FlyCatcher: Neural Inference of Runtime Checkers from Tests
Pith reviewed 2026-05-09 20:57 UTC · model grok-4.3
The pith
FlyCatcher infers stateful runtime checkers from tests by combining language model synthesis with static and dynamic analysis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
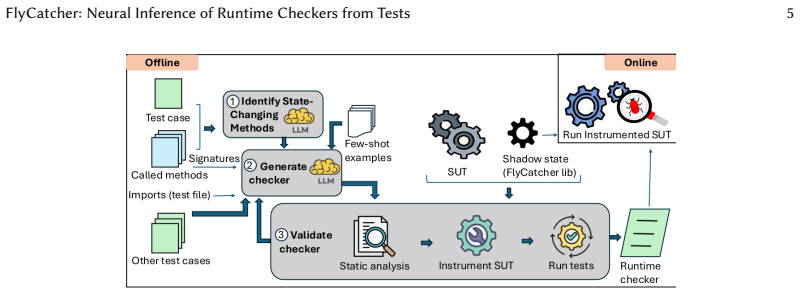
FlyCatcher derives runtime checkers from tests by using language-model synthesis to generate candidate stateful monitors, then applies static analysis to ensure they are well-formed and dynamic validation on the original tests to confirm they correctly assert properties that should hold at method calls. The resulting checkers track a shadow state that abstracts only the information needed for the assertions. When applied to 400 tests from four complex systems, the method produced 334 checkers of which 300 survived cross-validation, yielding 2.6 times as many correct checkers and enabling detection of 5.2 times as many errors as a prior state-of-the-art technique.
What carries the argument
The combination of language-model synthesis, static analysis, and dynamic validation that produces stateful checkers maintaining a shadow state to abstract system behavior at monitored method calls.
If this is right
- Existing test suites become a direct source of hundreds of additional runtime monitors without further manual coding.
- The same systems can now be instrumented to catch 5.2 times as many silent failures as with prior inference techniques.
- Runtime checking shifts from a rarely used practice to one that can be applied automatically once tests exist.
- Checkers remain stateful and can therefore enforce properties that depend on sequences of method calls rather than single invocations.
Where Pith is reading between the lines
- Developers could run the inference step periodically as tests evolve, keeping the set of checkers synchronized with changing code.
- The approach might be applied to other artifacts such as requirement documents or bug reports that also encode intended behavior.
- Integration into continuous-integration pipelines would let failing checkers surface during routine builds rather than only in production.
Load-bearing premise
The combination of language-model synthesis, static analysis, and dynamic validation can reliably turn properties observed in specific test executions into assertions that hold for arbitrary future runs of the same system.
What would settle it
Apply the inferred checkers to a fresh set of executions containing known silent failures and observe that many of the checkers either miss the failures or raise incorrect assertions on correct runs.
Figures







read the original abstract
Complex software systems often suffer from silent failures, i.e., violations of the intended semantics that do not cause explicit errors. A promising approach to detect such errors is to use system-specific runtime checkers that monitor the execution of a system and check for violations of the intended semantics. However, writing such checkers for a given software system is challenging and time-consuming, and hence, rarely done in practice. This work presents FlyCatcher, an automated approach to derive runtime checkers from existing tests, i.e., from a resource available for most software systems. The critical challenge of such an approach is to generalize the behavioral properties encoded in a test case to arbitrary executions of a system. FlyCatcher addresses this challenge through a combination of LLM-based synthesis, static analysis, and dynamic validation, which infers a checker that monitors specific method calls and asserts properties that should hold when they are called. The inferred checkers are stateful, i.e., they reason about the system's behavior by maintaining a shadow state that abstracts the actual system state as needed by the checker. Our evaluation applies FlyCatcher to 400 tests from four widely used, complex software systems. The approach infers 334 checkers, out of which 300 are found to be correct via cross-validation. Compared with a state-of-the-art approach, our approach infers 2.6x more correct checkers, which enables it to detect 5.2x more errors. By contributing to the automated inference of runtime checkers from tests, this work enables the broader adoption of runtime checking as a practical approach to detect silent failures in complex software systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents FlyCatcher, an approach to automatically infer stateful runtime checkers from existing tests via a combination of LLM-based synthesis, static analysis, and dynamic validation. The checkers monitor specific method calls and assert properties using a shadow-state abstraction of the system. Evaluation applies the approach to 400 tests across four complex real-world software systems, inferring 334 checkers of which 300 are reported correct via cross-validation; the method is claimed to produce 2.6x more correct checkers than a state-of-the-art baseline and to detect 5.2x more errors.
Significance. If the generalization from test-derived checkers to arbitrary executions can be shown to hold reliably, the work would be significant for lowering the barrier to runtime verification in practice, as it automates creation of system-specific checkers from a resource (tests) that is already widely available. The empirical scale—real systems, hundreds of tests, quantitative SOTA comparison—is a positive aspect that could support adoption if the validation concerns are resolved.
major comments (2)
- [Abstract and Evaluation] Abstract and Evaluation section: The abstract identifies generalization of test-encoded properties to arbitrary executions as the critical challenge, yet the reported cross-validation (300/334 checkers correct) provides no evidence that held-out executions exercise control or data flows absent from the inference-time tests. If validation re-uses or splits the original 400-test distribution, the results cannot rule out overfitting by the LLM synthesis step and therefore do not substantiate the central claim.
- [Evaluation] Evaluation section: The claims of 2.6x more correct checkers and 5.2x more errors detected relative to SOTA lack sufficient methodological detail—specifically, which SOTA tool was used, how it was configured or reproduced, the precise definition of “correct” in cross-validation, and any protocol for mitigating LLM non-determinism (e.g., multiple synthesis runs or temperature settings). These omissions make the quantitative superiority difficult to assess or replicate.
minor comments (1)
- [Abstract] The abstract would benefit from naming the four software systems and briefly characterizing the kinds of silent failures the checkers target, improving reader orientation without lengthening the text.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our manuscript. We address each major comment below and describe the revisions we will make to strengthen the presentation of our evaluation and claims.
read point-by-point responses
-
Referee: [Abstract and Evaluation] Abstract and Evaluation section: The abstract identifies generalization of test-encoded properties to arbitrary executions as the critical challenge, yet the reported cross-validation (300/334 checkers correct) provides no evidence that held-out executions exercise control or data flows absent from the inference-time tests. If validation re-uses or splits the original 400-test distribution, the results cannot rule out overfitting by the LLM synthesis step and therefore do not substantiate the central claim.
Authors: We agree that cross-validation performed by splitting the 400-test corpus provides evidence that the inferred checkers are consistent with the test distribution but does not by itself prove generalization to control or data flows entirely absent from all tests. The tests were chosen to exercise diverse method sequences and inputs across the four systems, and our cross-validation protocol holds out entire tests (not just individual assertions) to increase the chance that held-out executions differ in exercised behaviors. Nevertheless, the referee correctly identifies that this does not fully rule out overfitting to the test distribution. In the revised manuscript we will (1) explicitly describe the splitting procedure and the diversity metrics used to form the folds, (2) add a dedicated limitations paragraph discussing the scope of generalization, and (3) soften the abstract claim to state that the checkers are correct on held-out tests drawn from the same corpus while noting the open question of broader generalization. revision: yes
-
Referee: [Evaluation] Evaluation section: The claims of 2.6x more correct checkers and 5.2x more errors detected relative to SOTA lack sufficient methodological detail—specifically, which SOTA tool was used, how it was configured or reproduced, the precise definition of “correct” in cross-validation, and any protocol for mitigating LLM non-determinism (e.g., multiple synthesis runs or temperature settings). These omissions make the quantitative superiority difficult to assess or replicate.
Authors: We thank the referee for highlighting these omissions. The baseline is the state-of-the-art test-to-checker synthesis tool described in the prior work we cite; we used the authors’ publicly released implementation with the exact parameter settings reported in that paper. A checker is labeled “correct” if it produces no false-positive violations on any held-out test in the cross-validation fold. To mitigate LLM non-determinism we fixed the temperature to 0, used a deterministic decoding strategy, and performed three independent synthesis runs per test, retaining the checker that passed the largest number of validation tests (or reporting the union when multiple checkers were produced). We will expand the Evaluation section with a new subsection that lists the precise baseline tool name and version, all configuration parameters, the exact definition of correctness, the number of synthesis repetitions, and the aggregation rule, together with a pointer to the replication package that contains the scripts and seeds used. revision: yes
Circularity Check
No circularity: empirical inference validated on independent test suites
full rationale
The paper describes an empirical method (LLM synthesis + static analysis + dynamic validation) applied to 400 tests from four real systems, producing 334 checkers with 300 deemed correct via cross-validation and 2.6x/5.2x gains over SOTA. No derivation chain, equations, or theorems exist that reduce a claimed result to its own inputs by construction. Cross-validation and external system benchmarks provide independent falsifiability; no self-citation is load-bearing for the central claims, and no fitted parameter is relabeled as a prediction. The approach is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Tests contain generalizable behavioral properties for the system
Reference graph
Works this paper leans on
-
[1]
2026. CodeQL. https://codeql.github.com/ Accessed: 2026-01-29
work page 2026
-
[2]
Jepsen: Distributed Systems Safety Research
2026. Jepsen: Distributed Systems Safety Research. https://jepsen.io/ Accessed: 2026-01-29
work page 2026
-
[3]
Ramnatthan Alagappan, Aishwarya Ganesan, Jing Liu, Andrea Arpaci-Dusseau, and Remzi Arpaci-Dusseau. 2018. Fault-Tolerance, Fast and Slow: Exploiting Failure Asynchrony in Distributed Systems. In13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18). USENIX Association, Carlsbad, CA, 390–408. https: //www.usenix.org/conference/osdi1...
work page 2018
-
[4]
Glenn Ammons, Rastislav Bodík, and James R. Larus. 2002. Mining specifications. InProceedings of the 29th ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages(Portland, Oregon)(POPL ’02). Association for Computing Machinery, New York, NY, USA, 4–16. doi:10.1145/503272.503275 , Vol. 1, No. 1, Article . Publication date: April 2026. FlyCatche...
-
[5]
George Amvrosiadis and Medha Bhadkamkar. 2016. Getting Back Up: Understanding How Enterprise Data Backups Fail. In2016 USENIX Annual Technical Conference (USENIX ATC 16). USENIX Association, Denver, CO, 479–492. https://www.usenix.org/conference/atc16/technical-sessions/presentation/amvrosiadis
work page 2016
-
[6]
Matthew Arnold, Martin T. Vechev, and Eran Yahav. 2008. QVM: An efficient runtime for detecting defects in deployed systems. InConference on Object-Oriented Programming, Systems, Languages, and Applications (OOPSLA). ACM, 143–162
work page 2008
-
[7]
Alberto Bacchelli, Paolo Ciancarini, and Davide Rossi. 2008. On the Effectiveness of Manual and Automatic Unit Test Generation. InProceedings of the Third International Conference on Software Engineering Advances, ICSEA 2008, October 26-31, 2008, Sliema, Malta. IEEE Computer Society, 252–257. doi:10.1109/ICSEA.2008.66
-
[8]
Grounded copilot: How programmers interact with code-generating models,
Shraddha Barke, Michael B. James, and Nadia Polikarpova. 2023. Grounded Copilot: How Programmers Interact with Code-Generating Models.Proc. ACM Program. Lang.7, OOPSLA1 (2023), 85–111. doi:10.1145/3586030
-
[9]
Ivan Beschastnikh, Yuriy Brun, Michael D. Ernst, and Arvind Krishnamurthy. 2014. Inferring models of concurrent systems from logs of their behavior with CSight. InProceedings of the 36th International Conference on Software Engineering(Hyderabad, India)(ICSE 2014). Association for Computing Machinery, New York, NY, USA, 468–479. doi:10.1145/2568225.2568246
-
[10]
Jacob Burnim, Tayfun Elmas, George C. Necula, and Koushik Sen. 2011. NDSeq: runtime checking for nondeterministic sequential specifications of parallel correctness. InConference on Programming Language Design and Implementation (PLDI). ACM, 401–414
work page 2011
-
[11]
Jacob Burnim and Koushik Sen. 2010. DETERMIN: inferring likely deterministic specifications of multithreaded programs. InInternational Conference on Software Engineering (ICSE). ACM, 415–424
work page 2010
-
[12]
Feng Chen and Grigore Rosu. 2007. MOP: An efficient and generic runtime verification framework. InConference on Object-Oriented Programming, Systems, Languages, and Applications (OOPSLA). ACM, 569–588
work page 2007
-
[13]
Yinfang Chen, Huaibing Xie, Minghua Ma, Yu Kang, Xin Gao, Liu Shi, Yunjie Cao, Xuedong Gao, Hao Fan, Ming Wen, Jun Zeng, Supriyo Ghosh, Xuchao Zhang, Chaoyun Zhang, Qingwei Lin, Saravan Rajmohan, Dongmei Zhang, and Tianyin Xu. 2024. Automatic Root Cause Analysis via Large Language Models for Cloud Incidents. InProceedings of the Nineteenth European Confer...
-
[14]
Alvin Cheung and Samuel Madden. 2008. Performance profiling with EndoScope, an acquisitional software monitoring framework.Proc. VLDB Endow.1, 1 (aug 2008), 42–53. doi:10.14778/1453856.1453866
-
[15]
Mihai Christodorescu, Somesh Jha, and Christopher Kruegel. 2007. Mining specifications of malicious behavior. InProceedings of the the 6th Joint Meeting of the European Software Engineering Conference and the ACM SIGSOFT Symposium on The Foundations of Software Engineering(Dubrovnik, Croatia)(ESEC-FSE ’07). Association for Computing Machinery, New York, N...
-
[16]
Henry Coles, Thomas Laurent, Christopher Henard, Mike Papadakis, and Anthony Ventresque. 2016. PIT: a practical mutation testing tool for Java (demo). InProceedings of the 25th International Symposium on Software Testing and Analysis, ISSTA 2016, Saarbrücken, Germany, July 18-20, 2016, Andreas Zeller and Abhik Roychoudhury (Eds.). ACM, 449–452. doi:10.114...
-
[17]
Christoph Csallner, Nikolai Tillmann, and Yannis Smaragdakis. 2008. DySy: dynamic symbolic execution for invariant inference. InProceedings of the 30th International Conference on Software Engineering(Leipzig, Germany)(ICSE ’08). Association for Computing Machinery, New York, NY, USA, 281–290. doi:10.1145/1368088.1368127
-
[18]
Joshua Heneage Dawes and Domenico Bianculli. 2024. Checking complex source code-level constraints using runtime verification. InCompanion Proceedings of the 32nd ACM International Conference on the Foundations of Software Engineering. 255–265
work page 2024
-
[19]
R. A. DeMillo, R. J. Lipton, and F. G. Sayward. 1978. Hints on test data selection help for the practicing programmer. IEEE Computer11, 4 (April 1978), 34–41
work page 1978
-
[20]
Xueying Du, Mingwei Liu, Kaixin Wang, Hanlin Wang, Junwei Liu, Yixuan Chen, Jiayi Feng, Chaofeng Sha, Xin Peng, and Yiling Lou. 2024. Evaluating Large Language Models in Class-Level Code Generation. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering(Lisbon, Portugal)(ICSE ’24). Association for Computing Machinery, New York...
-
[21]
Aryaz Eghbali, Felix Burk, and Michael Pradel. 2025. DyLin: A Dynamic Linter for Python.Proc. ACM Softw. Eng.2, FSE (2025), 2828–2849. doi:10.1145/3729395
-
[22]
Aryaz Eghbali and Michael Pradel. 2022. DynaPyt: A Dynamic Analysis Framework for Python. InESEC/FSE ’22: 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering. ACM
work page 2022
-
[23]
Ernst, Jake Cockrell, William G
Michael D. Ernst, Jake Cockrell, William G. Griswold, and David Notkin. 1999. Dynamically Discovering Likely Program Invariants to Support Program Evolution. InProceedings of the 21st International Conference on Software Engineering(Los Angeles, California, USA)(ICSE ’99). ACM, New York, NY, USA, 213–224. doi:10.1145/302405.302467 , Vol. 1, No. 1, Article...
-
[24]
Ernst, Jake Cockrell, William G
Michael D. Ernst, Jake Cockrell, William G. Griswold, and David Notkin. 2001. Dynamically discovering likely program invariants to support program evolution.IEEE Transactions on Software Engineering27, 2 (2001), 213–224
work page 2001
-
[25]
Sarah Fakhoury, Aaditya Naik, Georgios Sakkas, Saikat Chakraborty, and Shuvendu K. Lahiri. 2024. LLM-Based Test-Driven Interactive Code Generation: User Study and Empirical Evaluation.IEEE Trans. Softw. Eng.50, 9 (Sept. 2024), 2254–2268. doi:10.1109/TSE.2024.3428972
-
[26]
Aishwarya Ganesan, Ramnatthan Alagappan, Andrea C. Arpaci-Dusseau, and Remzi H. Arpaci-Dusseau. 2017. Redun- dancy Does Not Imply Fault Tolerance: Analysis of Distributed Storage Reactions to Single Errors and Corruptions. In 15th USENIX Conference on File and Storage Technologies (FAST 17). USENIX Association, Santa Clara, CA, 149–166. https://www.usenix...
work page 2017
-
[27]
Liang Gong, Michael Pradel, Manu Sridharan, and Koushik Sen. 2015. DLint: Dynamically Checking Bad Coding Practices in JavaScript. InInternational Symposium on Software Testing and Analysis (ISSTA). 94–105
work page 2015
-
[28]
Stewart Grant, Hendrik Cech, and Ivan Beschastnikh. 2018. Inferring and asserting distributed system invariants. In Proceedings of the 40th International Conference on Software Engineering. 1149–1159
work page 2018
-
[29]
Kevin Guan, Marcelo d’Amorim, and Owolabi Legunsen. 2025. Faster Explicit-Trace Monitoring-Oriented Programming for Runtime Verification of Software Tests.Proc. ACM Program. Lang.9, OOPSLA2, Article 405 (Oct. 2025), 30 pages. doi:10.1145/3763183
-
[30]
Kevin Guan and Owolabi Legunsen. 2025. TraceMOP: An Explicit-Trace Runtime Verification Tool for Java. In Proceedings of the 33rd ACM International Conference on the Foundations of Software Engineering. 1218–1222
work page 2025
-
[31]
Haryadi S. Gunawi, Riza O. Suminto, Russell Sears, Casey Golliher, Swaminathan Sundararaman, Xing Lin, Tim Emami, Weiguang Sheng, Nematollah Bidokhti, Caitie McCaffrey, Gary Grider, Parks M. Fields, Kevin Harms, Robert B. Ross, Andree Jacobson, Robert Ricci, Kirk Webb, Peter Alvaro, H. Birali Runesha, Mingzhe Hao, and Huaicheng Li. 2018. Fail-slow at Scal...
-
[32]
Andrew Habib and Michael Pradel. 2018. How many of all bugs do we find? a study of static bug detectors. InASE. ACM, 317–328
work page 2018
-
[33]
Sudheendra Hangal and Monica S. Lam. 2002. Tracking down Software Bugs Using Automatic Anomaly Detection. In Proceedings of the 24th International Conference on Software Engineering(Orlando, Florida)(ICSE ’02). Association for Computing Machinery, New York, NY, USA, 291–301. doi:10.1145/581339.581377
-
[34]
Lexiang Huang, Matthew Magnusson, Abishek Bangalore Muralikrishna, Salman Estyak, Rebecca Isaacs, Abutalib Aghayev, Timothy Zhu, and Aleksey Charapko. 2022. Metastable Failures in the Wild. In16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22). USENIX Association, Carlsbad, CA, 73–90. https://www. usenix.org/conference/osdi22/pr...
work page 2022
-
[35]
Lorch, Yingnong Dang, Murali Chintalapati, and Randolph Yao
Peng Huang, Chuanxiong Guo, Lidong Zhou, Jacob R. Lorch, Yingnong Dang, Murali Chintalapati, and Randolph Yao
-
[36]
InProceedings of the 16th Workshop on Hot Topics in Operating Systems (HotOS XVI)
Gray Failure: The Achilles’ Heel of Cloud-Scale Systems. InProceedings of the 16th Workshop on Hot Topics in Operating Systems (HotOS XVI). ACM, British Columbia, Canada, 7 pages
-
[37]
Yue Jia and Mark Harman. 2011. An Analysis and Survey of the Development of Mutation Testing.IEEE Trans. Software Eng.37, 5 (2011), 649–678
work page 2011
-
[38]
René Just, Darioush Jalali, Laura Inozemtseva, Michael D. Ernst, Reid Holmes, and Gordon Fraser. 2014. Are mutants a valid substitute for real faults in software testing?. InProceedings of the 22nd ACM SIGSOFT International Symposium on Foundations of Software Engineering, (FSE-22), Hong Kong, China, November 16 - 22, 2014, Shing-Chi Cheung, Alessandro Or...
-
[39]
Choonghwan Lee, Feng Chen, and Grigore Roşu. 2011. Mining parametric specifications. InProceedings of the 33rd International Conference on Software Engineering(Waikiki, Honolulu, HI, USA)(ICSE ’11). Association for Computing Machinery, New York, NY, USA, 591–600. doi:10.1145/1985793.1985874
-
[40]
Gushu Li, Li Zhou, Nengkun Yu, Yufei Ding, Mingsheng Ying, and Yuan Xie. 2020. Projection-based runtime assertions for testing and debugging Quantum programs.Proc. ACM Program. Lang.4, OOPSLA (2020), 150:1–150:29. doi:10. 1145/3428218
work page 2020
-
[41]
Xuezheng Liu, Wei Lin, Aimin Pan, and Zheng Zhang. 2007. WiDS Checker: Combating Bugs in Distributed Systems. InProceedings of the 4th USENIX Symposium on Networked Systems Design and Implementation (NSDI ’07). USENIX Association, Cambridge, MA
work page 2007
-
[42]
Chang Lou, Peng Huang, and Scott Smith. 2020. Understanding, Detecting and Localizing Partial Failures in Large System Software. In17th USENIX Symposium on Networked Systems Design and Implementation (NSDI 20). USENIX Association, Santa Clara, CA, 559–574. https://www.usenix.org/conference/nsdi20/presentation/lou
work page 2020
-
[43]
Chang Lou, Yuzhuo Jing, and Peng Huang. 2022. Demystifying and checking silent semantic violations in large distributed systems. In16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22). 91–107. , Vol. 1, No. 1, Article . Publication date: April 2026. FlyCatcher: Neural Inference of Runtime Checkers from Tests 21
work page 2022
-
[44]
Chang Lou, Yuzhuo Jing, and Peng Huang. 2022. Demystifying and Checking Silent Semantic Violations in Large Distributed Systems. In16th USENIX Symposium on Operating Systems Design and Implementation (OSDI ’22). Carlsbad, CA, 91–107
work page 2022
-
[45]
Chang Lou, Dimas Shidqi Parikesit, Yujin Huang, Zhewen Yang, Senapati Diwangkara, Yuzhuo Jing, Achmad Imam Kistijantoro, Ding Yuan, Suman Nath, and Peng Huang. 2025. Deriving semantic checkers from tests to detect silent failures in production distributed systems. In19th USENIX Symposium on Operating Systems Design and Implementation (OSDI 25). 19–38
work page 2025
-
[46]
Chang Lou, Dimas Shidqi Parikesit, Yujin Huang, Zhewen Yang, Senapati Diwangkara, Yuzhuo Jing, Achmad Imam Kistijantoro, Ding Yuan, Suman Nath, and Peng Huang. 2025. Deriving Semantic Checkers from Tests to Detect Silent Failures in Production Distributed Systems. In19th USENIX Symposium on Operating Systems Design and Implementation, OSDI 2025, Boston, M...
work page 2025
-
[47]
Jie Lu, Chen Liu, Lian Li, Xiaobing Feng, Feng Tan, Jun Yang, and Liang You. 2019. CrashTuner: Detecting Crash- Recovery Bugs in Cloud Systems via Meta-Info Analysis. InProceedings of the 27th ACM Symposium on Operating Systems Principles(Huntsville, Ontario, Canada)(SOSP ’19). Association for Computing Machinery, New York, NY, USA, 114–130. doi:10.1145/3...
-
[48]
Ruiming Lu, Yunchi Lu, Yuxuan Jiang, Guangtao Xue, and Peng Huang. 2025. One-Size-Fits-None: Understanding and Enhancing Slow-Fault Tolerance in Modern Distributed Systems. InProceedings of the 22nd USENIX Symposium on Networked Systems Design and Implementation(Philadelphia, PA, USA)(NSDI ’25). USENIX Association, 359–378. https://www.usenix.org/conferen...
work page 2025
-
[49]
Shan Lu, Soyeon Park, Chongfeng Hu, Xiao Ma, Weihang Jiang, Zhenmin Li, Raluca A. Popa, and Yuanyuan Zhou. 2007. MUVI: Automatically inferring multi-variable access correlations and detecting related semantic and concurrency bugs. InSymposium on Operating Systems Principles (SOSP). ACM, 103–116
work page 2007
-
[50]
Sixiang Ma, Fang Zhou, Michael D. Bond, and Yang Wang. 2021. Finding heterogeneous-unsafe configuration parameters in cloud systems. InProceedings of the Sixteenth European Conference on Computer Systems(Online Event, United Kingdom)(EuroSys ’21). Association for Computing Machinery, New York, NY, USA, 410–425. doi:10.1145/3447786. 3456250
-
[51]
Michael Martin, Benjamin Livshits, and Monica S. Lam. 2005. Finding application errors and security flaws using PQL: a program query language. InProceedings of the 20th Annual ACM SIGPLAN Conference on Object-Oriented Programming, Systems, Languages, and Applications(San Diego, CA, USA)(OOPSLA ’05). Association for Computing Machinery, New York, NY, USA, ...
-
[52]
Gibbons, and Srinivasan Seshan
Suman Nath, Haifeng Yu, Phillip B. Gibbons, and Srinivasan Seshan. 2006. Subtleties in tolerating correlated failures in wide-area storage systems. InProceedings of the 3rd Conference on Networked Systems Design & Implementation - Volume 3(San Jose, CA)(NSDI’06). USENIX Association, USA, 17
work page 2006
-
[53]
Changhua Pei, Zexin Wang, Fengrui Liu, Zeyan Li, Yang Liu, Xiao He, Rong Kang, Tieying Zhang, Jianjun Chen, Jianhui Li, Gaogang Xie, and Dan Pei. 2025. Flow-of-Action: SOP Enhanced LLM-Based Multi-Agent System for Root Cause Analysis. InCompanion Proceedings of the ACM on Web Conference 2025(Sydney NSW, Australia)(WWW ’25). Association for Computing Machi...
-
[54]
Shangshu Qian, Wen Fan, Lin Tan, and Yongle Zhang. 2023. Vicious Cycles in Distributed Software Systems. In2023 38th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 91–103
work page 2023
-
[55]
Andrew Quinn, Jason Flinn, Michael Cafarella, and Baris Kasikci. 2022. Debugging the OmniTable Way. In16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22). USENIX Association, Carlsbad, CA, 357–373. https://www.usenix.org/conference/osdi22/presentation/quinn
work page 2022
-
[56]
Atanas Rountev. 2004. Precise identification of side-effect-free methods in Java. In20th IEEE International Conference on Software Maintenance, 2004. Proceedings.IEEE, 82–91
work page 2004
-
[57]
Devjeet Roy, Xuchao Zhang, Rashi Bhave, Chetan Bansal, Pedro Las-Casas, Rodrigo Fonseca, and Saravan Rajmohan
-
[58]
Exploring llm-based agents for root cause analysis,
Exploring LLM-Based Agents for Root Cause Analysis. InCompanion Proceedings of the 32nd ACM International Conference on the Foundations of Software Engineering(Porto de Galinhas, Brazil)(FSE 2024). Association for Computing Machinery, New York, NY, USA, 208–219. doi:10.1145/3663529.3663841
-
[59]
Alexandru Sălcianu and Martin Rinard. 2005. Purity and side effect analysis for Java programs. InInternational Workshop on Verification, Model Checking, and Abstract Interpretation. Springer, 199–215
work page 2005
-
[60]
Domenico Serra, Giovanni Grano, Fabio Palomba, Filomena Ferrucci, Harald C. Gall, and Alberto Bacchelli. 2019. On the effectiveness of manual and automatic unit test generation: ten years later. InProceedings of the 16th International Conference on Mining Software Repositories, MSR 2019, 26-27 May 2019, Montreal, Canada, Margaret-Anne D. Storey, Bram Adam...
-
[61]
Zhuohang Shen, Mohammed Yaseen, Denini Silva, Kevin Guan, Marcelo d’Amorim Junho Lee and, and Owolabi Legunsen. 2025. A Generic and Efficient Python Runtime Verification System and its Large-scale Evaluation. , Vol. 1, No. 1, Article . Publication date: April 2026. 22 Souza et al
work page 2025
-
[62]
Beatriz Souza and Patrícia D. L. Machado. 2020. A Large Scale Study On the Effectiveness of Manual and Automatic Unit Test Generation. In34th Brazilian Symposium on Software Engineering, SBES 2020, Natal, Brazil, October 19-23, 2020, Everton Cavalcante, Francisco Dantas, and Thaís Batista (Eds.). ACM, 253–262. doi:10.1145/3422392.3422407
-
[63]
Xudong Sun, Runxiang Cheng, Jianyan Chen, Elaine Ang, Owolabi Legunsen, and Tianyin Xu. 2020. Testing Configu- ration Changes in Context to Prevent Production Failures. In14th USENIX Symposium on Operating Systems Design and Implementation (OSDI ’20). USENIX Association, 735–751. https://www.usenix.org/conference/osdi20/presentation/sun
work page 2020
-
[64]
Shaobu Wang, Guangyan Zhang, Junyu Wei, Yang Wang, Jiesheng Wu, and Qingchao Luo. 2023. Understanding Silent Data Corruptions in a Large Production CPU Population. InProceedings of the 29th Symposium on Operating Systems Principles(<conf-loc>, <city>Koblenz</city>, <country>Germany</country>, </conf-loc>)(SOSP ’23). Association for Computing Machinery, Ne...
-
[65]
Yifan Wang and Kenneth P. Birman. 2025. Diagnosing and Resolving Cloud Platform Instability with Multi-modal RAG LLMs. InProceedings of the 5th Workshop on Machine Learning and Systems(World Trade Center, Rotterdam, Netherlands) (EuroMLSys ’25). Association for Computing Machinery, New York, NY, USA, 139–147. doi:10.1145/3721146.3721958
-
[66]
Zefan Wang, Zichuan Liu, Yingying Zhang, Aoxiao Zhong, Jihong Wang, Fengbin Yin, Lunting Fan, Lingfei Wu, and Qingsong Wen. 2024. RCAgent: Cloud Root Cause Analysis by Autonomous Agents with Tool-Augmented Large Language Models. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management(Boise, ID, USA)(CIKM ’24). Associ...
-
[67]
Tianyin Xu, Xinxin Jin, Peng Huang, Yuanyuan Zhou, Shan Lu, Long Jin, and Shankar Pasupathy. 2016. Early Detection of Configuration Errors to Reduce Failure Damage. In12th USENIX Symposium on Operating Systems Design and Implementation (OSDI ’16). USENIX Association, Savannah, GA, 619–634. https://www.usenix.org/conference/osdi16/ technical-sessions/prese...
work page 2016
-
[68]
Wei Xu, Ling Huang, Armando Fox, David Patterson, and Michael I. Jordan. 2009. Detecting large-scale system problems by mining console logs. InProceedings of the ACM SIGOPS 22nd Symposium on Operating Systems Principles (Big Sky, Montana, USA)(SOSP ’09). Association for Computing Machinery, New York, NY, USA, 117–132. doi:10.1145/ 1629575.1629587
-
[69]
Chenyuan Yang, Zijie Zhao, Zichen Xie, Haoyu Li, and Lingming Zhang. 2025. KNighter: Transforming Static Analysis with LLM-Synthesized Checkers. InProceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles (Seoul, Republic of Korea)(SOSP ’25). Association for Computing Machinery, New York, NY, USA. doi:10.1145/3731569. 3764827
-
[70]
Andrew Yoo, Yuanli Wang, Ritesh Sinha, Shuai Mu, and Tianyin Xu. 2021. Fail-slow fault tolerance needs programming support. InProceedings of the Workshop on Hot Topics in Operating Systems(Ann Arbor, Michigan)(HotOS ’21). Association for Computing Machinery, New York, NY, USA, 228–235. doi:10.1145/3458336.3465299
-
[71]
Ennan Zhai, Ang Chen, Ruzica Piskac, Mahesh Balakrishnan, Bingchuan Tian, Bo Song, and Haoliang Zhang. 2020. Check before You Change: Preventing Correlated Failures in Service Updates. In17th USENIX Symposium on Networked Systems Design and Implementation (NSDI 20). USENIX Association, Santa Clara, CA, 575–589. https://www.usenix. org/conference/nsdi20/pr...
work page 2020
-
[72]
Yongle Zhang, Junwen Yang, Zhuqi Jin, Utsav Sethi, Kirk Rodrigues, Shan Lu, and Ding Yuan. 2021. Understanding and Detecting Software Upgrade Failures in Distributed Systems. InProceedings of the ACM SIGOPS 28th Symposium on Operating Systems Principles(Virtual Event, Germany)(SOSP ’21). Association for Computing Machinery, New York, NY, USA, 116–131. doi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.