InterPartAbility: Phrase-Region Grounding for Interpretable Text-to-Image Person Re-Identification
Pith reviewed 2026-07-01 08:20 UTC · model grok-4.3
The pith
InterPartAbility grounds text phrases to specific image regions in text-to-image person re-identification to produce quantitative explanations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
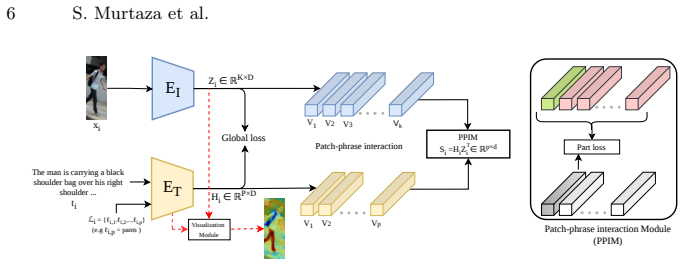
InterPartAbility performs phrase-region grounding by guiding a standard TI-ReID model with concept-level phrases via the open-vocabulary patch-phrase interaction module, which encourages attention to matching local image regions, then leverages CLIP ViT self-attention to produce spatially concentrated patch activations that form grounded explanation maps, and evaluates them through a quantitative protocol that measures retrieval degradation after counterfactual region removal.
What carries the argument
The open-vocabulary patch-phrase interaction module (PPIM) that binds visual patches to semantic part phrases to encourage region-specific attention.
If this is right
- TI-ReID decisions become tied to specific semantic phrases rather than opaque region highlights.
- Interpretability can be compared across methods using the same perturbation-based metrics.
- Grounded explanations support applications that require traceable matches, such as security screening.
- The same phrase-guided attention mechanism could be applied to other vision-language retrieval tasks.
Where Pith is reading between the lines
- The protocol could be reused to evaluate interpretability in related tasks like image captioning or visual question answering.
- If part phrases are derived automatically rather than predefined, the method might scale to open-ended descriptions.
- Spatially concentrated activations might reduce false matches caused by background clutter in crowded scenes.
Load-bearing premise
Concept-based part phrases reliably encourage the model to attend to the matching local image regions.
What would settle it
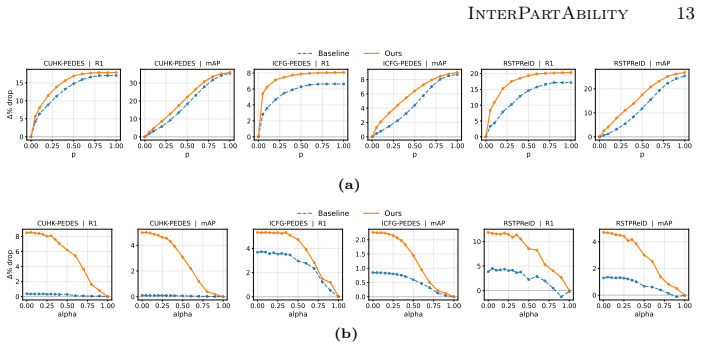
Removing the top-ranked explanatory regions produced by InterPartAbility fails to degrade retrieval performance more than removing regions from a non-interpretable baseline or random patches.
Figures


read the original abstract
Text-to-image person re-identification (TI-ReID) relies on natural-language text descriptions to retrieve top matching individuals from a gallery of reference images. While recent large vision-language models (VLMs) achieve strong retrieval performance, their decisions remain largely uninterpretable. Existing interpretability approaches in TI-ReID rely solely on slot-attention to highlight attended regions, but fail to reliably bind visual regions to semantically meaningful concepts, limiting interpretation to qualitative visualizations over a restricted vocabulary. This paper introduces InterPartAbility, an interpretable TI-ReID method that performs explicit part-wise matching and enables phrase-region grounding. Unlike parameter-heavy slot-attention methods that yield only qualitative interpretability, our open-vocabulary patch-phrase interaction module (PPIM) guides a standard TI-ReID model with concept-level phrases. Concept-based part phrases provide evidence that encourages the model to attend to the corresponding local image regions. InterPartAbility further leverages CLIP ViT self-attention to produce spatially concentrated patch activations aligned with each part-level phrase, yielding grounded explanation maps. Finally, a quantitative interpretability protocol for TI-ReID is introduced that extends current perturbation-based evaluation metrics into the TI-Reid domain. This includes a counterfactual region removal that measures retrieval degradation when top-ranked explanatory regions are removed. Empirical results on three challenging benchmarks show that InterPartAbility can achieve SOTA interpretability performance under these metrics, while sustaining competitive retrieval accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents InterPartAbility, an interpretable method for text-to-image person re-identification (TI-ReID). It augments a standard TI-ReID pipeline with an open-vocabulary patch-phrase interaction module (PPIM) driven by concept-level phrases, leverages CLIP ViT self-attention to produce spatially concentrated patch activations for grounded explanation maps, and introduces a quantitative interpretability protocol extending perturbation-based metrics with counterfactual region removal. The central claim is that this yields SOTA interpretability performance on three benchmarks while sustaining competitive retrieval accuracy.
Significance. If the empirical results hold with proper validation, the work would advance interpretability in TI-ReID by moving beyond qualitative slot-attention visualizations to explicit phrase-region grounding and a new quantitative evaluation protocol, addressing a clear gap in binding visual regions to semantically meaningful concepts.
major comments (1)
- [Abstract] Abstract: The abstract asserts SOTA interpretability results on three benchmarks but supplies no numbers, baselines, statistical tests, or implementation details; the central claim cannot be evaluated from the given text.
Simulated Author's Rebuttal
We thank the referee for their review. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract asserts SOTA interpretability results on three benchmarks but supplies no numbers, baselines, statistical tests, or implementation details; the central claim cannot be evaluated from the given text.
Authors: We agree that the abstract is too high-level and does not allow evaluation of the central claim. In the revised version we will expand the abstract to report the key quantitative interpretability scores (e.g., the perturbation-based degradation metrics), the main baselines, and a brief statement of the evaluation protocol and benchmarks used. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper describes an architectural augmentation to a standard TI-ReID pipeline via an open-vocabulary PPIM and CLIP ViT attention, followed by empirical evaluation on three benchmarks using an extended perturbation protocol. No equations, parameter-fitting steps, or self-citation chains appear in the abstract or described method that would reduce any claimed prediction or uniqueness result to the inputs by construction. The central claims rest on reported experimental outcomes rather than definitional or fitted tautologies.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2504.12197 (2025) 2, 4
Alehdaghi, M., Bhattacharya, R., Shamsolmoali, P., Cruz, R.M., Heritier, M., Granger, E.: Beyond patches: Mining interpretable part-prototypes for explain- able ai. arXiv preprint arXiv:2504.12197 (2025) 2, 4
-
[2]
In: CVPR (2025) 4
Bai, Y., Ji, Y., Cao, M., Wang, J., Ye, M.: Chat-based person retrieval via dialogue- refined cross-modal alignment. In: CVPR (2025) 4
2025
-
[3]
In: Proceedings of the AAAI Conference on Artificial Intelligence (2024) 4, 15
Cao, M., Bai, Y., Zeng, Z., Ye, M., Zhang, M.: An empirical study of clip for text-based person search. In: Proceedings of the AAAI Conference on Artificial Intelligence (2024) 4, 15
2024
-
[4]
In: Proceedings of the IEEE/CVF international conference on computer vision
Chefer, H., Gur, S., Wolf, L.: Generic attention-model explainability for interpret- ing bi-modal and encoder-decoder transformers. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 397–406 (2021) 9
2021
-
[5]
Advances in neural information processing systems32(2019) 4
Chen, C., Li, O., Tao, D., Barnett, A., Rudin, C., Su, J.K.: This looks like that: deep learning for interpretable image recognition. Advances in neural information processing systems32(2019) 4
2019
-
[6]
In: Scandinavian Conference on Image Analysis
Cohen, D., Chefer, H., Wolf, L.: A meaningful perturbation metric for evaluating explainability methods. In: Scandinavian Conference on Image Analysis. pp. 309–
-
[7]
Semantically self-aligned network for text-to-image part-aware person re-identification
Ding, Z., Ding, C., Shao, Z., Tao, D.: Semantically self-aligned network for text-to- image part-aware person re-identification. arXiv preprint arXiv:2107.12666 (2021) 2, 3, 11, 15
-
[8]
ACM Transactions on Multimedia Computing, Communications and Applications21(10), 1–22 (2025) 14, 17
Ergasti, A., Fontanini, T., Ferrari, C., Bertozzi, M., Prati, A.: Mars: Paying more attention to visual attributes for text-based person search. ACM Transactions on Multimedia Computing, Communications and Applications21(10), 1–22 (2025) 14, 17
2025
-
[9]
arXiv preprint arXiv:2101.03036 (2021) 3, 15
Gao, C., Cai, G., Jiang, X., Zheng, F., Zhang, J., Gong, Y., Peng, P., Guo, X., Sun, X.: Contextual non-local alignment over full-scale representation for text- based person search. arXiv preprint arXiv:2101.03036 (2021) 3, 15
-
[10]
Heritier, M., Mekhazni, D., Leblond-Menard, C., Godbout, B., Guilbaud, N., Ale- hdaghi, M., Granger, E.: Exam: Unsupervised concept-based representation learn- ingtobetterexplainmodelsinvisiontasks.In:ProceedingsoftheComputerVision and Pattern Recognition Conference. pp. 2750–2759 (2025) 2, 4
2025
-
[11]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Jiang, D., Ye, M.: Cross-modal implicit relation reasoning and aligning for text-to- image person retrieval. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 2787–2797 (2023) 3, 11, 14, 15, 17
2023
-
[12]
In: Proceedings of the AAAI Conference on Artificial Intelligence (2020) 3, 15
Jing, Y., Si, C., Wang, J., Wang, W., Wang, L., Tan, T.: Pose-guided multi- granularity attention network for text-based person search. In: Proceedings of the AAAI Conference on Artificial Intelligence (2020) 3, 15
2020
-
[13]
In: International conference on machine learning
Kim, B., Wattenberg, M., Gilmer, J., Cai, C., Wexler, J., Viegas, F., et al.: Inter- pretabilitybeyondfeatureattribution:Quantitativetestingwithconceptactivation vectors (tcav). In: International conference on machine learning. pp. 2668–2677. PMLR (2018) 4
2018
-
[14]
Neurocomputing p
Kim, G., Eom, C.: Dico: Disentangled concept representation for text-to-image person re-identification. Neurocomputing p. 132885 (2026) 2, 4, 8, 11, 14, 16, 17
2026
-
[15]
In: CVPR (2017) 2, 3, 11, 15
Li, S., Xiao, T., Li, H., Zhou, B., Yue, D., Wang, X.: Person search with natural language description. In: CVPR (2017) 2, 3, 11, 15
2017
-
[16]
In: European conference on com- puter vision
Liao, S., Shao, L.: Interpretable and generalizable person re-identification with query-adaptive convolution and temporal lifting. In: European conference on com- puter vision. pp. 456–474. Springer (2020) 4 24 S. Murtaza et al
2020
-
[17]
Advances in neural information processing systems33, 11525–11538 (2020) 2, 4, 8
Locatello, F., Weissenborn, D., Unterthiner, T., Mahendran, A., Heigold, G., Uszkoreit, J., Dosovitskiy, A., Kipf, T.: Object-centric learning with slot atten- tion. Advances in neural information processing systems33, 11525–11538 (2020) 2, 4, 8
2020
-
[18]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Nauta, M., Schlötterer, J., Van Keulen, M., Seifert, C.: Pip-net: Patch-based in- tuitive prototypes for interpretable image classification. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 2744–2753 (2023) 4
2023
-
[19]
In: European Conference on Com- puter Vision
Park, J., Kim, D., Jeong, B., Kwak, S.: Plot: Text-based person search with part slot attention for corresponding part discovery. In: European Conference on Com- puter Vision. pp. 474–490. Springer (2024) 2, 4, 8, 11, 14, 17
2024
-
[20]
In: CVPR (2025) 4, 5, 8, 11, 14, 16, 17
Qin, Y., Chen, C., Fu, Z., Peng, D., Peng, X., Hu, P.: Human-centered interactive learning via mllms for text-to-image person re-identification. In: CVPR (2025) 4, 5, 8, 11, 14, 16, 17
2025
-
[21]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Qin, Y., Chen, Y., Peng, D., Peng, X., Zhou, J.T., Hu, P.: Noisy-correspondence learning for text-to-image person re-identification. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 27197– 27206 (2024) 2, 4, 5, 16
2024
-
[22]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PMLR (2021) 2, 3, 15, 16
2021
-
[23]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Tan, W., Ding, C., Jiang, J., Wang, F., Zhan, Y., Tao, D.: Harnessing the power of mllms for transferable text-to-image person reid. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 17127–17137 (2024) 11, 14, 16, 17
2024
-
[24]
In: Computer Vision–ECCV 2020: 16th Eu- ropean Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XII 16
Wang, Z., Fang, Z., Wang, J., Yang, Y.: Vitaa: Visual-textual attributes alignment in person search by natural language. In: Computer Vision–ECCV 2020: 16th Eu- ropean Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XII 16. pp. 402–420. Springer (2020) 3, 15
2020
-
[25]
IEEE Transactions on Image Processing (2023) 4, 15
Yan, S., Dong, N., Zhang, L., Tang, J.: Clip-driven fine-grained text-image person re-identification. IEEE Transactions on Image Processing (2023) 4, 15
2023
-
[26]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al.: Qwen3 technical report. arXiv preprint arXiv:2505.09388 (2025) 5, 16
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
In: Proceedings of the 31st ACM international conference on multimedia
Yang, S., Zhou, Y., Zheng, Z., Wang, Y., Zhu, L., Wu, Y.: Towards unified text- based person retrieval: A large-scale multi-attribute and language search bench- mark. In: Proceedings of the 31st ACM international conference on multimedia. pp. 4492–4501 (2023) 11, 14, 16, 17
2023
-
[28]
In: Proceedings of the European conference on computer vision (ECCV)
Zhang, Y., Lu, H.: Deep cross-modal projection learning for image-text matching. In: Proceedings of the European conference on computer vision (ECCV). pp. 686– 701 (2018) 3, 15
2018
-
[29]
In: Pro- ceedings of the AAAI Conference on Artificial Intelligence (2024) 4, 16
Zhao, Z., Liu, B., Lu, Y., Chu, Q., Yu, N.: Unifying multi-modal uncertainty mod- eling and semantic alignment for text-to-image person re-identification. In: Pro- ceedings of the AAAI Conference on Artificial Intelligence (2024) 4, 16
2024
-
[30]
In: Proceedings of the 29th ACM International Conference on Multimedia
Zhu, A., Wang, Z., Li, Y., Wan, X., Jin, J., Wang, T., Hu, F., Hua, G.: Dssl: Deep surroundings-person separation learning for text-based person retrieval. In: Proceedings of the 29th ACM International Conference on Multimedia. p. 209–217. MM ’21 (2021) 2, 11 InterPartAbility25
2021
-
[31]
In: ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition
Zuo, J., Zhou, H., Nie, Y., Zhang, F., Guo, T., Sang, N., Wang, Y., Gao, C.: Ufinebench: Towards text-based person retrieval with ultra-fine granularity. In: ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition. pp. 22010–22019 (2024) 2, 4
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.