Scaling In-Context Segmentation with Hierarchical Supervision
Pith reviewed 2026-05-10 15:11 UTC · model grok-4.3
The pith
PatchICL uses selective patching and hierarchical supervision to reduce compute in in-context medical image segmentation by 44 percent while matching global attention accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
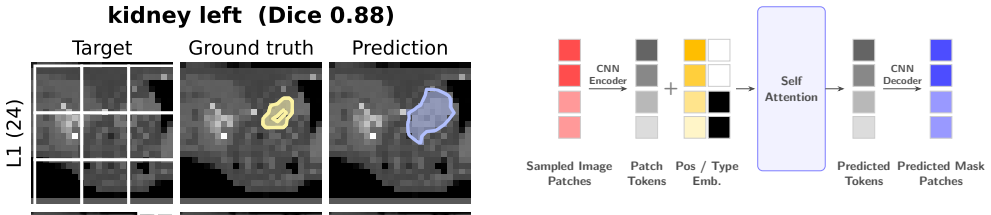
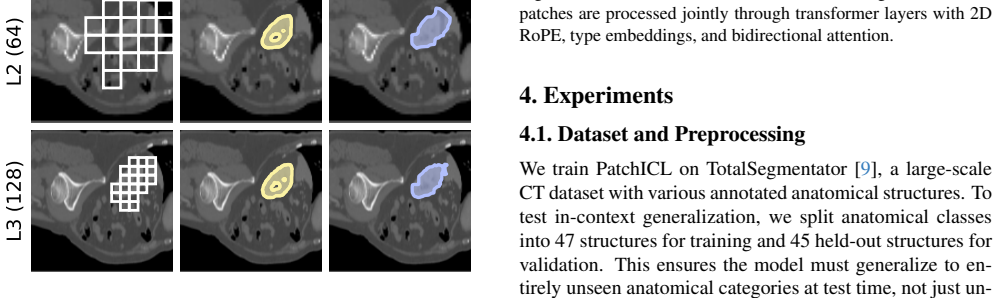
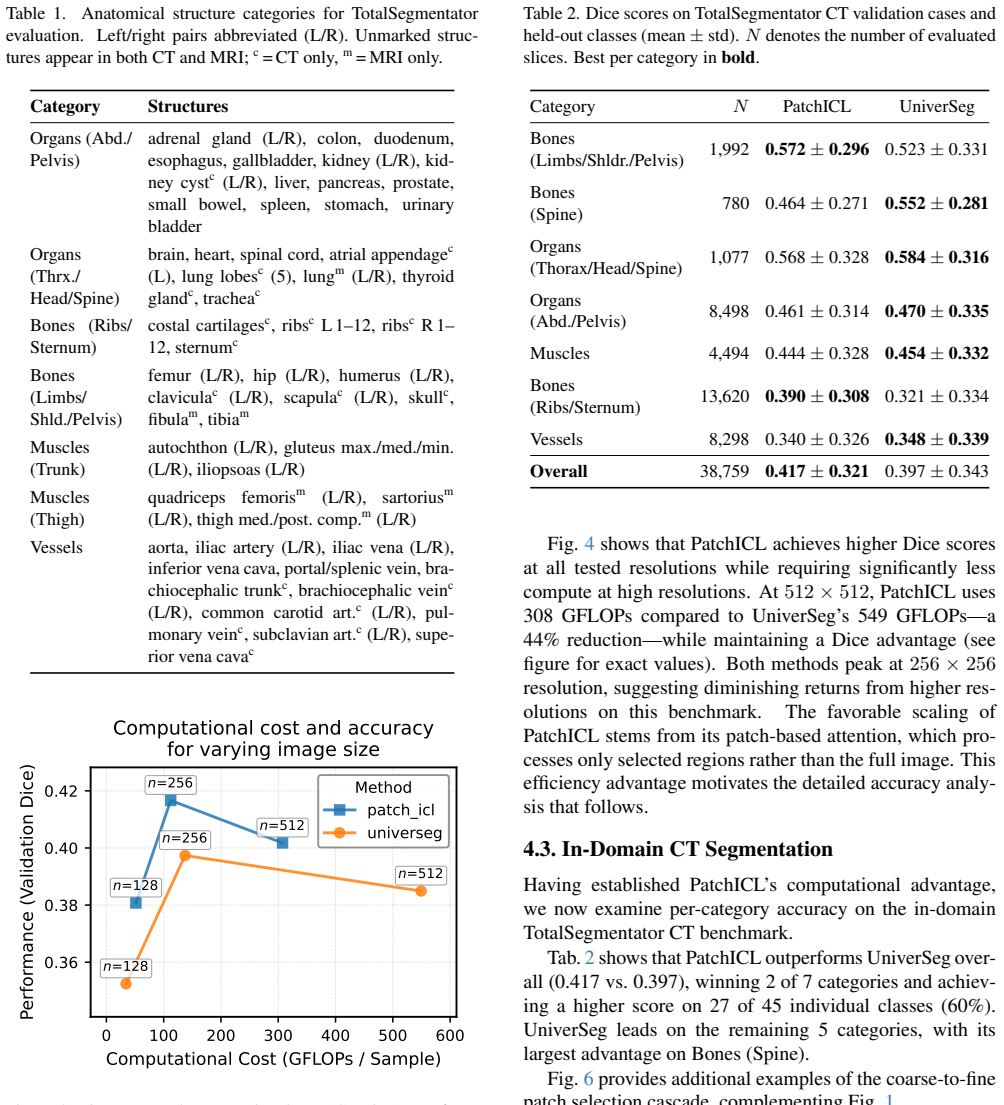
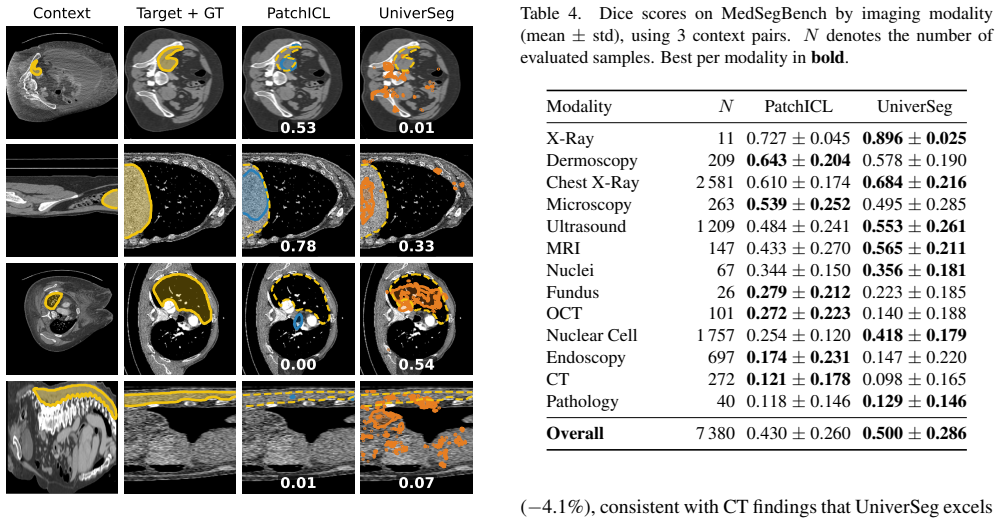
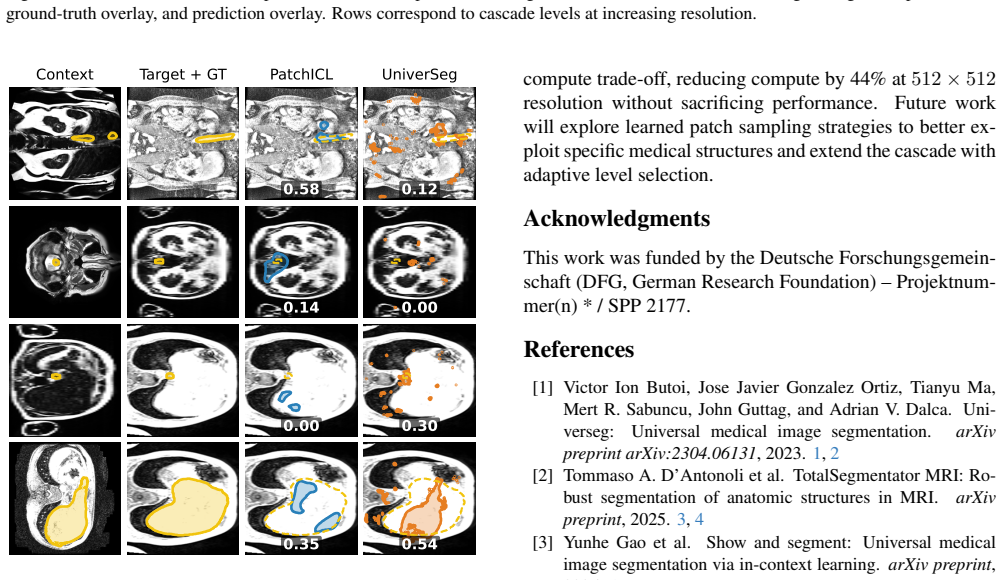
PatchICL is a hierarchical framework that combines selective image patching with multi-level supervision so the model learns to actively identify and attend only to the most informative anatomical regions, achieving competitive in-domain CT segmentation accuracy while reducing compute by 44 percent at 512 by 512 resolution and outperforming a global-attention baseline on 6 of 13 out-of-domain modality categories.
What carries the argument
Hierarchical supervision that trains a patch-selection module to restrict attention to the most relevant anatomical regions.
If this is right
- PatchICL matches UniverSeg accuracy on in-domain CT segmentation at 512 by 512 resolution but uses 44 percent less compute.
- The method outperforms the global-attention baseline on 6 of 13 modality categories across 35 out-of-domain datasets.
- Gains are largest on modalities dominated by localized pathology such as OCT and dermoscopy.
- Explicit supervision on the selection process reduces redundant computation in non-informative image regions.
Where Pith is reading between the lines
- The same selection-plus-hierarchy pattern could be tested on other dense-prediction tasks that currently rely on full cross-attention.
- If patch selection proves reliable, clinical systems could process higher-resolution scans in real time without proportional increases in hardware cost.
- When pathology is diffuse rather than focal, the current hierarchical signal might need an additional global-context term to avoid under-segmentation.
Load-bearing premise
The learned patch selection will always capture every region needed for accurate segmentation even when the target anatomy or pathology is not localized.
What would settle it
On a new out-of-domain dataset with diffuse pathology spread across the entire image, PatchICL would need to produce clearly lower Dice scores than the global baseline while still using far fewer patches.
Figures

read the original abstract
In-context learning (ICL) enables medical image segmentation models to adapt to new anatomical structures from limited examples, reducing the clinical annotation burden. However, standard ICL methods typically rely on dense, global cross-attention, which scales poorly with image resolution. While recent approaches have introduced localized attention mechanisms, they often lack explicit supervision on the selection process, leading to redundant computation in non-informative regions. We propose PatchICL, a hierarchical framework that combines selective image patching with multi-level supervision. Our approach learns to actively identify and attend only to the most informative anatomical regions. Compared to UniverSeg, a strong global-attention baseline, PatchICL achieves competitive in-domain CT segmentation accuracy while reducing compute by 44\% at $512\times512$ resolution. On 35 out-of-domain datasets spanning diverse imaging modalities, PatchICL outperforms the baseline on 6 of 13 modality categories, with particular strength on modalities dominated by localized pathology such as OCT and dermoscopy. Training and evaluation code are available at https://github.com/tidiane-camaret/ic_segmentation
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PatchICL, a hierarchical in-context learning framework for medical image segmentation that combines selective image patching with multi-level supervision to focus computation on informative regions. It claims competitive in-domain CT segmentation accuracy versus the global-attention baseline UniverSeg while achieving a 44% compute reduction at 512×512 resolution, plus outperformance on 6 of 13 out-of-domain modality categories (with noted strength on localized pathologies such as OCT and dermoscopy) across 35 datasets.
Significance. If the results prove robust, the work could meaningfully advance scalable in-context segmentation for high-resolution medical images by reducing compute without sacrificing accuracy, directly addressing annotation burden in clinical settings. The open-sourced code at the provided GitHub link is a clear strength for reproducibility.
major comments (2)
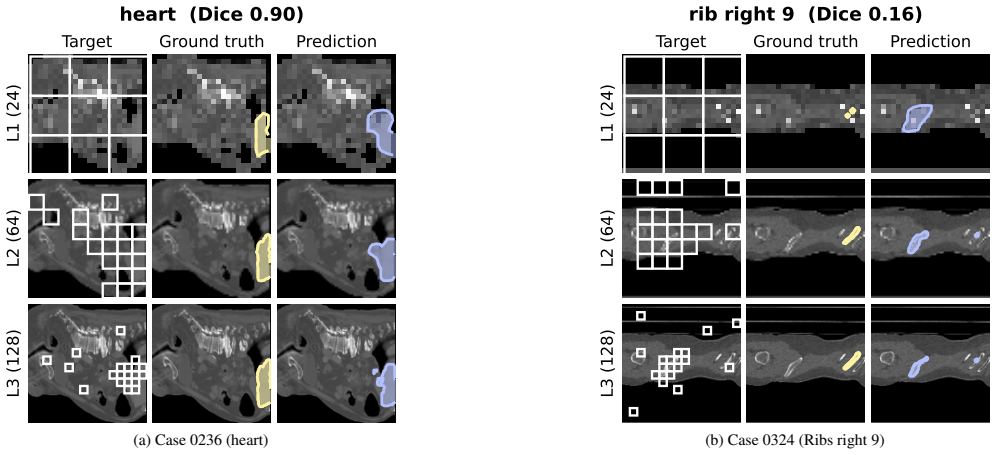
- [§4.2] §4.2 (OOD evaluation): The headline claim of outperformance on 6 of 13 modality categories rests on the assumption that the learned patch selector under hierarchical supervision surfaces all clinically relevant regions; however, no per-modality breakdown, failure-case analysis, or comparison of localized vs. diffuse pathology is provided, leaving open whether gains are an artifact of the test distribution rather than a general property.
- [§4.1] §4.1 and Table 2: The reported 44% compute reduction and competitive in-domain accuracy lack error bars, statistical significance tests, or details on out-of-domain split construction and baseline tuning; without these, it is impossible to assess whether post-hoc choices affect the comparison to UniverSeg.
minor comments (2)
- [Abstract and §3] The abstract and §3 could clarify the exact multi-level supervision losses and how patch selection thresholds are set during inference to improve reproducibility.
- [Figures] Figure captions for patch selection visualizations should include examples from diffuse-pathology cases to directly address potential context loss.
Simulated Author's Rebuttal
We sincerely thank the referee for their detailed and constructive feedback on our manuscript. We address each major comment below and commit to revisions that enhance the transparency and robustness of our evaluations.
read point-by-point responses
-
Referee: [§4.2] §4.2 (OOD evaluation): The headline claim of outperformance on 6 of 13 modality categories rests on the assumption that the learned patch selector under hierarchical supervision surfaces all clinically relevant regions; however, no per-modality breakdown, failure-case analysis, or comparison of localized vs. diffuse pathology is provided, leaving open whether gains are an artifact of the test distribution rather than a general property.
Authors: We acknowledge the referee's concern that additional granularity is needed to substantiate the OOD claims. While the manuscript notes particular strength on localized pathologies such as OCT and dermoscopy, we agree that a per-modality breakdown and failure-case analysis would better demonstrate generality. In the revised version, we will add a supplementary table with per-modality Dice scores and compute a localized-vs-diffuse pathology comparison using the existing 35-dataset suite. We will also include representative success and failure visualizations to show that the patch selector focuses on clinically relevant regions across modalities. revision: yes
-
Referee: [§4.1] §4.1 and Table 2: The reported 44% compute reduction and competitive in-domain accuracy lack error bars, statistical significance tests, or details on out-of-domain split construction and baseline tuning; without these, it is impossible to assess whether post-hoc choices affect the comparison to UniverSeg.
Authors: We agree that statistical rigor and experimental transparency are essential. In the revision we will augment Table 2 with error bars (standard deviation over three independent runs), report p-values from paired statistical tests comparing PatchICL to UniverSeg, and expand §4.1 with explicit details on OOD split construction (random patient-level partitioning per modality) and the hyperparameter search performed for the UniverSeg baseline to ensure the comparison is fair and reproducible. revision: yes
Circularity Check
No circularity: empirical results rest on external baseline comparisons
full rationale
The paper is an empirical ML contribution that proposes PatchICL and reports direct measurements of accuracy and compute against the external UniverSeg baseline on in-domain CT and 35 out-of-domain datasets. No derivation chain, equations, or first-principles results are present in the provided text that could reduce to fitted inputs or self-citations by construction. The 44% compute reduction is stated as a measured quantity at fixed resolution, and OOD performance is evaluated on held-out modalities rather than predicted from internal parameters. This is the normal case of a self-contained empirical paper whose central claims are falsifiable against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Sabuncu, John Guttag, and Adrian V
Victor Ion Butoi, Jose Javier Gonzalez Ortiz, Tianyu Ma, Mert R. Sabuncu, John Guttag, and Adrian V . Dalca. Uni- verseg: Universal medical image segmentation.arXiv preprint arXiv:2304.06131, 2023. 1, 2
-
[2]
Tommaso A. D’Antonoli et al. TotalSegmentator MRI: Ro- bust segmentation of anatomic structures in MRI.arXiv preprint, 2025. 3, 4
work page 2025
-
[3]
Show and segment: Universal medical image segmentation via in-context learning.arXiv preprint,
Yunhe Gao et al. Show and segment: Universal medical image segmentation via in-context learning.arXiv preprint,
-
[4]
Medverse: A universal model for medical image segmentation.arXiv preprint, 2025
others Hu. Medverse: A universal model for medical image segmentation.arXiv preprint, 2025. 1, 2
work page 2025
-
[5]
Wouter Kool, Herke van Hoof, and Max Welling. Stochastic beams and where to find them: The gumbel-top-k trick for sampling sequences without replacement, 2019. 2
work page 2019
-
[6]
MedSegBench: A comprehensive benchmark for medical image segmentation.arXiv preprint, 2024
Zeki Kus et al. MedSegBench: A comprehensive benchmark for medical image segmentation.arXiv preprint, 2024. 3, 5
work page 2024
-
[7]
Tyche: Stochastic in-context learning for medical image segmentation.arXiv preprint, 2025
Marianne Rakic et al. Tyche: Stochastic in-context learning for medical image segmentation.arXiv preprint, 2025. 1
work page 2025
-
[8]
Deep neural patchworks: Coping with large segmentation tasks
Marco Reisert et al. Deep neural patchworks: Coping with large segmentation tasks. InMedical Image Computing and Computer Assisted Intervention, 2022. 2
work page 2022
-
[9]
Jakob Wasserthal et al. TotalSegmentator: Robust segmen- tation of 104 anatomic structures in CT images.Radiology: Artificial Intelligence, 2023. 3
work page 2023
-
[10]
EICSeg: Universal medical image segmentation via efficient in-context learning.arXiv preprint, 2026
others Xie. EICSeg: Universal medical image segmentation via efficient in-context learning.arXiv preprint, 2026. 1, 2
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.