abbreviation 'eg.' in the abstract should be written as 'e.g.' for standard academic formatting.
Simulated Author's Rebuttal
Thank you for your constructive review and for acknowledging the potential value of BareBones as a benchmark for geometric comprehension in VLMs. We agree that the points raised regarding controls for leakage, reproducibility details, and statistical rigor are important and will improve the manuscript. We will prepare a revised version that incorporates additional analyses and clarifications while maintaining the core findings. Our point-by-point responses to the major comments are below.
read point-by-point responses
-
Referee: [Abstract and WTP-Bench construction] The central claim of a 'noise-free geometric taxonomy' and 'Texture Bias Cliff' rests on the assumption that boundary contours from the six datasets contain no exploitable class-specific shape statistics or annotation cues. No controls (novel synthetic shapes, prompt ablations, or human contour-only baselines) are described to rule out pre-training leakage via contour statistics when the zero-shot prompt supplies the class vocabulary.
Authors: We appreciate this observation on the central assumption. The current version does not include novel synthetic shapes or human contour-only baselines. In revision we will add prompt ablations that vary the class vocabulary and template phrasing to quantify any leakage from contour statistics. We will also revise the abstract and introduction to moderate the 'noise-free' phrasing and add a dedicated limitations paragraph discussing potential pre-training exposure to shape priors. We maintain that the consistent collapse across 26 models and six heterogeneous datasets provides supporting evidence for the Texture Bias Cliff, but we accept that the suggested controls would further strengthen the claims. This constitutes a partial revision, as conducting new human baseline studies falls outside the scope of the current work. revision: partial
-
Referee: [Evaluation methodology] Exact prompts, the silhouette generation pipeline, and the annotation verification procedure are not reported in sufficient detail to allow independent reproduction or verification that semantic/contextual cues have been eliminated. This directly affects the soundness of the performance-collapse measurements across the 26 models.
Authors: We agree that insufficient methodological detail hinders reproducibility. In the revised manuscript we will provide the exact zero-shot prompts used for every model family, a step-by-step description of the silhouette extraction and post-processing pipeline (including source code references), and the full annotation verification protocol employed to confirm removal of semantic cues. We will also release the complete prompt templates and generation scripts as supplementary material. These additions directly address the concern and will be marked as a full revision. revision: yes
-
Referee: [Results and analysis] No error bars, confidence intervals, or statistical significance tests are provided for the reported performance differences between RGB and silhouette conditions, weakening the assertion of a 'consistent, severe' collapse.
Authors: We acknowledge the absence of statistical support in the submitted version. Because the evaluations are zero-shot, we will recompute results for open-weight models across multiple prompt seeds where stochasticity exists, add error bars (standard deviation or bootstrap confidence intervals) to all bar plots, and include paired statistical tests (e.g., Wilcoxon signed-rank or McNemar tests) comparing RGB versus silhouette accuracy per model. These analyses and updated figures will appear in the revised results section. revision: yes
Circularity Check
No circularity: direct empirical measurements on held-out silhouettes
full rationale
The paper introduces BareBones as an empirical benchmark consisting of curated pixel-level silhouettes from existing segmentation datasets plus a new WTP-Bench collection. It evaluates 26 VLMs in zero-shot settings and reports observed performance drops under RGB deprivation. No mathematical derivations, fitted parameters, self-referential equations, or load-bearing self-citations are present. The Texture Bias Cliff is defined as the measured collapse itself, not constructed from any internal definition or prior result by the same authors. All reported numbers are direct observations on the benchmark inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pixel-level silhouettes from the listed sources provide a noise-free geometric taxonomy without semantic leakage.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.