The Query Channel: Information-Theoretic Limits of Masking-Based Explanations
Pith reviewed 2026-05-10 08:06 UTC · model grok-4.3
The pith
Masking-based explanations can be recovered reliably only when their rate stays below the query channel's identification capacity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By treating each masked evaluation as a channel use, the paper proves that reliable recovery of the latent explanation is possible if and only if the rate (entropy per query) lies below the identification capacity of the query channel. Above capacity a strong converse shows that the error probability converges to one for every sequence of explainers and decoders; below capacity a sparse maximum-likelihood decoder attains vanishing error. A Monte Carlo mutual-information estimator supplies a practical benchmark that reveals operating regimes where information theory permits exact recovery yet Lasso- and OLS-based surrogates still fail.
What carries the argument
The query channel, in which the latent explanation is the message and each randomized masking evaluation of the black-box model is one channel use, whose identification capacity sets the maximum rate for reliable recovery.
If this is right
- Super-pixel or token resolutions function as source-coding choices that set the entropy of the explanation and must be matched to the query capacity.
- Gaussian noise and nonlinear curvature in the black-box reduce the effective capacity and produce waterfall and error-floor behavior.
- There exist finite query budgets where information theory guarantees reliable recovery is possible but current convex surrogates still produce large errors.
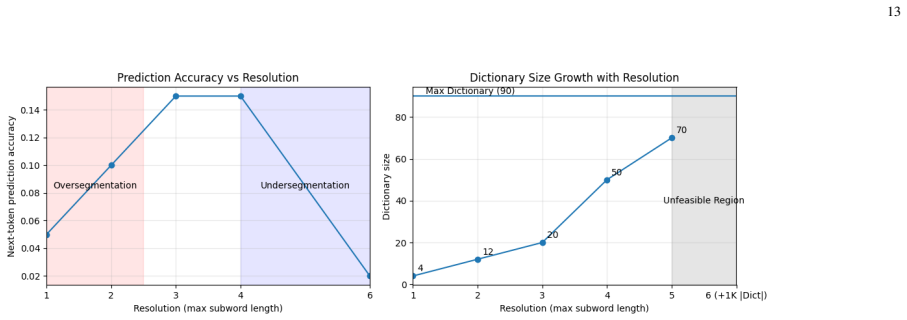
- High-resolution explanations become unattainable once the entropy induced by fine-grained masking exceeds the per-query capacity.
Where Pith is reading between the lines
- New explanation algorithms could be designed to approach the capacity bound by replacing convex surrogates with decoders closer to the maximum-likelihood rule.
- The same channel model could be applied to non-masking explanation techniques to derive comparable rate limits.
- Measuring the effective capacity on large language models would quantify how much query budget is wasted by tokenization choices.
Load-bearing premise
Randomized masking perturbations supply information at a well-defined identification capacity per query that does not depend on the particular black-box model in a way that would invalidate the uniform converse.
What would settle it
A concrete experiment in which an explainer and decoder recover explanations whose entropy exceeds the Monte Carlo estimated capacity with error probability that remains bounded away from one.
Figures





read the original abstract
Masking-based post-hoc explanation methods, such as KernelSHAP and LIME, estimate local feature importance by querying a black-box model under randomized perturbations. This paper formulates this procedure as communication over a query channel, where the latent explanation acts as a message and each masked evaluation is a channel use. Within this framework, the complexity of the explanation is captured by the entropy of the hypothesis class, while the query interface supplies information at a rate determined by an identification capacity per query. We derive a strong converse showing that, if the explanation rate exceeds this capacity, the probability of exact recovery necessarily converges to one in error for any sequence of explainers and decoders. We also prove an achievability result establishing that a sparse maximum-likelihood decoder attains reliable recovery when the rate lies below capacity. A Monte Carlo estimator of mutual information yields a non-asymptotic query benchmark that we use to compare optimal decoding with Lasso- and OLS-based procedures that mirror LIME and KernelSHAP. Experiments reveal a range of query budgets where information theory permits reliable explanations but standard convex surrogates still fail. Finally, we interpret super-pixel resolution and tokenization for neural language models as a source-coding choice that sets the entropy of the explanation and show how Gaussian noise and nonlinear curvature degrade the query channel, induce waterfall and error-floor behavior, and render high-resolution explanations unattainable.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper models masking-based post-hoc explanation methods such as LIME and KernelSHAP as communication over a query channel, where the latent explanation is the message and each randomized masked evaluation of the black-box is a channel use. Explanation complexity is measured by the entropy of the hypothesis class, and the query interface provides information at an identification capacity per query. The central results are a strong converse showing that if the explanation rate (entropy divided by number of queries) exceeds this capacity then the probability of exact recovery converges to 1 for any sequence of explainers and decoders, plus an achievability result that a sparse maximum-likelihood decoder succeeds reliably below capacity. A Monte Carlo mutual-information estimator supplies a non-asymptotic benchmark used to compare optimal decoding against Lasso- and OLS-based procedures; experiments identify query-budget regimes where information theory permits reliable recovery but the convex surrogates fail. The work also interprets super-pixel resolution and tokenization as source-coding choices and analyzes how Gaussian noise and nonlinear curvature degrade the channel.
Significance. If the results hold, the paper supplies the first information-theoretic characterization of fundamental query limits for masking-based explanations, which could guide the design of query-efficient explainers and clarify when high-resolution explanations are information-theoretically impossible. The Monte Carlo benchmark and direct comparisons to LIME/KernelSHAP-style procedures are practical strengths, as is the explicit treatment of resolution choices as source coding. The derivation of both a strong converse and an achievability result, together with the reproducible Monte Carlo estimator, constitutes a solid technical contribution.
major comments (2)
- [Abstract] Abstract and model definition: the strong converse is stated to apply uniformly 'for any sequence of explainers and decoders' and to constrain all practical masking explainers, yet the channel law P(black-box output | mask) is induced by the unknown black-box function itself. It is therefore unclear whether the resulting identification capacity remains bounded independently of the black-box or can be made arbitrarily large by suitable choice of f, which would prevent the rate threshold from serving as a universal limit. This assumption is load-bearing for the universality claim.
- [Abstract] Abstract: the manuscript asserts derivation of a 'strong converse' and an 'achievability result' together with Monte Carlo experiments, but the provided text does not include the full channel definitions, the precise statement of the capacity, or the proof sketches. Without these, the central claims cannot be verified at the level required for a journal.
minor comments (2)
- Notation for the query channel, identification capacity, and explanation rate should be introduced with explicit equations in the main text rather than relying on the abstract.
- The Monte Carlo estimator of mutual information is described only at a high level; adding pseudocode or implementation details would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. We address each major comment below and indicate the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract and model definition: the strong converse is stated to apply uniformly 'for any sequence of explainers and decoders' and to constrain all practical masking explainers, yet the channel law P(black-box output | mask) is induced by the unknown black-box function itself. It is therefore unclear whether the resulting identification capacity remains bounded independently of the black-box or can be made arbitrarily large by suitable choice of f, which would prevent the rate threshold from serving as a universal limit. This assumption is load-bearing for the universality claim.
Authors: The identification capacity is defined for the specific channel law induced by the fixed but arbitrary black-box f. The strong converse establishes that, for any such f, if the explanation rate exceeds the capacity of the induced query channel, then the probability of exact recovery converges to zero for every sequence of explainers and decoders. The result is therefore universal with respect to the choice of explainer and decoder, while the numerical value of the capacity naturally depends on f. This dependence is expected, as different black-box functions convey different amounts of information per masked query. We do not assert a single numerical bound independent of f. To remove any ambiguity, we will revise the abstract and the model section to state explicitly that the channel law and capacity are induced by f and to emphasize that the converse applies uniformly over explainers for any given f. revision: yes
-
Referee: [Abstract] Abstract: the manuscript asserts derivation of a 'strong converse' and an 'achievability result' together with Monte Carlo experiments, but the provided text does not include the full channel definitions, the precise statement of the capacity, or the proof sketches. Without these, the central claims cannot be verified at the level required for a journal.
Authors: The full manuscript defines the query channel and the induced channel law in Section 2, states the identification capacity, presents the strong converse and achievability theorems in Section 3 with proof sketches, and supplies complete proofs in the appendix. The Monte Carlo mutual-information estimator and its use as a benchmark are detailed in Section 4. Nevertheless, we agree that the abstract is highly condensed. We will expand the abstract to include a concise statement of the channel model and capacity, and we will ensure that the introduction highlights the theorem statements and proof outlines for easier verification. revision: yes
Circularity Check
No circularity: standard channel coding theorems applied to query channel model
full rationale
The paper models masking-based explanations as transmission over a query channel, with explanation rate defined as hypothesis-class entropy divided by number of queries and capacity defined via mutual information between latent explanation and black-box outputs under masks. The strong converse (error probability to 1 above capacity) and achievability (reliable recovery below capacity via sparse ML decoder) are obtained by direct application of classical information-theoretic results on identification capacity; these theorems are external and do not reduce to any fitted parameter, self-definition, or ansatz within the paper. The Monte Carlo MI estimator is used solely for non-asymptotic benchmarking against LIME/KernelSHAP surrogates and plays no role in the asymptotic derivation. No load-bearing self-citations, uniqueness theorems imported from the authors, or renaming of known results are present. The derivation chain is therefore self-contained and independent of its own inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Strong converse theorem for discrete memoryless channels
- domain assumption Achievability of reliable recovery below capacity with sparse ML decoder
invented entities (1)
-
Query channel
no independent evidence
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.