HELO-APR: Enhancing Low-Resource Program Repair through Cross-Lingual Knowledge Transfer
Pith reviewed 2026-05-10 06:29 UTC · model grok-4.3
The pith
Cross-lingual transfer from C++ raises low-resource language repair Pass@1 from 1.67% to 11.97% on CodeLlama.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
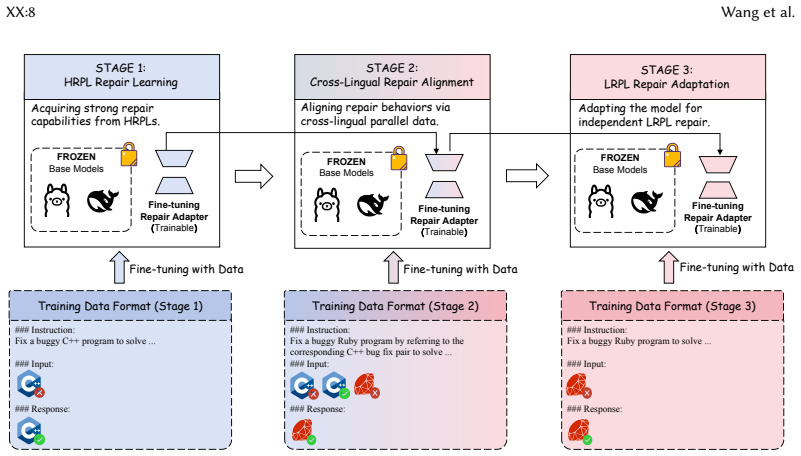
HELO-APR is a two-stage framework that constructs high-quality low-resource training data by synthesizing buggy-fixed pairs from high-resource counterparts while preserving defect type consistency and idiomaticity, then applies curriculum learning that progresses through high-resource repair learning, cross-lingual repair alignment, and low-resource repair adaptation. On xCodeEval this raises Pass@1 from 31.32% to 48.65% on DeepSeek-Coder-6.7B and from 1.67% to 11.97% on CodeLlama-7B, while lifting average target compilation rate on CodeLlama from 49.77% to 91.98%. On Defects4Ruby it also increases BLEU-4 from 61.20 to 66.79 and ROUGE-1 from 76.76 to 83.59 on CodeLlama-7B.
What carries the argument
HELO-APR, the two-stage framework that first synthesizes LRPL buggy-fixed pairs from HRPL counterparts and then runs a three-phase curriculum of HRPL repair learning, cross-lingual alignment, and LRPL adaptation.
If this is right
- LLMs reach substantially higher Pass@1 scores on Ruby and Rust repairs without large native training sets.
- Generated patches exhibit markedly higher syntactic validity, with compilation rates rising above 90 percent on CodeLlama.
- The gains extend to real-world benchmarks such as Defects4Ruby, producing patches closer to developer-written fixes.
- Ablation results confirm that both the data-synthesis step and each curriculum phase contribute measurably to the final performance.
Where Pith is reading between the lines
- The same synthesis-plus-curriculum pattern could be tested on other low-data software engineering tasks such as bug localization or test generation.
- Varying the high-resource source language or adding more low-resource targets would test how far defect-type preservation can stretch before the synthesized data loses utility.
- Larger base models might show even bigger relative gains if their cross-lingual alignment capacity exceeds that of the 7B-scale models evaluated here.
Load-bearing premise
Synthesizing low-resource language buggy-fixed pairs from high-resource language examples must preserve defect type consistency while producing idiomatic target code that supplies effective training signals.
What would settle it
Running the same synthesis and curriculum procedure on a new low-resource language whose defect distribution differs markedly from the high-resource source and observing no Pass@1 gain or a drop below direct fine-tuning baselines would show the transfer fails to deliver usable supervision.
Figures


read the original abstract
Large Language Models (LLMs) perform well on automatic program repair (APR) for high-resource programming languages (HRPLs), but their effectiveness drops sharply in low-resource programming languages (LRPLs), due to a lack of sufficient verified buggy-fixed pairs for APR training. To address this challenge, we propose HELO-APR (High-resource Enabled LOw-resource APR), a two-stage APR framework that enables cross-lingual transfer of repair knowledge from HRPLs to LRPLs. HELO-APR (1) constructs high-quality LRPL training data by synthesizing LRPL buggy-fixed pairs from HRPL counterparts, preserving defect type consistency while ensuring the synthesized code is idiomatic, and then (2) adopts a curriculum learning strategy that progressively performs HRPL repair learning, cross-lingual repair alignment, and LRPL repair adaptation, improving repair effectiveness in LRPLs. Using C++ as the source HRPL and Ruby and Rust as the target LRPLs, experiments on xCodeEval show that HELO-APR consistently outperforms strong baselines, increasing Pass@1 from 31.17% to 48.65% on DeepSeek-Coder-6.7B and from 1.67% to 11.97% on CodeLlama-7B, while improving syntactic validity by raising the average target compilation rate on CodeLlama from 49.77% to 91.98%. On Defects4Ruby, HELO-APR increases BLEU-4 from 61.20 to 66.79 and ROUGE-1 from 76.76 to 83.59 on CodeLlama-7B, indicating higher similarity to developer patches in real-world settings. Finally, we conduct ablation studies to assess the necessity of each core component. These results suggest that verified cross-lingual supervision provides a reusable approach for improving LLM-based repair in low-resource languages.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes HELO-APR, a two-stage framework for automatic program repair (APR) in low-resource programming languages (LRPLs) such as Ruby and Rust. It first synthesizes LRPL buggy-fixed pairs from high-resource counterparts (C++ as HRPL) while claiming to preserve defect types and idiomaticity, then applies curriculum learning with HRPL repair pretraining, cross-lingual alignment, and LRPL adaptation. Experiments on xCodeEval report Pass@1 gains (e.g., 31.32% to 48.65% on DeepSeek-Coder-6.7B) and higher compilation rates; results on Defects4Ruby show improved BLEU/ROUGE similarity to developer patches. Ablations assess component necessity.
Significance. If the synthesis step produces valid supervision, the approach offers a practical route to bootstrap APR for LRPLs from abundant HRPL data, addressing a clear resource disparity. The empirical gains on public benchmarks and the curriculum design are potentially reusable, and the ablation studies provide some isolation of effects. However, the absence of independent checks on the synthesized data limits how much weight the performance claims can carry for the field.
major comments (3)
- [§3] §3 (Data Construction): The central claim that HRPL-to-LRPL synthesis preserves defect-type consistency and produces idiomatic, compilable LRPL pairs is asserted without any quantitative validation (e.g., defect-type agreement rate, human idiomaticity scores, or comparison to native LRPL bugs). This step supplies all supervision for the subsequent adaptation stage; without such checks the reported Pass@1 lifts (31.32%→48.65%, 1.67%→11.97%) cannot be confidently attributed to cross-lingual transfer rather than data volume or ordering artifacts.
- [§4.1] §4.1 (Experimental Setup): Baseline implementations, hyper-parameter matching, and statistical significance tests for the Pass@1 and compilation-rate improvements are not described in sufficient detail. Without these, it is impossible to determine whether the gains over the listed strong baselines are reproducible or merely reflect differences in training regime.
- [§4.3] §4.3 (Ablation Studies): The ablations demonstrate necessity of each stage, yet they do not isolate the contribution of synthesis quality itself (e.g., by comparing against randomly translated or non-idiomatic pairs). This leaves open whether the curriculum ordering or the sheer volume of synthesized data drives the results.
minor comments (2)
- [§3.3] Notation for the three curriculum stages (HRPL repair learning, cross-lingual alignment, LRPL adaptation) is introduced without a compact diagram or equation summarizing the progressive loss schedule.
- [§2] The paper cites prior cross-lingual transfer work but does not compare against recent multilingual code models that already incorporate some Ruby/Rust data; a brief discussion of why those baselines were omitted would strengthen the positioning.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and outline the revisions we will incorporate to strengthen the paper.
read point-by-point responses
-
Referee: [§3] §3 (Data Construction): The central claim that HRPL-to-LRPL synthesis preserves defect-type consistency and produces idiomatic, compilable LRPL pairs is asserted without any quantitative validation (e.g., defect-type agreement rate, human idiomaticity scores, or comparison to native LRPL bugs). This step supplies all supervision for the subsequent adaptation stage; without such checks the reported Pass@1 lifts (31.32%→48.65%, 1.67%→11.97%) cannot be confidently attributed to cross-lingual transfer rather than data volume or ordering artifacts.
Authors: We agree that the current manuscript lacks explicit quantitative validation for the synthesis step. In the revised version, we will add a dedicated subsection in §3 reporting defect-type agreement rates (via automated static analysis matching bug patterns between HRPL and synthesized LRPL pairs), human idiomaticity scores from a pilot evaluation on 100 samples, and direct comparisons of synthesized defect distributions against native LRPL bugs from Defects4Ruby. These additions will provide stronger evidence that performance gains stem from cross-lingual transfer rather than artifacts. revision: yes
-
Referee: [§4.1] §4.1 (Experimental Setup): Baseline implementations, hyper-parameter matching, and statistical significance tests for the Pass@1 and compilation-rate improvements are not described in sufficient detail. Without these, it is impossible to determine whether the gains over the listed strong baselines are reproducible or merely reflect differences in training regime.
Authors: We acknowledge that §4.1 requires more implementation detail. We will expand this section to include all hyper-parameter values, exact baseline configurations (with code references or prompt templates), and statistical significance results using paired tests (e.g., McNemar's test) and bootstrap confidence intervals on the Pass@1 and compilation-rate metrics to demonstrate reproducibility. revision: yes
-
Referee: [§4.3] §4.3 (Ablation Studies): The ablations demonstrate necessity of each stage, yet they do not isolate the contribution of synthesis quality itself (e.g., by comparing against randomly translated or non-idiomatic pairs). This leaves open whether the curriculum ordering or the sheer volume of synthesized data drives the results.
Authors: The existing ablations isolate the curriculum stages. To further isolate synthesis quality, we will add new ablation experiments in the revised §4.3 that compare our synthesized pairs against randomly translated equivalents and non-idiomatic variants, quantifying their impact on final Pass@1 to clarify the role of synthesis quality versus data volume or ordering. revision: yes
Circularity Check
No circularity: empirical results from external benchmarks
full rationale
The paper presents an empirical method (data synthesis from HRPL to LRPL followed by curriculum learning) whose performance claims are measured on independent benchmarks (xCodeEval, Defects4Ruby) rather than any internal derivation, equation, or fitted parameter that reduces to the method's own inputs by construction. No self-definitional steps, fitted-input predictions, or load-bearing self-citations appear in the described framework or results. The synthesis assumption is an unverified modeling choice, not a circular reduction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs can be effectively fine-tuned on synthesized cross-lingual code repair data
- domain assumption Repair knowledge can be aligned across programming languages through curriculum learning
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.