0
Mapped wildfire surrogates match high-fidelity PDFs at 1000x lower cost
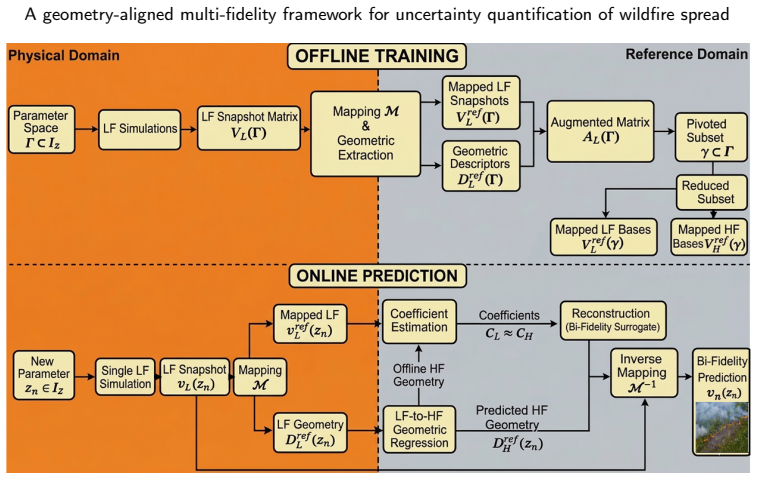
A geometry-aligned multi-fidelity framework for uncertainty quantification of wildfire spread
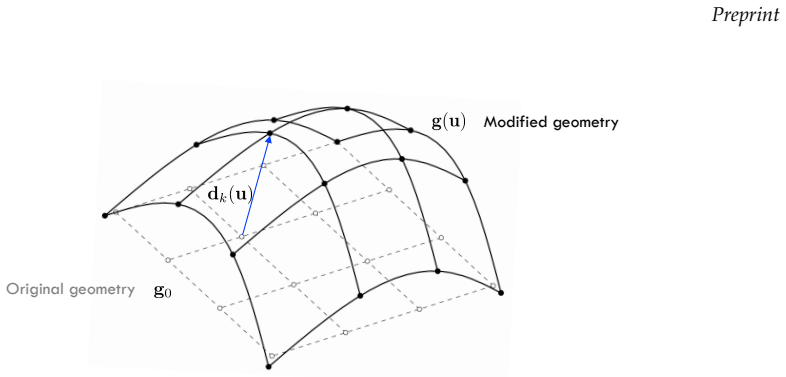
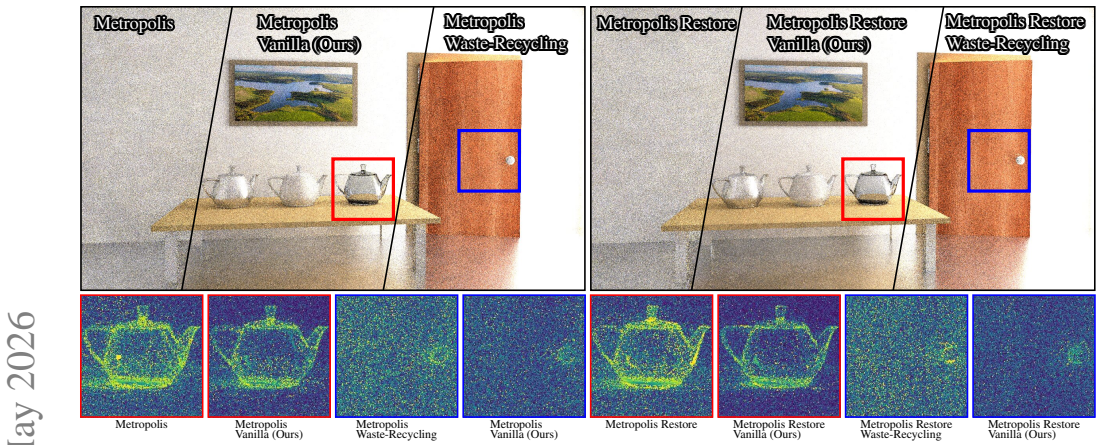
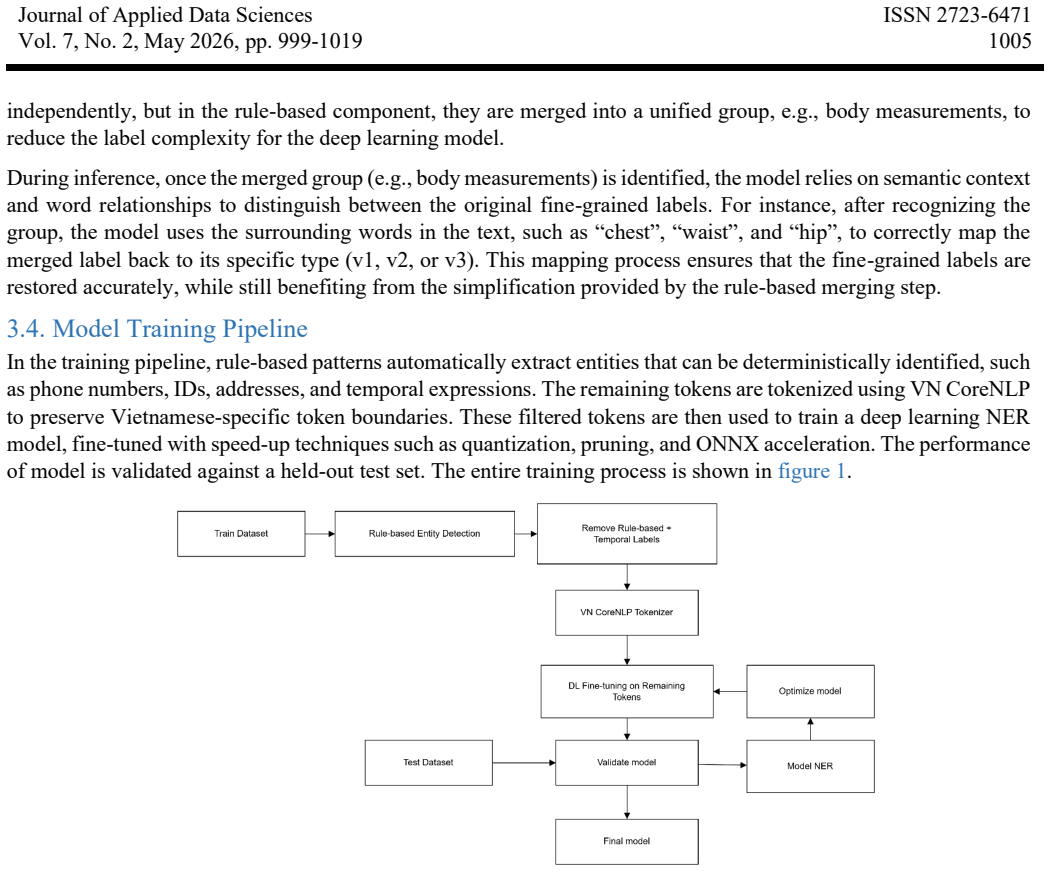
Aligning simulation fronts to a common domain before basis construction removes oscillations and recovers accurate temperature and burned-
 full image
full image
abstract click to expand
Forward propagation of input uncertainties in physics-based wildfire models is computationally prohibitive, limiting the use of high-fidelity simulators in risk assessment workflows. This work introduces a geometry-aligned bi-fidelity surrogate framework that addresses the convection-dominated nature of wildfire spread by mapping low- and high-fidelity solution snapshots onto a common reference domain prior to basis selection and reconstruction. Unlike conventional bi-fidelity schemes, which combine spatially shifted snapshots and thus suffer from oscillations and excess basis requirements near sharp fronts, the proposed mapping aligns the dominant front geometry through per-variable shift/stretch transforms in 1D and an activity indicator-based affine alignment in 2D, so that reduced bases compare physically corresponding structures rather than displaced ones. Building on the ADfiRe physics-based simulator, we demonstrate the method on 1D and 2D test cases in which low- and high-fidelity models differ in mesh resolution and physical completeness. Across both settings, the geometry-aligned surrogate reproduces full-field temperature and fuel composition with substantially lower error than its unmapped counterpart, eliminates Gibbs-type oscillations near steep gradients, and recovers high-fidelity probability density functions for key quantities of interest (e.g., maximum temperature, evaporated moisture, and burned area). After offline training, online predictions are roughly three orders of magnitude cheaper than direct high-fidelity evaluation, making the framework a practical building block for many-query uncertainty quantification once the offline cost is amortized over enough queries. We discuss the conditions under which the geometric alignment is most effective, its limitations for non-convex or topologically complex fronts, and the path toward validation against real data.