Recognition: unknown
Learning to Evolve: A Self-Improving Framework for Multi-Agent Systems via Textual Parameter Graph Optimization
Pith reviewed 2026-05-09 23:38 UTC · model grok-4.3
The pith
Multi-agent systems can learn to improve their own designs by modeling components as an optimizable graph and deriving updates from execution history.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By modeling a multi-agent system as a Textual Parameter Graph and applying Group Relative Agent Optimization to learn from historical textual gradients, the framework enables the system to automatically refine its components and achieve higher success rates on complex tasks.
What carries the argument
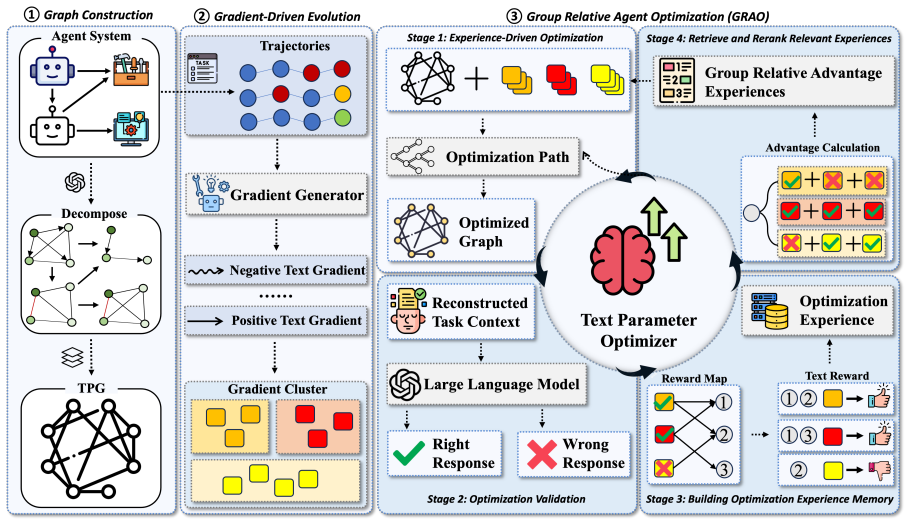
Textual Parameter Graph (TPG) that treats agents, tools, and workflows as modular optimizable nodes, paired with Group Relative Agent Optimization (GRAO) that learns improvement strategies from past optimization experiences.
If this is right
- State-of-the-art agent frameworks reach higher success rates on GAIA and MCP-Universe benchmarks.
- Optimization shifts from static prompt tuning to dynamic learning from past runs.
- Granular modifications become possible for debugging complex agent interactions.
- Labor required for agent engineering decreases as the system proposes its own updates.
Where Pith is reading between the lines
- The same graph-plus-textual-gradient pattern could extend to single-agent or code-generation systems.
- Accumulated optimization history might surface reusable design principles that transfer across unrelated tasks.
- Pairing textual gradients with numerical reward signals could produce more robust self-improvement.
Load-bearing premise
Structured natural language feedback from execution traces can reliably identify specific failures in agent interactions and that historical data yields improvement strategies that generalize without overfitting or instability.
What would settle it
Apply TPGO to a held-out multi-agent benchmark and observe no rise in success rate after multiple self-optimization rounds, or see performance drop from GRAO proposing unstable changes.
Figures

read the original abstract
Designing and optimizing multi-agent systems (MAS) is a complex, labor-intensive process of "Agent Engineering." Existing automatic optimization methods, primarily focused on flat prompt tuning, lack the structural awareness to debug the intricate web of interactions in MAS. More critically, these optimizers are static; they do not learn from experience to improve their own optimization strategies. To address these gaps, we introduce Textual Parameter Graph Optimization (TPGO), a framework that enables a multi-agent system to learn to evolve. TPGO first models the MAS as a Textual Parameter Graph (TPG), where agents, tools, and workflows are modular, optimizable nodes. To guide evolution, we derive "textual gradients," structured natural language feedback from execution traces, to pinpoint failures and suggest granular modifications. The core of our framework is Group Relative Agent Optimization (GRAO), a novel meta-learning strategy that learns from historical optimization experiences. By analyzing past successes and failures, GRAO becomes progressively better at proposing effective updates, allowing the system to learn how to optimize itself. Extensive experiments on complex benchmarks like GAIA and MCP-Universe show that TPGO significantly enhances the performance of state-of-the-art agent frameworks, achieving higher success rates through automated, self-improving optimization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Textual Parameter Graph Optimization (TPGO) for multi-agent systems (MAS). It represents the MAS as a Textual Parameter Graph (TPG) with modular nodes, derives structured textual gradients from execution traces to identify failures and propose modifications, and uses Group Relative Agent Optimization (GRAO) as a meta-learning mechanism that improves update proposals by analyzing historical optimization successes and failures. Experiments on GAIA and MCP-Universe are reported to show higher success rates than existing agent frameworks through this self-improving process.
Significance. If the core mechanisms hold, the work could meaningfully advance automated agent engineering by moving beyond static prompt tuning to experience-driven, adaptive optimization of complex MAS interactions. The combination of graph-structured parameterization and meta-learning from textual feedback offers a potentially scalable path to reducing manual debugging effort in multi-agent workflows.
major comments (3)
- [Abstract and §3] Abstract and §3 (Textual Gradients): The central claim that structured natural language feedback from execution traces can reliably pinpoint and correct failures in interdependent MAS interactions (e.g., coordination errors or tool-misuse chains) is load-bearing for both the TPG updates and the GRAO loop, yet no mechanism is described for validating gradient accuracy, resolving ambiguous or multiple plausible failure explanations, or mitigating LLM summarization noise on long multi-agent traces.
- [§4] §4 (GRAO): The meta-learning strategy that learns improvement strategies from historical optimization experiences lacks explicit safeguards against circularity or overfitting; if the same execution traces used to generate gradients are also used to train GRAO without held-out evaluation or cross-period validation, the reported performance gains may not reflect generalizable self-improvement.
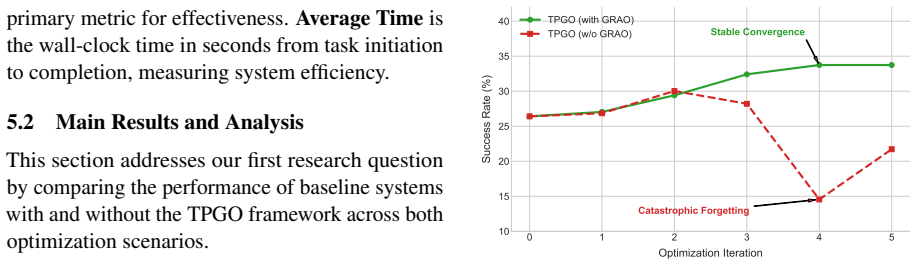
- [§5] §5 (Experiments): The abstract asserts that TPGO 'significantly enhances' state-of-the-art frameworks on GAIA and MCP-Universe, but no quantitative success rates, baseline comparisons, ablation results on the textual-gradient or GRAO components, or statistical analysis are provided to support the magnitude or robustness of the claimed gains.
minor comments (2)
- [Abstract] Abstract: The first use of 'TPGO' should be accompanied by its full expansion for immediate clarity.
- [§2] Notation: The distinction between 'textual gradients' and conventional numerical gradients should be made explicit early in the method section to avoid reader confusion.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We will revise the manuscript to strengthen the presentation of textual gradients, clarify the GRAO mechanism, and expand the experimental results with quantitative details.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Textual Gradients): The central claim that structured natural language feedback from execution traces can reliably pinpoint and correct failures in interdependent MAS interactions (e.g., coordination errors or tool-misuse chains) is load-bearing for both the TPG updates and the GRAO loop, yet no mechanism is described for validating gradient accuracy, resolving ambiguous or multiple plausible failure explanations, or mitigating LLM summarization noise on long multi-agent traces.
Authors: We acknowledge that the current §3 does not explicitly describe mechanisms for validating textual gradient accuracy, resolving ambiguities, or mitigating LLM noise. In the revised manuscript we will add a dedicated subsection to §3 outlining our mitigation strategies, including structured output templates, chain-of-thought prompting for failure localization, and cross-verification across multiple LLM calls. We will also discuss limitations arising from ambiguous explanations and how the modular TPG structure aids localization. revision: yes
-
Referee: [§4] §4 (GRAO): The meta-learning strategy that learns improvement strategies from historical optimization experiences lacks explicit safeguards against circularity or overfitting; if the same execution traces used to generate gradients are also used to train GRAO without held-out evaluation or cross-period validation, the reported performance gains may not reflect generalizable self-improvement.
Authors: We agree that explicit safeguards are needed to demonstrate generalizable meta-learning. Although GRAO is designed to operate on historical optimization episodes, the manuscript does not detail data separation. We will revise §4 to specify the use of temporally separated historical data, a held-out validation subset for GRAO updates, and cross-period evaluation protocols, thereby clarifying that reported gains arise from learned optimization strategies rather than overfitting to current traces. revision: yes
-
Referee: [§5] §5 (Experiments): The abstract asserts that TPGO 'significantly enhances' state-of-the-art frameworks on GAIA and MCP-Universe, but no quantitative success rates, baseline comparisons, ablation results on the textual-gradient or GRAO components, or statistical analysis are provided to support the magnitude or robustness of the claimed gains.
Authors: We agree that the experimental section requires more quantitative support. While §5 reports performance improvements, we will expand it in the revision to include concrete success rates on GAIA and MCP-Universe, direct comparisons against baselines, ablation studies isolating the textual-gradient and GRAO components, and statistical analysis (means, standard deviations, and significance tests across multiple runs) presented in tables. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces TPGO as a modeling framework (TPG nodes plus textual gradients) and GRAO as a meta-learning loop over historical traces, but presents no equations, fitted parameters, or self-citations that reduce any claimed result to its inputs by construction. The central claims rest on empirical benchmark gains rather than a closed mathematical derivation, so the chain remains non-circular.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Natural language execution traces can be converted into structured, actionable optimization signals
invented entities (2)
-
Textual Parameter Graph (TPG)
no independent evidence
-
Group Relative Agent Optimization (GRAO)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2310.16427 , year=
Promptagent: Strategic planning with language models enables expert-level prompt optimization , author=. arXiv preprint arXiv:2310.16427 , year=
-
[2]
Proceedings of the 31st International Conference on Computational Linguistics , pages=
Evoprompt: Evolving prompts for enhanced zero-shot named entity recognition with large language models , author=. Proceedings of the 31st International Conference on Computational Linguistics , pages=
-
[3]
TextGrad: Automatic "Differentiation" via Text
Textgrad: Automatic" differentiation" via text , author=. arXiv preprint arXiv:2406.07496 , year=
work page internal anchor Pith review arXiv
-
[4]
Narasimhan and Yuan Cao , title =
Shunyu Yao and Jeffrey Zhao and Dian Yu and Nan Du and Izhak Shafran and Karthik R. Narasimhan and Yuan Cao , title =. The Eleventh International Conference on Learning Representations,. 2023 , url =
2023
-
[5]
Chawla and Olaf Wiest and Xiangliang Zhang , title =
Taicheng Guo and Xiuying Chen and Yaqi Wang and Ruidi Chang and Shichao Pei and Nitesh V. Chawla and Olaf Wiest and Xiangliang Zhang , title =. Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence,. 2024 , url =
2024
-
[6]
Multi-Agent Collaboration Mechanisms: A Survey of LLMs
Khanh. Multi-Agent Collaboration Mechanisms:. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2501.06322 , eprinttype =. 2501.06322 , timestamp =
work page internal anchor Pith review doi:10.48550/arxiv.2501.06322 2025
-
[7]
Joon Sung Park and Joseph C. O'Brien and Carrie Jun Cai and Meredith Ringel Morris and Percy Liang and Michael S. Bernstein , editor =. Generative Agents: Interactive Simulacra of Human Behavior , booktitle =. 2023 , url =. doi:10.1145/3586183.3606763 , timestamp =
-
[8]
arXiv preprint arXiv:2410.19245 , year=
MaCTG: Multi-Agent Collaborative Thought Graph for Automatic Programming , author=. arXiv preprint arXiv:2410.19245 , year=
-
[9]
arXiv preprint arXiv:2505.21116 , year=
Creativity in LLM-based Multi-Agent Systems: A Survey , author=. arXiv preprint arXiv:2505.21116 , year=
-
[10]
Exploring collaboration mechanisms for
Jintian Zhang and Xin Xu and Ningyu Zhang and Ruibo Liu and Bryan Hooi and Shumin Deng , editor =. Exploring Collaboration Mechanisms for. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers),. 2024 , url =. doi:10.18653/V1/2024.ACL-LONG.782 , timestamp =
-
[11]
The Twelfth International Conference on Learning Representations , year=
Gaia: a benchmark for general ai assistants , author=. The Twelfth International Conference on Learning Representations , year=
-
[12]
Mcp-universe: Benchmarking large language models with real-world model context protocol servers , author=. arXiv preprint arXiv:2508.14704 , year=
-
[13]
MiroFlow: A High-Performance Open-Source Research Agent Framework , author=
-
[14]
The Twelfth International Conference on Learning Representations , year=
MetaGPT: Meta programming for a multi-agent collaborative framework , author=. The Twelfth International Conference on Learning Representations , year=
-
[15]
Multi-agent collaboration: Harnessing the power of intelligent llm agents , author=. arXiv preprint arXiv:2306.03314 , year=
-
[16]
Large Language Model Agent: A Survey on Methodology, Applications and Challenges
Large language model agent: A survey on methodology, applications and challenges , author=. arXiv preprint arXiv:2503.21460 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Multi-Agent Collaboration Mechanisms: A Survey of LLMs
Multi-agent collaboration mechanisms: A survey of llms , author=. arXiv preprint arXiv:2501.06322 , year=
work page internal anchor Pith review arXiv
-
[18]
A comprehensive survey of self-evolving ai agents: A new paradigm bridging foundation models and lifelong agentic systems , author=. arXiv preprint arXiv:2508.07407 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.