Recognition: unknown
RealBench: A Repo-Level Code Generation Benchmark Aligned with Real-World Software Development Practices
Pith reviewed 2026-05-08 11:21 UTC · model grok-4.3
The pith
RealBench pairs natural language requirements with UML diagrams to test LLMs on generating full code repositories the way industry teams receive specs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
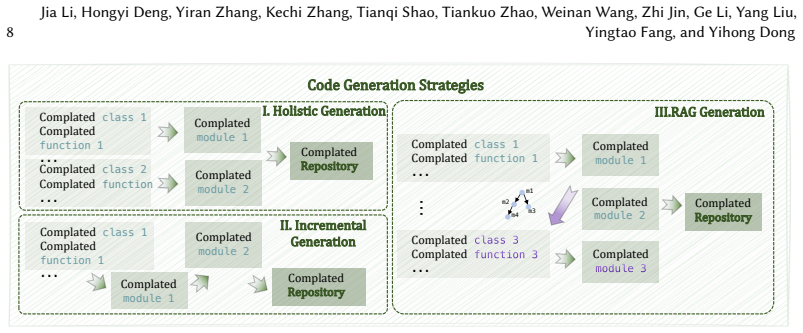
RealBench is a repository-level code generation benchmark in which each example supplies natural language requirements together with UML diagrams as the system design. Testing reveals that LLMs achieve markedly lower performance on these tasks than on simpler benchmarks, accompanied by substantial gaps across different models. The models readily identify and instantiate the modules defined in the UML diagrams but produce code that often contains grammar and logic errors. Generating the entire repository in a single pass proves the strongest strategy for smaller repositories, whereas a module-by-module strategy yields better results for larger and more complex repositories.
What carries the argument
RealBench benchmark, in which each task pairs natural language requirements with UML diagrams to represent system design and thereby simulate real-world specification delivery.
If this is right
- LLMs exhibit substantially lower performance and wide gaps between models on repository-scale code generation.
- LLMs reliably detect modules from UML diagrams but produce code containing frequent grammar and logic errors.
- Generating the full repository in one step is the best approach for smaller repositories.
- Generating module by module is the better strategy for complex repositories.
Where Pith is reading between the lines
- Teams could adopt RealBench scores to choose which LLM to deploy for projects of different sizes.
- LLM training focused on structured inputs such as UML could narrow the observed quality gap.
- Similar benchmarks that incorporate other design documents beyond UML could test whether the size-dependent strategy pattern holds more broadly.
Load-bearing premise
The examples built from natural language requirements plus UML diagrams accurately reflect how developers typically receive specifications in enterprise applications and team development.
What would settle it
A direct comparison that measures whether higher RealBench scores for a given LLM predict larger measured productivity gains when that LLM assists developers on live enterprise projects would falsify the alignment claim if no correlation appears.
Figures





read the original abstract
Writing code requires significant time and effort in software development. To automate this process, researchers have made substantial progress using Large Language Models (LLMs) for code generation. Many benchmarks like HumanEval and EvoCodeBench have been created to evaluate LLMs by requiring them to generate code from natural language requirements. However, in enterprise applications and team development, developers typically write code based on structured designs or specifications rather than raw natural language descriptions. This gap between existing benchmarks and real industry development practices means that current benchmark scores may not accurately reflect how much code generation can help automate software development tasks. To address this gap, we propose RealBench, a repository-level code generation benchmark aligned with real-world industry software development practices. Each example includes both natural language requirements and UML diagrams as system design, matching how developers typically receive specifications. Based on the constructed benchmarks, we conduct a systematic evaluation of advanced LLMs' code generation capabilities when provided with structured system designs. The experimental results reveal key insights in current LLMs' capabilities for repo-level code generation aligned with real-world software development practices. First, we notice that regarding repo-level code generation, LLMs show much worse performance and there are significant performance gaps among LLMs. Second, LLMs are good at finding and creating modules defined in UML diagrams, but the quality of generated modules is often poor due to grammar and logic errors. Third, generating the entire repository at once is the best generation strategy on smaller repositories, while generating a complex repository with the module-by-module strategy works better compared to other strategies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces RealBench, a repository-level code generation benchmark that augments natural language requirements with UML diagrams to align more closely with how developers receive specifications in industry settings. It evaluates several advanced LLMs on tasks involving generating code for entire repositories or modules, reporting that LLMs perform poorly overall with large gaps between models, excel at identifying UML-defined modules but generate low-quality code with errors, and that whole-repo generation is preferable for small repos while modular is better for complex ones.
Significance. Should the benchmark's construction methodology prove representative of real enterprise specification practices, these findings would offer valuable guidance on the current limitations of LLMs for practical software automation and suggest context-dependent prompting strategies. The work builds on prior benchmarks by emphasizing structured designs, potentially improving the predictive power of evaluations for real-world impact.
major comments (2)
- [Abstract and Benchmark Construction section] The central motivation and interpretation of results rest on the claim that each RealBench example 'includes both natural language requirements and UML diagrams as system design, matching how developers typically receive specifications' (abstract). However, no section describes the sourcing or authoring of the UML diagrams, provides expert validation, developer surveys, or comparisons to real artifacts such as Jira tickets, Confluence pages, or UML present in open-source repositories. Without this, the external validity of the reported performance gaps, module quality issues, and strategy preferences cannot be established.
- [Experimental Results section] The experimental results section summarizes high-level findings (e.g., 'much worse performance', 'significant performance gaps', 'poor quality due to grammar and logic errors') but the abstract and available description omit key details including dataset size, number of examples per repository, exact LLMs and metrics used, error rate breakdowns, or statistical tests. This makes it difficult to assess the strength of the three directional claims.
minor comments (2)
- [Results discussion] Clarify the precise definition of 'grammar and logic errors' in generated modules and how they were measured (e.g., via compilation checks, test suites, or manual review).
- [Evaluation] Add a table or figure summarizing per-model performance metrics to support the 'significant gaps' claim.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. The comments highlight important areas for improving the manuscript's clarity on benchmark construction and experimental reporting. We address each major comment below and will incorporate revisions to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract and Benchmark Construction section] The central motivation and interpretation of results rest on the claim that each RealBench example 'includes both natural language requirements and UML diagrams as system design, matching how developers typically receive specifications' (abstract). However, no section describes the sourcing or authoring of the UML diagrams, provides expert validation, developer surveys, or comparisons to real artifacts such as Jira tickets, Confluence pages, or UML present in open-source repositories. Without this, the external validity of the reported performance gaps, module quality issues, and strategy preferences cannot be established.
Authors: We agree that a more explicit description of the UML diagram construction process is needed to support the alignment claim. In the revised manuscript, we will add a dedicated subsection under 'Benchmark Construction' that details the authoring process: the UML diagrams were created manually by the authors using standard UML notation (class, sequence, and component diagrams) to represent typical system architectures drawn from publicly documented open-source repository structures and general industry software design guidelines. We will also acknowledge the absence of formal developer surveys or direct artifact comparisons (due to the proprietary nature of many enterprise specifications) and discuss this as a limitation, while citing supporting literature on how structured designs are used in practice. This revision will clarify the methodology without overstating external validity. revision: yes
-
Referee: [Experimental Results section] The experimental results section summarizes high-level findings (e.g., 'much worse performance', 'significant performance gaps', 'poor quality due to grammar and logic errors') but the abstract and available description omit key details including dataset size, number of examples per repository, exact LLMs and metrics used, error rate breakdowns, or statistical tests. This makes it difficult to assess the strength of the three directional claims.
Authors: We appreciate the referee's point on reporting completeness. While the full Experimental Setup and Results sections contain the underlying data, we agree the high-level summaries and abstract could be more precise. In the revision, we will expand the Experimental Results section to explicitly report: the total number of repositories and examples in RealBench, the exact LLMs evaluated along with prompting configurations, the full set of metrics (including any code quality and error analysis measures), quantitative error rate breakdowns by type (grammar, logic, etc.), and any statistical tests used to support the directional claims. The abstract will be updated to reference these elements at a high level. These changes will make the evidence for the three findings more transparent and verifiable. revision: yes
Circularity Check
Empirical benchmark proposal with no derivation chain or circular reductions
full rationale
The paper proposes RealBench as a new repo-level benchmark that augments natural-language requirements with UML diagrams, then reports direct experimental observations of LLM performance on the resulting examples. No equations, fitted parameters, predictions, or mathematical derivations appear in the abstract or described structure. Claims about performance gaps, module-finding ability, and generation strategies rest on observed outputs rather than any self-referential definition or self-citation load-bearing step. The asserted real-world alignment is an input premise, not a derived result that loops back to the benchmark construction itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Developers in enterprise and team settings typically receive specifications as structured designs such as UML diagrams rather than raw natural language descriptions alone.
Reference graph
Works this paper leans on
-
[1]
GPT-4o.https://openai.com/index/hello-gpt-4o/(2024)
2024. GPT-4o.https://openai.com/index/hello-gpt-4o/(2024)
2024
-
[2]
Qwen2.5-Coder-7B.https://huggingface.co/Qwen/Qwen2.5-Coder-7B-Instruct(2024)
2024. Qwen2.5-Coder-7B.https://huggingface.co/Qwen/Qwen2.5-Coder-7B-Instruct(2024)
2024
-
[3]
Claude Sonnet 4.https://www.anthropic.com/claude/sonnet(2025)
2025. Claude Sonnet 4.https://www.anthropic.com/claude/sonnet(2025)
2025
-
[4]
Gemini-2.5-flash.https://ai.google.dev/gemini-api/docs/models?hl=zh-cn#gemini-2.5-flash(2025)
2025. Gemini-2.5-flash.https://ai.google.dev/gemini-api/docs/models?hl=zh-cn#gemini-2.5-flash(2025)
2025
-
[5]
Qwen3-235B-A22B.https://huggingface.co/Qwen/Qwen3-235B-A22B(2025)
2025. Qwen3-235B-A22B.https://huggingface.co/Qwen/Qwen3-235B-A22B(2025)
2025
- [6]
-
[7]
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. 2021. Program synthesis with large language models.arXiv preprint arXiv:2108.07732 (2021)
work page internal anchor Pith review arXiv 2021
-
[8]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al
-
[9]
Qwen technical report.arXiv preprint arXiv:2309.16609(2023)
work page internal anchor Pith review arXiv 2023
-
[10]
2025.TIOBE Index
Tiobe Software BV. 2025.TIOBE Index. https://www.tiobe.com/tiobe-index/
2025
-
[11]
Jialun Cao, Zhiyong Chen, Jiarong Wu, Shing-Chi Cheung, and Chang Xu. 2024. Javabench: A benchmark of object- oriented code generation for evaluating large language models. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering. 870–882
2024
-
[12]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. 2021. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374(2021)
work page internal anchor Pith review arXiv 2021
-
[13]
Wei Cheng, Yuhan Wu, and Wei Hu. 2024. Dataflow-Guided Retrieval Augmentation for Repository-Level Code Completion. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 7957–7977
2024
-
[14]
Yangruibo Ding, Zijian Wang, Wasi Ahmad, Hantian Ding, Ming Tan, Nihal Jain, Murali Krishna Ramanathan, Ramesh Nallapati, Parminder Bhatia, Dan Roth, et al. 2023. Crosscodeeval: A diverse and multilingual benchmark for cross-file , Vol. 1, No. 1, Article . Publication date: April 2026. 20 Jia Li, Hongyi Deng, Yiran Zhang, Kechi Zhang, Tianqi Shao, Tiankuo...
2023
- [15]
-
[16]
Daya Guo, Canwen Xu, Nan Duan, Jian Yin, and Julian McAuley. 2023. Longcoder: A long-range pre-trained language model for code completion. InInternational Conference on Machine Learning. PMLR, 12098–12107
2023
-
[17]
Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Yu Wu, YK Li, et al. 2024. DeepSeek-Coder: When the Large Language Model Meets Programming–The Rise of Code Intelligence. arXiv preprint arXiv:2401.14196(2024)
work page internal anchor Pith review arXiv 2024
-
[18]
Dan Hendrycks, Steven Basart, Saurav Kadavath, Mantas Mazeika, Akul Arora, Ethan Guo, Collin Burns, Samir Puranik, Horace He, Dawn Song, et al. 2021. Measuring coding challenge competence with apps.arXiv preprint arXiv:2105.09938 (2021)
work page internal anchor Pith review arXiv 2021
-
[19]
Rasha Ahmad Husein, Hala Aburajouh, and Cagatay Catal. 2025. Large language models for code completion: A systematic literature review.Computer Standards & Interfaces92 (2025), 103917
2025
- [20]
-
[21]
Maliheh Izadi, Roberta Gismondi, and Georgios Gousios. 2022. Codefill: Multi-token code completion by jointly learning from structure and naming sequences. InProceedings of the 44th international conference on software engineering. 401– 412
2022
-
[22]
Maliheh Izadi, Jonathan Katzy, Tim Van Dam, Marc Otten, Razvan Mihai Popescu, and Arie Van Deursen. 2024. Language models for code completion: A practical evaluation. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering. 1–13
2024
-
[23]
Juyong Jiang, Fan Wang, Jiasi Shen, Sungju Kim, and Sunghun Kim. 2024. A survey on large language models for code generation.arXiv preprint arXiv:2406.00515(2024)
work page internal anchor Pith review arXiv 2024
- [24]
-
[25]
Yuhang Lai, Chengxi Li, Yiming Wang, Tianyi Zhang, Ruiqi Zhong, Luke Zettlemoyer, Wen-tau Yih, Daniel Fried, Sida Wang, and Tao Yu. 2023. DS-1000: A natural and reliable benchmark for data science code generation. InInternational Conference on Machine Learning. PMLR, 18319–18345
2023
-
[26]
2012.Applying UML and patterns: an introduction to object oriented analysis and design and interative development
Craig Larman. 2012.Applying UML and patterns: an introduction to object oriented analysis and design and interative development. Pearson Education India
2012
-
[27]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems33 (2020), 9459–9474
2020
-
[28]
Jia Li, Xuyuan Guo, Lei Li, Kechi Zhang, Ge Li, Zhengwei Tao, Fang Liu, Chongyang Tao, Yuqi Zhu, and Zhi Jin
- [29]
- [30]
-
[31]
Jia Li, Ge Li, Yunfei Zhao, Yongmin Li, Zhi Jin, Hao Zhu, Huanyu Liu, Kaibo Liu, Lecheng Wang, Zheng Fang, et al
- [32]
-
[33]
Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, et al. 2022. Competition-level code generation with alphacode.Science378, 6624 (2022), 1092–1097
2022
-
[34]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. 2024. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437(2024)
work page internal anchor Pith review arXiv 2024
- [35]
-
[36]
Agile Manifesto. 2001. Manifesto for agile software development
2001
-
[37]
Phuong T Nguyen, Juri Di Rocco, Davide Di Ruscio, Lina Ochoa, Thomas Degueule, and Massimiliano Di Penta. 2019. Focus: A recommender system for mining api function calls and usage patterns. In2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE). IEEE, 1050–1060
2019
-
[38]
Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, and Caiming Xiong. 2022. Codegen: An open large language model for code with multi-turn program synthesis.arXiv preprint arXiv:2203.13474 (2022). , Vol. 1, No. 1, Article . Publication date: April 2026. RealBench: A Repo-Level Code Generation Benchmark Aligned with R...
work page internal anchor Pith review arXiv 2022
-
[39]
2017.Unified Modeling Language (UML) Version 2.5.1
Object Management Group. 2017.Unified Modeling Language (UML) Version 2.5.1. Specification. Object Management Group. https://www.omg.org/spec/UML/2.5.1/
2017
-
[40]
Pressman and B.R
R.S. Pressman and B.R. Maxim. 2019.Software Engineering: A Practitioner’s Approach. McGraw-Hill Education
2019
-
[41]
Winston W Royce. 1987. Managing the development of large software systems: concepts and techniques. InProceedings of the 9th international conference on Software Engineering. 328–338
1987
-
[42]
Aarohi Srivastava, Abhinav Rastogi, Abhishek Rao, Abu Awal Shoeb, Abubakar Abid, Adam Fisch, Adam R Brown, Adam Santoro, Aditya Gupta, Adri Garriga-Alonso, et al. 2023. Beyond the imitation game: Quantifying and extrapolating the capabilities of language models.Transactions on machine learning research(2023)
2023
- [43]
- [44]
- [45]
- [46]
-
[47]
Pengcheng Yin, Bowen Deng, Edgar Chen, Bogdan Vasilescu, and Graham Neubig. 2018. Learning to mine aligned code and natural language pairs from stack overflow. InProceedings of the 15th international conference on mining software repositories. 476–486
2018
-
[48]
Hao Yu, Bo Shen, Dezhi Ran, Jiaxin Zhang, Qi Zhang, Yuchi Ma, Guangtai Liang, Ying Li, Qianxiang Wang, and Tao Xie. 2024. Codereval: A benchmark of pragmatic code generation with generative pre-trained models. InProceedings of the 46th IEEE/ACM International Conference on Software Engineering. 1–12
2024
-
[49]
Daoguang Zan, Bei Chen, Dejian Yang, Zeqi Lin, Minsu Kim, Bei Guan, Yongji Wang, Weizhu Chen, and Jian-Guang Lou
- [50]
- [51]
- [52]
- [53]
-
[54]
Qinkai Zheng, Xiao Xia, Xu Zou, Yuxiao Dong, Shan Wang, Yufei Xue, Lei Shen, Zihan Wang, Andi Wang, Yang Li, et al. 2023. Codegeex: A pre-trained model for code generation with multilingual benchmarking on humaneval-x. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 5673–5684. , Vol. 1, No. 1, Article . Publication...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.