FingerEye: Learning Dexterous Manipulation with Continuous Vision-Tactile Sensing
Pith reviewed 2026-05-09 23:40 UTC · model grok-4.3
The pith
FingerEye combines binocular cameras and a marker-tracked compliant ring to create one continuous perception stream from vision to tactile wrench estimates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
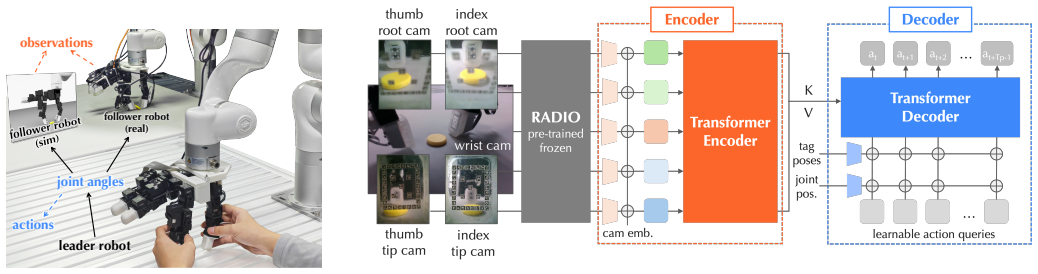
FingerEye integrates binocular RGB cameras for close-range visual perception with implicit stereo depth and marker-based pose estimation on a compliant ring to serve as a proxy for contact wrench sensing, enabling a perception stream that smoothly transitions from pre-contact visual cues to post-contact tactile feedback and supporting vision-tactile imitation learning for dexterous manipulation from limited real-world data augmented by simulated observations.
What carries the argument
Binocular camera pair plus marker-based pose estimation on a deformable ring that acts as wrench proxy.
If this is right
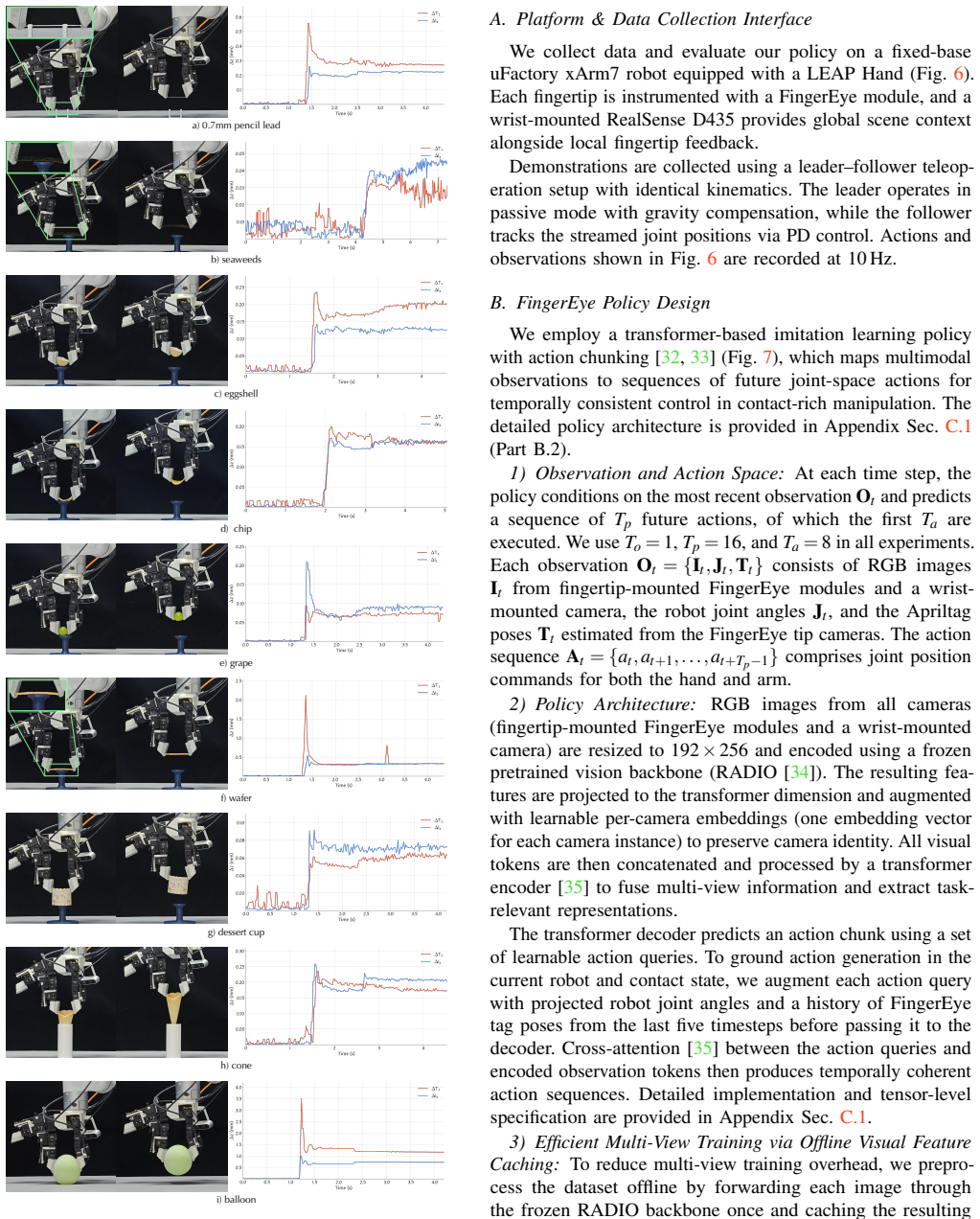
- Multiple FingerEye units can be fused to train policies for tasks such as coin standing, chip picking, letter retrieval, and syringe manipulation.
- Real demonstrations combined with visually augmented simulated observations improve policy robustness to object appearance changes.
- The sensor supplies both pre-contact depth cues and post-contact force estimates in one hardware package.
- A digital twin of the sensor and robot platform supports sim-to-real transfer without additional real-world data collection.
Where Pith is reading between the lines
- The approach could eliminate the need for separate vision systems and force sensors in future gripper designs.
- If the ring proxy holds under high-speed or high-force regimes, similar hybrid sensing could be retrofitted to existing compliant fingers.
- The digital-twin augmentation technique might transfer to other camera-based tactile sensors to reduce real-data requirements.
Load-bearing premise
Marker-tracked deformations of the compliant ring supply an accurate enough proxy for the full contact wrench across varied objects, forces, and contact angles.
What would settle it
Systematic mismatch between the ring-derived wrench estimates and simultaneous readings from a calibrated external force-torque sensor during repeated trials with different contact directions and object stiffnesses.
Figures













read the original abstract
Dexterous robotic manipulation requires perception that remains informative from pre-contact approach to contact initiation and post-contact control. We introduce FingerEye, a sensing and learning framework that strengthens robotic dexterity through continuous vision-tactile feedback throughout interaction. On the sensing side, FingerEye integrates binocular RGB cameras with a compliant contact interface to support perception both before and after contact. Before contact, the fingertip cameras provide close-range visual cues and implicit stereo for precise approach and object localization. After contact, marker-tracked deformation of the compliant ring provides a proxy for contact wrench sensing. On the learning side, we build real-and-sim infrastructure for data collection and evaluation, systematically study policy-interface designs for learning with multiple FingerEye sensors, and develop FingerEye Policy, which applies group-structured modality fusion to reduce modality shortcuts and better exploit distributed fingertip feedback. Across seven contact-sensitive task settings, FingerEye improves wrist-only policy by over 30 percentage points in mean success rate in both simulation and the real world.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FingerEye, a compact sensor that fuses binocular RGB cameras for pre-contact visual perception (with implicit stereo depth) and a compliant ring whose marker-tracked deformations serve as a proxy for post-contact 6D wrench sensing. This unified stream supports a multi-sensor vision-tactile imitation learning policy trained on limited real demonstrations, augmented via a digital twin for sim-to-real generalization, and is demonstrated on dexterous tasks including coin standing, chip picking, letter retrieving, and syringe manipulation.
Significance. If the deformation-to-wrench proxy can be shown to be accurate and reliable across regimes, the design would address a genuine gap in continuous perception for dexterous manipulation, enabling smoother contact initiation and policy learning with modest real-world data plus visual augmentation. The open release of hardware, code, and digital twin is a clear strength that supports reproducibility.
major comments (3)
- [Sensor Design] Sensor design and characterization: the central claim that marker-based pose estimation on the compliant ring provides a usable proxy for full contact wrench (3D force + 3D torque) is not supported by any explicit mapping (stiffness matrix, FEM model, or learned regressor), calibration procedure, or direct comparison to a reference force/torque sensor. Without this, the asserted smooth vision-to-tactile transition and reliable imitation learning rest on an unverified assumption.
- [Experiments] Experimental evaluation: task success is reported for the four manipulation scenarios, yet no quantitative metrics appear for wrench estimation accuracy (e.g., RMSE vs. ground truth, drift, saturation limits, or sensitivity to contact location/shear), nor any ablation isolating the contribution of the tactile proxy versus vision alone.
- [Imitation Learning] Imitation learning pipeline: the fusion of signals from multiple FingerEye units and the role of the digital twin in representation learning lack ablation studies or baseline comparisons that would demonstrate the necessity of the continuous vision-tactile stream for the claimed generalization gains.
minor comments (2)
- [Abstract / Sensor Design] The phrase 'implicit stereo depth' is used without a concrete description of the stereo algorithm, baseline, or expected depth accuracy at the close-range operating distances.
- [Figures] Figure captions and text could more clearly distinguish pre-contact visual cues from post-contact deformation signals to help readers follow the continuous perception claim.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which has identified important areas for clarification and strengthening in our manuscript. We address each major comment point by point below, outlining the revisions we will make.
read point-by-point responses
-
Referee: [Sensor Design] Sensor design and characterization: the central claim that marker-based pose estimation on the compliant ring provides a usable proxy for full contact wrench (3D force + 3D torque) is not supported by any explicit mapping (stiffness matrix, FEM model, or learned regressor), calibration procedure, or direct comparison to a reference force/torque sensor. Without this, the asserted smooth vision-to-tactile transition and reliable imitation learning rest on an unverified assumption.
Authors: We clarify that the policy directly ingests the 6D marker poses estimated from the binocular images as the tactile observation; these poses encode contact-induced deformations without an intermediate explicit wrench computation. The 'proxy' phrasing in the manuscript is conceptual, indicating that the deformation signal captures equivalent information to a wrench for the purposes of the imitation learning pipeline. The continuous perception stream arises because the same RGB cameras provide both pre-contact stereo vision and post-contact marker tracking. In the revision we will expand the sensor design section with the precise marker tracking algorithm, representation of the 6D pose in the observation vector, and a discussion of why an explicit stiffness mapping is unnecessary for our end-to-end approach. We will also add qualitative examples of marker deformation under varied contact conditions. revision: partial
-
Referee: [Experiments] Experimental evaluation: task success is reported for the four manipulation scenarios, yet no quantitative metrics appear for wrench estimation accuracy (e.g., RMSE vs. ground truth, drift, saturation limits, or sensitivity to contact location/shear), nor any ablation isolating the contribution of the tactile proxy versus vision alone.
Authors: The manuscript's primary evaluation is end-to-end task success on dexterous behaviors, which serves as the practical validation of the sensing approach. We agree that an ablation isolating the tactile component would be informative and will add a vision-only baseline comparison in the revised experiments section. For quantitative wrench metrics, we will include qualitative deformation visualizations and a limitations discussion noting the absence of reference-sensor calibration data; however, we cannot add RMSE or saturation figures without new experiments. revision: partial
-
Referee: [Imitation Learning] Imitation learning pipeline: the fusion of signals from multiple FingerEye units and the role of the digital twin in representation learning lack ablation studies or baseline comparisons that would demonstrate the necessity of the continuous vision-tactile stream for the claimed generalization gains.
Authors: We will add the requested ablation studies to the imitation learning section. These will compare the full multi-FingerEye vision-tactile policy against (i) a single-sensor variant, (ii) a vision-only variant, and (iii) a version without digital-twin augmentation, reporting success rates and generalization performance across the four tasks. This will directly quantify the contribution of the continuous sensing stream and the digital twin. revision: yes
- Quantitative wrench estimation accuracy (RMSE, drift, saturation limits, sensitivity to contact location/shear) versus a reference force/torque sensor, as no such calibration experiments were performed in the original work.
Circularity Check
No significant circularity: hardware design and imitation learning with no mathematical derivations or self-referential predictions
full rationale
The paper describes a sensor hardware design (binocular RGB cameras + compliant ring with marker-based pose estimation as proxy for contact wrench) and applies it to vision-tactile imitation learning for dexterous tasks. No equations, derivations, fitted parameters presented as predictions, or uniqueness theorems appear in the provided text. Claims rest on empirical demonstration and design choices rather than any chain that reduces to its own inputs by construction. Self-citations, if present, are not load-bearing for any core result. This matches the default expectation of non-circularity for applied robotics hardware papers.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.