Does Visual Token Pruning Improve Calibration? An Empirical Study on Confidence in MLLMs
Pith reviewed 2026-05-10 15:48 UTC · model grok-4.3
The pith
Visual token pruning can lower calibration error in multimodal models while preserving accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
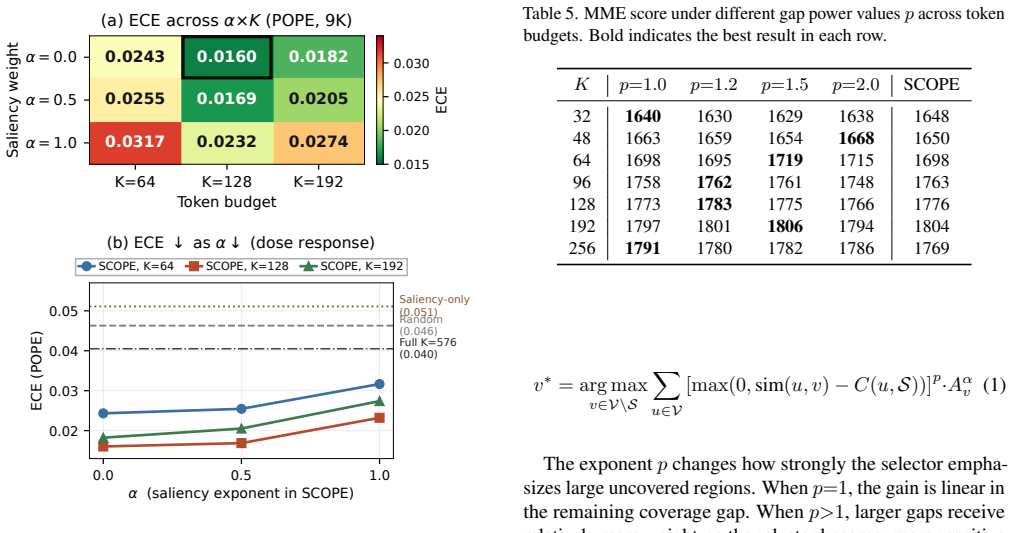
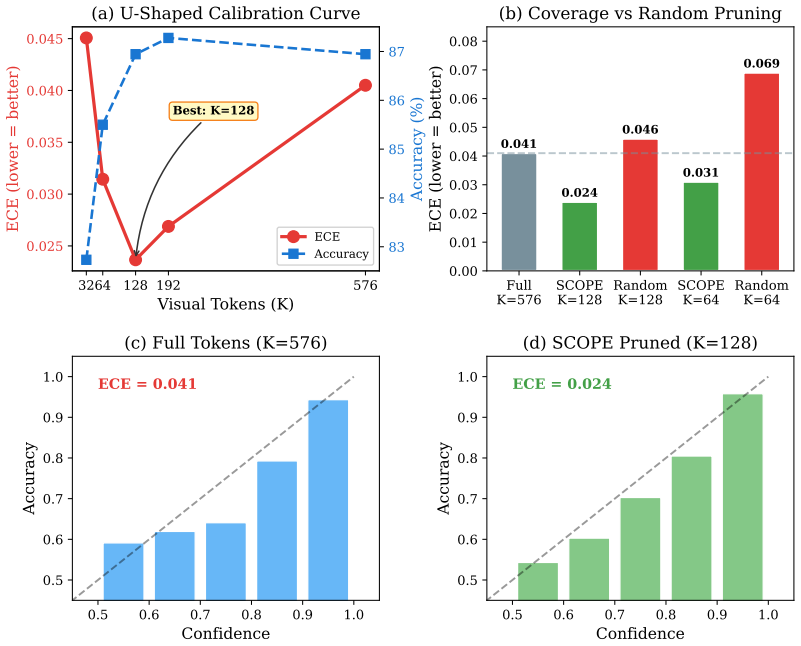
On POPE, a pure-coverage setting in SCOPE achieves substantially lower ECE than the full unpruned model while maintaining similar accuracy. An internal alpha-sweep shows reducing the saliency weight improves calibration at all tested token budgets, while accuracy changes only slightly. In contrast, saliency-based pruning leads to worse calibration and real FastV causes severe performance degradation. On ScienceQA-IMG, pruning also reduces ECE with accuracy remaining stable or slightly improving. The default gap power exponent in coverage-based selection is not always optimal.
What carries the argument
SCOPE pruning with adjustable saliency weight alpha, evaluated by Expected Calibration Error (ECE) on visual question-answering tasks.
If this is right
- Certain pruning choices can improve reliability of confidence estimates without accuracy loss.
- Saliency weight acts as a tunable knob that trades off accuracy and calibration in predictable ways.
- Saliency-only and FastV-style pruning degrade calibration more than coverage-based alternatives.
- The gap power exponent in coverage selection should be tuned rather than left at default.
- Multimodal systems needing trustworthy decisions must track calibration metrics when adopting pruning.
Where Pith is reading between the lines
- These patterns suggest pruning could be used deliberately to produce more trustworthy confidence scores in deployed multimodal agents.
- Combining coverage-based pruning with post-hoc calibration methods might yield additive gains not tested here.
- The results raise the question of whether similar calibration benefits appear in vision-only or language-only pruning regimes.
- If the trend holds, evaluation benchmarks for efficient MLLMs should routinely include ECE alongside accuracy.
Load-bearing premise
The calibration trends observed with these specific datasets, model, token budgets, and pruning implementations will generalize beyond the tested conditions.
What would settle it
Repeating the experiments on a different MLLM or dataset such as LLaVA-Next or VQA v2 and observing that all tested pruning methods increase ECE relative to the unpruned baseline.
Figures


read the original abstract
Visual token pruning is a widely used strategy for efficient inference in multimodal large language models (MLLMs), but existing work mainly evaluates it with task accuracy. In this paper, we study how visual token pruning affects model calibration, that is, whether predicted confidence matches actual correctness. Using LLaVA-1.5-7B on POPE and ScienceQA-IMG, we evaluate Expected Calibration Error (ECE), Brier score, and AURC under several pruning strategies, including SCOPE with different saliency weights, saliency-only pruning, FastV, and random pruning, across multiple token budgets. Our results show that pruning does not simply trade reliability for efficiency. On POPE, a pure-coverage setting in SCOPE achieves substantially lower ECE than the full unpruned model while maintaining similar accuracy. An internal alpha-sweep further shows a consistent trend: reducing the saliency weight improves calibration at all tested token budgets, while accuracy changes only slightly. In contrast, saliency-based pruning leads to worse calibration, and real FastV causes severe performance degradation in our setting. On ScienceQA-IMG, pruning also reduces ECE, with accuracy remaining stable or slightly improving. We additionally study the gap power exponent in coverage-based selection and find that its default setting is not always optimal. Overall, our results suggest that visual token pruning should be evaluated not only by accuracy, but also by confidence quality, especially for multimodal systems that need reliable decisions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an empirical study examining how visual token pruning strategies affect calibration (via ECE, Brier score, and AURC) in multimodal LLMs, using LLaVA-1.5-7B on POPE and ScienceQA-IMG. It compares SCOPE (with varying saliency weights alpha), saliency-only pruning, FastV, and random pruning across token budgets. Central observations are that pure-coverage SCOPE on POPE yields substantially lower ECE than the unpruned baseline at comparable accuracy, that lowering alpha consistently improves calibration, and that pruning reduces ECE on ScienceQA-IMG with stable or slightly improved accuracy; the work concludes that pruning should be assessed on confidence quality in addition to accuracy.
Significance. If the directional trends hold under broader conditions, the work is significant for shifting evaluation of efficiency methods in MLLMs beyond accuracy to include calibration, which matters for reliable decision-making. It supplies concrete, controlled comparisons across multiple pruning variants and budgets on two datasets, and the internal alpha-sweep provides a falsifiable pattern that can guide follow-up work.
major comments (2)
- [Abstract and Results] Abstract and Results: the headline claim that 'pruning does not simply trade reliability for efficiency' and the recommendation to evaluate pruning on confidence quality rest on experiments with only LLaVA-1.5-7B; without cross-model validation on other MLLM architectures the observed ECE reductions could be architecture-specific rather than general.
- [Experiments/Results] Experiments/Results: no error bars, standard deviations across seeds, or statistical significance tests are reported for the ECE and accuracy differences (e.g., the 'substantially lower ECE' for pure-coverage SCOPE on POPE); this weakens the ability to judge whether the calibration gains are robust or could be due to run-to-run variation.
minor comments (1)
- [Abstract] Abstract: the phrase 'gap power exponent in coverage-based selection' is introduced without definition or citation; a brief parenthetical explanation or reference would improve accessibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our empirical study. The comments correctly identify limitations in model scope and statistical reporting. We address each major comment below and will revise the manuscript to strengthen the presentation without overstating generality.
read point-by-point responses
-
Referee: [Abstract and Results] Abstract and Results: the headline claim that 'pruning does not simply trade reliability for efficiency' and the recommendation to evaluate pruning on confidence quality rest on experiments with only LLaVA-1.5-7B; without cross-model validation on other MLLM architectures the observed ECE reductions could be architecture-specific rather than general.
Authors: We agree that the experiments are restricted to LLaVA-1.5-7B and that the ECE reductions may not generalize to other MLLM architectures. The manuscript does not claim universality; however, the abstract and conclusion use phrasing that could be read as broader. In the revised version we will explicitly qualify all headline statements (abstract, introduction, and conclusion) to note that results are for LLaVA-1.5-7B, add a limitations paragraph discussing the single-model scope, and explicitly recommend cross-model validation in future work. This preserves the value of the controlled comparisons while removing any implication of generality. revision: yes
-
Referee: [Experiments/Results] Experiments/Results: no error bars, standard deviations across seeds, or statistical significance tests are reported for the ECE and accuracy differences (e.g., the 'substantially lower ECE' for pure-coverage SCOPE on POPE); this weakens the ability to judge whether the calibration gains are robust or could be due to run-to-run variation.
Authors: We concur that the absence of variability measures limits assessment of robustness. The original runs used fixed seeds for reproducibility. For the revision we will re-execute the key POPE configurations (unpruned baseline, pure-coverage SCOPE at multiple budgets, and the alpha sweep) with at least three independent random seeds, report mean ECE and accuracy together with standard deviations, and add a brief statistical comparison (e.g., noting whether differences exceed one standard deviation). This will directly address concerns about run-to-run variation. revision: yes
Circularity Check
No circularity: pure empirical evaluation with no derivations or self-defined quantities
full rationale
This paper is a pure empirical study that runs experiments on LLaVA-1.5-7B using POPE and ScienceQA-IMG datasets, measuring ECE, Brier score, and AURC under various pruning strategies (SCOPE with alpha sweeps, FastV, random) and token budgets. No equations, derivations, fitted parameters presented as predictions, or load-bearing self-citations exist; all claims are direct experimental observations. The work is self-contained against external benchmarks, with no reduction of results to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Expected Calibration Error, Brier score, and AURC are appropriate and sufficient measures of model confidence quality.
Reference graph
Works this paper leans on
-
[1]
DivPrune: Diversity-based visual token pruning for large multimodal models
Saeed Ranjbar Alvar, Gursimran Singh, Mohammad Akbari, and Yong Zhang. DivPrune: Diversity-based visual token pruning for large multimodal models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recog- nition, 2025
work page 2025
-
[2]
Changwoo Baek, Jouwon Song, Sohyeon Kim, and Kyeongbo Kong. AgilePruner: An empirical study of attention and diver- sity for adaptive visual token pruning in large vision-language models.arXiv preprint arXiv:2603.01236, 2026
-
[3]
Liang Chen, Haozhe Zhao, Tianyu Liu, Shuai Bai, Junyang Lin, Chang Zhou, and Baobao Chang. An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models. InProceedings of the European Conference on Computer Vision, 2024. 8
work page 2024
-
[4]
OTPrune: Distribution-aligned visual token pruning via optimal transport
Xiwen Chen, Wenhui Zhu, Gen Li, Xuanzhao Dong, Yu- jian Xiong, Hao Wang, Peijie Qiu, Qingquan Song, Zhipeng Wang, Shao Tang, Yalin Wang, and Abolfazl Razi. OTPrune: Distribution-aligned visual token pruning via optimal transport. arXiv preprint arXiv:2602.20205, 2026
-
[5]
Zijun Chen, Wenbo Hu, Guande He, Zhijie Deng, Zheng Zhang, and Richang Hong. Unveiling uncertainty: A deep dive into calibration and performance of multimodal large language models. InProceedings of the 31st International Conference on Computational Linguistics, 2025
work page 2025
-
[6]
FLoC: Facility location-based efficient visual token compression for long video understanding
Janghoon Cho, Jungsoo Lee, Munawar Hayat, Kyuwoong Hwang, Fatih Porikli, and Sungha Choi. FLoC: Facility location-based efficient visual token compression for long video understanding. InInternational Conference on Learning Representations, 2026
work page 2026
-
[7]
SCOPE: Saliency-coverage oriented token pruning for effi- cient multimodal LLMs
Jinhong Deng, Wen Li, Joey Tianyi Zhou, and Yang He. SCOPE: Saliency-coverage oriented token pruning for effi- cient multimodal LLMs. InAdvances in Neural Information Processing Systems, 2025
work page 2025
-
[8]
Zhengyao Fang, Pengyuan Lyu, Chengquan Zhang, Guang- ming Lu, Jun Yu, and Wenjie Pei. Prune redundancy, preserve essence: Vision token compression in VLMs via synergistic importance-diversity. InInternational Conference on Learning Representations, 2026
work page 2026
-
[9]
Evaluating object hallucination in large vision-language models
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vision-language models. InProceedings of the 2023 Con- ference on Empirical Methods in Natural Language Processing, 2023
work page 2023
-
[10]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. InAdvances in Neural Information Processing Systems, 2023
work page 2023
-
[11]
LLaV A-NeXT: Improved rea- soning, OCR, and world knowledge
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. LLaV A-NeXT: Improved rea- soning, OCR, and world knowledge. https://llava-vl. github.io/blog/2024-01-30-llava-next/ ,
work page 2024
-
[12]
Learn to explain: Multimodal reasoning via thought chains for science question answering
Pan Lu, Swaroop Mishra, Tony Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. Learn to explain: Multimodal reasoning via thought chains for science question answering. InAdvances in Neural Information Processing Systems, 2022
work page 2022
-
[13]
Runyu Ma, Songqing Chen, and Shuochao Yao. Better relia- bility compression: Model pruning with calibrated uncertainty estimation for mobile deep learning applications. In2025 IEEE 3rd International Conference on Mobility, Operations, Services and Technologies (MOST), 2025
work page 2025
-
[14]
Uncovering the hidden cost of model compression
Diganta Misra, Muawiz Chaudhary, Agam Goyal, Bharat Run- wal, and Pin-Yu Chen. Uncovering the hidden cost of model compression. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 2024
work page 2024
-
[15]
Pallavi Mitra, Gesina Schwalbe, and Nadja Klein. Investigat- ing calibration and corruption robustness of post-hoc pruned perception CNNs: An image classification benchmark study. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 2024
work page 2024
-
[16]
Qizhe Zhang, Mengzhen Liu, Lichen Li, Ming Lu, Yuan Zhang, Junwen Pan, Qi She, and Shanghang Zhang. CDPruner: Be- yond attention or similarity: Maximizing conditional diversity for token pruning in MLLMs. InAdvances in Neural Informa- tion Processing Systems, 2025
work page 2025
-
[17]
arXiv preprint arXiv:2411.11919 (2024) 2, 3, 4, 6, 10, 12, 13, 14, 18
Ruiyang Zhang, Hu Zhang, and Zhedong Zheng. VL- Uncertainty: Detecting hallucination in large vision- language model via uncertainty estimation.arXiv preprint arXiv:2411.11919, 2024
-
[18]
Gudovskiy, Tomoyuki Okuno, Yohei Nakata, Kurt Keutzer, and Shanghang Zhang
Yuan Zhang, Chun-Kai Fan, Junpeng Ma, Wenzhao Zheng, Tao Huang, Kuan Cheng, Denis A. Gudovskiy, Tomoyuki Okuno, Yohei Nakata, Kurt Keutzer, and Shanghang Zhang. Sparse- VLM: Visual token sparsification for efficient vision-language model inference. InProceedings of the 42nd International Conference on Machine Learning, 2025
work page 2025
-
[19]
Calibrated self-rewarding vision lan- guage models
Yiyang Zhou, Zhiyuan Fan, Dongjie Cheng, Sihan Yang, Zhaorun Chen, Chenhang Cui, Xiyao Wang, Yun Li, Linjun Zhang, and Huaxiu Yao. Calibrated self-rewarding vision lan- guage models. InAdvances in Neural Information Processing Systems, 2024. 9
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.