Beyond the YAML File: Understanding Real-World GitHub Actions Workflow Adoption
Pith reviewed 2026-05-10 05:05 UTC · model grok-4.3
The pith
Real-world GitHub Actions data reveals three distinct developer responses to workflow failures along with a gap between configuration and actual use.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We identify three distinct failure response patterns, observe that higher usage intensity of GHA workflows correlates with lower failure rates, and uncover a configuration-usage gap where the presence of configuration files masks disabled or unused workflows. Moreover, our qualitative analysis of relationships between project characteristics and utilization patterns yields five hypotheses for future validation.
What carries the argument
Mixed-methods analysis of 258,300 workflow run records combined with in-depth review of 21 repositories to map failure responses and usage patterns.
Load-bearing premise
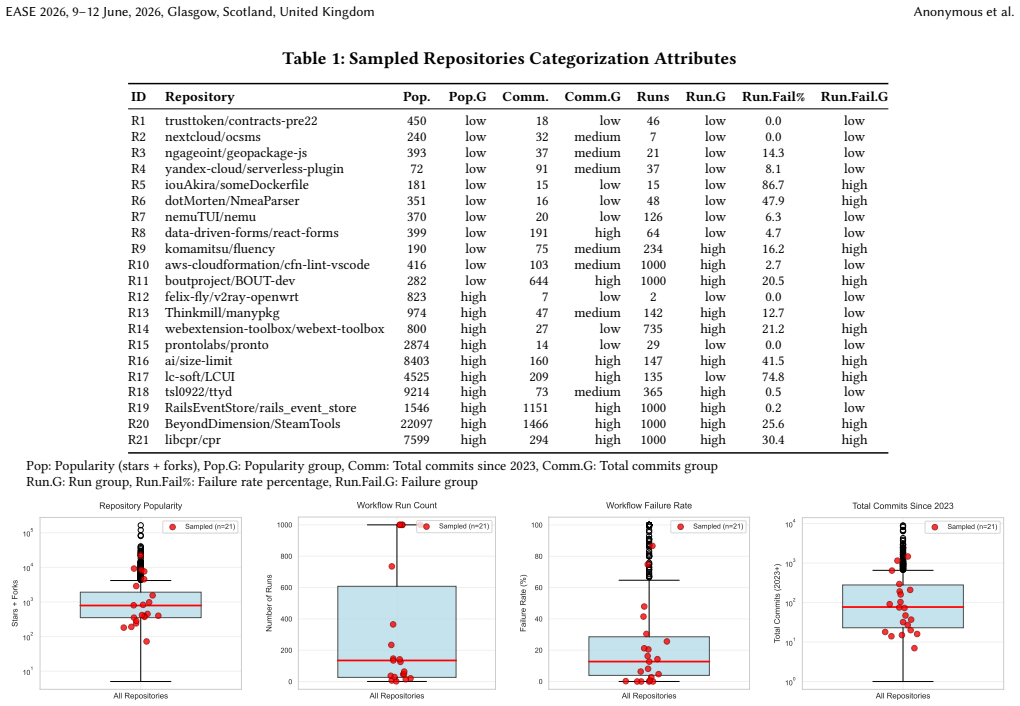
The chosen set of 952 repositories for quantitative data and 21 for qualitative analysis accurately reflects how GitHub Actions are used more broadly.
What would settle it
Finding a different number of failure response patterns or no correlation between usage intensity and failure rates in a larger random sample of repositories would challenge the main findings.
Figures



read the original abstract
Continuous Integration and Continuous Deployment (CI/CD) have become fundamental to modern software development, with GitHub Actions (GHA) emerging as a dominant automation platform. In this study, we analyze real-world execution records of GHA, examining how developers react to workflow failures, how these workflows are utilized by projects, and how these aspects relate to project characteristics. We quantitatively analyze 258,300 workflow run records from 952 repositories and perform an in-depth qualitative analysis of 21 selected, diverse GitHub repositories to understand how maintainers and contributors interact with workflow results. We identify three distinct failure response patterns, observe that higher usage intensity of GHA workflows correlates with lower failure rates, and uncover a configuration-usage gap where the presence of configuration files masks disabled or unused workflows. Moreover, our qualitative analysis of relationships between project characteristics and utilization patterns yields five hypotheses for future validation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents an empirical study of real-world GitHub Actions (GHA) adoption. It quantitatively analyzes 258,300 workflow run records from 952 repositories to examine failure responses, usage intensity, and failure rates, and qualitatively studies 21 selected repositories to identify patterns in how maintainers interact with workflow results. The central claims are the identification of three distinct failure response patterns, a negative correlation between higher GHA usage intensity and lower failure rates, a configuration-usage gap where config files mask disabled workflows, and five hypotheses relating project characteristics to utilization patterns.
Significance. If the findings hold after addressing sampling and analysis details, the work offers valuable large-scale observational data on CI/CD practices with GHA, a dominant platform. The scale of the quantitative dataset (258k runs) is a strength for identifying usage patterns and correlations, and the mixed-methods approach yields actionable hypotheses. This could inform tool builders and practitioners on workflow design, though the observational design inherently limits causal claims.
major comments (3)
- [§3] §3 (Data Collection and Sampling): The criteria and process for selecting the 952 repositories (and the 21 for qualitative analysis) are not described in sufficient detail to evaluate representativeness or rule out selection bias. This is load-bearing for the correlation between usage intensity and failure rates (reported in §4) and the three failure patterns, as unmeasured factors like repository popularity, age, or language could confound results.
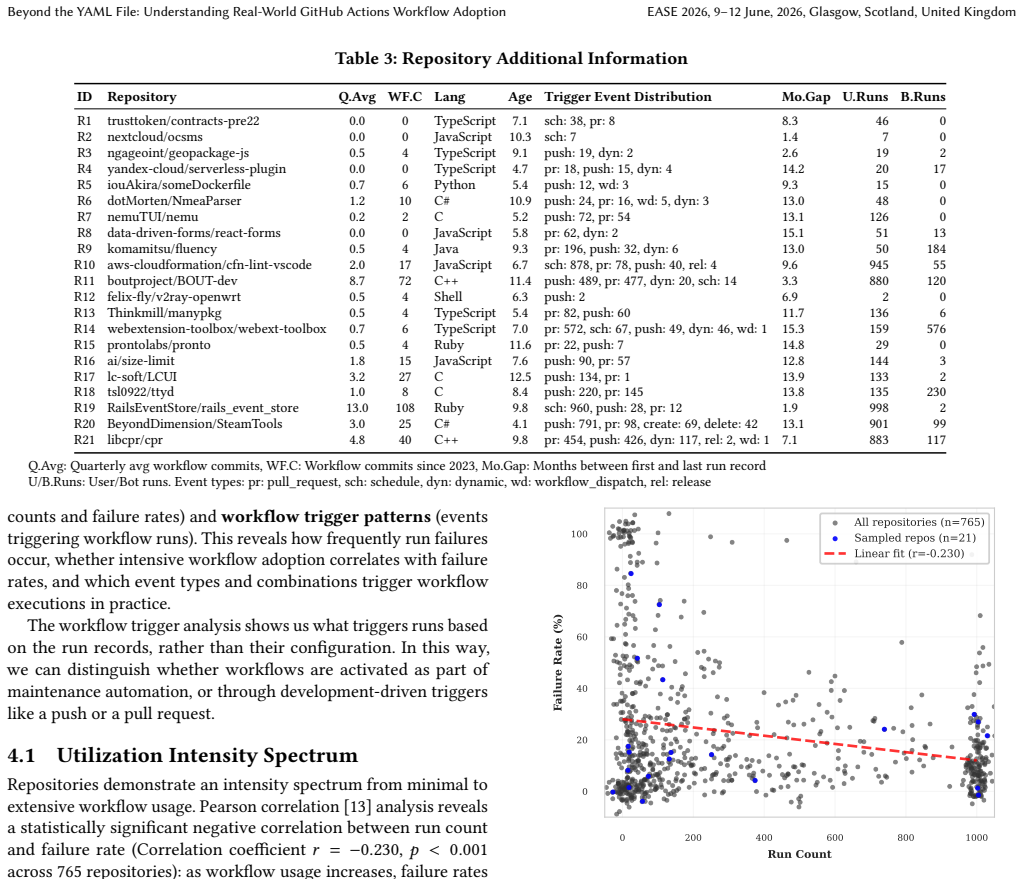
- [§4.2] §4.2 (Quantitative Results on Usage and Failures): The reported negative correlation lacks mention of statistical controls for potential confounders (e.g., project size, team activity, primary language). Without these or sensitivity analyses, the claim that higher usage intensity correlates with lower failure rates cannot be confidently attributed to usage rather than external variables.
- [§5] §5 (Qualitative Analysis): The failure classification criteria, inter-rater reliability measures, and exact selection process for the 21 repositories are not specified. This undermines the validity of the three identified failure response patterns and the configuration-usage gap, as measurement bias or non-representative cases could produce the observed patterns.
minor comments (2)
- [Abstract] The abstract and introduction could more clearly distinguish between the quantitative sample (952 repos) and qualitative subsample (21 repos) to avoid reader confusion about scope.
- [Figures/Tables] Figure captions and table descriptions would benefit from explicit definitions of 'usage intensity' and 'failure rate' to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which highlights important areas for improving the transparency and robustness of our empirical study. We address each major comment point by point below, outlining the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Data Collection and Sampling): The criteria and process for selecting the 952 repositories (and the 21 for qualitative analysis) are not described in sufficient detail to evaluate representativeness or rule out selection bias. This is load-bearing for the correlation between usage intensity and failure rates (reported in §4) and the three failure patterns, as unmeasured factors like repository popularity, age, or language could confound results.
Authors: We agree that greater detail on the sampling process is required to allow evaluation of representativeness and potential biases. In the revised manuscript, we will expand §3 with a full description of the repository selection criteria, including the source population (e.g., GitHub repositories with public workflow histories), inclusion filters such as minimum workflow run counts and activity thresholds, and steps taken to promote diversity in programming languages and project sizes. For the 21 repositories in the qualitative analysis, we will document the purposive sampling approach used to capture variation in failure response patterns. We will also add an explicit limitations subsection addressing selection bias and generalizability. revision: yes
-
Referee: [§4.2] §4.2 (Quantitative Results on Usage and Failures): The reported negative correlation lacks mention of statistical controls for potential confounders (e.g., project size, team activity, primary language). Without these or sensitivity analyses, the claim that higher usage intensity correlates with lower failure rates cannot be confidently attributed to usage rather than external variables.
Authors: We concur that controlling for confounders strengthens causal interpretation in observational data. In the revision, we will augment the analysis in §4.2 with multivariate regression models that include controls for project size (measured by stars and contributors), team activity (commit frequency), primary language, and repository age. We will also report sensitivity analyses, such as stratified correlations and alternative model specifications, to assess the stability of the negative association between usage intensity and failure rates. These additions will be presented alongside the existing descriptive results while maintaining the observational framing of the study. revision: yes
-
Referee: [§5] §5 (Qualitative Analysis): The failure classification criteria, inter-rater reliability measures, and exact selection process for the 21 repositories are not specified. This undermines the validity of the three identified failure response patterns and the configuration-usage gap, as measurement bias or non-representative cases could produce the observed patterns.
Authors: We recognize the need for explicit methodological transparency in the qualitative component. In the revised §5, we will specify the failure classification criteria in detail, including the coding scheme, category definitions, and illustrative examples from the data. We will report inter-rater reliability statistics (e.g., Cohen's kappa) from the independent coding performed by the research team. Additionally, we will describe the exact selection process for the 21 repositories, including how cases were chosen to reflect diversity in failure patterns and project characteristics. These clarifications will support readers' assessment of the identified patterns and the configuration-usage gap. revision: yes
Circularity Check
No circularity: purely observational empirical study
full rationale
The paper performs quantitative analysis of 258300 external GitHub workflow runs from 952 repositories plus qualitative coding of 21 cases. It reports observed failure-response patterns, a usage-intensity correlation, a configuration-usage gap, and five hypotheses. No equations, fitted parameters, predictions, derivations, or self-citations appear in the provided text or abstract; all claims are direct summaries of collected external data with no reduction to internal definitions or prior author results.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The 952 repositories provide a representative sample of GitHub Actions usage across open-source projects.
- domain assumption Failure responses observed in the 21 qualitative repositories can be generalized into three distinct patterns.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.