Recognition: unknown
STRIDE: Strategic Iterative Decision-Making for Retrieval-Augmented Multi-Hop Question Answering
Pith reviewed 2026-05-10 05:59 UTC · model grok-4.3
The pith
STRIDE builds an entity-agnostic reasoning skeleton first, then uses a supervisor to coordinate retrieval and inference steps for multi-hop questions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
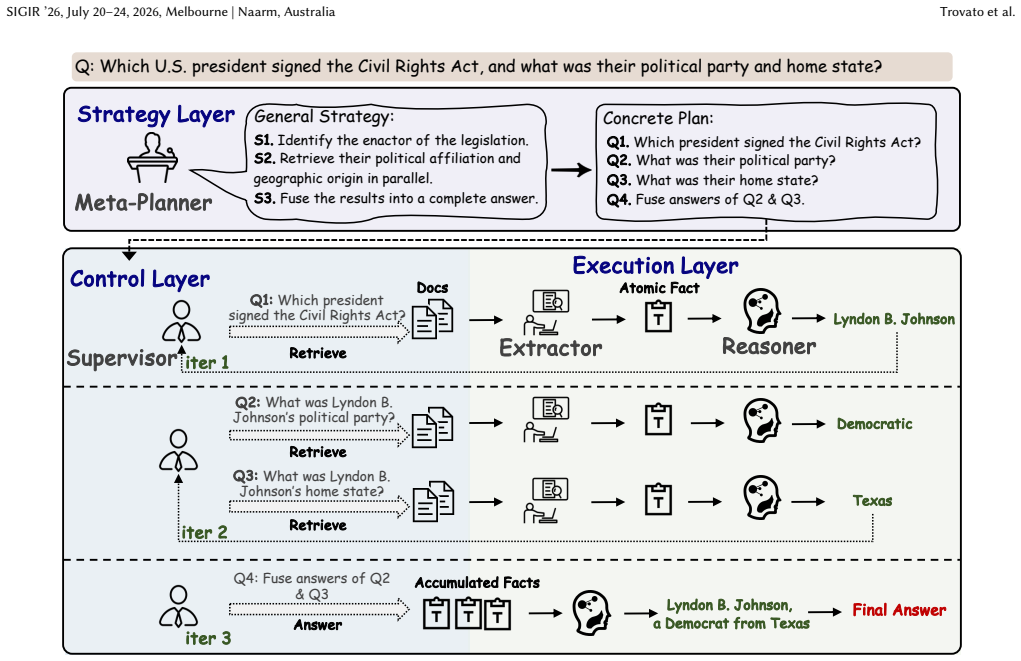
STRIDE separates strategic planning, dynamic control, and grounded execution. A Meta-Planner first constructs an entity-agnostic reasoning skeleton to capture the abstract logic of the query, deferring entity grounding until after the structure is established. A Supervisor then orchestrates sub-question execution in a dependency-aware manner, dynamically choosing retrieval or inference to avoid redundant queries and error propagation, while fusing cross-branch information and reformulating failed queries.
What carries the argument
The Meta-Planner's entity-agnostic reasoning skeleton, which records only the logical relations in the query before any specific entities are identified, together with the Supervisor that tracks dependencies and decides at each step whether to retrieve or infer.
If this is right
- Defers all entity names until the reasoning structure is fixed, which reduces errors from surface-level ambiguity.
- Allows parallel execution of independent sub-questions and enforces sequential order only where dependencies require it.
- Replaces some retrieval calls with inference from already-retrieved facts, cutting redundant queries and limiting error accumulation.
- Fuses partial answers across parallel branches and rewrites failed sub-questions to improve overall robustness.
- STRIDE-FT generates its own execution traces to fine-tune open-source models without human labels or a stronger teacher.
Where Pith is reading between the lines
- The explicit separation of planning from execution could let future systems swap in better retrievers or reasoners without retraining the planner.
- The same skeleton-plus-supervisor pattern may apply to other chained-reasoning settings such as multi-step planning or code generation where early commitments cause downstream failures.
- Self-generated trajectories from the framework could be used to create synthetic training data for tasks beyond question answering.
Load-bearing premise
That a reliable abstract reasoning skeleton can be written from the query alone without losing critical logical details, and that the supervisor's orchestration decisions will not create new coordination problems.
What would settle it
A collection of multi-hop questions containing lexical ambiguity where the generated skeleton selects the wrong logical path, producing lower accuracy than a baseline that grounds entities immediately.
Figures



read the original abstract
Multi-hop question answering (MHQA) enables accurate answers to complex queries by retrieving and reasoning over evidence dispersed across multiple documents. Existing MHQA approaches mainly rely on iterative retrieval-augmented generation, which suffer from the following two major issues. 1) Existing methods prematurely commit to surface-level entities rather than underlying reasoning structures, making question decomposition highly vulnerable to lexical ambiguity. 2) Existing methods overlook the logical dependencies among reasoning steps, resulting in uncoordinated execution. To address these issues, we propose STRIDE, a framework that separates strategic planning, dynamic control, and grounded execution. At its core, a Meta-Planner first constructs an entity-agnostic reasoning skeleton to capture the abstract logic of the query, thereby deferring entity grounding until after the reasoning structure is established, which mitigates disambiguation errors caused by premature lexical commitment. A Supervisor then orchestrates sub-question execution in a dependency-aware manner, enabling efficient parallelization where possible and sequential coordination when necessary. By dynamically deciding whether to retrieve new evidence or infer from existing facts, it avoids redundant queries and error propagation, while fusing cross-branch information and reformulating failed queries to enhance robustness. Grounded fact extraction and logical inference are delegated to specialized execution modules, ensuring faithfulness through explicit separation of retrieval and reasoning. We further propose STRIDE-FT, a modular fine-tuning framework that uses self-generated execution trajectories from STRIDE, requiring neither human annotations nor stronger teacher models. Experiments show that STRIDE achieves robust and accurate reasoning, while STRIDE-FT effectively enhances open-source LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces STRIDE, a modular framework for retrieval-augmented multi-hop question answering (MHQA) that decomposes the process into an entity-agnostic Meta-Planner to build abstract reasoning skeletons, a dependency-aware Supervisor for orchestrating sub-question execution with dynamic retrieval/inference decisions, and specialized execution modules for grounded fact extraction and logical inference. It additionally proposes STRIDE-FT, a self-supervised fine-tuning method that generates training trajectories from STRIDE without human annotations or stronger teacher models. Experiments claim that STRIDE delivers robust and accurate reasoning while STRIDE-FT improves open-source LLMs.
Significance. If the results hold, the work provides a concrete architectural separation of planning, control, and execution that directly targets two common failure modes in iterative RAG (premature lexical commitment and uncoordinated steps). The self-supervised trajectory generation for fine-tuning is a practical, low-overhead contribution that could be adopted more broadly in agentic reasoning systems.
major comments (1)
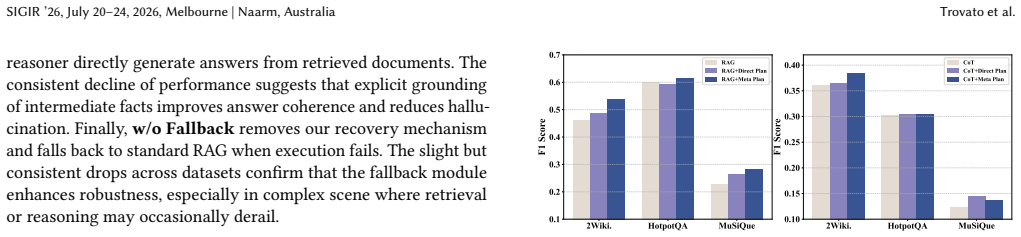
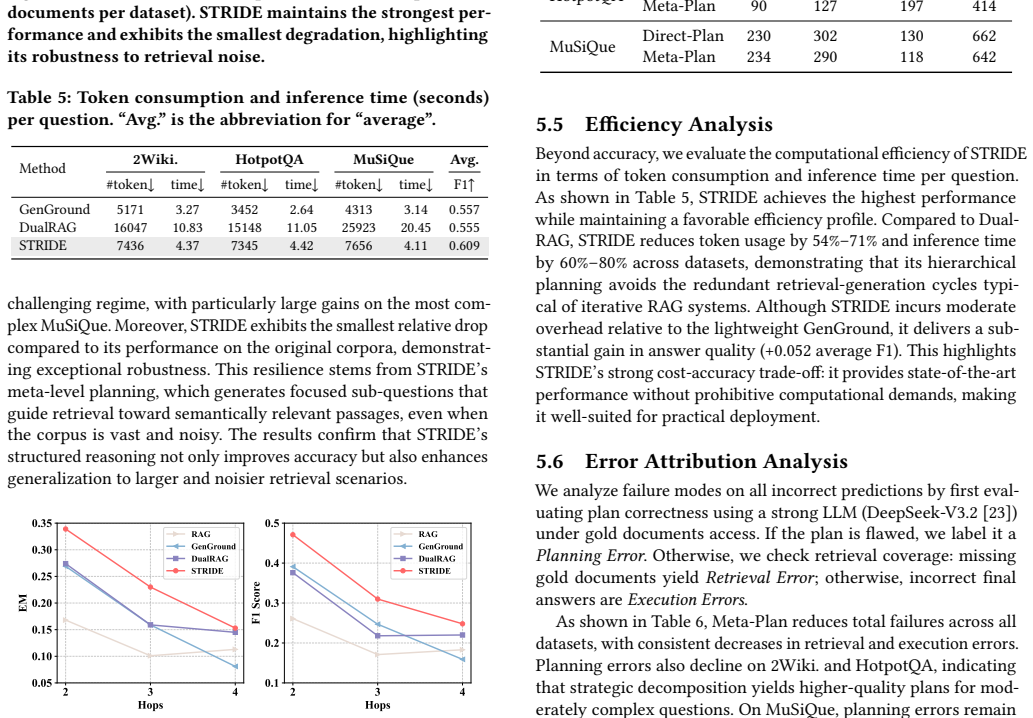
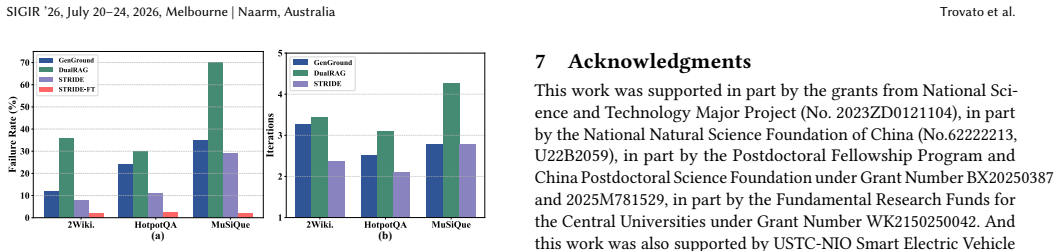
- [§4.3] §4.3 and Table 3: the ablation isolating the Meta-Planner's entity-agnostic skeleton shows gains, but the paper does not report how often the skeleton itself contains logical errors that propagate; a failure-case analysis on queries where the abstract structure is incorrect would strengthen the central claim that deferring entity grounding mitigates disambiguation errors.
minor comments (3)
- [§3.2] §3.2: the Supervisor's dependency graph construction is described at a high level; adding pseudocode or a small worked example would clarify how parallelization decisions are made without introducing coordination failures.
- [Table 1] Table 1: baseline descriptions are brief; explicitly stating whether all baselines use the same retrieval corpus and LLM backbone would aid reproducibility.
- [§5.1] §5.1: the STRIDE-FT training objective is given informally; a short equation or loss formulation would make the self-supervised signal precise.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation for minor revision. We address the single major comment below.
read point-by-point responses
-
Referee: [§4.3] §4.3 and Table 3: the ablation isolating the Meta-Planner's entity-agnostic skeleton shows gains, but the paper does not report how often the skeleton itself contains logical errors that propagate; a failure-case analysis on queries where the abstract structure is incorrect would strengthen the central claim that deferring entity grounding mitigates disambiguation errors.
Authors: We appreciate this observation. The ablation in §4.3 and Table 3 isolates the Meta-Planner contribution and shows clear gains, but we agree that the manuscript currently lacks quantitative reporting on the rate at which the entity-agnostic skeletons contain logical errors and how often those errors propagate to the final answer. A dedicated failure-case analysis on queries with incorrect abstract structures would indeed provide stronger support for the claim that deferring entity grounding reduces disambiguation errors. In the revised manuscript we will add this analysis, including (i) the observed frequency of logical skeleton errors across the evaluation sets, (ii) their measured impact on end-to-end accuracy, and (iii) representative qualitative examples. revision: yes
Circularity Check
No significant circularity in the proposed framework
full rationale
The paper presents STRIDE as an architectural decomposition that directly targets two stated failure modes in prior MHQA methods (premature entity commitment and uncoordinated steps) via an entity-agnostic Meta-Planner followed by a dependency-aware Supervisor. No equations, parameter-fitting steps, or self-referential definitions appear in the provided text; the separation of planning, control, and execution is introduced as an explicit design choice rather than derived from or reduced to its own outputs. No load-bearing self-citations, uniqueness theorems, or ansatzes smuggled via prior work are invoked. The self-supervised STRIDE-FT trajectory generation is described as a standard data-generation technique without circular reduction to the target performance claims. The derivation chain is therefore self-contained and does not collapse to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can reliably generate entity-agnostic reasoning skeletons and follow supervisor instructions for execution and reformulation
invented entities (3)
-
Meta-Planner
no independent evidence
-
Supervisor
no independent evidence
-
STRIDE-FT
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. 2024. Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection. InThe Twelfth International Conference on Learning Representations
2024
-
[2]
Wei Chen, Lili Zhao, Zhi Zheng, Tong Xu, Yang Wang, and Enhong Chen. 2024. Double-checker: Large language model as a checker for few-shot named entity recognition. InFindings of the Association for Computational Linguistics: EMNLP
2024
-
[3]
Wei Chen, Zhi Zheng, Lili Zhao, Huijun Hou, and Tong Xu. 2025. Following Occam’s Razor: Dynamic Combination of Structured Knowledge for Multi-Hop Question Answering using LLMs. InFindings of the Association for Computational Linguistics: EMNLP 2025. 17942–17956
2025
-
[4]
Rong Cheng, Jinyi Liu, Yan Zheng, Fei Ni, Jiazhen Du, Hangyu Mao, Fuzheng Zhang, Bo Wang, and Jianye Hao. 2025. DualRAG: A Dual-Process Approach to Integrate Reasoning and Retrieval for Multi-Hop Question Answering. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 31877–31899
2025
-
[5]
Florin Cuconasu, Giovanni Trappolini, Federico Siciliano, Simone Filice, Cesare Campagnano, Yoelle Maarek, Nicola Tonellotto, and Fabrizio Silvestri. 2024. The power of noise: Redefining retrieval for rag systems. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 719–729
2024
-
[6]
Ming Ding, Chang Zhou, Qibin Chen, Hongxia Yang, and Jie Tang. 2019. Cognitive Graph for Multi-Hop Reading Comprehension at Scale. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2694–2703
2019
-
[7]
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. 2024. From local to global: A graph rag approach to query-focused summarization.arXiv preprint arXiv:2404.16130(2024)
work page internal anchor Pith review arXiv 2024
-
[8]
Wenqi Fan, Yujuan Ding, Liangbo Ning, Shijie Wang, Hengyun Li, Dawei Yin, Tat-Seng Chua, and Qing Li. 2024. A survey on rag meeting llms: Towards retrieval-augmented large language models. InProceedings of the 30th ACM SIGKDD conference on knowledge discovery and data mining. 6491–6501
2024
-
[9]
Yuwei Fang, Siqi Sun, Zhe Gan, Rohit Pillai, Shuohang Wang, and Jingjing Liu
-
[10]
InProceed- ings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)
Hierarchical Graph Network for Multi-hop Question Answering. InProceed- ings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 8823–8838
2020
-
[11]
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yixin Dai, Jiawei Sun, Haofen Wang, and Haofen Wang. 2023. Retrieval-augmented generation for large language models: A survey.arXiv preprint arXiv:2312.10997 2, 1 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. 2020. Constructing A Multi-hop QA Dataset for Comprehensive Evaluation of Reason- ing Steps. InProceedings of the 28th International Conference on Computational Linguistics. 6609–6625
2020
-
[13]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. LoRA: Low-Rank Adaptation of Large Language Models. InThe Tenth International Conference on Learning Representa- tions
2022
-
[14]
Gautier Izacard, Mathilde Caron, Lucas Hosseini, Sebastian Riedel, Piotr Bo- janowski, Armand Joulin, and Edouard Grave. 2022. Unsupervised Dense In- formation Retrieval with Contrastive Learning.Trans. Mach. Learn. Res.2022 (2022)
2022
-
[15]
Gautier Izacard, Patrick Lewis, Maria Lomeli, Lucas Hosseini, Fabio Petroni, Timo Schick, Jane Dwivedi-Yu, Armand Joulin, Sebastian Riedel, and Edouard Grave. 2023. Atlas: Few-shot learning with retrieval augmented language models. Journal of Machine Learning Research24, 251 (2023), 1–43
2023
-
[16]
Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig
Zhengbao Jiang, Frank F. Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig. 2023. Active Retrieval Aug- mented Generation. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023. 7969–7992. STRIDE: Strategic Iterative Decision-Making for Retrieval-Augmented Mult...
2023
-
[17]
Jeff Johnson, Matthijs Douze, and Hervé Jégou. 2019. Billion-scale similarity search with GPUs.IEEE Transactions on Big Data7, 3 (2019), 535–547
2019
-
[18]
Muhammad Khalifa, Lajanugen Logeswaran, Moontae Lee, Honglak Lee, and Lu Wang. 2023. Few-shot Reranking for Multi-hop QA via Language Model Prompt- ing. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 15882–15897
2023
-
[19]
Yunshi Lan, Gaole He, Jinhao Jiang, Jing Jiang, Wayne Xin Zhao, and Ji-Rong Wen. 2021. A Survey on Complex Knowledge Base Question Answering: Meth- ods, Challenges and Solutions. InProceedings of the Thirtieth International Joint Conference on Artificial Intelligence. 4483–4491
2021
-
[20]
Myeonghwa Lee, Seonho An, and Min-Soo Kim. 2024. PlanRAG: A Plan-then- Retrieval Augmented Generation for Generative Large Language Models as Deci- sion Makers. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 6537–6555
2024
-
[21]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in neural information processing systems33 (2020), 9459–9474
2020
-
[22]
Ruosen Li and Xinya Du. 2023. Leveraging Structured Information for Explainable Multi-hop Question Answering and Reasoning. InFindings of the Association for Computational Linguistics: EMNLP 2023. 6779–6789
2023
- [23]
-
[24]
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al . 2025. Deepseek- v3. 2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556(2025)
work page internal anchor Pith review arXiv 2025
- [25]
-
[26]
Pranoy Panda, Ankush Agarwal, Chaitanya Devaguptapu, Manohar Kaul, and Prathosh A P. 2024. HOLMES: Hyper-Relational Knowledge Graphs for Multi-hop Question Answering using LLMs. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 13263–13282
2024
-
[27]
Ofir Press, Muru Zhang, Sewon Min, Ludwig Schmidt, Noah A Smith, and Mike Lewis. 2023. Measuring and Narrowing the Compositionality Gap in Language Models. InFindings of the Association for Computational Linguistics: EMNLP 2023. 5687–5711
2023
-
[28]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. 2023. Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems36 (2023), 53728–53741
2023
-
[29]
Alireza Salemi and Hamed Zamani. 2024. Evaluating Retrieval Quality in Retrieval-Augmented Generation. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2395– 2400
2024
-
[30]
Zhihong Shao, Yeyun Gong, Yelong Shen, Minlie Huang, Nan Duan, and Weizhu Chen. 2023. Enhancing Retrieval-Augmented Large Language Models with Iterative Retrieval-Generation Synergy. InFindings of the Association for Compu- tational Linguistics: EMNLP 2023. 9248–9274
2023
-
[31]
Zhengliang Shi, Shuo Zhang, Weiwei Sun, Shen Gao, Pengjie Ren, Zhumin Chen, and Zhaochun Ren. 2024. Generate-then-Ground in Retrieval-Augmented Gen- eration for Multi-hop Question Answering. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 7339–7353
2024
-
[32]
Hongda Sun, Yuxuan Liu, Chengwei Wu, Haiyu Yan, Cheng Tai, Xin Gao, Shuo Shang, and Rui Yan. 2024. Harnessing multi-role capabilities of large language models for open-domain question answering. InProceedings of the ACM Web Conference 2024. 4372–4382
2024
-
[34]
Transactions of the Association for Computational Linguistics10 (2022), 539–554
MuSiQue: Multihop Questions via Single-hop Question Composition. Transactions of the Association for Computational Linguistics10 (2022), 539–554
2022
-
[35]
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal
-
[36]
InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Interleaving Retrieval with Chain-of-Thought Reasoning for Knowledge- Intensive Multi-Step Questions. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 10014–10037
-
[37]
Jinke Wang, Zenan Ying, Qi Liu, Wei Chen, Tong Xu, Huijun Hou, and Zhi Zheng
-
[38]
In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
Think and Recall: Layer-Level Prompting for Lifelong Model Editing. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 14498–14513
2025
-
[39]
Yuhao Wang, Ruiyang Ren, Yucheng Wang, Wayne Xin Zhao, Jing Liu, Hua Wu, and Haifeng Wang. 2025. Unveiling Knowledge Utilization Mechanisms in LLM- based Retrieval-Augmented Generation. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1262–1271
2025
-
[40]
Zheng Wang, Shu Xian Teo, Jun Jie Chew, and Wei Shi. 2025. InstructRAG: Lever- aging Retrieval-Augmented Generation on Instruction Graphs for LLM-Based Task Planning. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1413–1422
2025
-
[41]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems35 (2022), 24824–24837
2022
-
[42]
Derong Xu, Wei Chen, Wenjun Peng, Chao Zhang, Tong Xu, Xiangyu Zhao, Xian Wu, Yefeng Zheng, Yang Wang, and Enhong Chen. 2024. Large language models for generative information extraction: A survey.Frontiers of Computer Science18, 6 (2024), 186357
2024
-
[43]
Derong Xu, Xinhang Li, Ziheng Zhang, Zhenxi Lin, Zhihong Zhu, Zhi Zheng, Xian Wu, Xiangyu Zhao, Tong Xu, and Enhong Chen. 2025. Harnessing large language models for knowledge graph question answering via adaptive multi- aspect retrieval-augmentation. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 25570–25578
2025
-
[44]
Derong Xu, Yi Wen, Pengyue Jia, Yingyi Zhang, Wenlin Zhang, Yichao Wang, Huifeng Guo, Ruiming Tang, Xiangyu Zhao, Enhong Chen, and Tong Xu. 2026. From Single to Multi-Granularity: Toward Long-Term Memory Association and Selection of Conversational Agents. InThe Fourteenth International Conference on Learning Representations. https://openreview.net/forum?i...
2026
-
[45]
Shicheng Xu, Liang Pang, Jun Xu, Huawei Shen, and Xueqi Cheng. 2024. List- aware reranking-truncation joint model for search and retrieval-augmented generation. InProceedings of the ACM Web Conference 2024. 1330–1340
2024
-
[46]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Diji Yang, Jinmeng Rao, Kezhen Chen, Xiaoyuan Guo, Yawen Zhang, Jie Yang, and Yi Zhang. 2024. IM-RAG: Multi-Round Retrieval-Augmented Generation Through Learning Inner Monologues. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 730–740
2024
-
[48]
Sohee Yang, Elena Gribovskaya, Nora Kassner, Mor Geva, and Sebastian Riedel
-
[49]
In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Do Large Language Models Latently Perform Multi-Hop Reasoning?. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 10210–10229
-
[50]
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D Manning. 2018. HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2369–2380
2018
-
[51]
Jiahao Zhang, Haiyang Zhang, Dongmei Zhang, Liu Yong, and Shen Huang. 2024. End-to-End Beam Retrieval for Multi-Hop Question Answering. InProceedings of the 2024 Conference of the North American Chapter of the Association for Com- putational Linguistics: Human Language Technologies (Volume 1: Long Papers). 1718–1731
2024
-
[52]
Lili Zhao, Yang Wang, Qi Liu, Mengyun Wang, Wei Chen, Zhichao Sheng, and Shijin Wang. 2025. Evaluating large language models through role-guide and self-reflection: A comparative study. InThe Thirteenth International Conference on Learning Representations
2025
-
[53]
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, et al. 2023. A survey of large language models.arXiv preprint arXiv:2303.18223(2023)
work page Pith review arXiv 2023
-
[54]
Zexuan Zhong, Zhengxuan Wu, Christopher D Manning, Christopher Potts, and Danqi Chen. 2023. MQuAKE: Assessing Knowledge Editing in Language Models via Multi-Hop Questions. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 15686–15702
2023
-
[55]
Yujia Zhou, Zheng Liu, Jiajie Jin, Jian-Yun Nie, and Zhicheng Dou. 2024. Metacog- nitive Retrieval-Augmented Large Language Models. InProceedings of the ACM on Web Conference 2024. 1453–1463
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.