UAV Trajectory and Bandwidth Allocation for Efficient Data Collection in Low-Altitude Intelligent IoT: A Hierarchical DRL Approach
Pith reviewed 2026-05-25 06:54 UTC · model grok-4.3
The pith
A hierarchical deep reinforcement learning method optimizes UAV trajectories and bandwidth allocation to maximize IoT data collection under interference and dynamics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
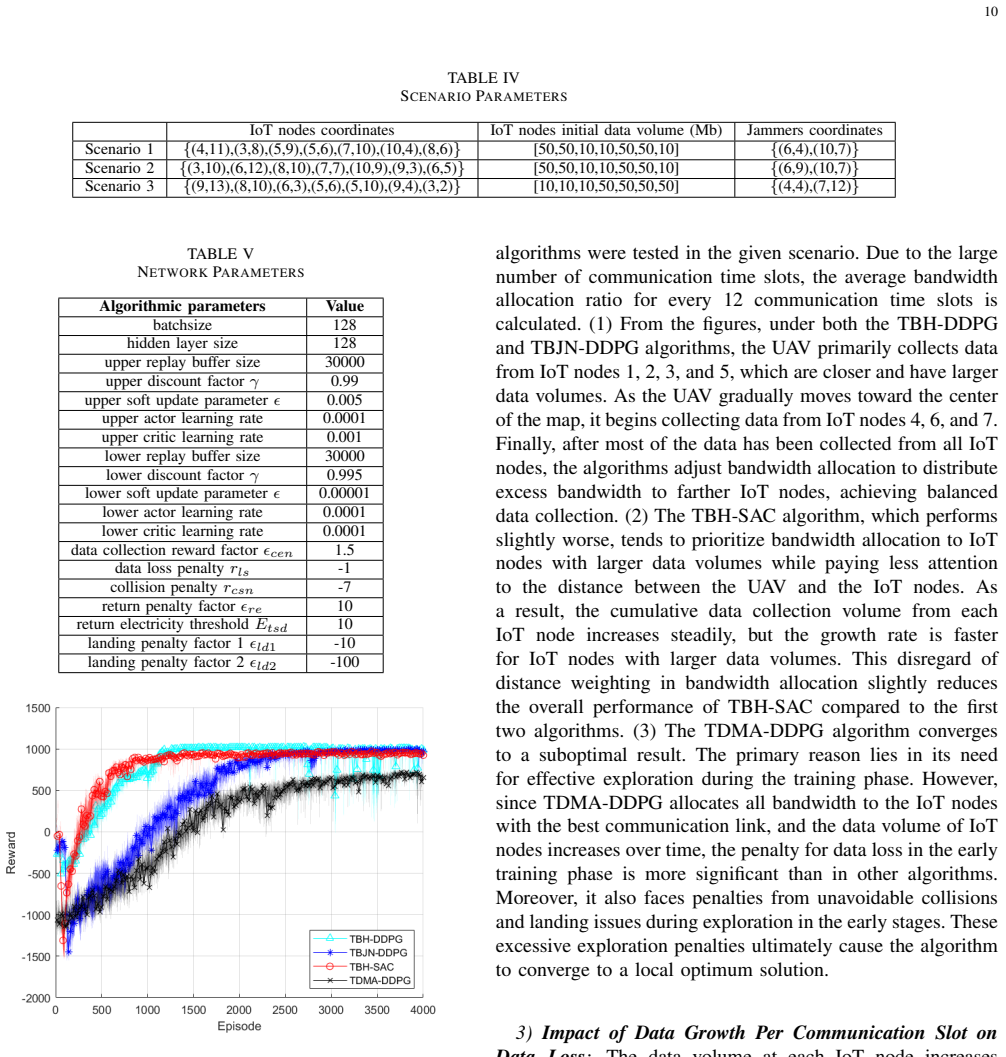
The central claim is that decomposing the joint trajectory-and-bandwidth problem into two DRL levels, with the upper level selecting coarse flight paths and the lower level selecting fine-grained bandwidth shares, produces an effective solution via the TBH-DDPG algorithm; simulations of the resulting policy show a 44.44 percent improvement in convergence speed and a 58.05 percent reduction in computational cost compared with a flat DDPG baseline under the modeled interference, dynamic data, and obstacle conditions.
What carries the argument
The TBH-DDPG algorithm, which runs an upper-level DDPG policy for trajectory at coarse temporal granularity and a lower-level DDPG policy for bandwidth allocation at fine granularity.
If this is right
- The hierarchical split enables the UAV to respond to fast-changing bandwidth needs without recomputing entire trajectories at every time step.
- Data collection volume can be increased while still respecting interference limits and obstacle avoidance.
- Onboard computation load drops enough that the same hardware can support longer missions or additional sensors.
- The method scales to scenarios with many IoT nodes because the lower level operates locally on bandwidth while the upper level plans global movement.
Where Pith is reading between the lines
- The same coarse-to-fine split could be applied to other UAV tasks such as target tracking or delivery routing where planning and actuation occur at mismatched time scales.
- If the computational savings hold in hardware, the approach could extend mission duration by lowering energy spent on repeated policy evaluations.
- Real-world validation would need to check whether wireless channel estimation errors erode the reported gains when the lower-level policy must act on noisy observations.
Load-bearing premise
The simulation environment, including its interference model, data-volume dynamics, and obstacle types, accurately represents the conditions under which the hierarchical split preserves solution quality while delivering the reported speed and cost gains.
What would settle it
Execute both the proposed TBH-DDPG and the non-hierarchical DDPG baseline on an identical scenario whose interference, data arrivals, and obstacle geometry are taken from field measurements rather than synthetic models, then measure whether the 44 percent convergence and 58 percent cost advantages remain.
Figures








read the original abstract
The low-altitude Internet of Things (IoT), supported by unmanned aerial vehicles (UAVs), provides ground sensing networks with advanced real-time monitoring and data collection. To maximize data collection volume from distributed IoT nodes, AI-powered data collection technology plays a critical role in enabling intelligent decision-making. Among them, deep reinforcement learning (DRL) has gained particular attention. However, existing DRL-based work on UAV-assisted IoT data collection rarely addresses challenges such as interference and dynamic data volume, while also suffering from high computational demands and slow convergence. To address these challenges, a hierarchical DRL (HDRL) is designed to optimize UAV trajectories and bandwidth allocation to maximize data collection volume. Firstly, the proposed scenario incorporates interference, dynamic data volume of IoT nodes, and multiple types of obstacles. The entire task is hierarchically structured: the upper-level makes flight trajectory decisions at a coarse temporal granularity, while the lower-level makes bandwidth allocation decisions at a finer temporal granularity. Secondly, a trajectory and bandwidth allocation optimization algorithm based on hierarchical deep deterministic policy gradients (TBH-DDPG) is proposed to solve the problem. Finally, simulation results demonstrate that the proposed algorithm improves convergence speed by 44.44%, and reduces computational cost by 58.05%, compared to non-hierarchical algorithm.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a hierarchical deep reinforcement learning (HDRL) framework called TBH-DDPG for joint UAV trajectory planning and bandwidth allocation in low-altitude IoT data collection. The scenario includes interference, dynamic IoT data volumes, and multiple obstacle types. Trajectory decisions are made at coarse temporal granularity in the upper level while bandwidth decisions occur at finer granularity in the lower level. Simulation results claim that TBH-DDPG achieves 44.44% faster convergence and 58.05% lower computational cost relative to a non-hierarchical algorithm.
Significance. If the performance claims can be reproduced with matched baselines, the hierarchical decomposition offers a practical route to scaling DRL to high-dimensional joint action spaces in UAV-assisted IoT without sacrificing data-collection volume. The approach directly targets the sample-efficiency and compute bottlenecks that currently limit deployment of flat DDPG-style methods in dynamic wireless environments.
major comments (1)
- [Simulation Results] Simulation Results section: The central empirical claims (44.44% faster convergence, 58.05% lower computational cost) are stated without any description of the non-hierarchical baseline algorithm, including its actor-critic network architectures, total gradient steps, exploration schedule, or number of independent trials with reported variance. Because the joint trajectory-plus-bandwidth action space is high-dimensional, any mismatch in network size or training budget between TBH-DDPG and the flat comparator would produce exactly these speed-ups without demonstrating that the hierarchy itself preserves solution quality.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the simulation results. We agree that the non-hierarchical baseline requires fuller documentation to support the reported performance gains and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Simulation Results] Simulation Results section: The central empirical claims (44.44% faster convergence, 58.05% lower computational cost) are stated without any description of the non-hierarchical baseline algorithm, including its actor-critic network architectures, total gradient steps, exploration schedule, or number of independent trials with reported variance. Because the joint trajectory-plus-bandwidth action space is high-dimensional, any mismatch in network size or training budget between TBH-DDPG and the flat comparator would produce exactly these speed-ups without demonstrating that the hierarchy itself preserves solution quality.
Authors: We agree that the current manuscript provides insufficient detail on the non-hierarchical baseline. In the revised version we will add a dedicated subsection describing the baseline as a flat DDPG implementation that receives the concatenated trajectory-and-bandwidth action vector at every time step. We will specify the actor and critic network architectures (layer counts and widths), the total number of gradient steps, the exploration noise schedule, the number of independent random seeds (with standard deviation reported for all metrics), and the precise training budget allocated to each method. These additions will allow direct verification that the observed speed-up and cost reduction arise from the hierarchical decomposition rather than from unequal computational resources. revision: yes
Circularity Check
No circularity: empirical simulation claims rest on external benchmarks, not self-referential definitions or fitted inputs.
full rationale
The paper's central claims are simulation outcomes (44.44% faster convergence, 58.05% lower cost for TBH-DDPG vs. non-hierarchical baseline). No mathematical derivation chain, equations, or first-principles results are presented that reduce to inputs by construction. The hierarchical structure and algorithm are proposed as design choices, with performance evaluated externally via simulation; the baseline comparison, while potentially underspecified, does not constitute a self-definitional or fitted-input reduction. No self-citation load-bearing steps or ansatz smuggling appear in the abstract or described content. This is a standard empirical DRL paper with independent simulation evidence.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The UAV-IoT data collection task can be formulated as a Markov decision process amenable to DRL
- ad hoc to paper Decomposing trajectory decisions at coarse granularity and bandwidth decisions at fine granularity yields both faster learning and lower compute without sacrificing data-collection performance
Reference graph
Works this paper leans on
-
[1]
Internet of Low-Altitude UA Vs (IoLoUA): a methodical modeling on integration of Internet of “Things
A. Srivastava and J. Prakash, “Internet of Low-Altitude UA Vs (IoLoUA): a methodical modeling on integration of Internet of “Things” with “UA V” possibilities and tests,”Artificial Intelligence Review, vol. 56, no. 3, pp. 2279–2324, 2023
work page 2023
-
[2]
UA V meets integrated sensing and communication: Challenges and future directions,
J. Mu, R. Zhang, Y . Cui, N. Gao, and X. Jing, “UA V meets integrated sensing and communication: Challenges and future directions,”IEEE Communications Magazine, vol. 61, no. 5, pp. 62–67, 2023
work page 2023
-
[3]
UA V-assisted data collection for Internet of Things: A survey,
Z. Wei, M. Zhu, N. Zhang, L. Wang, Y . Zou, Z. Meng, H. Wu, and Z. Feng, “UA V-assisted data collection for Internet of Things: A survey,” IEEE Internet of Things Journal, vol. 9, no. 17, pp. 15 460–15 483, 2022
work page 2022
-
[4]
A review of cognitive UA Vs: AI-driven situation awareness for enhanced operations,
M. Dehghan and E. Khosravian, “A review of cognitive UA Vs: AI-driven situation awareness for enhanced operations,”AI and Tech in Behavioral and Social Sciences, vol. 2, no. 4, pp. 54–65, 2024
work page 2024
-
[5]
E. V . Butil ˘a and R. G. Boboc, “Urban traffic monitoring and analysis using unmanned aerial vehicles (UA Vs): A systematic literature review,” Remote Sensing, vol. 14, no. 3, p. 620, 2022
work page 2022
-
[6]
Unmanned aerial vehicles for air pollution monitoring: A survey,
N. H. Motlagh, P. Kortoc ¸i, X. Su, L. Lov´en, H. K. Hoel, S. B. Haugsvær, V . Srivastava, C. F. Gulbrandsen, P. Nurmi, and S. Tarkoma, “Unmanned aerial vehicles for air pollution monitoring: A survey,”IEEE Internet of Things Journal, vol. 10, no. 24, pp. 21 687–21 704, 2023
work page 2023
-
[7]
K. P. Valavanis and G. J. Vachtsevanos,Handbook of unmanned aerial vehicles. Springer Publishing Company, Incorporated, 2014
work page 2014
-
[8]
Mobile unmanned aerial vehicles (UA Vs) for energy-efficient Internet of Things commu- nications,
M. Mozaffari, W. Saad, M. Bennis, and M. Debbah, “Mobile unmanned aerial vehicles (UA Vs) for energy-efficient Internet of Things commu- nications,”IEEE Transactions on Wireless Communications, vol. 16, no. 11, pp. 7574–7589, 2017
work page 2017
-
[9]
Z. Lu, Z. Jia, Q. Wu, and Z. Han, “Joint trajectory planning and communication design for multiple UA Vs in intelligent collaborative air-ground communication systems,”IEEE Internet of Things Journal, 2024
work page 2024
-
[10]
Y . Wang, Z. Gao, J. Zhang, X. Cao, D. Zheng, Y . Gao, D. W. K. Ng, and M. Di Renzo, “Trajectory design for UA V-based Internet of Things data collection: A deep reinforcement learning approach,”IEEE Internet of Things Journal, vol. 9, no. 5, pp. 3899–3912, 2021
work page 2021
-
[11]
C. Mingcheng, F. Shoucheng, X. GuoQiang, and H. Ke, “Deep rein- forcement learning-based UA V path planning algorithm in agricultural time-constrained data collection.”Advances in Electrical & Computer Engineering, vol. 23, no. 2, 2023
work page 2023
-
[12]
S. Fu, Y . Tang, Y . Wu, N. Zhang, H. Gu, C. Chen, and M. Liu, “Energy-efficient UA V-enabled data collection via wireless charging: A reinforcement learning approach,”IEEE Internet of Things Journal, vol. 8, no. 12, pp. 10 209–10 219, 2021
work page 2021
-
[13]
Energy-efficient data collection in UA V enabled wireless sensor network,
C. Zhan, Y . Zeng, and R. Zhang, “Energy-efficient data collection in UA V enabled wireless sensor network,”IEEE Wireless Communications Letters, vol. 7, no. 3, pp. 328–331, 2017
work page 2017
-
[14]
UA V trajectory planning for data collection from time-constrained IoT devices,
M. Samir, S. Sharafeddine, C. M. Assi, T. M. Nguyen, and A. Ghrayeb, “UA V trajectory planning for data collection from time-constrained IoT devices,”IEEE Transactions on Wireless Communications, vol. 19, no. 1, pp. 34–46, 2019
work page 2019
-
[15]
AoI-minimal trajectory planning and data collection in UA V-assisted wireless powered IoT networks,
H. Hu, K. Xiong, G. Qu, Q. Ni, P. Fan, and K. B. Letaief, “AoI-minimal trajectory planning and data collection in UA V-assisted wireless powered IoT networks,”IEEE Internet of Things Journal, vol. 8, no. 2, pp. 1211– 1223, 2020
work page 2020
-
[16]
Y . Pan, Y . Yang, and W. Li, “A deep learning trained by genetic algorithm to improve the efficiency of path planning for data collection with multi-UA V,”IEEE Access, vol. 9, pp. 7994–8005, 2021
work page 2021
-
[17]
Playing Atari with Deep Reinforcement Learning
V . Mnih, “Playing atari with deep reinforcement learning,”arXiv preprint arXiv:1312.5602, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[18]
R. S. Sutton and A. G. Barto,Reinforcement learning: An introduction. MIT press, 2018
work page 2018
-
[19]
UA V path planning for wireless data harvesting: A deep reinforcement learning approach,
H. Bayerlein, M. Theile, M. Caccamo, and D. Gesbert, “UA V path planning for wireless data harvesting: A deep reinforcement learning approach,” inGLOBECOM 2020-2020 IEEE Global Communications Conference. IEEE, 2020, pp. 1–6
work page 2020
-
[20]
Distributed multi-UA V trajectory planning for downlink transmission: A GNN-enhanced DRL approach,
Y . Du, N. Qi, X. Li, M. Xiao, A.-A. A. Boulogeorgos, T. A. Tsiftsis, and Q. Wu, “Distributed multi-UA V trajectory planning for downlink transmission: A GNN-enhanced DRL approach,”IEEE Wireless Com- munications Letters, 2024
work page 2024
-
[21]
S. Wang, N. Qi, H. Jiang, M. Xiao, H. Liu, L. Jia, and D. Zhao, “Trajectory planning for UA V-assisted data collection in IoT network: A double deep Q network approach,”Electronics, vol. 13, no. 8, p. 1592, 2024
work page 2024
-
[22]
R. Ding, F. Gao, and X. S. Shen, “3D UA V trajectory design and frequency band allocation for energy-efficient and fair communication: A deep reinforcement learning approach,”IEEE Transactions on Wireless Communications, vol. 19, no. 12, pp. 7796–7809, 2020
work page 2020
-
[23]
Intelligent joint trajectory design and resource allocation in UA V-based data harvesting system,
S. Luo, J. Liu, S. Chen, J. Chen, and J. Guo, “Intelligent joint trajectory design and resource allocation in UA V-based data harvesting system,” in2020 IEEE 16th International Conference on Control & Automation (ICCA). IEEE, 2020, pp. 1378–1383
work page 2020
-
[24]
B. Zhu, E. Bedeer, H. H. Nguyen, R. Barton, and J. Henry, “UA V trajectory planning in wireless sensor networks for energy consumption minimization by deep reinforcement learning,”IEEE Transactions on Vehicular Technology, vol. 70, no. 9, pp. 9540–9554, 2021
work page 2021
-
[25]
Energy-efficient distributed mobile crowd sensing: A deep learning approach,
C. H. Liu, Z. Chen, and Y . Zhan, “Energy-efficient distributed mobile crowd sensing: A deep learning approach,”IEEE Journal on Selected Areas in Communications, vol. 37, no. 6, pp. 1262–1276, 2019
work page 2019
-
[26]
M. Sun, X. Xu, X. Qin, and P. Zhang, “AoI-energy-aware UA V- assisted data collection for IoT networks: A deep reinforcement learning method,”IEEE Internet of Things Journal, vol. 8, no. 24, pp. 17 275– 17 289, 2021
work page 2021
-
[27]
Deep reinforcement learning for fresh data collection in UA V-assisted IoT networks,
M. Yi, X. Wang, J. Liu, Y . Zhang, and B. Bai, “Deep reinforcement learning for fresh data collection in UA V-assisted IoT networks,” in 14 IEEE INFOCOM 2020-IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS). IEEE, 2020, pp. 716–721
work page 2020
-
[28]
Challenges of Real-World Reinforcement Learning
G. Dulac-Arnold, D. Mankowitz, and T. Hester, “Challenges of real- world reinforcement learning,”arXiv preprint arXiv:1904.12901, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[29]
UA V swarm deploy- ment and trajectory for 3D area coverage via reinforcement learning,
J. He, Z. Jia, C. Dong, J. Liu, Q. Wu, and J. Liu, “UA V swarm deploy- ment and trajectory for 3D area coverage via reinforcement learning,” in 2023 International Conference on Wireless Communications and Signal Processing (WCSP). IEEE, 2023, pp. 683–688
work page 2023
-
[30]
Elastic collaborative edge intelligence for UA V swarm: Architecture, challenges, and opportunities,
Y . Qu, H. Sun, C. Dong, J. Kang, H. Dai, Q. Wu, and S. Guo, “Elastic collaborative edge intelligence for UA V swarm: Architecture, challenges, and opportunities,”IEEE Communications Magazine, 2023
work page 2023
-
[31]
Hierarchical reinforcement learning with the MAXQ value function decomposition,
T. G. Dietterich, “Hierarchical reinforcement learning with the MAXQ value function decomposition,”Journal of artificial intelligence re- search, vol. 13, pp. 227–303, 2000
work page 2000
-
[32]
T. D. Kulkarni, K. Narasimhan, A. Saeedi, and J. Tenenbaum, “Hier- archical deep reinforcement learning: Integrating temporal abstraction and intrinsic motivation,”Advances in neural information processing systems, vol. 29, 2016
work page 2016
-
[33]
The option-critic architecture,
P.-L. Bacon, J. Harb, and D. Precup, “The option-critic architecture,” in Proceedings of the AAAI conference on artificial intelligence, vol. 31, no. 1, 2017
work page 2017
-
[34]
Z. Qin, X. Zhang, X. Zhang, B. Lu, Z. Liu, and L. Guo, “The UA V trajectory optimization for data collection from time-constrained IoT devices: A hierarchical deep Q-network approach,”Applied Sciences, vol. 12, no. 5, p. 2546, 2022
work page 2022
-
[35]
Hierarchical deep reinforcement learning for backscattering data collection with multiple UA Vs,
Y . Zhang, Z. Mou, F. Gao, L. Xing, J. Jiang, and Z. Han, “Hierarchical deep reinforcement learning for backscattering data collection with multiple UA Vs,”IEEE Internet of Things Journal, vol. 8, no. 5, pp. 3786–3800, 2020
work page 2020
-
[36]
M. Zhiyu, Y . Zhang, F. Dian, L. Jun, and G. Feifei, “Research on the UA V-aided data collection and trajectory design based on the deep reinforcement learning,”Chinese Journal on Internet of Things, vol. 4, no. 3, pp. 42–51, 2020
work page 2020
-
[37]
N. Qi, Z. Huang, W. Sun, S. Jin, and X. Su, “Coalitional formation- based group-buying for UA V-enabled data collection: An auction game approach,”IEEE Transactions on Mobile Computing, vol. 22, no. 12, pp. 7420–7437, 2022
work page 2022
-
[38]
W. Wang, N. Qi, L. Jia, C. Li, T. A. Tsiftsis, and M. Wang, “Energy- efficient UA V-relaying 5G/6G spectrum sharing networks: Interference coordination with power management and trajectory design,”IEEE Open Journal of the Communications Society, vol. 3, pp. 1672–1687, 2022
work page 2022
-
[39]
Learning to communicate in UA V-aided wireless networks: Map-based approaches,
O. Esrafilian, R. Gangula, and D. Gesbert, “Learning to communicate in UA V-aided wireless networks: Map-based approaches,”IEEE Internet of Things Journal, vol. 6, no. 2, pp. 1791–1802, 2018
work page 2018
-
[40]
Altitude and number optimisation for UA Vv-enabled wireless communications,
J. Zhang, T. Zhang, Z. Yang, B. Li, and Y . Wu, “Altitude and number optimisation for UA Vv-enabled wireless communications,”IET Commu- nications, vol. 14, no. 8, pp. 1228–1233, 2020
work page 2020
-
[41]
Energy minimization for wireless communication with rotary-wing UA V,
Y . Zeng, J. Xu, and R. Zhang, “Energy minimization for wireless communication with rotary-wing UA V,”IEEE Transactions on Wireless Communications, vol. 18, no. 4, pp. 2329–2345, 2019
work page 2019
-
[42]
UA V path planning using global and local map information with deep rein- forcement learning,
M. Theile, H. Bayerlein, R. Nai, D. Gesbert, and M. Caccamo, “UA V path planning using global and local map information with deep rein- forcement learning,” in2021 20th International Conference on Advanced Robotics (ICAR). IEEE, 2021, pp. 539–546
work page 2021
-
[43]
DDPG-based aerial secure data collection,
H. Lei, H. Ran, I. S. Ansari, K.-H. Park, G. Pan, and M.-S. Alouini, “DDPG-based aerial secure data collection,”IEEE Transactions on Communications, vol. 72, no. 8, pp. 5179–5193, 2024
work page 2024
-
[44]
SAC-based UA V mobile edge computing for energy minimization and secure data transmission,
X. Zhao, T. Zhao, F. Wang, Y . Wu, and M. Li, “SAC-based UA V mobile edge computing for energy minimization and secure data transmission,” Ad Hoc Networks, vol. 157, p. 103435, 2024. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S1570870524000465 Zhenjia Xureceived the B.S. degree in commu- nication engineering from Nanjing Univer...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.