Recognition: unknown
LiteResearcher: A Scalable Agentic RL Training Framework for Deep Research Agent
Pith reviewed 2026-05-10 04:18 UTC · model grok-4.3
The pith
A lite virtual world mirroring real searches lets a 4B agent master deep research via scalable RL.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
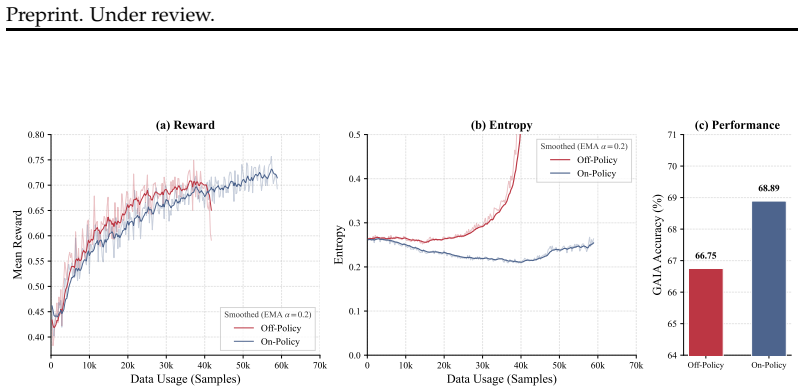
LiteResearcher constructs a lite virtual world that mirrors real-world search dynamics to enable a continuously improving RL training recipe. This approach empowers a 4B-parameter search agent to outperform large open-source and commercial models such as Tongyi DeepResearch and Claude-4.5 Sonnet. On GAIA the model reaches 71.3 percent and on Xbench it reaches 78.0 percent, establishing new open-source state-of-the-art results for these benchmarks.
What carries the argument
The lite virtual world that mirrors real-world search dynamics and supports repeated, stable RL training cycles.
If this is right
- Reinforcement learning for agents becomes feasible at scale without repeated real-world API costs or instability.
- Small-parameter models can reach benchmark scores previously limited to much larger systems.
- The training process supports ongoing improvement through repeated cycles inside the virtual setting.
- Real-world search dependencies are minimized during the learning phase while still producing transferable skills.
- Deep research agents gain a practical path to high performance on complex, multi-step information tasks.
Where Pith is reading between the lines
- Similar virtual mirroring could be adapted to train agents in adjacent interactive domains such as code debugging or data analysis.
- The continuous-improvement recipe may combine with other RL methods to produce agents that refine themselves over longer periods.
- Lower training costs open the possibility of broader experimentation with research-agent architectures that were previously too expensive to iterate.
- If the mirroring principle generalizes, it suggests simulation fidelity as a core lever for transferring skills across many agent environments.
Load-bearing premise
The lite virtual world accurately captures the essential dynamics of real-world search so that capabilities transfer to genuine tasks without simulation artifacts.
What would settle it
Running the trained 4B agent on fresh research tasks that demand search patterns absent from the virtual world and finding its accuracy falls below that of an otherwise identical agent trained with live searches.
Figures







read the original abstract
Reinforcement Learning (RL) has emerged as a powerful training paradigm for LLM-based agents. However, scaling agentic RL for deep research remains constrained by two coupled challenges: hand-crafted synthetic data fails to elicit genuine real-world search capabilities, and real-world search dependency during RL training introduces instability and prohibitive cost, which limits the scalability of Agentic RL. LiteResearcher is a training framework that makes Agentic RL scalable: by constructing a lite virtual world that mirrors real-world search dynamics, we enable a continuously improving training recipe that empowers a tiny search agent to outperform large-scale open-source and commercial models (e.g., Tongyi DeepResearch and Claude-4.5 Sonnet). Specifically, on common benchmarks such as GAIA and Xbench, our LiteResearcher-4B achieves open-source state-of-the-art results of 71.3% and 78.0% respectively, demonstrating that scalable RL training is a key enabler for Deep Research Agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LiteResearcher, a scalable agentic RL training framework that constructs a 'lite virtual world' mirroring real-world search dynamics to overcome the instability and cost of real-world interactions during training. This enables a continuously improving training recipe for a 4B-parameter search agent, which the authors report achieves open-source SOTA results of 71.3% on GAIA and 78.0% on Xbench, outperforming larger models such as Tongyi DeepResearch and Claude-4.5 Sonnet.
Significance. If the lite virtual world is shown to faithfully replicate essential search dynamics (tool responses, information retrieval, multi-step trajectories) with validated transfer to real tasks, the framework could meaningfully advance scalable RL for deep research agents by reducing reliance on expensive real-world rollouts while enabling smaller models to reach competitive performance.
major comments (3)
- [Abstract and §3] Abstract and §3 (Virtual World Construction): the central claim that the lite virtual world 'mirrors real-world search dynamics' and enables transferable capabilities is unsupported, as no construction details, fidelity metrics (e.g., statistical distribution matching of trajectories or tool-response distributions), or validation against real search logs are provided.
- [§5 and §4] §5 (Experiments) and §4 (Training Procedure): the reported GAIA/Xbench gains for LiteResearcher-4B are presented without ablations that test performance degradation when the virtual world is altered (e.g., removing simulated shortcuts) or when evaluated on out-of-distribution real queries, leaving open the possibility that results reflect simulation-specific overfitting rather than genuine scalable RL progress.
- [§5] §5 (Experiments): no controls or comparisons are described for confounding factors such as differences in evaluation protocols, data leakage between virtual-world training and benchmark queries, or baseline training recipes without the virtual world, which are required to substantiate that the framework itself is the key enabler.
minor comments (2)
- [Abstract] Abstract: the comparison models (Tongyi DeepResearch, Claude-4.5 Sonnet) should include exact versions, access dates, and prompting details for reproducibility.
- [Throughout] Throughout: the notation and components of the lite virtual world (e.g., tool interfaces, state representations) are introduced without a clear diagram or pseudocode, hindering reader understanding of the mirroring mechanism.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, indicating the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Virtual World Construction): the central claim that the lite virtual world 'mirrors real-world search dynamics' and enables transferable capabilities is unsupported, as no construction details, fidelity metrics (e.g., statistical distribution matching of trajectories or tool-response distributions), or validation against real search logs are provided.
Authors: We agree that the current §3 provides a high-level overview but would benefit from greater specificity to substantiate the mirroring claim. In the revised manuscript we will expand §3 with explicit construction details of the lite virtual world, including how tool responses and search trajectories are simulated, quantitative fidelity metrics (e.g., statistical distribution matching for trajectories and tool-response distributions), and direct validation comparisons against real-world search logs. revision: yes
-
Referee: [§5 and §4] §5 (Experiments) and §4 (Training Procedure): the reported GAIA/Xbench gains for LiteResearcher-4B are presented without ablations that test performance degradation when the virtual world is altered (e.g., removing simulated shortcuts) or when evaluated on out-of-distribution real queries, leaving open the possibility that results reflect simulation-specific overfitting rather than genuine scalable RL progress.
Authors: We acknowledge that additional ablations are required to address the possibility of simulation-specific overfitting. We will add these experiments to §5, including controlled alterations to the virtual world (such as removal of simulated shortcuts) and evaluation on out-of-distribution real queries, to demonstrate performance degradation patterns and support transferability of the learned capabilities. revision: yes
-
Referee: [§5] §5 (Experiments): no controls or comparisons are described for confounding factors such as differences in evaluation protocols, data leakage between virtual-world training and benchmark queries, or baseline training recipes without the virtual world, which are required to substantiate that the framework itself is the key enabler.
Authors: We appreciate the identification of these potential confounds. In the revised §5 we will incorporate the requested controls: explicit comparisons against baseline training recipes that omit the virtual world, checks for data leakage between virtual-world training data and the GAIA/Xbench queries, and clear documentation of evaluation protocols to isolate the contribution of the LiteResearcher framework. revision: yes
Circularity Check
No circularity: empirical benchmark results with no derivation chain or fitted predictions
full rationale
The paper presents LiteResearcher as an RL training framework whose central claims rest on external benchmark scores (GAIA 71.3%, Xbench 78.0%) achieved by a 4B agent. No equations, parameters, or first-principles derivations are described in the provided text. The lite virtual world is introduced as a construction that mirrors real dynamics, but its validity is treated as an empirical premise evaluated by transfer to real benchmarks rather than by any self-referential definition or fitted-input prediction. No self-citations are invoked as load-bearing uniqueness theorems. The result is therefore self-contained against external benchmarks and exhibits no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Questions should be specific and reference the exact context from the page
-
[2]
500 billion
Answers should be concise and factual (e.g., “500 billion”, “2025”, “15%”)
2025
-
[3]
Focus on extractable, verifiable data points—NOT opinions or general statements
-
[4]
qa_pairs
Each Q&A pair should be independently understandable with proper context in the question. Example of a good Q&A pair: Q: According to the India Skills Report 2025 (Key Findings and Government Initiatives), what is the projected global economic contribution of hybrid work models and digital nomadism by 2030? A: $500 billion Now analyze this webpage and gen...
2025
-
[5]
42”, “1,500 members
Answer Specificity & Verifiability:The answer must be verifiable and consist of specific, concrete information such as: • A specific number (e.g., “42”, “1,500 members”). • A particular name (e.g., “John Smith”, “Eiffel Tower”). • An exact model/designation (e.g., “Model T”, “Boeing 747”). • A precise date/year (e.g., “1945”, “March 15, 1990”). • A specif...
1945
-
[6]
Question Unambiguity:The question must be unambiguous with only one clear inter- pretation
-
[7]
Question Answerability:The question is clearly stated and it’s obvious what is being asked
-
[8]
how”, “why
Avoid Open-ended Questions:Must allow for a definite, measurable short answer (not an explanatory response). Questions shouldnotuse words like “how”, “why”, “ 怎么”, “如何”, “为什么”. 14 Preprint. Under review
-
[9]
Avoid Oversimplicity:The question and answer must not be common sense; if it’s too simple, filter it out
-
[10]
latest”, “most recent
Time Specificity:If the question refers to time-dependent information, it must include a specific, concrete time constraint. Vague temporal references like “latest”, “most recent”, “as of now”, “currently”, “so far”, “up to now”, “到目前为止”, “最新” arenotallowed. QA pair to evaluate: Question : { question } Answer : { answer } Please provide your reasoning for...
-
[11]
Younger” Season 2 Episode 3 “Like a Boss
What important event were Liza and Kelsey preparing for in this episode? Answer:In “Younger” Season 2 Episode 3 “Like a Boss”, Liza and Kelsey were preparing for the launch of their new publishing imprint while facing massive online criticism. Reasoning:
-
[12]
Question Independence: true - The question is self-contained
-
[13]
Answer Specificity: false - The answer is descriptive, not a specific fact
-
[16]
Avoid Open-ended Questions: false - Requires an explanatory description
-
[17]
Avoid Oversimplicity: true - Not common sense; requires searching
-
[18]
There are multiple false conditions, therefore the answer is\boxed{false}
Time Specificity: true - Contains specific year “2024”. There are multiple false conditions, therefore the answer is\boxed{false}. Example 2 Question:What was the gun configuration of the first production variant J22A (or J22 UBv) of the J22 fighter aircraft developed by the Swedish Royal Air Administration Aircraft Factory (FFVS) for the Swedish Air Forc...
2024
-
[19]
Question Independence: true - Fully self-contained
-
[20]
Answer Specificity: true - Specific technical specification
-
[21]
Question Unambiguity: true - Clearly asks about a specific configuration
-
[22]
Question Answerability: true - Clear and answerable
-
[23]
Avoid Open-ended Questions: true - Requires a precise technical answer
-
[25]
All conditions are true, therefore the answer is\boxed{true}
Time Specificity: true - Contains specific year “1940”. All conditions are true, therefore the answer is\boxed{true}. Example 3 Question:What was one of the main German fighter aircraft models that the Swedish J22 fighter faced during its service in the 1940s? Answer:FW 190 Reasoning:
1940
-
[27]
Answer Specificity: true - Specific aircraft model
-
[28]
Question Unambiguity: false - “one of” implies multiple correct answers
-
[29]
Question Answerability: true - Clear what is being asked
-
[30]
Avoid Open-ended Questions: true - Allows for a specific model name
-
[31]
Avoid Oversimplicity: true - Requires searching historical knowledge
-
[32]
There is a false condition, therefore the answer is\boxed{false}
Time Specificity: true - Contains specific decade “1940s”. There is a false condition, therefore the answer is\boxed{false}. Example 4 Question:In what year was the latest version of the annual report template file for the Cooperative Innovation High School (CIHS) in North Carolina released? Answer:2025 Reasoning:
2025
-
[33]
15 Preprint
Question Independence: true - Self-contained question. 15 Preprint. Under review
-
[34]
Answer Specificity: true - Specific year
-
[37]
Avoid Open-ended Questions: true - Requires a specific year
-
[38]
Avoid Oversimplicity: true - Requires searching about CIHS
-
[39]
Nature School
Time Specificity: false - “latest” is vague and changes over time. There is a false condition, therefore the answer is\boxed{false}. Example 5 Question:In June 1937, in a collective school in Valencia, Spain, how did a teacher who had studied at Barcelona’s “Nature School” (La Farigola) use the natural environment in teaching? Answer:Organized students to...
1937
-
[41]
Answer Specificity: false - Descriptive explanation rather than a specific fact
-
[44]
Avoid Open-ended Questions: false - Uses “how” which invites an explanatory response
-
[46]
June 1937
Time Specificity: true - Contains specific time “June 1937”. There are multiple false conditions, therefore the answer is\boxed{false}. Example 6 Question:What was Frances Tiafoe’s career tour-level finals record after his loss in the final of the 2025 Houston Men’s Clay Court Championship? Answer:3 wins, 7 losses Reasoning:
1937
-
[53]
All conditions are true, therefore the answer is\boxed{true}
Time Specificity: true - Contains specific year “2025”. All conditions are true, therefore the answer is\boxed{true}. Example 7 Question:What is Frances Tiafoe’s current career tour-level finals record? Answer:3 wins, 7 losses Reasoning:
2025
-
[54]
Question Independence: true - Self-contained question
-
[55]
Answer Specificity: true - Specific win-loss record
-
[56]
Question Unambiguity: true - Clear what is being asked
-
[57]
Question Answerability: true - The question is clearly stated
-
[58]
Avoid Open-ended Questions: true - Requires a specific record
-
[59]
Avoid Oversimplicity: true - Requires searching
-
[60]
There is a false condition, therefore the answer is\boxed{false}
Time Specificity: false - “current” is vague. There is a false condition, therefore the answer is\boxed{false}. IMPORTANT:If you think any question is a multiple-choice question or a yes/no question, answer false. Yes/no example: Question: 在2007年9月15日发表于《Biological Psychiatry》第62卷第6期的论文中,研究者在使 用卡比多巴处理大鼠脑片后,3,4-亚甲二氧基甲基苯丙胺(MDMA)诱导的放电抑制和膜超极化 现象是否消失? Answer:消...
-
[61]
Programs of Study
Knowledge Graph (≤N max) InputSeed entitye 0; hyperparamsN max =8,K feat =2,K ent =2 Search Query Serper API for entity ei; LLM selects reliable sources; crawl pages ExtractLLM extractsK feat factual features per entity from crawled evidence Discover LLM identifies ≤K ent new concrete entities + directed relations; exclude generic concepts (e.g., “Program...
-
[62]
Subgraph Sampling InitPick random nodev 0 ∈ Gas BFS root Grow Greedily add candidate with most edges to subgraph + perturbation Uniform(0, 0.5) Format Anonymize entity IDs; truncate to ≤3 features per entity; output 6-node subgraph
-
[63]
a late antique writer
Backward QA Gen SelectStrong LLM picks a target entity as the answer Constrain Convert each edge → relationship constraint with vague references (e.g., “a late antique writer”) Augment Optionally add minimal entity constraints from features (only if needed for uniqueness) ComposeIntegrate all constraints into a natural-language multi-hop question Output Q...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.