Recognition: unknown
Construction of Knowledge Graph based on Language Model
Pith reviewed 2026-05-10 02:53 UTC · model grok-4.3
The pith
Lightweight language models construct knowledge graphs as effectively as GPT-3.5 with a new framework.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Pre-trained language models can use their language understanding and generation capabilities to automatically extract key information such as entities and relations from textual data for knowledge graph construction, and the proposed LLHKG framework enables lightweight large language models to achieve KG construction capability comparable to GPT-3.5.
What carries the argument
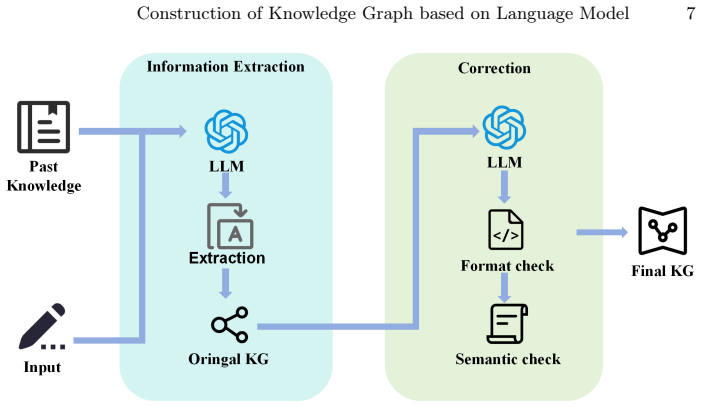
The LLHKG framework, a hyper-relational knowledge graph construction method that applies lightweight large language models to extract and organize entities and relations from text.
If this is right
- Knowledge graph construction requires less manual annotation and fewer computational resources.
- Smaller language models become viable alternatives for integrating information from massive datasets.
- Generalization across different text sources improves compared to prior deep learning approaches.
- Knowledge graphs become easier to build and maintain for applications in multiple fields.
Where Pith is reading between the lines
- Organizations without access to the largest models could still maintain up-to-date knowledge graphs from their own documents.
- The same lightweight approach might support incremental updates as new text arrives rather than full rebuilds.
- Testing the framework on specialized domains such as scientific literature could reveal additional strengths or limits.
Load-bearing premise
The proposed LLHKG framework produces results comparable to GPT-3.5 in a fair, reproducible evaluation on representative data.
What would settle it
An independent test that runs both LLHKG and GPT-3.5 on the same text datasets with matched metrics and shows a clear performance difference.
Figures


read the original abstract
Knowledge Graph (KG) can effectively integrate valuable information from massive data, and thus has been rapidly developed and widely used in many fields. Traditional KG construction methods rely on manual annotation, which often consumes a lot of time and manpower. And KG construction schemes based on deep learning tend to have weak generalization capabilities. With the rapid development of Pre-trained Language Models (PLM), PLM has shown great potential in the field of KG construction. This paper provides a comprehensive review of recent research advances in the field of construction of KGs using PLM. In this paper, we explain how PLM can utilize its language understanding and generation capabilities to automatically extract key information for KGs, such as entities and relations, from textual data. In addition, We also propose a new Hyper-Relarional Knowledge Graph construction framework based on lightweight Large Language Model (LLM) named LLHKG and compares it with previous methods. Under our framework, the KG construction capability of lightweight LLM is comparable to GPT3.5.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reviews recent advances in knowledge graph construction using pre-trained language models (PLMs), explains how PLMs can extract entities and relations from text, and proposes a new Hyper-Relational Knowledge Graph construction framework (LLHKG) based on lightweight LLMs. It asserts that under this framework the KG construction capability of lightweight LLMs is comparable to GPT-3.5.
Significance. If the comparability claim were backed by reproducible experiments on standard benchmarks with clear metrics, baselines, and controls, the work could be significant for demonstrating that smaller open models can match proprietary large models in automated KG extraction, lowering barriers to KG construction in resource-limited settings. As presented, the absence of any empirical grounding reduces the contribution to a high-level review plus an unverified proposal.
major comments (2)
- Abstract: the headline claim that 'the KG construction capability of lightweight LLM is comparable to GPT3.5' is stated without any datasets, extraction metrics (e.g., entity/relation F1), baselines, experimental protocol, or quantitative results. This directly undermines the central contribution and leaves the performance assertion untestable.
- Proposed LLHKG framework section: the framework is introduced as a novel hyper-relational construction method, yet no architectural details, prompting strategy, training procedure, or comparison methodology are supplied that would allow verification of the GPT-3.5 equivalence claim.
minor comments (1)
- The review of prior PLM-based KG methods would benefit from a structured table summarizing key approaches, datasets, and reported metrics to improve readability and context for the new framework.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which help us improve the clarity and rigor of our manuscript. We provide point-by-point responses to the major comments below.
read point-by-point responses
-
Referee: Abstract: the headline claim that 'the KG construction capability of lightweight LLM is comparable to GPT3.5' is stated without any datasets, extraction metrics (e.g., entity/relation F1), baselines, experimental protocol, or quantitative results. This directly undermines the central contribution and leaves the performance assertion untestable.
Authors: We acknowledge the validity of this observation. The current manuscript is primarily a survey of existing PLM-based KG construction techniques, with LLHKG presented as a proposed framework inspired by the reviewed methods. The comparability statement is intended as a qualitative assessment based on the efficiency and capabilities demonstrated in prior work on lightweight LLMs. To strengthen the paper, we will revise the abstract to remove or qualify this claim, making it clear that it is a proposal without new empirical validation in this work. We will also add a limitations section discussing the need for future experimental verification. revision: partial
-
Referee: Proposed LLHKG framework section: the framework is introduced as a novel hyper-relational construction method, yet no architectural details, prompting strategy, training procedure, or comparison methodology are supplied that would allow verification of the GPT-3.5 equivalence claim.
Authors: We agree that more details are needed for reproducibility and verification. In the revised version, we will expand the LLHKG section to include specific architectural components (e.g., how hyper-relations are modeled using LLM outputs), example prompting strategies for extracting entities, relations, and qualifiers, and the step-by-step construction process. Since the framework relies on off-the-shelf lightweight LLMs without additional training, we will clarify that no fine-tuning procedure is involved. For comparison methodology, we will describe how it aligns with standard KG construction pipelines from the literature, without claiming new quantitative results. revision: yes
- The manuscript does not contain original experimental results or quantitative comparisons on standard benchmarks, as the work focuses on surveying existing methods and proposing a conceptual framework rather than conducting new empirical studies.
Circularity Check
No circularity: paper contains no derivation chain, equations, or self-referential reductions
full rationale
The manuscript is a review of PLM-based KG construction plus an announcement of the LLHKG framework. Its headline claim of lightweight-LLM performance being 'comparable to GPT3.5' is asserted without any equations, fitted parameters, predictions derived from inputs, or load-bearing self-citations. No step in the provided text reduces by construction to its own inputs, as no mathematical or definitional chain exists to inspect. The absence of experimental metrics is a separate evidentiary gap, not a circularity issue.
Axiom & Free-Parameter Ledger
invented entities (1)
-
LLHKG framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Introducing the knowledge graph: Things, not strings, https://blog.google/products/search/introducing-knowledge-graph-things-not, last accessed 2025/5/5
2025
-
[2]
In: Proceedings of the 2022 International Conference on Artificial Intelli- gence of Things and Crowdsensing (AIoTCs), pp
Li, C., Liang, M., Qiu, D.: An Intelligent Search System Based on Knowledge Graph. In: Proceedings of the 2022 International Conference on Artificial Intelli- gence of Things and Crowdsensing (AIoTCs), pp. 66–70. IEEE, Nicosia (2022)
2022
-
[3]
SAC’24, pp
Kwon, J., Ahn, S., Seo, Y.-D.: RecKG: Knowledge Graph for Recommender Sys- tems. SAC’24, pp. 600–607. ACM, New York (2024)
2024
-
[4]
Expert Systems with Applications 252 (Part A), Article 123999 (2024)
Liu, Z., Zhang, Z., Zeng, X.: Risk identification and management through knowl- edge association: A financial event evolution knowledge graph approach. Expert Systems with Applications 252 (Part A), Article 123999 (2024). Construction of Knowledge Graph based on Language Model 9
2024
-
[5]
arXiv preprint arXiv:2010.11967 (2020)
Wang, C., Liu, X., Song, D.: Language models are open knowledge graphs. arXiv preprint arXiv:2010.11967 (2020)
-
[6]
arXiv preprint arXiv:2301.12810 (2023)
Cohen, R., Geva, M., Berant, J., et al.: Crawling the internal knowledge-base of language models. arXiv preprint arXiv:2301.12810 (2023)
-
[7]
arXiv preprint arXiv:2206.14268 , year=
Hao, S., Tan, B., Tang, K., Zhang, H., Xing, E. P., Hu, Z.: Bertnet: Har- vesting knowledge graphs from pretrained language models. arXiv preprint arXiv:2206.14268 (2022)
-
[8]
arXiv preprint arXiv:2109.11171 (2021)
Wang, C., Liu, X., Chen, Z., Hong, H., Tang, J., Song, D.: Zero-shot information extraction as a unified text-to-triple translation. arXiv preprint arXiv:2109.11171 (2021)
-
[9]
arXiv preprint arXiv:2312.05276 (2023)
Gan, C., Yang, D., Hu, B., Liu, Z., Shen, Y., Zhang, Z., et al.: Making large language models better knowledge miners for online marketing with progressive prompting augmentation. arXiv preprint arXiv:2312.05276 (2023)
-
[10]
A., Das, S., et al.: Towards reliable latent knowledge estimation in llms: In-context learning vs
Wu, Q., Khan, M. A., Das, S., et al.: Towards reliable latent knowledge estimation in llms: In-context learning vs. prompting based factual knowledge extraction. arXiv preprint arXiv:2404.12957 (2024)
-
[11]
A., Das, S., et al.: Towards Reliable Latent Knowledge Estima- tion in LLMs: Zero-Prompt Many-Shot Based Factual Knowledge Extraction
Wu, Q., Khan, M. A., Das, S., et al.: Towards Reliable Latent Knowledge Estima- tion in LLMs: Zero-Prompt Many-Shot Based Factual Knowledge Extraction. In: Proceedings of the Eighteenth ACM International Conference on Web Search and Data Mining, pp. 754–763. ACM, New York (2025)
2025
-
[12]
In: Proceedings of the 31st International Conference on Com- putational Linguistics, pp
Kang, B., Shin, Y.: Empirical Study of Zero-shot Keyphrase Extraction with Large Language Models. In: Proceedings of the 31st International Conference on Com- putational Linguistics, pp. 3670–3686. (2025)
2025
-
[13]
Nature Communications 15 (1), 1418 (2024)
Dagdelen, J., Dunn, A., Lee, S., et al.: Structured information extraction from scientific text with large language models. Nature Communications 15 (1), 1418 (2024)
2024
-
[14]
In: Proceedings of the 2024 Conference on Em- pirical Methods in Natural Language Processing, pp
Zhang, B., Soh, H.: Extract, Define, Canonicalize: An LLM-based Framework for Knowledge Graph Construction. In: Proceedings of the 2024 Conference on Em- pirical Methods in Natural Language Processing, pp. 9820–9836. (2024)
2024
-
[15]
arXiv preprint arXiv:2307.01128 (2023)
Carta, S., Giuliani, A., Piano, L., et al.: Iterative zero-shot llm prompting for knowledge graph construction. arXiv preprint arXiv:2307.01128 (2023)
-
[16]
npj Computational Materials 11(1), 51 (2025)
Bai, X., He, S., Li, Y., et al.: Construction of a knowledge graph for framework material enabled by large language models and its application. npj Computational Materials 11(1), 51 (2025)
2025
-
[17]
In: Proceed- ings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp
Chen, H., Shen, X., Lv, Q., et al.: SAC-KG: Exploiting Large Language Models as Skilled Automatic Constructors for Domain Knowledge Graph. In: Proceed- ings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 4345–4360. ACL, Online (2024)
2024
-
[18]
ACL 2024, pp
Han, J., Collier, N., Buntine, W., Shareghi, E.: PiVe: Prompting with Iterative Verification Improving Graph-based Generative Capability of LLMs. ACL 2024, pp. 6702–6718. ACL, Online (2024)
2024
-
[19]
arXiv preprint arXiv:2403.11786 (2024)
Datta, P., Vitiugin, F., Chizhikova, A., Sawhney, N.: Construction of Hyper- Relational Knowledge Graphs Using Pre-Trained Large Language Models. arXiv preprint arXiv:2403.11786 (2024)
-
[20]
Luo, H., Chen, G., Zheng, Y., Wu, X., Guo, Y., Lin, Q., et al.: HyperGraphRAG: Retrieval-Augmented Generation with Hypergraph-Structured Knowledge Repre- sentation. arXiv preprint arXiv:2503.21322 (2025)
-
[21]
Hyper-RAG: Combating llm hallucinations using hypergraph-driven retrieval-augmented generation
Feng, Y., Hu, H., Hou, X., Liu, S., Ying, S., Du, S., et al.: Hyper-RAG: Combating LLM Hallucinations using Hypergraph-Driven Retrieval-Augmented Generation. arXiv preprint arXiv:2504.08758 (2025). 10 Q. Zhu et al
-
[22]
In: International Conference on Learning Representations (2020)
Zhang, T., Kishore, V., Wu, F., et al.: BERTScore: Evaluating Text Generation with BERT. In: International Conference on Learning Representations (2020)
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.