Efficient INT8 Single-Image Super-Resolution via Deployment-Aware Quantization and Teacher-Guided Training
Pith reviewed 2026-05-10 00:11 UTC · model grok-4.3
The pith
A three-stage pipeline of basic supervision, teacher distillation, and quantization-aware training produces stable INT8 models for x3 single-image super-resolution on mobile hardware.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
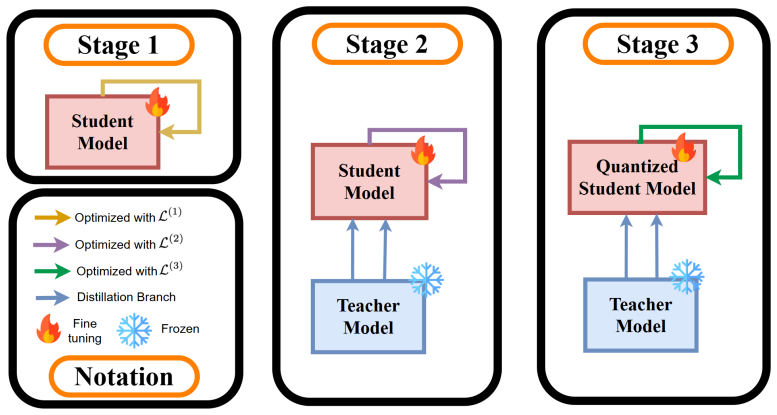
The extract-refine-upsample student, trained first with spatial supervision, then with Charbonnier plus DCT losses and confidence-weighted distillation from a Mamba teacher, and finally with quantization-aware training plus weight clipping and BatchNorm recalibration, yields an INT8 model that attains 29.79 dB PSNR and 0.8634 SSIM on the MAI 2026 Quantized 4K Image Super-Resolution Challenge test set under mobile deployment.
What carries the argument
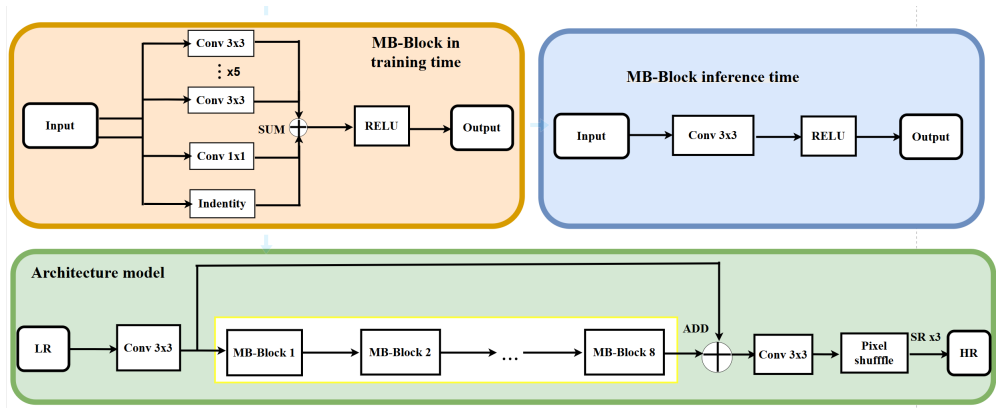
Extract-refine-upsample design with low-resolution re-parameterizable backbone and PixelShuffle reconstruction, trained end-to-end through the three-stage pipeline of spatial supervision, multi-term refinement with teacher distillation, and quantization-aware training with clipping and recalibration.
If this is right
- Most computation stays in low-resolution space, keeping the inference graph compact for mobile INT8.
- Teacher-guided supervision raises dynamic INT8 PSNR from 29.91 dB to 30.0003 dB while improving SSIM from 0.853 to 0.856.
- The fixed-shape deployable INT8 model reaches 30.006 dB PSNR and 0.857 SSIM.
- Weight clipping and BatchNorm recalibration after quantization-aware training stabilize the final INT8 artifact.
- The method targets x3 scaling specifically, balancing fidelity against the constraints of low-bit mobile deployment.
Where Pith is reading between the lines
- The same staged approach could be tested on other low-bit widths such as INT4 to measure how much additional quality loss occurs.
- Replacing the Mamba teacher with a different architecture might reveal whether the distillation benefit depends on the teacher's particular inductive bias.
- Running the final INT8 model on multiple mobile chipsets would test whether the reported 1.8 deployment score holds beyond the challenge hardware.
Load-bearing premise
The specific three-stage sequence of spatial supervision, Charbonnier-plus-DCT-plus-distillation refinement, and quantization-aware training with weight clipping will remain stable on real-world images and hardware not seen in the MAI challenge.
What would settle it
A drop below 29.5 dB PSNR or 0.85 SSIM on a fresh set of real-world 4K images when the same INT8 TFLite model is run on different mobile hardware would show the pipeline does not generalize as claimed.
Figures


read the original abstract
Efficient single-image super-resolution (SISR) requires balancing reconstruction fidelity, model compactness, and robustness under low-bit deployment, which is especially challenging for x3 SR. We present a deployment-oriented quantized SISR framework based on an extract-refine-upsample design. The student performs most computation in the low-resolution space and uses a lightweight re-parameterizable backbone with PixelShuffle reconstruction, yielding a compact inference graph. To improve quality without significantly increasing complexity, we adopt a three-stage training pipeline: Stage 1 learns a basic reconstruction mapping with spatial supervision; Stage 2 refines fidelity using Charbonnier loss, DCT-domain supervision, and confidence-weighted output-level distillation from a Mamba-based teacher; and Stage 3 applies quantization-aware training directly on the fused deploy graph. We further use weight clipping and BatchNorm recalibration to improve quantization stability. On the MAI 2026 Quantized 4K Image Super-Resolution Challenge test set, our final AIO MAI submission achieves 29.79 dB PSNR and 0.8634 SSIM, obtaining a final score of 1.8 under the target mobile INT8 deployment setting. Ablation on Stage 3 optimization shows that teacher-guided supervision improves the dynamic INT8 TFLite reconstruction from 29.91 dB/0.853 to 30.0003 dB/0.856, while the fixed-shape deployable INT8 TFLite artifact attains 30.006 dB/0.857.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an efficient INT8 quantized single-image super-resolution (SISR) framework for x3 upscaling based on an extract-refine-upsample student architecture with a lightweight re-parameterizable backbone and PixelShuffle. It uses a three-stage training pipeline: Stage 1 with spatial supervision, Stage 2 with Charbonnier loss, DCT-domain supervision, and confidence-weighted distillation from a Mamba teacher, and Stage 3 with quantization-aware training incorporating weight clipping and BatchNorm recalibration. The final model achieves 29.79 dB PSNR and 0.8634 SSIM on the MAI 2026 Quantized 4K Image Super-Resolution Challenge test set under mobile INT8 deployment, with an ablation showing teacher guidance improves dynamic INT8 TFLite performance.
Significance. If the results hold under broader conditions, the work provides a practical deployment-aware approach to quantized SISR that balances fidelity and compactness for mobile INT8 inference. The concrete challenge metrics and the targeted ablation on teacher-guided supervision in Stage 3 are strengths, as is the focus on re-parameterizable design for inference efficiency. However, the overall significance for the field is limited without evidence of generalization.
major comments (1)
- [Results] The evaluation reports results exclusively on the MAI 2026 challenge test set (Abstract and Results). Given the modest ablation gain from teacher guidance (~0.09 dB PSNR) and the central claim of stable INT8 performance, experiments on standard benchmarks such as DIV2K validation or Set5 are required to test whether the three-stage pipeline (spatial supervision, Charbonnier+DCT+distillation, QAT with clipping/BN recalibration) generalizes beyond the challenge distribution and the specific Mamba teacher.
minor comments (2)
- [Abstract] The abstract and results lack details on training dataset composition, number of images, or any error bars/standard deviations for the PSNR/SSIM metrics, which would aid reproducibility and assessment of result stability.
- [Results] No full baseline comparisons or tables against other quantized SR methods are visible, making it difficult to contextualize the 29.79 dB / 0.8634 SSIM achievement relative to prior work.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment point by point below.
read point-by-point responses
-
Referee: [Results] The evaluation reports results exclusively on the MAI 2026 challenge test set (Abstract and Results). Given the modest ablation gain from teacher guidance (~0.09 dB PSNR) and the central claim of stable INT8 performance, experiments on standard benchmarks such as DIV2K validation or Set5 are required to test whether the three-stage pipeline (spatial supervision, Charbonnier+DCT+distillation, QAT with clipping/BN recalibration) generalizes beyond the challenge distribution and the specific Mamba teacher.
Authors: We acknowledge that the manuscript reports results exclusively on the MAI 2026 Quantized 4K challenge test set. This focus is intentional, as the extract-refine-upsample architecture, lightweight re-parameterizable backbone with PixelShuffle, and the three-stage training pipeline (spatial supervision in Stage 1, Charbonnier+DCT+confidence-weighted distillation from the Mamba teacher in Stage 2, and QAT with weight clipping/BN recalibration in Stage 3) were specifically designed and optimized to satisfy the mobile INT8 deployment constraints and 4K x3 upscaling requirements of this challenge. The ablation demonstrates that teacher guidance improves dynamic INT8 TFLite performance within this setting (from 29.91 dB/0.853 to 30.0003 dB/0.856), supporting the claim of stable quantized inference for the target use case. Standard benchmarks such as DIV2K validation or Set5 involve lower resolutions and lack the quantized 4K mobile inference characteristics central to the work; adapting the full pipeline (including the Mamba teacher) to them would not directly validate performance under the intended deployment constraints. We therefore maintain that the challenge test set constitutes a rigorous and appropriate evaluation for the paper's contributions and do not plan to add results on DIV2K or Set5. revision: no
Circularity Check
No circularity: empirical results on external test set are independent of method description
full rationale
The paper describes a three-stage training pipeline (spatial supervision, Charbonnier+DCT+distillation, then QAT with clipping/BN recalibration) for an extract-refine-upsample student model and directly reports PSNR/SSIM scores on the MAI 2026 Quantized 4K challenge test set. No equations appear in the provided text, no fitted parameters are renamed as predictions, and no self-citations or uniqueness theorems are invoked to derive the final metrics. The reported numbers (29.79 dB PSNR, 0.8634 SSIM) are external empirical outcomes, not reductions of the method's own inputs by construction. The ablation gain is also a direct measurement, not a tautology.
Axiom & Free-Parameter Ledger
free parameters (2)
- relative weights among Charbonnier, DCT, and distillation losses
- quantization clipping thresholds and BN recalibration parameters
axioms (2)
- domain assumption Distillation from a Mamba-based teacher improves student fidelity under quantization constraints
- domain assumption The extract-refine-upsample design preserves reconstruction quality when most computation occurs in low-resolution space
Reference graph
Works this paper leans on
-
[1]
Ntire 2017 challenge on single image super-resolution: Dataset and study
Eirikur Agustsson and Radu Timofte. Ntire 2017 challenge on single image super-resolution: Dataset and study. InPro- ceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2017. 5
work page 2017
-
[2]
Fast, accurate, and lightweight super-resolution with cascading residual network
Namhyuk Ahn, Byungkon Kang, and Kyung-Ah Sohn. Fast, accurate, and lightweight super-resolution with cascading residual network. InECCV, 2018. 2
work page 2018
-
[3]
Freqnet: A frequency-domain image super-resolution network with dicrete cosine transform,
Runyuan Cai, Yue Ding, and Hongtao Lu. Freqnet: A frequency-domain image super-resolution network with dis- crete cosine transform.arXiv preprint arXiv:2111.10800,
-
[4]
Activating more pixels in image super- resolution transformer
Xiangyu Chen, Xintao Wang, Jiantao Zhou, Yu Qiao, and Chao Dong. Activating more pixels in image super- resolution transformer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 22367–22377, 2023. 1
work page 2023
-
[5]
Repvgg: Making vgg-style convnets great again
Xiaohan Ding, Xiangyu Zhang, Ningning Ma, Jungong Han, Guiguang Ding, and Jian Sun. Repvgg: Making vgg-style convnets great again. InCVPR, 2021. 2, 3, 5, 7
work page 2021
-
[6]
Accelerat- ing the super-resolution convolutional neural network, 2016
Chao Dong, Chen Change Loy, and Xiaoou Tang. Accelerat- ing the super-resolution convolutional neural network, 2016. 7
work page 2016
-
[7]
Anchor- based plain net for mobile image super-resolution
Zongcai Du, Jie Liu, Jie Tang, and Gangshan Wu. Anchor- based plain net for mobile image super-resolution. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, pages 2494– 2502, 2021. 7
work page 2021
-
[8]
Mambair: A simple baseline for image restoration with state-space model
Hang Guo, Jinmin Li, Tao Dai, Zhihao Ouyang, Xudong Ren, and Shu-Tao Xia. Mambair: A simple baseline for image restoration with state-space model. InECCV, pages 222–241, 2024. 2, 3
work page 2024
-
[9]
Mambairv2: Atten- tive state space restoration
Hang Guo, Yong Guo, Yaohua Zha, Yulun Zhang, Wenbo Li, Tao Dai, Shu-Tao Xia, and Yawei Li. Mambairv2: Atten- tive state space restoration. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025. 2, 3, 4
work page 2025
-
[10]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distill- ing the knowledge in a neural network.arXiv preprint arXiv:1503.02531, 2015. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[11]
Fast and accu- rate single image super-resolution via information distilla- tion network
Zheng Hui, Xiumei Wang, and Xinbo Gao. Fast and accu- rate single image super-resolution via information distilla- tion network. InCVPR, 2018. 2
work page 2018
-
[12]
Lightweight image super-resolution with information multi- distillation network
Zheng Hui, Xinbo Gao, Yunchu Yang, and Xiumei Wang. Lightweight image super-resolution with information multi- distillation network. InProceedings of the 27th ACM In- ternational Conference on Multimedia, pages 2024–2032,
work page 2024
-
[13]
Andrey Ignatov, Radu Timofte, et al. Efficient and accu- rate quantized image super-resolution on mobile npus, mo- bile ai & aim 2022 challenge: Report.arXiv preprint arXiv:2211.05910, 2022. 3
-
[14]
Quan- tized image super-resolution on mobile npus, mobile ai 2025 challenge: Report
Andrey Ignatov, Georgy Perevozchikov, Radu Timofte, Zhiyu Zhang, Tianxiao Gao, Yukun Yang, et al. Quan- tized image super-resolution on mobile npus, mobile ai 2025 challenge: Report. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition Work- shops (CVPRW), 2025. 3, 4, 5, 6
work page 2025
-
[15]
Quantization and training of neural networks for efficient integer-arithmetic-only inference
Benoit Jacob, Skirmantas Kligys, Bo Chen, Menglong Zhu, Matthew Tang, Andrew Howard, Hartwig Adam, and Dmitry Kalenichenko. Quantization and training of neural networks for efficient integer-arithmetic-only inference. InCVPR,
-
[16]
Deep laplacian pyramid networks for fast and accurate super-resolution
Wei-Sheng Lai, Jia-Bin Huang, Narendra Ahuja, and Ming- Hsuan Yang. Deep laplacian pyramid networks for fast and accurate super-resolution. InCVPR, 2017. 1, 2, 4
work page 2017
-
[17]
Dvmsr: Distillated vision mamba for efficient super-resolution
Xiaoyan Lei, Wenlong Zhang, and Weifeng Cao. Dvmsr: Distillated vision mamba for efficient super-resolution. In CVPR Workshops, 2024. 3
work page 2024
-
[18]
Swinir: Image restoration using swin transformer
Jingyun Liang, Jiezhang Cao, Guolei Sun, Kai Zhang, Luc Van Gool, and Radu Timofte. Swinir: Image restoration using swin transformer. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision Workshops (IC- CVW), 2021. 1
work page 2021
-
[19]
Enhanced deep residual networks for single image super-resolution
Bee Lim, Sanghyun Son, Heewon Kim, Seungjun Nah, and Kyoung Mu Lee. Enhanced deep residual networks for single image super-resolution. InCVPR Workshops, 2017. 1, 2
work page 2017
-
[20]
Residual feature dis- tillation network for lightweight image super-resolution
Jie Liu, Jie Tang, and Gangshan Wu. Residual feature dis- tillation network for lightweight image super-resolution. In Computer Vision – ECCV 2020 Workshops, pages 41–55,
work page 2020
-
[21]
Improving generalization in visual reasoning via self-ensemble, 2024
Tien-Huy Nguyen, Quang-Khai Tran, and Anh-Tuan Quang- Hoang. Improving generalization in visual reasoning via self-ensemble, 2024. 1
work page 2024
-
[22]
Hybrid, unified and itera- tive: A novel framework for text-based person anomaly re- trieval, 2025
Tien-Huy Nguyen, Huu-Loc Tran, Huu-Phong Phan- Nguyen, and Quang-Vinh Dinh. Hybrid, unified and itera- tive: A novel framework for text-based person anomaly re- trieval, 2025. 1
work page 2025
-
[23]
It- self: Attention guided fine-grained alignment for vision- language retrieval, 2026
Tien-Huy Nguyen, Huu-Loc Tran, and Thanh Duc Ngo. It- self: Attention guided fine-grained alignment for vision- language retrieval, 2026. 1
work page 2026
-
[24]
Ster-vlm: Spatio-temporal with enhanced reference vision- language models, 2025
Tinh-Anh Nguyen-Nhu, Triet Dao Hoang Minh, Dat To- Thanh, Phuc Le-Gia, Tuan V o-Lan, and Tien-Huy Nguyen. Ster-vlm: Spatio-temporal with enhanced reference vision- language models, 2025. 1
work page 2025
-
[25]
Huu-Phong Phan-Nguyen, Anh Dao, Tien-Huy Nguyen, Tuan Quang, Huu-Loc Tran, Tinh-Anh Nguyen-Nhu, Huy- Thach Pham, Quan Nguyen, Hoang M. Le, and Quang-Vinh Dinh. Cycle training with semi-supervised domain adapta- tion: Bridging accuracy and efficiency for real-time mobile scene detection, 2025. 2
work page 2025
-
[26]
Quantsr: Accu- rate low-bit quantization for efficient image super-resolution
Haotong Qin, Yulun Zhang, Yifu Ding, Yifan Liu, Xiang- long Liu, Martin Danelljan, and Fisher Yu. Quantsr: Accu- rate low-bit quantization for efficient image super-resolution. InAdvances in Neural Information Processing Systems 36 (NeurIPS 2023), 2023. 2, 3
work page 2023
-
[27]
Aitken, Rob Bishop, Daniel Rueckert, and Zehan Wang
Wenzhe Shi, Jose Caballero, Ferenc Huszar, Johannes Totz, Andrew P. Aitken, Rob Bishop, Daniel Rueckert, and Zehan Wang. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In CVPR, 2016. 1, 2, 3, 4
work page 2016
-
[28]
Post-training batchnorm recal- ibration.arXiv preprint arXiv:2010.05625, 2020
Gil Shomron and Uri Weiser. Post-training batchnorm recal- ibration.arXiv preprint arXiv:2010.05625, 2020. 2
-
[29]
Toward accurate post-training quantization for image super resolu- tion
Zhijun Tu, Jie Hu, Hanting Chen, and Yunhe Wang. Toward accurate post-training quantization for image super resolu- tion. InCVPR, pages 5856–5865, 2023. 3
work page 2023
-
[30]
Mobileone: An improved one millisecond mobile backbone
Pavan Kumar Anasosalu Vasu, James Gabriel, Jeff Zhu, On- cel Tuzel, and Anurag Ranjan. Mobileone: An improved one millisecond mobile backbone. InCVPR, 2023. 2, 3, 5, 7
work page 2023
-
[31]
Describe anything in medical images, 2025
Xi Xiao, Yunbei Zhang, Thanh-Huy Nguyen, Ba-Thinh Lam, Janet Wang, Lin Zhao, Jihun Hamm, Tianyang Wang, Xingjian Li, Xiao Wang, Hao Xu, Tianming Liu, and Min Xu. Describe anything in medical images, 2025. 1
work page 2025
-
[32]
Confidence-aware multi-teacher knowledge dis- tillation.arXiv preprint arXiv:2201.00007, 2022
Hailin Zhang, Defang Chen, and Can Wang. Confidence- aware multi-teacher knowledge distillation.arXiv preprint arXiv:2201.00007, 2022. 2
-
[33]
Image super-resolution using very deep residual channel attention networks
Yulun Zhang, Kunpeng Li, Kai Li, Lichen Wang, Bineng Zhong, and Yun Fu. Image super-resolution using very deep residual channel attention networks. InProceedings of the European Conference on Computer Vision (ECCV), 2018. 1
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.