Hierarchical Long-Term Semantic Memory for LinkedIn's Hiring Agent
Pith reviewed 2026-05-07 13:28 UTC · model grok-4.3
The pith
A schema-aligned hierarchical memory tree lets LLM agents store and retrieve long-term semantic knowledge with over 10% gains in correctness and retrieval quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that representing long-term semantic memory as a schema-aligned tree that holds knowledge at multiple granularities, combined with an adaptation mechanism, solves the joint problems of scalable ingestion, privacy-aware storage, low-latency retrieval, and observable provenance, producing more than 10% higher answer correctness and retrieval F1 while moving the query-versus-indexing latency frontier outward.
What carries the argument
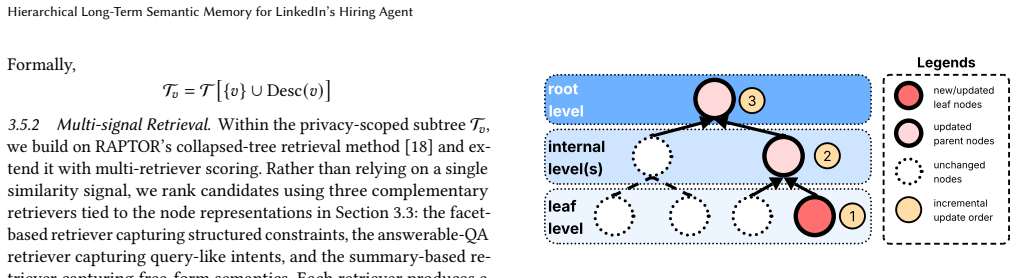
The schema-aligned memory tree that stores semantic knowledge at multiple levels of granularity and incorporates an adaptation mechanism for cross-domain use.
If this is right
- Ingestion of noisy longitudinal behavioral data becomes scalable because the tree grows incrementally along schema paths.
- Storage can remain privacy-aware since only the structured nodes, not raw logs, need to be kept.
- Retrieval latency drops because queries can target the appropriate granularity level instead of scanning everything.
- Provenance stays transparent because every retrieved fact traces back to its originating node and schema.
- The adaptation mechanism allows the same tree structure to be reused in new domains with limited additional tuning.
Where Pith is reading between the lines
- The tree structure might naturally support selective forgetting or data minimization, which could help satisfy stricter privacy rules without extra engineering.
- Similar hierarchical organization could be tested in other agent settings that accumulate user history, such as personal scheduling or customer-support assistants.
- The latency gains suggest that indexing cost might stay manageable even as the number of users grows, provided the schema remains stable.
- If the adaptation step can be made fully automatic, the framework could reduce the need for per-domain engineering effort.
Load-bearing premise
The schema-aligned memory tree and adaptation mechanism will work across many different applications and the reported gains on internal data will hold when baselines and data splits are chosen independently.
What would settle it
Applying the same tree construction and retrieval procedure to an independent, publicly available long-term memory benchmark and measuring no improvement in correctness or in the latency trade-off would falsify the central performance claim.
Figures




read the original abstract
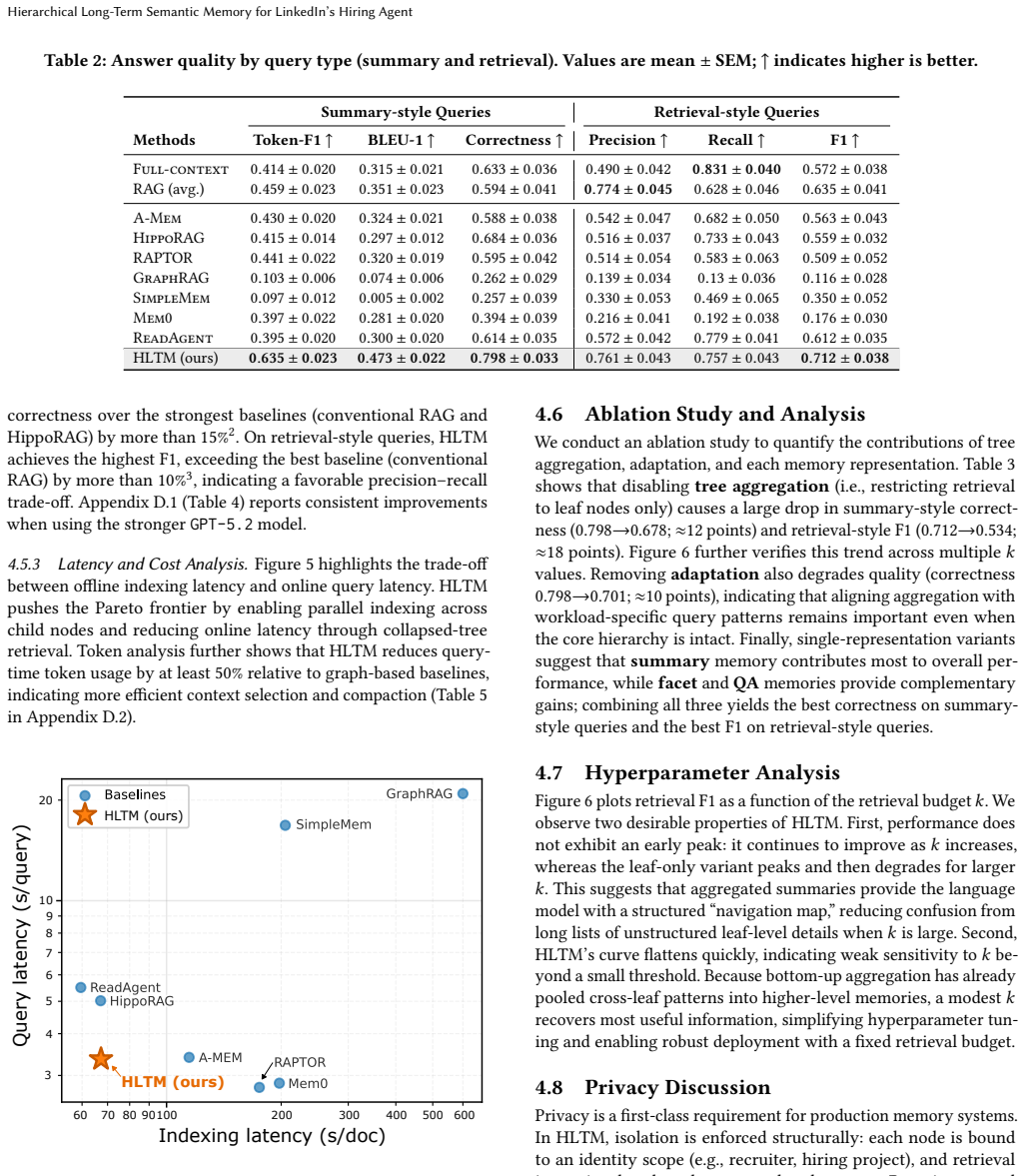
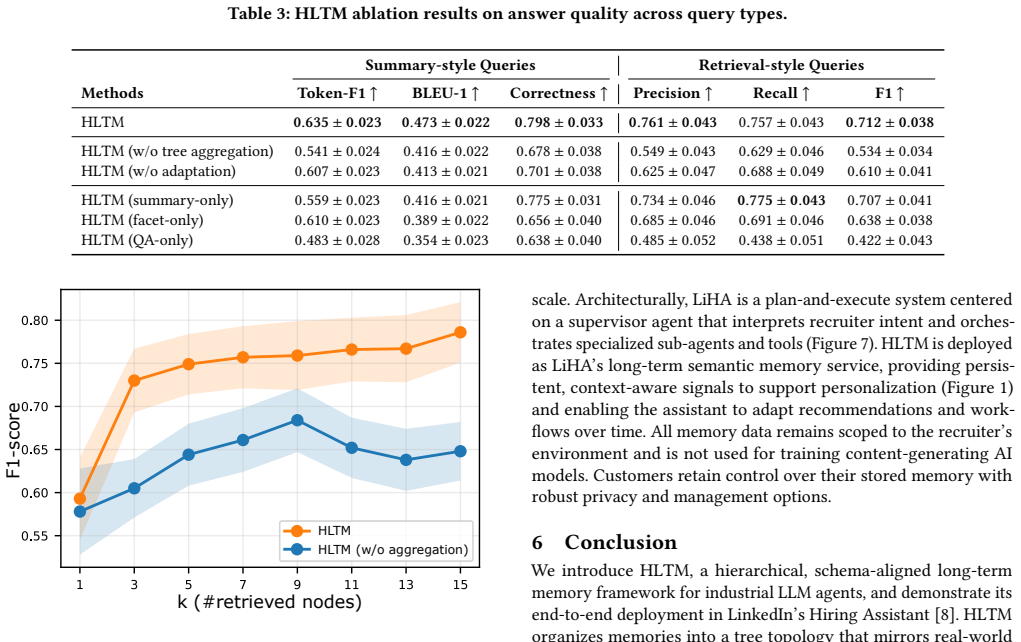
Large Language Model (LLM) agents are increasingly used in real-world products, where personalized and context-aware user interactions are essential. A central enabler of such capabilities is the agent's long-term semantic memory system, which extracts implicit and explicit signals from noisy longitudinal behavioral data, stores them in a structured form, and supports low-latency retrieval. Building industrial-grade long-term memory for LLM agents raises five challenges: scalability, low-latency retrieval, privacy constraints, adaptability, and observability. We introduce the Hierarchical Long-Term Semantic Memory (HLTM) framework, which organizes textual data into a schema-aligned memory tree that captures semantic knowledge at multiple levels of granularity, enabling scalable ingestion, privacy-aware storage, low-latency retrieval, and transparent provenance; HLTM further incorporates an adaptation mechanism to generalize across diverse use cases. Extensive evaluations on LinkedIn's Hiring Assistant show that HLTM improves answer correctness by more than 5% and retrieval F1 by more than 10%, while significantly advancing the Pareto frontier between query and indexing latency. HLTM has been fully deployed in LinkedIn's Hiring Assistant to power core personalization features in production hiring workflows.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Hierarchical Long-Term Semantic Memory (HLTM) framework for LLM agents, which structures longitudinal behavioral data into a schema-aligned memory tree supporting multi-granularity semantic knowledge. This addresses industrial challenges including scalability, low-latency retrieval, privacy, cross-domain generalizability, and observability, with an adaptation mechanism for diverse use cases. Evaluations on LinkedIn's Hiring Assistant data report >10% gains in answer correctness and retrieval F1, plus Pareto improvements in query/indexing latency; the system is deployed in production for personalization in hiring workflows.
Significance. If the empirical results hold under scrutiny, the work is significant for industrial information retrieval and LLM agent systems. It offers a deployable solution to long-term memory challenges with explicit attention to privacy and latency trade-offs, backed by real-world production use at LinkedIn. This provides a concrete reference point for similar personalization tasks in hiring and recommendation domains.
major comments (2)
- [Abstract / Evaluation] Abstract and Evaluation section: The central claims of >10% improvements in answer correctness and retrieval F1 (plus Pareto frontier advance) are stated without any reported details on test-set size, query distribution, baseline definitions (e.g., standard RAG or prior memory systems), statistical tests, ablation results, or data characteristics. This omission is load-bearing because the headline performance gains cannot be verified as robust rather than artifacts of data selection or weak baselines.
- [HLTM Framework] Framework description (likely §3): The adaptation mechanism is asserted to enable generalization across use cases, yet no cross-domain, hold-out, or external validation experiments are described to support this claim, leaving the generalizability assertion unsupported by evidence.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important areas for strengthening the presentation of our empirical results and the generalizability discussion. We have revised the manuscript to provide additional context and clarifications while respecting the proprietary constraints of the LinkedIn production data.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and Evaluation section: The central claims of >10% improvements in answer correctness and retrieval F1 (plus Pareto frontier advance) are stated without any reported details on test-set size, query distribution, baseline definitions (e.g., standard RAG or prior memory systems), statistical tests, ablation results, or data characteristics. This omission is load-bearing because the headline performance gains cannot be verified as robust rather than artifacts of data selection or weak baselines.
Authors: We agree that greater transparency on the experimental setup is warranted. In the revised manuscript, we have expanded the Evaluation section (and updated the abstract for consistency) to report test-set size, high-level query characteristics, explicit baseline definitions (including standard RAG and prior memory systems), statistical significance testing, and ablation studies isolating the contribution of the hierarchical structure and adaptation mechanism. Due to privacy and proprietary constraints, we report aggregated statistics rather than raw query distributions or individual examples. revision: yes
-
Referee: [HLTM Framework] Framework description (likely §3): The adaptation mechanism is asserted to enable generalization across use cases, yet no cross-domain, hold-out, or external validation experiments are described to support this claim, leaving the generalizability assertion unsupported by evidence.
Authors: We acknowledge that the generalizability claim would be strengthened by additional empirical validation. The current work evaluates HLTM on LinkedIn's Hiring Assistant, a complex production setting. The adaptation mechanism is presented in Section 3 as a modular, schema-driven component intended to support diverse domains. In the revision, we have added a new subsection in the Discussion that explicitly addresses design choices supporting generalization, outlines how the mechanism can be applied to other use cases, and states the limitations of validating only within the hiring domain. revision: partial
- Full raw query distributions and per-user data characteristics, which cannot be disclosed due to LinkedIn's privacy policies and data protection regulations.
Circularity Check
No circularity: claims rest on empirical system evaluation without self-referential derivations
full rationale
The paper describes the HLTM framework as a hierarchical memory tree with schema alignment and an adaptation mechanism for LLM agents in hiring workflows. Central performance claims (>10% gains in correctness and F1, plus Pareto latency improvements) are presented as results of extensive evaluations on LinkedIn's internal Hiring Assistant data and production deployment. No equations, fitted parameters, predictions, or uniqueness theorems appear in the abstract or described structure that could reduce to inputs by construction. No self-citations are invoked as load-bearing justification for core premises. The derivation chain is therefore self-contained as an engineering contribution validated externally to any internal definitions.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.