DR³-Eval: Towards Realistic and Reproducible Deep Research Evaluation
Pith reviewed 2026-05-10 11:44 UTC · model grok-4.3
The pith
DR³-Eval provides a reproducible benchmark using static verifiable sandboxes to evaluate deep research agents on complex multimodal tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
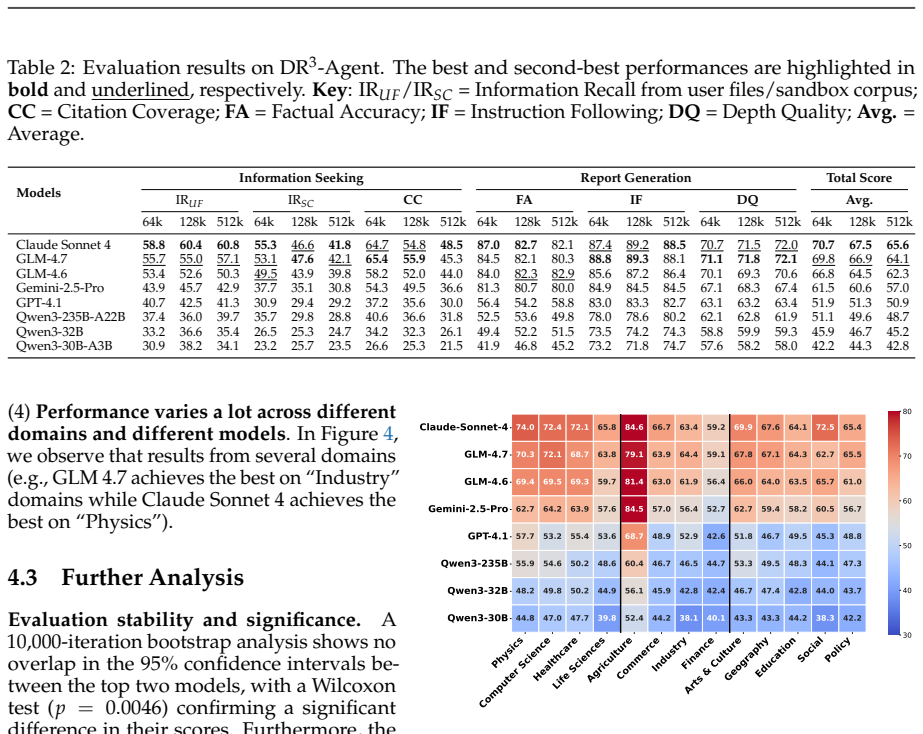
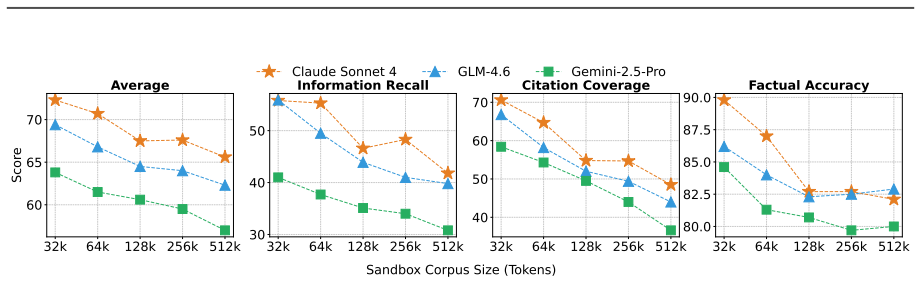
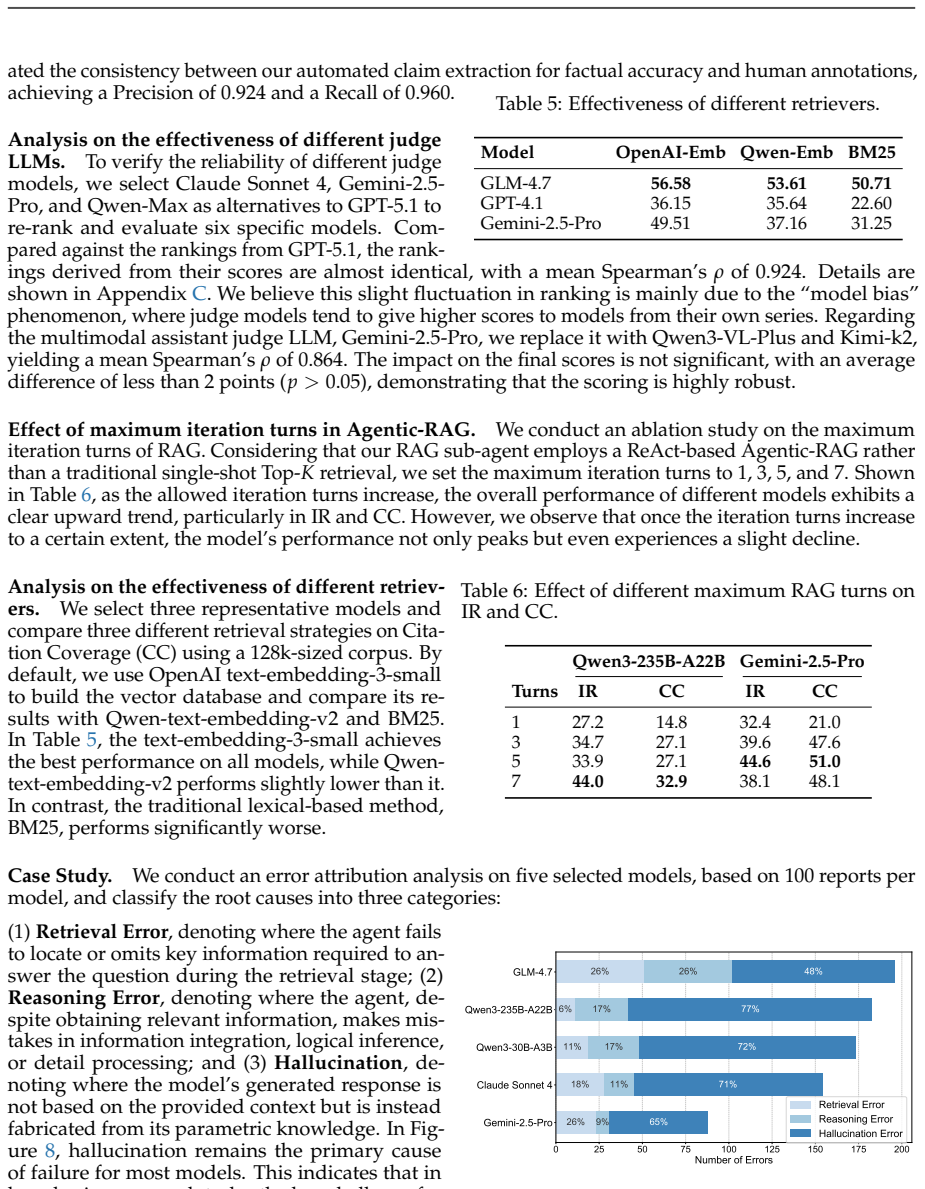
DR³-Eval is constructed from authentic user-provided materials and paired with a per-task static research sandbox corpus that simulates open-web complexity while remaining fully verifiable, containing supportive documents, distractors, and noise. A multi-dimensional evaluation framework measures Information Recall, Factual Accuracy, Citation Coverage, Instruction Following, and Depth Quality, and it aligns with human judgments. Experiments using a multi-agent system based on multiple state-of-the-art language models show that the benchmark is highly challenging and reveals critical failure modes in retrieval robustness and hallucination control.
What carries the argument
The per-task static research sandbox corpus, which simulates open-web complexity in a fully verifiable manner by including supportive documents, distractors, and noise alongside authentic task materials.
If this is right
- Current deep research agents struggle with maintaining retrieval robustness across the benchmark tasks.
- These agents have difficulty controlling hallucinations in their generated multimodal reports.
- The proposed multi-dimensional evaluation aligns closely with human judgments of report quality.
- The benchmark enables reproducible experiments without reliance on dynamic web environments.
Where Pith is reading between the lines
- Approaches like this static sandbox could be extended to create benchmarks for agent performance in other knowledge-intensive fields.
- Identifying these specific failure modes may guide targeted improvements in agent design for better fact handling.
- Reproducible benchmarks of this type could accelerate progress by providing consistent metrics for comparing new agent architectures.
Load-bearing premise
The per-task static research sandbox corpus simulates open-web complexity while remaining fully verifiable, containing supportive documents, distractors, and noise.
What would settle it
Showing that state-of-the-art models complete the tasks with high scores on all evaluation dimensions and without retrieval or hallucination issues would challenge the claim that the benchmark reveals critical failure modes.
Figures








read the original abstract
Deep Research Agents (DRAs) aim to solve complex, long-horizon research tasks involving planning, retrieval, multimodal understanding, and report generation, yet their evaluation remains challenging due to dynamic web environments and ambiguous task definitions. We propose DR$^{3}$-Eval, a realistic and reproducible benchmark for evaluating deep research agents on multimodal, multi-file report generation. DR$^{3}$-Eval is constructed from authentic user-provided materials and paired with a per-task static research sandbox corpus that simulates open-web complexity while remaining fully verifiable, containing supportive documents, distractors, and noise. Moreover, we introduce a multi-dimensional evaluation framework measuring Information Recall, Factual Accuracy, Citation Coverage, Instruction Following, and Depth Quality, and validate its alignment with human judgments. Experiments with our developed multi-agent system DR$^{3}$-Agent based on multiple state-of-the-art language models demonstrate that DR$^{3}$-Eval is highly challenging and reveals critical failure modes in retrieval robustness and hallucination control. Our code and data are publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DR³-Eval, a benchmark for Deep Research Agents focused on multimodal, multi-file report generation tasks. It pairs authentic user materials with a per-task static research sandbox corpus containing supportive documents, distractors, and noise, intended to simulate open-web complexity while remaining verifiable. A multi-dimensional evaluation framework is introduced measuring Information Recall, Factual Accuracy, Citation Coverage, Instruction Following, and Depth Quality, with a claimed validation against human judgments. Experiments on the authors' DR³-Agent system using multiple state-of-the-art LLMs are said to show the benchmark is highly challenging and exposes failure modes in retrieval robustness and hallucination control. Code and data are released publicly.
Significance. If the evaluation framework's alignment with human judgments holds and the static sandbox successfully surfaces transferable failure modes, DR³-Eval could offer a valuable reproducible alternative to dynamic web evaluations for long-horizon research agents. The public code and data release is a clear strength for reproducibility.
major comments (2)
- [Abstract] Abstract: the claim that the multi-dimensional evaluation framework 'aligns with human judgments' is unsupported, as no details are provided on the human evaluation protocol, number of annotators, inter-annotator agreement, statistical tests, or quantitative alignment results.
- [Abstract and sandbox construction] Benchmark description (Abstract and sandbox construction section): the central claim that the per-task static research sandbox 'simulates open-web complexity' while revealing general failure modes rests on an untested assumption; a fixed corpus cannot reproduce live search ranking changes, temporal drift, or iterative reformulation against an evolving index, risking sandbox-specific artifacts rather than transferable limitations.
minor comments (1)
- [Abstract] Abstract: expand the DR³ acronym on first use and clarify whether 'multi-file' refers to multiple source documents or output files.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point by point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the multi-dimensional evaluation framework 'aligns with human judgments' is unsupported, as no details are provided on the human evaluation protocol, number of annotators, inter-annotator agreement, statistical tests, or quantitative alignment results.
Authors: We agree that the abstract would benefit from additional context to make this claim self-contained. The main body of the manuscript provides a dedicated description of the human evaluation protocol along with the associated quantitative alignment results. To address the concern, we will revise the abstract to include a concise reference to the validation approach and key findings, directing readers to the relevant section for full details. revision: yes
-
Referee: [Abstract and sandbox construction] Benchmark description (Abstract and sandbox construction section): the central claim that the per-task static research sandbox 'simulates open-web complexity' while revealing general failure modes rests on an untested assumption; a fixed corpus cannot reproduce live search ranking changes, temporal drift, or iterative reformulation against an evolving index, risking sandbox-specific artifacts rather than transferable limitations.
Authors: We acknowledge the inherent limitations of any static sandbox in fully replicating dynamic web behaviors such as ranking fluctuations, temporal changes, or iterative query reformulation against a live index. Our design prioritizes verifiability and reproducibility, which are necessary for a benchmark that supports consistent evaluation across research efforts. The corpus incorporates supportive documents, distractors, and noise to approximate open-web complexity, and the reported experiments highlight failure modes in retrieval and hallucination control. We will add an explicit discussion of these design trade-offs and the potential for sandbox-specific artifacts in the limitations section of the revised manuscript. revision: partial
Circularity Check
No circularity: benchmark and agent presented as independent artifacts
full rationale
The paper introduces DR³-Eval as a new benchmark constructed from authentic user materials paired with a per-task static sandbox, along with a multi-dimensional evaluation framework and a multi-agent system DR³-Agent. No equations, derivations, or predictions appear in the provided text. The sandbox is explicitly described as an independent construction that remains verifiable, with public code and data released. Experiments demonstrate challenges on this benchmark but do not reduce any claimed result to a fitted parameter or self-referential definition. Self-citations, if present, are not load-bearing for the central claims, satisfying the criteria for a self-contained empirical contribution.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human judgments constitute a reliable and stable ground truth for measuring report quality dimensions such as depth and factual accuracy
invented entities (1)
-
DR³-Eval benchmark with static sandbox corpus
no independent evidence
Reference graph
Works this paper leans on
-
[1]
China’s high-speed rail network is dense, especially in the east
-
[2]
The map shows the extensive network as of November 2023
work page 2023
-
[3]
The network includes lines with speeds of 300 km/h or more
-
[4]
Rail lines are color-coded by speed, from<200 to≥300 km/h
-
[5]
Map of Japan’s Shinkansen lines as of March 2025
work page 2025
-
[6]
Shows operational, planned, and under-construction routes
-
[7]
A future Linear Ch ¯u¯o Shinkansen (maglev) line is projected
-
[8]
The network connects major cities like Tokyo, Osaka, and Hakata
-
[9]
Developed from non-existent to world-class in just over 10 years
-
[10]
Current trains travel at world-leading speeds of 300-350 km/h
-
[11]
The new CR450 EMU prototype is the world’s fastest
-
[12]
CRH380A reaching up to 380 km/h
CR450 prototype reaches 450 km/h in tests. 20 Table 9: Evaluation of Information Recall from User Files. Number Status Evidence 1 Covered The network analysis reveals dense connectivity in eastern and central regions, with key routes connecting major cities... 2 Half Covered The map shows a well-developed network ... as of November 27, 2009, with continue...
work page 2009
-
[13]
Reducing aerodynamic resistance is crucial for faster trains
-
[14]
Shinkansen’s strengths are efficiency and passenger comfort
-
[15]
China has an ambitious 2035 high-speed rail expansion plan
work page 2035
-
[16]
Digital transformation is key to future rail network evolution
-
[17]
Future rail relies on IoT, 5G, and AI technologies
-
[18]
China plans to extend its HSR network to Southeast Asia. F.2 Citation Coverage Table 11: Evaluation of Citation Coverage. No. Source Title Status Web Page Coverage 1 Japan’s Shinkansen: How Does It Stack Up Worldwide?Cited 2 The global rail transportation market was valued at US$ 724,180 million in 2022 and, by 2029, is pro Cited (Continued on next page) ...
work page 2022
-
[19]
Concise: Query must be SHORT (50-100 words), like a real user’s brief question, not verbose 2.Natural: Query should be from user’s perspective, like a real person would ask
-
[20]
Guiding: Query topic should naturally lead agent to search “relevant keywords", but don’t over-hint
-
[21]
No Exposure: Don’t directly use technical terms from keywords, use simple natural expressions
-
[22]
Brief File Reference: Query must briefly mention user files, like “based on my xxx file" or “see attachment"
-
[23]
Cover All Results: Query must be designed so ALL len(useful_search) search results are needed for a complete answer, even if each result is only used a little
-
[24]
Use All Files: Query must be designed so ALL len(user_file_names) user files are needed for a complete answer, even if each file is only used a little Design Approach
-
[25]
Analyze the common theme of relevant keywords
-
[26]
Design a SHORT natural query (50-100 words), don’t over-describe background
-
[27]
Three-distance method spatial layout modern pocket park design cases
Query should: • Be short and direct, like a casual question • Not contain technical jargon or hint-like words • Briefly mention user files ExamplesIf relevant keywords are: - “Three-distance method spatial layout modern pocket park design cases" - “Scattered perspective step-by-step scenery urban micro-renewal" User file is: - Suzhou_Garden_Design.pdf ✗BA...
-
[30]
Machine learning requires large amounts of data
Atomicity: Each insight must be atomic, containing only 1-12 words, expressing a simple fact or concept Examples of Common Knowledge (DO NOT Extract) • “Machine learning requires large amounts of data"→This is common knowledge • “User experience is important"→This is common knowledge • “This method improved accuracy"→Too vague, no specific value or compar...
work page 2024
-
[31]
Source Contribution: Extract the main contribution of each source to answering the query, such as: • Methods/techniques/concepts introduced by the source (e.g., “proposes AfME em- bedding", “uses MCMC optimization") • Core topics or problems discussed by the source • Key conclusions or findings of the source • Note: No need to extract precise numbers (e.g...
-
[32]
Verifiability: Can determine whether the report mentions this information (semantic similarity is sufficient, exact match not required)
-
[33]
Machine learning requires large amounts of data
Atomicity: Each insight must be atomic, containing only 1-12 words, expressing a simple fact or concept Examples of Common Knowledge (DO NOT Extract) • “Machine learning requires large amounts of data"→This is common knowledge 28 • “User experience is important"→This is common knowledge • “This method improved accuracy"→Too vague, no specific value or com...
work page 2024
-
[34]
Atomic Decomposition: Break down complex requirements into minimal, independent checkpoints • Each requirement checks only one specific point • Example: “Analyze aspects A, B, and C" → Split into “Mention A", “Mention B", “Mention C" • Example: “Compare X and Y" → Split into “Describe X", “Describe Y", “Explain differences" 2.Short and Clear: Each require...
work page 2023
-
[35]
Only part of the core meaning is covered (missing key details)
-
[36]
The topic is mentioned but specifics are absent
-
[37]
Related concept exists but not the exact point
-
[38]
Generalization without the specific insight
-
[39]
Shanghai’s garbage classification coverage rate will reach 95% by 2023
The connection requires inference (not explicit) Examples of 0.5: • Insight: “Shanghai’s garbage classification coverage rate will reach 95% by 2023" Report: “Shanghai’s garbage classification has achieved significant results"→ 0.5 (topic covered, but no specific percentage) • Insight: “Germany adopts a dual track recycling system" Report: “Developed coun...
work page 2023
-
[40]
If >50% of core meaning is covered→1.0
-
[41]
If reasonable semantic connection exists→1.0
-
[42]
If only weak connection or keyword overlap→0.5
-
[43]
If no connection at all→0.0 Principle: Prefer false positives over false negatives (The goal of recall assessment is to check if information is missing) RESPONSE FORMAT Respond ONLY with valid JSON (no markdown, no extra text): “results": [ “id": 1, “core_points": [“point1", “point2"], “found_in_report": “[quote or describe what was found]", “missing_poin...
-
[44]
A statement is ageneralization, summary, inference, or extensionof the content of the source document
-
[45]
The statements use different wording, buthave similar semantics
-
[46]
The statement containsimplicit informationfrom the source document
-
[47]
For images/videos: The content described may be visually visible or inferable
-
[48]
The statement is areasonable interpretationof the content of the source document, even if it is not the only interpretation
-
[49]
The source document containspartially supportingcontent for this statement Situations where it is determined as supported: false (limited to the following situations) Only when one of the following conditions is met, it is determined as false:
-
[50]
Statements that aredirectly contradictoryto the source document (such as significant errors in numbers or completely opposite facts)
-
[51]
The source documentcompletely lacksany relevant content stated
-
[52]
The company’s revenue increased by 25% in 2023
The statement cannot be reasonably inferred from the source document Judgment principles • Allowsubstantial generalization and inference • Allowwording differencesanddifferent ways of expression • Allowpartially correctstatements (as long as they are not completely wrong) • For situations that areambiguous or uncertain, they should all be determined as tr...
work page 2023
-
[53]
A research question that the report attempts to answer <research_question> Question </research_question> <Report> result_text </Report> Instructions: ANALYZE THOROUGHLY: Examine the report in detail and identify any issues, even small ones. Look for subtle problems, minor inconsistencies, areas that could be improved, or any shortcomings that might affect...
-
[54]
Do NOT cluster scores in a narrow range
Use the FULL scoring range: Distribute scores across 1-10 based on actual quality differ- ences. Do NOT cluster scores in a narrow range
-
[55]
Only truly exceptional work deserves 10
Differentiate clearly: A mediocre report should score 4-5, a good report 6-7, an excellent report 8-9. Only truly exceptional work deserves 10
-
[56]
Better analysis, clearer structure, and deeper insights should result in higher scores
Be discriminating: Look for specific quality differences between reports. Better analysis, clearer structure, and deeper insights should result in higher scores
-
[57]
Penalize appropriately: Minor issues = small deductions (0.5-1 point), major issues = significant deductions (2-3 points)
-
[58]
Reward excellence: If a report demonstrates exceptional depth, clarity, or insight, give it the high score it deserves
-
[59]
Compare mentally: Consider how this report compares to the best and worst possible reports on this topic. Evaluation Criterion: Depth & Quality of Analysis Evaluate how thoroughly the report analyzes the research question.BE HARSH: Look for superficiality, missing details, lack of evidence, weak reasoning. •1-2: Completely superficial, no real analysis, j...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.