SaFeR-Steer: Evolving Multi-Turn MLLMs via Synthetic Bootstrapping and Feedback Dynamics
Pith reviewed 2026-05-15 09:46 UTC · model grok-4.3
The pith
SaFeR-Steer trains multi-turn multimodal models to hold safety and helpfulness against escalating attacks through synthetic bootstrapping and tutor feedback.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
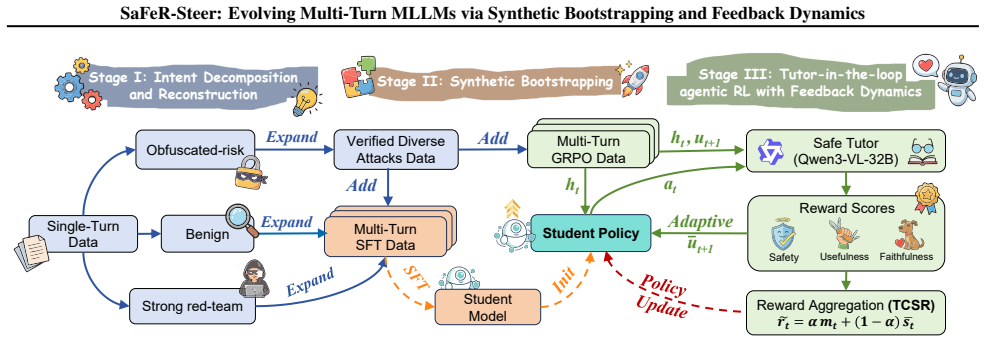
SaFeR-Steer is a progressive multi-turn alignment framework that combines staged synthetic bootstrapping with tutor-in-the-loop GRPO to train a single student under adaptive on-policy attacks. It introduces TCSR, which uses trajectory minimum and average safety to propagate late-turn failures to earlier turns. Starting from Qwen2.5-VL-3B and 7B models, the approach produces large gains in safety and helpfulness on single-turn and multi-turn benchmarks while shifting failures later in conversations.
What carries the argument
The SaFeR-Steer framework of staged synthetic bootstrapping combined with tutor-in-the-loop GRPO and TCSR for propagating safety signals across conversation trajectories.
If this is right
- Safety and helpfulness scores rise substantially on both single-turn and multi-turn benchmarks for the starting 3B and 7B models.
- Safety failures are shifted to later turns rather than appearing early in the conversation.
- The gains exceed what would be expected from scaling model size alone.
- A new dataset called STEER is released with splits for supervised fine-tuning, reinforcement learning, and benchmarking.
Where Pith is reading between the lines
- The same staged bootstrapping pattern could be tested on text-only models that face comparable multi-turn safety decay.
- Real deployment logs from diverse user bases would be needed to check whether performance holds when attack styles differ from the synthetic ones.
- The approach might combine with other feedback methods to further reduce reliance on large tutor models.
- Longer context windows could be studied by extending the trajectory safety propagation to conversations beyond ten turns.
Load-bearing premise
The synthetic attack dialogues and tutor feedback signals will produce training gradients that transfer to real-world multi-turn interactions instead of overfitting to the generated data distribution.
What would settle it
Testing the trained models on a separate collection of multi-turn dialogues created by human attackers or independent generation pipelines that were never used in the synthetic bootstrapping stage.
Figures




read the original abstract
MLLMs are increasingly deployed in multi-turn settings, where attackers can escalate unsafe intent through the evolving visual-text history and exploit long-context safety decay. Yet safety alignment is still dominated by single-turn data and fixed-template dialogues, leaving a mismatch between training and deployment. To bridge this gap, we propose SaFeR-Steer, a progressive multi-turn alignment framework that combines staged synthetic bootstrapping with tutor-in-the-loop GRPO to train a single student under adaptive, on-policy attacks. We also introduce Trajectory-Consistent Summative Reward (TCSR), which aggregates the historical minimum and average of turn rewards so that any low-quality turn affects the trajectory-level return. I. Dataset. We release STEER, a multi-turn multimodal safety dataset with STEER-SFT (12,934), STEER-RL (2,000), and STEER-Bench (3,227) dialogues spanning 2-10 turns. II. Experiment. Starting from Qwen2.5-VL-3B/7B, SaFeR-Steer substantially improves Safety/Helpfulness on both single-turn (48.30/45.86 $\rightarrow$ 81.84/70.77 for 3B; 56.21/60.32 $\rightarrow$ 87.89/77.40 for 7B) and multi-turn benchmarks (12.55/27.13 $\rightarrow$ 55.58/70.27 for 3B; 24.66/46.48 $\rightarrow$ 64.89/72.35 for 7B), shifting failures to later turns and yielding robustness beyond scaling alone. Code is available at https://anonymous.4open.science/r/SaFeR-Steer
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SaFeR-Steer, a progressive multi-turn alignment framework for MLLMs that combines staged synthetic bootstrapping with tutor-in-the-loop GRPO training under adaptive on-policy attacks. It introduces the TCSR mechanism to propagate late-turn safety failures backward along trajectories and releases the STEER dataset (STEER-SFT with 12,934 dialogues, STEER-RL with 2,000, and STEER-Bench with 3,227). Experiments starting from Qwen2.5-VL-3B/7B report large gains in safety/helpfulness on single-turn (e.g., 48.30/45.86 to 81.84/70.77 for 3B) and multi-turn benchmarks (e.g., 12.55/27.13 to 55.58/70.27 for 3B), with failures shifted to later turns.
Significance. If the gains are shown to arise from genuine generalization rather than synthetic-distribution match, the work addresses a clear deployment mismatch between single-turn safety training and multi-turn visual-text escalation attacks. The public release of the STEER dataset splits and code is a concrete positive contribution that enables reproducibility and follow-on research on multi-turn MLLM robustness.
major comments (3)
- [Dataset section (I)] Dataset section (I): the manuscript provides no explicit description of the generation procedures, attack templates, or visual-text coupling rules used to create STEER-Bench dialogues versus those used for STEER-SFT and STEER-RL. Because all splits originate from the same synthetic bootstrapping pipeline, overlap or distributional similarity cannot be ruled out; this directly undermines the claim that the multi-turn gains (e.g., 12.55 → 55.58 safety on 3B) reflect robustness rather than memorization of tutor-generated patterns.
- [Experiments section (II)] Experiments section (II): the reported metric deltas lack any mention of benchmark construction details, attack-generation diversity metrics, or statistical significance tests (e.g., confidence intervals or paired tests across seeds). Without these, it is impossible to assess whether the observed shifts in failure timing are reliable or artifacts of the specific tutor model and synthetic process.
- [TCSR description] TCSR description: the trajectory-min/average safety propagation is presented as addressing late-turn decay, yet no ablation isolates its contribution from the synthetic data distribution itself. The paper should show that TCSR improves performance on held-out real-world escalation patterns rather than only on tutor-generated trajectories.
minor comments (2)
- [Method] Clarify the exact definition and weighting of the safety and helpfulness reward components inside the GRPO objective; the current description leaves the balance between the two objectives ambiguous.
- [Figures] Figure captions and axis labels should explicitly state the number of evaluation runs and any error bars; several reported point estimates appear without variance information.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback, which highlights important areas for improving clarity, rigor, and reproducibility. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core claims. All changes will be incorporated in the next version.
read point-by-point responses
-
Referee: Dataset section (I): the manuscript provides no explicit description of the generation procedures, attack templates, or visual-text coupling rules used to create STEER-Bench dialogues versus those used for STEER-SFT and STEER-RL. Because all splits originate from the same synthetic bootstrapping pipeline, overlap or distributional similarity cannot be ruled out; this directly undermines the claim that the multi-turn gains (e.g., 12.55 → 55.58 safety on 3B) reflect robustness rather than memorization of tutor-generated patterns.
Authors: We agree that the original manuscript omitted these procedural details for brevity. In the revision, we will expand the Dataset section with a new subsection explicitly describing the generation pipeline, attack templates, visual-text coupling rules, and the criteria used to partition dialogues into STEER-SFT, STEER-RL, and STEER-Bench. We will also include quantitative overlap analysis (e.g., n-gram similarity, embedding cosine distances) and diversity metrics across splits to demonstrate that STEER-Bench evaluates generalization rather than simple memorization of tutor patterns. revision: yes
-
Referee: Experiments section (II): the reported metric deltas lack any mention of benchmark construction details, attack-generation diversity metrics, or statistical significance tests (e.g., confidence intervals or paired tests across seeds). Without these, it is impossible to assess whether the observed shifts in failure timing are reliable or artifacts of the specific tutor model and synthetic process.
Authors: We acknowledge the need for these details. The revised Experiments section will add: (1) explicit benchmark construction details, (2) attack-generation diversity metrics (template variety, visual element entropy, and escalation depth statistics), and (3) statistical significance reporting including 95% confidence intervals and results from multiple random seeds. These additions will allow readers to evaluate the reliability of the safety/helpfulness gains and the observed shift of failures to later turns. revision: yes
-
Referee: TCSR description: the trajectory-min/average safety propagation is presented as addressing late-turn decay, yet no ablation isolates its contribution from the synthetic data distribution itself. The paper should show that TCSR improves performance on held-out real-world escalation patterns rather than only on tutor-generated trajectories.
Authors: We will add a dedicated ablation study comparing SaFeR-Steer with and without the TCSR mechanism on STEER-Bench, isolating its contribution from the underlying synthetic data distribution. This will quantify the specific benefit of trajectory-level safety propagation. While STEER-Bench is constructed via adaptive on-policy attacks designed to emulate real-world multi-turn escalation, we recognize that external held-out real-world datasets would provide stronger evidence; we will explicitly discuss this limitation and note it as an avenue for future work. revision: partial
- Demonstrating TCSR improvements on external held-out real-world multi-turn escalation datasets that were never generated by the synthetic bootstrapping pipeline.
Circularity Check
Multi-turn gains on STEER-Bench reduce to in-distribution fit on tutor-generated synthetic data
specific steps
-
fitted input called prediction
[Abstract / II. Experiment]
"We release STEER, a multi-turn multimodal safety dataset with STEER-SFT (12,934), STEER-RL (2,000), and STEER-Bench (3,227) dialogues spanning 2~10 turns. ... SaFeR-Steer substantially improves Safety/Helpfulness on both single-turn ... and multi-turn benchmarks (12.55/27.13 -> 55.58/70.27 for 3B; 24.66/46.48 -> 64.89/72.35 for 7B)"
STEER-Bench is produced by the same staged synthetic bootstrapping and tutor-in-the-loop procedure that generates the RL training data. The performance delta is therefore computed on trajectories drawn from the identical generative distribution used for training, making the reported 'improvement' a within-distribution fit rather than an out-of-distribution prediction of robustness to real multi-turn attacks.
full rationale
The paper's central empirical claim is large gains on its newly introduced multi-turn benchmark after training with synthetic bootstrapping and tutor-in-the-loop GRPO. Because STEER-Bench is generated by the identical synthetic process and tutor model used to create the training splits (STEER-SFT/RL), the reported lift from 12.55/27.13 to 55.58/70.27 is measured inside the same distribution rather than on external multi-turn attacks. This matches the 'fitted input called prediction' pattern: the evaluation set is constructed from the same generative loop that supplies the training signal, so the headline robustness number is partly a measure of how well the student matches the tutor's attack distribution. No external benchmark or human-authored multi-turn corpus is used to break the loop. The TCSR propagation rule and single-turn numbers do not remove this dependency.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.