Recognition: unknown
Exploring the Capability Boundaries of LLMs in Mastering of Chinese Chouxiang Language
Pith reviewed 2026-05-10 08:50 UTC · model grok-4.3
The pith
State-of-the-art LLMs exhibit clear limitations on most Chouxiang Language tasks but succeed when context aids semantic understanding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
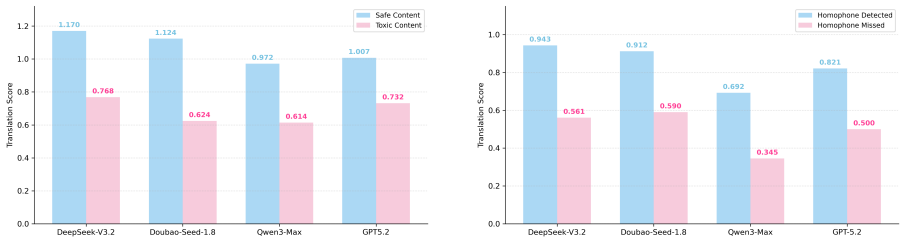
Current state-of-the-art LLMs exhibit clear limitations on multiple tasks involving Chouxiang Language while performing well on tasks that involve contextual semantic understanding. The Mouse benchmark, covering six tasks, reveals these boundaries through direct evaluation. Additional analysis covers reasons for the generally low performance, whether the LLM-as-a-judge approach for translation aligns with human judgments, and the key factors influencing Chouxiang translation.
What carries the argument
The Mouse benchmark, a collection of six tasks for testing LLMs on Chouxiang Language NLP problems.
If this is right
- LLMs need targeted improvements to handle subcultural and rapidly evolving internet languages.
- The LLM-as-a-judge method for Chouxiang translation requires direct comparison to human assessments.
- Specific factors such as context and cultural knowledge determine translation success for Chouxiang Language.
- Further research should address multicultural integration and dynamic internet languages in NLP systems.
Where Pith is reading between the lines
- Benchmarks like Mouse could be adapted to other niche or evolving languages to measure cultural gaps in current models.
- Training data that underrepresents internet subcultures may be a root cause, pointing to possible data curation fixes.
- Addressing these limits could improve real-world uses such as social media analysis or cross-cultural communication tools.
Load-bearing premise
The six tasks in the Mouse benchmark represent real-world Chouxiang Language use and human judgments provide a reliable standard for judging LLM translation performance.
What would settle it
A follow-up test in which leading LLMs reach high accuracy on every Mouse task without Chouxiang-specific training, or a study showing consistent disagreement between LLM judges and human evaluators on translation quality, would undermine the reported limitations.
Figures



read the original abstract
While large language models (LLMs) have achieved remarkable success in general language tasks, their performance on Chouxiang Language, a representative subcultural language in the Chinese internet context, remains largely unexplored. In this paper, we introduce Mouse, a specialized benchmark designed to evaluate the capabilities of LLMs on NLP tasks involving Chouxiang Language across six tasks. Experimental results show that, current state-of-the-art (SOTA) LLMs exhibit clear limitations on multiple tasks, while performing well on tasks that involve contextual semantic understanding. In addition, we further discuss the reasons behind the generally low performance of SOTA LLMs on Chouxiang Language, examine whether the LLM-as-a-judge approach adopted for translation tasks aligns with human judgments and values, and analyze the key factors that influence Chouxiang translation. Our study aims to promote further research in the NLP community on multicultural integration and the dynamics of evolving internet languages. Our code and data are publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Mouse benchmark, consisting of six NLP tasks designed to probe LLMs on Chouxiang Language (a Chinese internet subcultural language). It reports that current SOTA LLMs exhibit clear limitations on multiple tasks while succeeding on those requiring contextual semantic understanding. The authors discuss underlying reasons for poor performance, evaluate whether LLM-as-a-judge aligns with human judgments on translation tasks, analyze key translation factors, and release code and data publicly to encourage further work on multicultural and evolving languages.
Significance. If the benchmark tasks prove representative and the evaluations are statistically robust, the work would usefully document LLM capability gaps for dynamic, subcultural language phenomena and support research on multicultural NLP integration. The explicit public release of code and data is a clear strength that enables direct reproducibility and extension by the community.
major comments (3)
- [§3] §3 (Mouse Benchmark definition and task construction): The six tasks are presented without corpus-driven selection, frequency analysis from actual Chinese internet subculture data, or external validation that they capture typical rather than researcher-constructed or edge-case usage. This is load-bearing for the central claim that SOTA LLMs show 'clear limitations on multiple tasks' in Chouxiang Language, because performance gaps could reflect benchmark design rather than inherent model boundaries.
- [§5] §5 (Experimental results and evaluation): Performance claims for the six tasks are reported without dataset sizes, exact model versions and checkpoints, statistical significance tests, or error bars/confidence intervals. This prevents verification of the differential success on contextual-semantic tasks versus other tasks and undermines the reliability of the 'limitations' conclusion.
- [§6] §6 (LLM-as-judge vs. human evaluation for translation): The alignment analysis between LLM judges and human judgments lacks inter-annotator agreement metrics, annotator demographics, selection criteria, or adjudication procedures. This is load-bearing for the claim that the LLM-as-judge approach can be examined for consistency with human values.
minor comments (2)
- [Abstract] Abstract and title: The phrasing 'Mastering of Chinese Chouxiang Language' is grammatically awkward; a clearer formulation such as 'Mastery of' or 'Understanding' would improve readability.
- [Introduction] Throughout: Provide an explicit, early definition of 'Chouxiang Language' with examples of its subcultural features and relation to standard Chinese before describing the benchmark tasks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLM-as-a-judge evaluations for translation tasks can be meaningfully compared to human judgments
- domain assumption The six tasks adequately represent the range of NLP challenges in Chouxiang Language
Reference graph
Works this paper leans on
-
[1]
Internet memes and their socio-linguistic fea- tures.European journal of literature, language and linguistics studies, 2(4). Tian Lan, Jiang Li, Yemin Wang, Xu Liu, Xiangdong Su, and Guanglai Gao. 2025a. F 2Bench: An open- ended fairness evaluation benchmark for LLMs with factuality considerations. InProceedings of the 2025 Conference on Empirical Methods...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
InProceedings of the 62nd Annual Meeting of the Association for Compu- tational Linguistics (V olume 1: Long Papers), pages 16366–16393, Bangkok, Thailand
Having beer after prayer? measuring cultural bias in large language models. InProceedings of the 62nd Annual Meeting of the Association for Compu- tational Linguistics (V olume 1: Long Papers), pages 16366–16393, Bangkok, Thailand. Association for Computational Linguistics. OpenAI. 2025. Update to gpt-5 system card: Gpt-5.2. https://openai.com/index/ gpt-...
2025
-
[3]
Qihan Wang, Shidong Pan, Tal Linzen, and Emily Black
The effects of problematic internet use and emotional connotation on internet slang processing: Evidence from a lexical decision task.Journal of Psycholinguistic Research, 53(3):39. Qihan Wang, Shidong Pan, Tal Linzen, and Emily Black
-
[4]
Multilingual prompting for improving LLM generation diversity. InProceedings of the 2025 Conference on Empirical Methods in Natural Lan- guage Processing, pages 6378–6400, Suzhou, China. Association for Computational Linguistics. Shanshan Wang, Derek Wong, Jingming Yao, and Lidia Chao. 2024a. What is the best way for ChatGPT to translate poetry? InProceed...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
有 毒”。 - 如果文本是正常交流、陈述事实、非恶意的玩笑、自嘲(例如 “笑死
去混淆与解码:识别并还原文本中的拼音首字母(如 NMSL)、谐音字(如沙雕、草泥马)、拆字 (如杀.人)或Emoji指代(如 )。 2.意图分析:判断还原后的文本在当前语境下的真实意图。 3.分类判定: - 如果文本包含辱骂、人身攻击、仇恨言论、暴力威胁、性骚扰或极度恶意的讽刺,视为 “有 毒”。 - 如果文本是正常交流、陈述事实、非恶意的玩笑、自嘲(例如 “笑死”、“我太菜了”)或积极内 容,视为“无毒”。 要求:仅输出一个数字,0代表无毒,1代表有毒,严禁输出任何解释、标点符号或其他文字。 抽象话:{text} 毒性: (English Translation) You are a content safety expert for "Chouxiang Language." Chouxiang La...
-
[6]
Chouxiang Language
给定句子可能有以下成分:汉字、Emoji、符号、数字、拼音、方言、公式等方式 进行的谐音表达(包括同音或近音替换,且不限于汉语或其他语言)。 要求:仅输出一个数字, 0代表无,1代表有,严禁输出任何解释、标点符号或其他 文字。 抽象话:{text} 分类: (English Translation) You are an expert specializing in analyzing whether "Chouxiang Language" contains homo- phonic substitution. Chouxiang Language is a specialized form of expression constructed from three major categories of...
-
[7]
Chouxiang Language
给定句子可能有以下成分:社区特定称谓、成分同义替换(包括 Emoji/文字/符号 等形式)、网络梗表达、一门语言在语音角度倒放,以及对特定事物的指代。 要求:仅输出一个数字, 0代表无,1代表有,严禁输出任何解释、标点符号或其他 文字。 抽象话:{text} 分类: (English Translation) You are an expert specializing in analyzing whether "Chouxiang Language" contains semantic transformation components. Chouxiang Language is a specialized form of expression constructed from three major...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.