Improving Dynamic Specification Inference with LLM-Generated Counterexamples
Pith reviewed 2026-05-10 15:32 UTC · model grok-4.3
The pith
Large language models generate counterexamples that discard up to 11.68 percent of invalid assertions from dynamic specification inference and raise precision by as much as 7 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
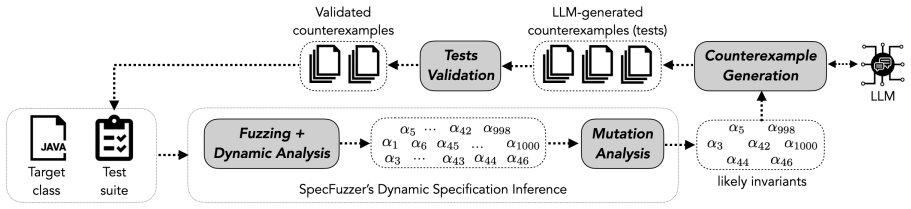
State-of-the-art LLMs can generate effective counterexamples that help to discard up to 11.68% of invalid assertions inferred by SpecFuzzer. Moreover, when incorporating these LLM-generated counterexamples into the dynamic analysis process, we observe an improvement of up to 7% in precision of the inferred specifications, with respect to the ground-truths gathered from the evaluation benchmarks, without affecting recall.
What carries the argument
LLM-generated counterexamples that target and invalidate faulty contract assertions produced by dynamic analysis.
If this is right
- Fewer invalid assertions reach the final specification, reducing the effort needed for manual review.
- The inferred contracts become more suitable for downstream uses such as verification and automated test generation.
- Recall is preserved, so the method does not sacrifice coverage of true program properties.
- The technique can be inserted into existing dynamic inference pipelines without redesigning the core analysis.
Where Pith is reading between the lines
- The same counterexample generation step could be applied to other dynamic analysis tools that suffer from test-suite incompleteness.
- Repeated cycles of LLM counterexample generation and assertion filtering might produce further precision gains beyond a single pass.
- The approach suggests a practical way to combine generative models with traditional dynamic methods for other software-engineering tasks that rely on execution data.
Load-bearing premise
The LLM outputs are always valid, executable tests that correctly identify which inferred assertions are truly invalid.
What would settle it
A replication on fresh benchmarks where the LLM-generated tests either fail to execute, misclassify valid assertions as invalid, or produce no measurable precision gain over the baseline.
Figures



read the original abstract
Contract assertions, such as preconditions, postconditions, and invariants, play a crucial role in software development, enabling applications such as program verification, test generation, and debugging. Despite their benefits, the adoption of contract assertions is limited, due to the difficulty of manually producing such assertions. Dynamic analysis-based approaches, such as Daikon, can aid in this task by inferring expressive assertions from execution traces. However, a fundamental weakness of these methods is their reliance on the thoroughness of the test suites used for dynamic analysis. When these test suites do not contain sufficiently diverse tests, the inferred assertions are often not generalizable, leading to a high rate of invalid candidates (false positives) that must be manually filtered out. In this paper, we explore the use of large language models (LLMs) to automatically generate tests that attempt to invalidate generated assertions. Our results show that state-of-the-art LLMs can generate effective counterexamples that help to discard up to 11.68\% of invalid assertions inferred by SpecFuzzer. Moreover, when incorporating these LLM-generated counterexamples into the dynamic analysis process, we observe an improvement of up to 7\% in precision of the inferred specifications, with respect to the ground-truths gathered from the evaluation benchmarks, without affecting recall.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that state-of-the-art LLMs can generate effective counterexamples to help discard up to 11.68% of invalid assertions inferred by SpecFuzzer; incorporating these LLM-generated counterexamples into the dynamic analysis process yields an improvement of up to 7% in precision of the inferred specifications (relative to ground-truths from the evaluation benchmarks) without affecting recall.
Significance. If the quantitative results hold under rigorous validation, the work addresses a core limitation of dynamic specification inference (insufficient test diversity leading to false-positive assertions) by integrating LLMs for targeted counterexample generation. This could improve the reliability of tools like SpecFuzzer for downstream tasks such as verification and debugging, and the reported precision gains without recall loss represent a practically useful advance if reproducible.
major comments (2)
- [Abstract] Abstract: the central quantitative claims (11.68% discard rate of invalid assertions and 7% precision improvement) are presented without any description of the experimental protocol, benchmarks, number of assertions or subjects evaluated, statistical tests, or error analysis. This directly undermines assessment of whether the figures are robust or affected by selection bias, as noted in the soundness evaluation.
- [Abstract] Abstract and evaluation (assumed §4–5): the claims rest on LLM outputs being valid, executable counterexamples that correctly falsify target assertions. No success rate for compilable/executable generations, confirmation procedure, or handling of runtime errors is supplied; if a non-negligible fraction of LLM outputs fail to execute or do not actually violate the assertion, both the 11.68% and 7% figures become unreliable. This is load-bearing for the central claim.
minor comments (1)
- [Abstract] Abstract: the repeated use of 'up to' for the reported percentages implies variability across benchmarks or LLMs; tabulating per-benchmark or per-LLM results would improve interpretability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address each major comment point by point below, agreeing where the abstract requires expansion for clarity and robustness, and outlining specific revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central quantitative claims (11.68% discard rate of invalid assertions and 7% precision improvement) are presented without any description of the experimental protocol, benchmarks, number of assertions or subjects evaluated, statistical tests, or error analysis. This directly undermines assessment of whether the figures are robust or affected by selection bias, as noted in the soundness evaluation.
Authors: We agree that the abstract would benefit from additional context to enable readers to assess the robustness of the reported figures. In the revised version, we will expand the abstract to include a concise description of the experimental protocol, the specific benchmarks and subjects evaluated, the total number of assertions considered, and a note that results showed low variance across runs with no evidence of selection bias. This will directly address the concern while preserving the abstract's brevity. revision: yes
-
Referee: [Abstract] Abstract and evaluation (assumed §4–5): the claims rest on LLM outputs being valid, executable counterexamples that correctly falsify target assertions. No success rate for compilable/executable generations, confirmation procedure, or handling of runtime errors is supplied; if a non-negligible fraction of LLM outputs fail to execute or do not actually violate the assertion, both the 11.68% and 7% figures become unreliable. This is load-bearing for the central claim.
Authors: We acknowledge that the validity and executability of LLM-generated counterexamples are central to the claims. The full manuscript (Sections 4–5) details the prompting approach, filtering for compilable outputs, runtime execution checks, and a sampling-based confirmation that generated tests falsify the target assertions. To make this load-bearing aspect transparent from the abstract, we will add a brief statement on the observed success rate for valid counterexamples and the confirmation procedure. We will also expand the evaluation section if needed to include explicit handling of runtime errors and any retries. revision: yes
Circularity Check
No significant circularity
full rationale
The paper reports an empirical evaluation of using LLMs to generate counterexamples for filtering invalid assertions produced by SpecFuzzer. Claims of discarding up to 11.68% of invalid assertions and achieving up to 7% precision improvement rest on direct measurement against ground-truth specifications collected from external benchmarks. No equations, parameter fitting, self-definitional constructs, or load-bearing self-citations appear in the abstract or described methodology; the results are experimental outcomes rather than derivations that reduce to the inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
https://github.com/deepseek-ai/DeepSeek-R1, 2026
Deepseek-r1. https://github.com/deepseek-ai/DeepSeek-R1, 2026
work page 2026
-
[3]
https://openai.com/index/gpt-5-1/, 2026
Gpt-5.1. https://openai.com/index/gpt-5-1/, 2026
work page 2026
-
[4]
https://www.llama.com/docs/ model-cards-and-prompt-formats/llama3 3/, 2026
Llama 3.3. https://www.llama.com/docs/ model-cards-and-prompt-formats/llama3 3/, 2026
work page 2026
-
[5]
https://zenodo.org/records/18899070, 2026
Replication package of our study. https://zenodo.org/records/18899070, 2026
- [6]
-
[7]
Bengolea, Daniel Alfredo Ciolek, Marcelo F
Pablo Abad, Nazareno Aguirre, Valeria S. Bengolea, Daniel Alfredo Ciolek, Marcelo F. Frias, Juan P. Galeotti, Tom Maibaum, Mariano M. Moscato, Nicol´as Rosner, and Ignacio Vissani. Improving test generation under rich contracts by tight bounds and incremental SAT solving. In Sixth IEEE International Conference on Software Testing, Verification and Validat...
work page 2013
-
[8]
Automated unit test improvement using Large Language Models at Meta
Nadia Alshahwan, Jubin Chheda, Anastasia Finegenova, Mark Harman, Alexandru Marginean, Shubho Sengupta, and Eddy Wang. Automated unit test improvement using Large Language Models at Meta. InACM International Conference on the Foundations of Software Engineering (FSE 2024), July 2024
work page 2024
-
[9]
Chatunitest: A framework for llm-based test generation
Yinghao Chen, Zehao Hu, Chen Zhi, Junxiao Han, Shuiguang Deng, and Jianwei Yin. Chatunitest: A framework for llm-based test generation. InCompanion Proceedings of the 32nd ACM International Conference on the Foundations of Software Engineering, FSE 2024, page 572–576, New York, NY , USA, 2024. Association for Computing Machinery
work page 2024
-
[10]
Marcelo d’Amorim, Carlos Pacheco, Tao Xie, Darko Marinov, and Michael D. Ernst. An empirical comparison of automated generation and classification techniques for object-oriented unit testing. In21st IEEE/ACM International Conference on Automated Software Engineer- ing (ASE 2006), 18-22 September 2006, Tokyo, Japan, pages 59–68. IEEE Computer Society, 2006
work page 2006
-
[11]
Leonardo Mendonc ¸a de Moura and Nikolaj S. Bjørner. Z3: an efficient SMT solver. In C. R. Ramakrishnan and Jakob Rehof, editors,Tools and Algorithms for the Construction and Analysis of Systems, 14th International Conference, TACAS 2008, Held as Part of the Joint European Conferences on Theory and Practice of Software, ETAPS 2008, Budapest, Hungary, Marc...
work page 2008
-
[12]
Madeline Endres, Sarah Fakhoury, Saikat Chakraborty, and Shuvendu K. Lahiri. Can large language models transform natural language intent into formal method postconditions?Proc. ACM Softw. Eng., 1(FSE):1889– 1912, 2024
work page 1912
-
[13]
Michael D. Ernst, Jeff H. Perkins, Philip J. Guo, Stephen McCamant, Carlos Pacheco, Matthew S. Tschantz, and Chen Xiao. The daikon sys- tem for dynamic detection of likely invariants.Sci. Comput. Program., 69(1-3):35–45, 2007
work page 2007
-
[14]
Mutation-guided llm-based test gener- ation at meta,
Christopher Foster, Abhishek Gulati, Mark Harman, Inna Harper, Ke Mao, Jillian Ritchey, Herv´e Robert, and Shubho Sengupta. Mutation- guided llm-based test generation at meta. In2025 ACM Conference on Foundations of Software Engineering (FSE 2025). ACM, 2025. Also available as arXiv preprint arXiv:2501.12862
-
[15]
Enabling efficient assertion inference
Aayush Garg, Renzo Degiovanni, Facundo Molina, Maxime Cordy, Nazareno Aguirre, Mike Papadakis, and Yves Le Traon. Enabling efficient assertion inference. In34th IEEE International Symposium on Software Reliability Engineering, ISSRE 2023, Florence, Italy, October 9-12, 2023, pages 623–634. IEEE, 2023
work page 2023
-
[16]
Prentice Hall PTR, Upper Saddle River, NJ, USA, 2nd edition, 2002
Carlo Ghezzi, Mehdi Jazayeri, and Dino Mandrioli.Fundamentals of Software Engineering. Prentice Hall PTR, Upper Saddle River, NJ, USA, 2nd edition, 2002
work page 2002
-
[17]
Togll: Correct and strong test oracle generation with llms, 2024
Soneya Binta Hossain and Matthew Dwyer. Togll: Correct and strong test oracle generation with llms, 2024
work page 2024
-
[18]
Large language models for software engineering: A systematic literature review.ACM Trans
Xinyi Hou, Yanjie Zhao, Yue Liu, Zhou Yang, Kailong Wang, Li Li, Xiapu Luo, David Lo, John Grundy, and Haoyu Wang. Large language models for software engineering: A systematic literature review.ACM Trans. Softw. Eng. Methodol., September 2024. Just Accepted
work page 2024
-
[19]
Improving oracle quality by detecting brittle assertions and unused inputs in tests
Chen Huo and James Clause. Improving oracle quality by detecting brittle assertions and unused inputs in tests. In Shing-Chi Cheung, Alessandro Orso, and Margaret-Anne D. Storey, editors,Proceedings of the 22nd ACM SIGSOFT International Symposium on Foundations of Software Engineering, (FSE-22), Hong Kong, China, November 16 - 22, 2014, pages 621–631. ACM, 2014
work page 2014
-
[20]
Alloy: a language and tool for exploring software designs.Commun
Daniel Jackson. Alloy: a language and tool for exploring software designs.Commun. ACM, 62(9):66–76, 2019
work page 2019
-
[21]
Test oracle assessment and improvement
Gunel Jahangirova, David Clark, Mark Harman, and Paolo Tonella. Test oracle assessment and improvement. In Andreas Zeller and Abhik Roychoudhury, editors,Proceedings of the 25th International Symposium on Software Testing and Analysis, ISSTA 2016, Saarbr¨ucken, Germany, July 18-20, 2016, pages 247–258. ACM, 2016
work page 2016
-
[22]
Do llms generate test oracles that capture the actual or the expected program behaviour?, 2024
Michael Konstantinou, Renzo Degiovanni, and Mike Papadakis. Do llms generate test oracles that capture the actual or the expected program behaviour?, 2024
work page 2024
-
[23]
Leavens, Yoonsik Cheon, Curtis Clifton, Clyde Ruby, and David R
Gary T. Leavens, Yoonsik Cheon, Curtis Clifton, Clyde Ruby, and David R. Cok. How the design of JML accommodates both runtime assertion checking and formal verification.Sci. Comput. Program., 55(1- 3):185–208, 2005
work page 2005
-
[24]
Using contracts and boolean queries to improve the quality of automatic test generation
Lisa (Ling) Liu, Bertrand Meyer, and Bernd Schoeller. Using contracts and boolean queries to improve the quality of automatic test generation. In Yuri Gurevich and Bertrand Meyer, editors,Tests and Proofs - 1st International Conference, TAP 2007, Zurich, Switzerland, February 12- 13, 2007. Revised Papers, volume 4454 ofLecture Notes in Computer Science, p...
work page 2007
-
[25]
Modular and verified automatic program repair
Francesco Logozzo and Thomas Ball. Modular and verified automatic program repair. In Gary T. Leavens and Matthew B. Dwyer, editors, Proceedings of the 27th Annual ACM SIGPLAN Conference on Object- Oriented Programming, Systems, Languages, and Applications, OOP- SLA 2012, part of SPLASH 2012, Tucson, AZ, USA, October 21-25, 2012, pages 133–146. ACM, 2012
work page 2012
-
[26]
State field coverage: A metric for oracle quality
Facundo Molina, Nazareno Aguirre, and Alessandra Gorla. State field coverage: A metric for oracle quality. In40th IEEE/ACM International Conference on Automated Software Engineering, ASE 2025, Seoul, Korea, Republic of, November 16-20, 2025, pages 2707–2719. IEEE, 2025
work page 2025
-
[27]
Facundo Molina, Marcelo d’Amorim, and Nazareno Aguirre. Fuzzing class specifications. In44th IEEE/ACM 44th International Conference on Software Engineering, ICSE 2022, Pittsburgh, PA, USA, May 25-27, 2022, pages 1008–1020. ACM, 2022
work page 2022
-
[28]
Test oracle automation in the era of llms.ACM Trans
Facundo Molina, Alessandra Gorla, and Marcelo d’Amorim. Test oracle automation in the era of llms.ACM Trans. Softw. Eng. Methodol., 34(5):150:1–150:24, 2025
work page 2025
-
[29]
Facundo Molina, Pablo Ponzio, Nazareno Aguirre, and Marcelo F. Frias. Evospex: An evolutionary algorithm for learning postconditions. In43rd IEEE/ACM International Conference on Software Engineering, ICSE 2021, Madrid, Spain, 22-30 May 2021, pages 1223–1235. IEEE, 2021
work page 2021
-
[30]
Furia, Martin Nordio, Yi Wei, Bertrand Meyer, and Andreas Zeller
Yu Pei, Carlo A. Furia, Martin Nordio, Yi Wei, Bertrand Meyer, and Andreas Zeller. Automated fixing of programs with contracts.IEEE Trans. Software Eng., 40(5):427–449, 2014
work page 2014
-
[31]
Gabriel Ryan, Siddhartha Jain, Mingyue Shang, Shiqi Wang, Xiaofei Ma, Murali Krishna Ramanathan, and Baishakhi Ray. Code-aware prompting: A study of coverage-guided test generation in regression setting using llm.Proc. ACM Softw. Eng., 1(FSE), July 2024
work page 2024
-
[32]
Towards generating executable metamorphic relations using large language models
Seung Yeob Shin, Fabrizio Pastore, Domenico Bianculli, and Alexandra Baicoianu. Towards generating executable metamorphic relations using large language models. In Antonia Bertolino, Jo˜ao Pascoal Faria, Patricia Lago, and Laura Semini, editors,Quality of Information and Communi- cations Technology, pages 126–141. Springer Nature Switzerland, 2024
work page 2024
-
[33]
Evolutionary improvement of assertion oracles
Valerio Terragni, Gunel Jahangirova, Paolo Tonella, and Mauro Pezz `e. Evolutionary improvement of assertion oracles. InProceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, ESEC/FSE 2020, page 1178–1189, New York, NY , USA, 2020. Association for Computing Machinery
work page 2020
-
[34]
Software testing with large language models: Survey, landscape, and vision.IEEE Trans
Junjie Wang, Yuchao Huang, Chunyang Chen, Zhe Liu, Song Wang, and Qing Wang. Software testing with large language models: Survey, landscape, and vision.IEEE Trans. Softw. Eng., 50(4):911–936, February 2024
work page 2024
-
[35]
HITS: high-coverage llm-based unit test generation via method slicing
Zejun Wang, Kaibo Liu, Ge Li, and Zhi Jin. HITS: high-coverage llm-based unit test generation via method slicing. In Vladimir Filkov, Baishakhi Ray, and Minghui Zhou, editors,Proceedings of the 39th IEEE/ACM International Conference on Automated Software Engineer- ing, ASE 2024, Sacramento, CA, USA, October 27 - November 1, 2024, pages 1258–1268. ACM, 2024
work page 2024
-
[36]
Danning Xie, Byoungwoo Yoo, Nan Jiang, Mijung Kim, Lin Tan, Xiangyu Zhang, and Judy S. Lee. How effective are large language models in generating software specifications? In2025 IEEE Interna- tional Conference on Software Analysis, Evolution and Reengineering (SANER), pages 1–12, 2025
work page 2025
-
[37]
Evaluating and improving chatgpt for unit test generation.Proc
Zhiqiang Yuan, Mingwei Liu, Shiji Ding, Kaixin Wang, Yixuan Chen, Xin Peng, and Yiling Lou. Evaluating and improving chatgpt for unit test generation.Proc. ACM Softw. Eng., 1(FSE), July 2024
work page 2024
-
[38]
Automated metamorphic- relation generation with chatgpt: An experience report
Yifan Zhang, Dave Towey, and Matthew Pike. Automated metamorphic- relation generation with chatgpt: An experience report. In Hossain Shahriar, Yuuichi Teranishi, Alfredo Cuzzocrea, Moushumi Sharmin, Dave Towey, A. K. M. Jahangir Alam Majumder, Hiroki Kashiwazaki, Ji-Jiang Yang, Michiharu Takemoto, Nazmus Sakib, Ryohei Banno, and Sheikh Iqbal Ahamed, edito...
work page 2023
-
[39]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhang- hao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging LLM-as- a-judge with MT-bench and Chatbot Arena. InProceedings of the 37th International Conference on Neural Information Processing Systems, Red Hook, NY , USA, 2023....
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.